Google の Cloud Speech-to-Text API で音声認識に加えて、発話者の識別ができるようになったのでこれを利用して以下のように結果を色分けする形で表示してみたいと思います。
なお、今回作成したソースは以下のGitHubのリポジトリに置いてあります
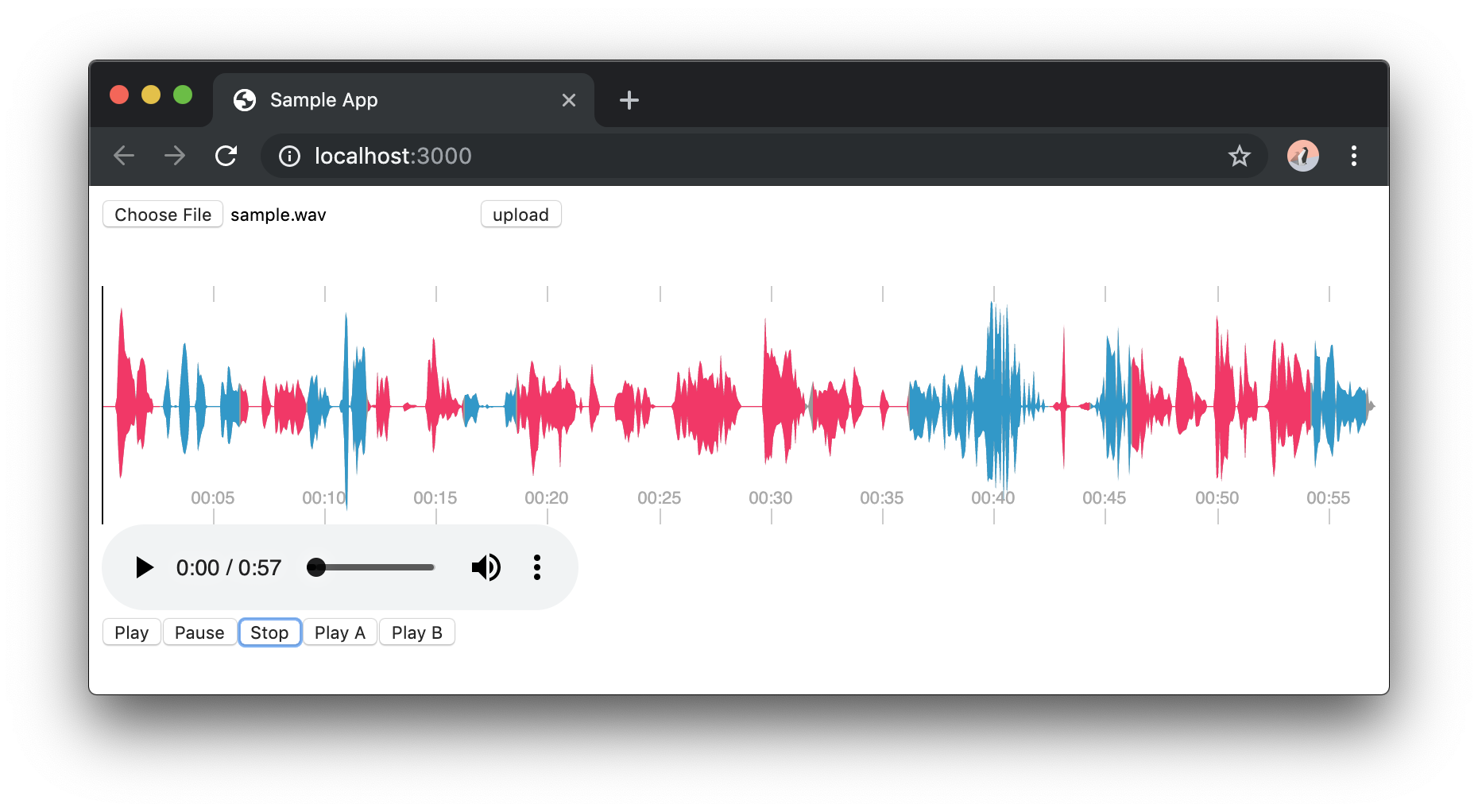
なお、API 上は入力として最大5名まで対応しているようなのですが、今回のサンプルでは固定で2名としています。
【注意】2019年5月3日現在、Google Cloud の API ドキュメント (https://cloud.google.com/speech-to-text/docs/multiple-voices) によると、speaker diarization は en-US, en-IN, es-ES のみの対応(ただしベータ)だそうですのでご注意ください。(日本語の音声も speaker diarization を有効にして入力すれば話者ラベルは付与されるのでそのうちサポートされると思います)
動作確認環境
- macOS Mojave
- Node.js 11.6.0
- Express.js 4.16.4
- React 16.8.6
- peaks.js 0.9.14
- waveform-data 2.1.2
- Google Chrome 73
全体の構成
フロントエンドに React を使用しています。ここでは、Wavファイルのサーバへのアップロード機能と、サーバから結果を受け取り、Peaks.js を使って波形を表示する処理を提供します。
サーバサイドには Express.js を使用しています。ここでは、Wavファイルがアップロードされた際に、音声を Google Cloud Speech API に送信して音声認識と話者分離の結果を受け取り、話者分離の結果を抽出してフロントエンドに返す処理を行っています。
1. Google Cloud Speech API を有効にする
以下の記事に大変詳しい説明が記載されていますのでこちらをご参照ください。
なお、1ヶ月に60分までは無料で利用できますが、それ以上は有料になりますのでご注意ください。
2. Speech-to-Text Client ライブラリのインストールと設定
以下のコマンドでNode.js 用のクライアントライブラリをインストールします。
npm install --save @google-cloud/speech
次に、環境変数 GOOGLE_APPLICATION_CREDENTIALS に 1 で取得したサービスアカウントキーJSONを指定します。
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
これでライブラリを使用するための準備は完了です。
3 Cloud Speech API で音声認識と話者分離を実行する
はじめにクライアントの初期化を行います。話者分離の機能はベータ版のみでの提供となっているので、ここでベータ版を指定しておきます。
const speech = require('@google-cloud/speech').v1p1beta1
const client = new speech.SpeechClient()
次に、音声ファイル(サンプリング周波数16kHz、リニアPCM形式のWAVEファイル)を読み込んで、Base64でエンコードします。
const fs = require('fs')
const audio = {
content: fs.readFileSync(filename).toString('base64')
}
次に、設定を記述しています。
const config = {
encoding: 'LINEAR16'',
sampleRateHertz: 16000,
languageCode: 'ja-JP',
diarizationSpeakerCount: 2,
enableAutomaticPunctuation: true,
enableSpeakerDiarization: true,
model: 'default'
}
各設定項目の内容は以下のとおりです。
| 設定 | 説明 |
|---|---|
| encoding | 音声ファイルの形式です。ここではビット長16のリニアPCMを使用しているため 'LINEAR16' を指定しています。 |
| sampleRateHertz | 音声ファイルのサンプリング周波数です。単位が Hz なので、16kHz の場合は 16000 となります。 |
| languageCode | 入力音声の言語コードです。日本語の場合は 'ja-JP' を指定します |
| diarizationSpeakerCount | 入力音声中の話者の数です。今回は2名での会話なので 2 を指定します |
| enableAutomaticPunctuation | 音声認識の出力結果に句読点を付けるか否かの指定と思われます。が、私が試した範囲では true にしても句読点付いてなかった... |
| enableSpeakerDiarization | 話者分離を行うか否かの指定。 |
| model | 入力音声に応じた(機械学習の?)モデルを指定します。 |
最後に音声データと設定項目をリクエストデータに指定して recognize メソッドを呼ぶことで、音声認識と話者分離の結果が取得できます。
const request = {
audio: audio,
config: config
}
const [response] = await client.recognize(request)
Cloud Speech API の結果から話者分離の結果を取得する
話者分離の結果は Cloud Speech API のレスポンスデータに以下のように格納されています(今回必要のない要素は一部省略しています)。
{ results:
[
{
alternatives: [
{
"words": [
{
"startTime": {"seconds": "1", nanos: 70000000},
"endTime": {"seconds": "1", nanos: 90000000},
"word": "はい",
"confidence": 0,
"speakerTag": 1
},
{
"startTime": {"seconds": "2", nanos: 60000000},
"endTime": {"seconds": "2", nanos: 80000000},
"word": "いいえ",
"confidence": 0,
"speakerTag": 2
}
]
}
]
}
]
}
次に Cloud Speech API のレスポンスから今回の可視化に必要な "words" の中の "startTime" と "endTime" と "speakerTag" を抽出します。
もうちょっとキレイに書きたいところですが今回は妥協しています。ゴメンナサイ。
// Extract segmentation info from Cloud Speech API's results
const extractSegInfo = (recognizeInfo) => {
// Convert Speech API result to segment data
let segSpk1 = [] // speakerTag が 1 の [startTime, endTime] を格納する
let segSpk2 = [] // speakerTag が 2 の [startTime, endTime] を格納する
recognizeInfo.results[0].alternatives[0].words.forEach((word) => {
const startTime = parseFloat(word.startTime.seconds) + parseFloat(word.startTime.nanos) / 1000 / 1000 / 1000
const endTime = parseFloat(word.endTime.seconds) + parseFloat(word.endTime.nanos) / 1000 / 1000 / 1000
const speakerTag = word.speakerTag
if (speakerTag === 1) {
if (segSpk1.length > 0 && segSpk1[segSpk1.length - 1][1] === startTime) {
segSpk1[segSpk1.length - 1][1] = endTime
} else {
segSpk1.push([startTime, endTime])
}
} else if (speakerTag === 2) {
if (segSpk2.length > 0 && segSpk2[segSpk2.length - 1][1] === startTime) {
segSpk2[segSpk2.length - 1][1] = endTime
} else {
segSpk2.push([startTime, endTime])
}
} else {
console.log(`unknown speaker ${speakerTag}`)
}
})
return [segSpk1, segSpk2]
}
なお speakerTag が同じで、前の word の endTime と次の word の startTime が一致している場合(結構多いです)は要素を結合しています。
最終的にサーバからフロントへ送られるデータは以下のようになります。
{
wavfile: 'wav/sample.wav',
segInfo: [
[[0.0, 0.5], [1.5, 2.0], [2.8, 3.2]], // 話者1の発声区間
[[0.6, 1.4], [2.1, 2.7]] // 話者2の発声区間
]
Peaks.js で可視化する
Peaks.js とはBBCが開発している音声データを可視化するソフトウェアです。公式サイトで詳細な説明と簡単なデモが確認できます。
今回はこのライブラリを使用して波形の表示を行ってみたいと思います。
インストール
peaks.js と waveform-data をインストールします。waveform-data は WAVE ファイルから peaks.js の入力となる波形データを生成するために使用されます。
$ npm install --save peaks.js waveform-data
区間情報の作成
サーバからのレスポンスを元に、Peaks.js の初期化に必要な区間情報を作成します。
作成する区間情報は以下のような形式です。
[{ startTime: 0.0, endTime: 1.0, editable: false, color: '#ff0000' },
{ startTime: 1.0, endTime: 2.0, editable: true, color: '#00ff00' },
...
]
componentDidUpdate () {
if (this.props.segInfo !== null) {
this.seg1 = this.createSegments(this.props.segInfo[0], '#ff0066')
this.seg2 = this.createSegments(this.props.segInfo[1], '#0099cc')
const segments = this.seg1.concat(this.seg2)
this.initPeaks(segments)
}
}
// Peaks.js の初期化に必要な以下の形式の区間情報を作成する
// [[{startTime, endTime, editable, color}], {startTime, endTime, editable, color}, ...]
createSegments (arr, color) {
let segments = []
for (let v of arr) {
// startTime と endTime が同じ場合、Peaks.js がエラーを返すため回避策として 1msec 加算する
if (v[0] === v[1]) v[1] += 0.001
segments.push({ startTime: v[0], endTime: v[1], editable: false, color: color })
}
return segments
}
次に、上記で作成した区間情報を用いて Peaks.js の初期化を行います。
なお、HTML要素として <audio> と <div id='peaks-container'> を予め定義しておく必要があります。
initPeaks (segments) {
this.audioCtx = new window.AudioContext()
this.peaks = Peaks.init({
// 波形を表示する container
container: document.querySelector('#peaks-container'),
// 音声データをセットした HTML5 の Media 要素
mediaElement: document.querySelector('audio'),
// 波形を描画する際に使用される Web Audio API の AudioContext インスタンス
audioContext: this.audioCtx,
height: 150,
inMarkerColor: '#aff000',
outMarkerColor: '#0000ff',
// 拡大波形の色(区間情報が定義されていない区間に適用される)
zoomWaveformColor: '#999999',
// 全体波形の色(区間情報が定義されていない区間に適用される)
overviewWaveformColor: '#999999',
// 全体波形で、拡大区間に表示されている領域のハイライトに使用される色。以下のように設定するとハイライトは表示されない。
overviewHighlightRectangleColor: 'rgba(0, 0, 0, 0.0)',
// 始端、終端、表示色を含む区間情報
segments: segments
})
this.peaks.on('peaks.ready', () => {
console.log('peaks ready')
})
}
波形を表示するコンポーネントの render() メソッドは以下のとおりです。
波形の container として <div id='peaks-container /> を定義しているのと、HTML 5 の Media 要素として <audio> タグで音声ファイルを指定しています。
また、おまけ要素として話者1の区間のみ、話者2の区間のみを連続して再生する機能も設けています。
render () {
if (this.props.wavfile === '' || this.props.segInfo === null) {
return <div />
}
const play = () => {
this.peaks.player.play()
}
const pause = () => {
this.peaks.player.pause()
}
const stop = () => {
this.peaks.player.pause()
this.peaks.player.seek(0)
}
return (
<div className='Form'>
<div id='peaks-container' />
<audio id='peaks-audio' controls='controls'>
<source src={this.props.wavfile} type='audio/wav' />
</audio><br />
<button onClick={play}>Play</button>
<button onClick={pause}>Pause</button>
<button onClick={stop}>Stop</button>
<button onClick={() => this.playSegments(this.seg1, 0)}>Play A</button>
<button onClick={() => this.playSegments(this.seg2, 0)}>Play B</button>
</div>
)
}

なお、標準では上記のように再生区間を拡大したものと全体の波形が上下に別れて表示されますが、拡大部分が不要な場合は以下のように ".zoom-container" を非表示にすることができます。
.zoom-container {
display: none;
}