はじめに
最近『ゼロから作るDeep Learning 2』で自然言語処理の勉強をしていて、備忘を兼ねてRNNについてまとめてみました!
この記事では、Word2Vecの問題点とそれを解決したRNNの仕組みを「本当にゼロから」実装しながら学んだことを、できるだけ丁寧に・分かりやすく紹介するので良かったら見てみてください!!
Word2Vecでは見えない「前の単語」
前回の記事では、Word2Vecを使った「単語の意味ベクトル化」について解説しました。
Word2Vecは「ある単語の周囲(=コンテキスト)にある単語たち」を使って、意味的な分布を学習する方法で、語彙をベクトル空間上にマッピングする強力な技術でした。
でも、少し問題点があります。
Word2Vecには ある制約 があるのです。
Word2Vecの限界:固定長のコンテキスト
Word2Vecでは、たとえば「前後5単語」など 固定長のコンテキストウィンドウ を使います。
つまり、ターゲットとなる単語の「すぐ近くにある単語」しか学習の材料にできないのです。
しかし、自然言語(日本語とか英語)って、もっと長い依存関係がありますよね。
たとえば、こんな文章です。
↓
さっき言った赤いリンゴ、おばあちゃんが昨日スーパーで買ったやつだよ。
このとき「 やつ(=リンゴ) 」という単語に対して、「 赤いリンゴ 」という表現はずっと前に出てきてしまっています。
先ほど、「前後5単語」をコンテキストウィンドウとして学習する場合、ターゲット(やつ)に対して本当に推論したい単語(赤いリンゴ)はすごく遠くて計算できないのです。
こういう「距離(時間)を超えたつながり」を捉えるのって、Word2Vecにはちょっと苦手な領域だったのです。
コンテキストウィンドウを大きくすれば推論できると思います。
ですが、メモリリソースを大きく消費してしまうというデメリットが大きすぎますし、コンテキストウィンドウをどこまで長くするべきか?など問題点があるため、結局RNNで時系列の計算をした方が良さそうです。
Word2Vecはそもそも単語ベクトルの分散表現を得るために生み出されたものであり、そもそも RNNとは別個のもの とのことでした。実際、RNNよりもWord2Vecの方が後発で生み出されたようです。ですが、本記事では便宜上、Word2Vecの苦手分野をRNNが解消したという文脈で記載してます。
時系列を扱えるモデルが欲しい → RNNの登場!
そこで登場したのが、RNN(Recurrent Neural Network) です。
RNNは「文を左から右へ読み進めながら、内部の状態(メモリ)を持ちつつ処理できる」モデルです。
ざっくり言えば、「前に見た情報」を持ったまま、次の単語を処理するイメージです。
RNNの仕組み:内部状態を循環させて学習するネットワーク
RNNのコアとなる公式は以下になります:
$$
h_t = \tanh(h_{t-1} W_h + x_t W_x + b)
$$
ここでの各変数の意味は以下の通りです:
- $h_{t-1}$:1つ前の隠れ状態(これが「記憶」の役割を担います)
- $x_t$:現在の入力(単語ベクトルなど)
- $W_h, W_x$:それぞれの重み行列(学習されるパラメータ)
- $b$:バイアス
Affineレイヤで線形変換を行うときには、以下のようなイメージで重みとバイアスを使って推論されるんでしたよね。
$$
y = wx + b
$$
実はこれと同じことをしています。
具体的には、
- $h_{t-1} W_h$ は前の時系列の隠れ状態に重みをかけたもの
- $x_t W_x$ は現時系列での入力値に重みをかけたもの
となり、上記2値とバイアスの和を求めることで前時系列の情報を持ったまま学習ができるといった機構になっているのです。
ちなみに、tanh関数は上記で求めた値を非線形変換するために用いてます。
これによって、「 過去の文脈を受け継ぎながら、今の入力を解釈する構造」ができあがるのです!
tanh関数のような活性化関数は複数あり、Relu関数やSigmoid関数などがあります。
tanh関数は出力を-1〜1にして、正負の情報をバランスよく伝えることができるため、勾配が安定しやすいなどのメリットがありますが、最近はRelu関数がよく選択されるらしいです。
どうやら、tanh(sigmoid)関数はどちらも「S字型」で出力されることが原因で、極端な入力に対して出力が飽和して勾配が小さくなってしまうためRelu関数を選択するケースが増えている?らしいです。
Relu関数についてはこちらがわかりやすかったので参照してみてください。
ただし…長い文章はツラい:勾配消失&勾配爆発
ここまででRNNが時系列を含んだ学習ができることを解説しました。
ところが、コーパスが長〜い文章になると、RNNはうまく学習できなくなる問題が出てきてしまいます。。
逆伝播のときに何層も連続で重み行列をかけてしまうことで、勾配が小さくなりすぎてしまう(= 勾配消失)、または逆に大きくなりすぎてしまう(= 勾配爆発)ことがあるからです。
結果として、古い情報がうまく学習されなかったり、モデルが不安定になっちゃうといった問題点もあります。
対策:Truncated BPTT(時間方向のミニバッチ化)
勾配消失(爆発)を防ぐ対策方法はもちろんあります。
それが、Truncated Backpropagation Through Time(Truncated BPTT) というテクニックです。
簡単に言うと、時系列をバサッと切って、分割して学習させる方法です。
たとえば1000個のコーパスがある場合:
- 前半(1〜500)をまず処理
- 後半(501〜1000)を次に処理
のようにRNNの時間軸を区切って処理するのです。
これによって、問題の原因である何層にも渡って重み行列をかけてしまうことのリスクを減らしつつ、時系列情報をそれなりに保持できるようになります。
循環するRNN
ここまでで、RNNの概要と問題点、その解決方法を解説してきました。
なお、実際のRNN実装では、「時系列方向に伸びた構造(今回はTime RNN)」として実装されるのが一般的のようです。
イメージとしてはプログラミングでいうforやeachのようなものです。
単語ベクトルが時間に沿って流れていき、各ステップで同じ重みを使い回すことで、過去学習した内容を含めて効率的に学習ができるようになります。
では、次はTime RNNを用いて言語モデルを解説したいと思います。
Time RNNを用いた言語モデル(RNNLM)
本記事ではTime RNNを用いた言語モデルを、RNNLMとして呼ぶことにします。
※「ゼロから作るDeepLearning②」を参考にさせていただきました。
とはいっても、構造自体は単純です。
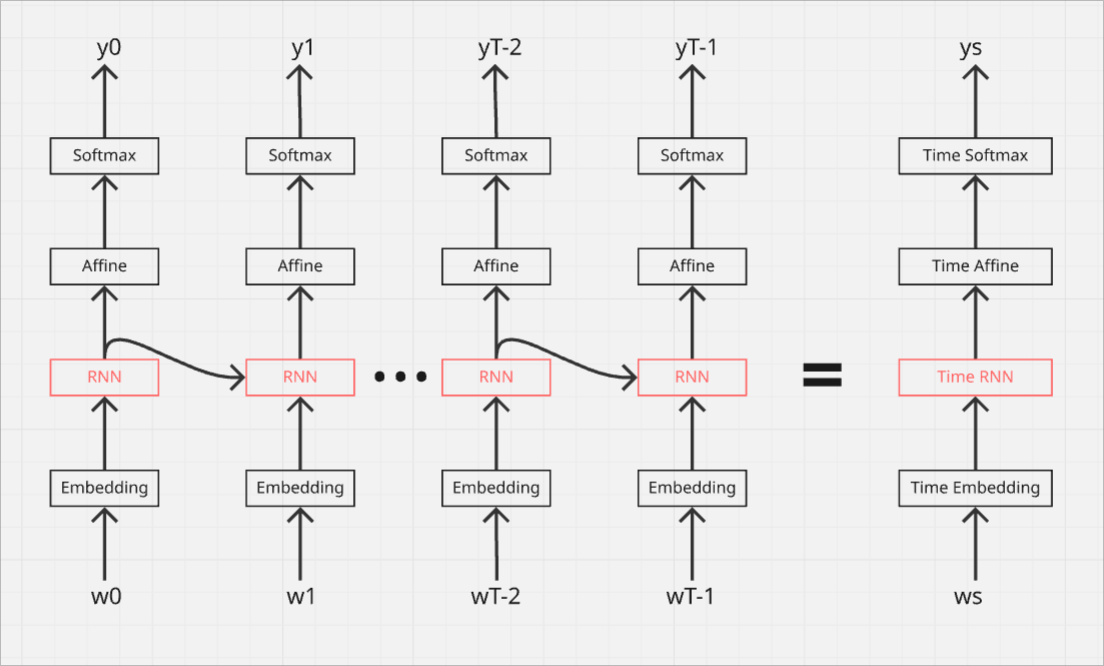
まず、$w_n$の部分は各単語に紐づくID情報となっています。
赤い:0
りんご:1
おばあちゃん:2のようなイメージです。
各単語IDはEmbeddingレイヤによって単語ベクトルに変換されます。
次に、RNNレイヤによって時系列を含んだ隠れ状態を学習します。
続いて、AfiineレイヤではRNNレイヤによって求めた分散表現を線形変換して、最後にsoftmax(with loss)レイヤによって確率分布と損失を求めています。
RNNLMの評価
では、上で解説したRNNLMを評価してみたいと思います。
と言いたいところですが、その前に言語モデルで予測精度を評価する指標である パープレキシティ(Perplexity) について解説してから、実際の予測結果を共有したいと思います。
パープレキシティ
パープレキシティは、言語モデルが次に来る単語を予測する際の困惑度合いを示す指標です。数値が低いほど、モデルがうまく予測できていることを意味します。
パープレキシティ(Perplexity)は言語モデルが次に来る単語をどれだけうまく予測できるかを測る指標で、簡単に言うと 言語モデルがどれくらい「困惑」しているか を示すものです。
この値が小さければ小さいほど精度が良いということになります。
具体的な式は以下になります。
$$
\text{Perplexity} = 2^{H(p)}
$$
$H_(p_)$はモデルに対するエントロピー(どれくらい不確実かどうか?)です。
つまり、テストデータ全体に対する平均的な対数尤度の損失を表します。
ただ、実はもっと簡単に求められます。
言語モデルによって、各ターゲットに対して確率分布を求めたと思います(softmax)。
このときの確率の逆数を求めればよいのです。
実際に求めてみましょう。
// サンプル: 言語モデルから求めた確率分布
A = [0.05 0.05 0.02 0.08 0.8]
B = [0.25 0.15 0.02 0.08 0.5]
正解が4番目の場合のパープレキシティは以下になります。
Aのパープレキシティ:1 / A[4](= 0.8) = 1.25
Bのパープレキシティ:1 / B[4](= 0.5) = 2.00
上で述べたとおり、パープレキシティは 言語モデルがどれくらい「困惑」しているか でした。
このときの求められた値の解釈は、「 次に来るであろう単語の数 」になります。
そのため、
- Aの場合はほぼほぼ1つの単語に決まっているのに対して、
- Bの場合はまだ2つの単語で迷っている
ということになります。
(正確には「正解ラベル」か「他のラベルのどれか」かで迷ってるイメージですが。。)
言語モデルではこのパープレキシティを各単語ごとに調べて、その平均から良し悪しを評価するようです。
RNNLMの評価 その2
では、パープレキシティの解説が終わったところでRNNLMの精度を求めてみましょう!
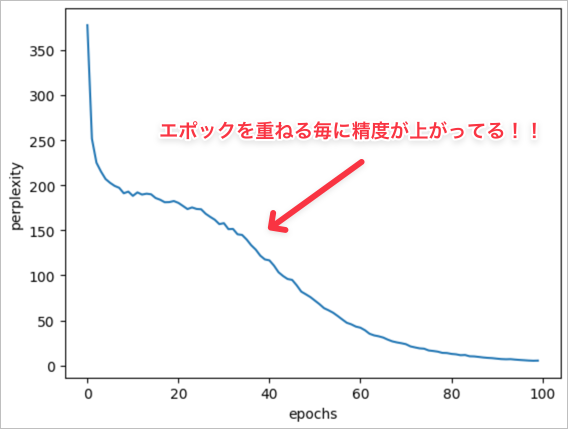
縦軸がパープレキシティ、横軸がエポックになります。
エポックが進むにつれて、パープレキシティの値が小さくなっているようなので、言語モデルとして精度が高くなっているようです!!
おわりに
前回のWord2Vec編に続いて、今回は「時系列データも扱える」RNN(再帰型ニューラルネットワーク)の仕組みについて解説してみました!
時系列を扱えるということは…?
そう、株価の予測、音声データの認識、そして言語翻訳など、様々な分野に応用できるんです!
こんなことができるなんて、ちょっとワクワクしませんか?!
本記事はゼロから作るDeep Learning 2を学習する中での備忘録も兼ねています。
この本は理論にしっかりフォーカスしながら、コードもセットで学べるのでとにかく楽しい!
本当にオススメの一冊なので、気になった方はぜひ手に取ってみてください〜!
これからも、RNNの改良版である ゲート付きRNN(例:LSTM) や、最近話題の Attention機構 など、さらに深掘りした内容を記事としてまとめていく予定です!!
最後まで読んでくださり、ありがとうございました!
もし記事が参考になったら、「いいね」と「ストック」をしてもらえるとすごく励みになります!
また、内容に誤りや気になる点があれば、遠慮なくご指摘していただけると嬉しいです!
他にもいろいろな記事を投稿しているので、もしよかったら見てみてください!
参考
RNNを理解するにあたって、以下の資料を参考にさせていただきました。
先人たちの知見に本当に本当に感謝です!