はじめに
LLMを実行するためのサンプルコードです。
コードは下記にあります。
https://github.com/toshi-4886/LLM/blob/main/notebook/4_perplexity.ipynb
概要
- perplexityでLLMを評価します。
- モデルはLlamaの小型モデルを使用します。
事前準備
- Hugging Faceのアカウント作成
- アクセストークンの作成
Hugging Faceのアカウントにログインし、「自分のアイコン→Settings→Access Tokens→+ Create new token」からトークンを作成します。
「Read access to contents of all public gated repos you can access」の権限が必要となります。 - Llamaの利用申請
Hugging Faceで使用したいモデルのページにアクセスして、必要事項を記入して申請します。
申請が承認されると利用可能になります。
Perplexity
言語モデルの性能を評価する方法の1つです。
次のトークンを予測する性能を測る指標になります。
トークン列$X = [x_0, x_1, ..., x_t]$、パラメータ$\theta$の言語モデルに関するperplexityは下記の通り定義されます。
$$
PPL(X) = \exp{-\frac{1}{t}\sum_i^t \log p_{\theta}(x_i|x_{<i})}
$$
ここで、$p(x_i|x_{<i})$はi番目より前のトークンを言語モデルに入力したときの、トークン$x_i$の生成確率です。
expの中は各トークンのcross entropyの平均になっています。
そこで、今回はAutoModelで計算されるlossを活用します。
実装
1. ライブラリのインポート
import sys
import os
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from transformers import AutoTokenizer, AutoModelForCausalLM
! pip install datasets
from datasets import load_dataset
import torch
2. 認証
Hugging Faceからモデルをダウンロードするために、アカウント認証を行います。
login()を実行するとトークンを入力するUIが出てくるので、そこにトークンを入力します。
また、colabのシークレットにトークンを保存しておけば、それを利用することもできます。
from huggingface_hub import login
# シークレットにトークンを保存しておけば下記で認証可能
from google.colab import userdata
login(token=userdata.get('HF_TOKEN'))
3. 推論と評価
モデルとトークナイザーをダウンロードします。
今回はLlama3.2の1Bモデルを使用します。
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-3.2-1B-Instruct",
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-1B-Instruct",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=False,
)
データセットをダウンロードします。
今回はメールのデータセットであるEnronを使用します。
Pileというデータセットに含まれていますが、大規模なデータセットのため、Enronだけを抽出したものを用います。
dataset = load_dataset("suolyer/pile_enron", split='test')
# データセットの内容を確認
print(dataset)
# データセットからテキストの情報を取得
sentences = dataset['text']
# 最初の文の先頭を表示
print(sentences[0][:1000])
perplexityを計算します。
そのために、入力と同じトークン列をラベルとして与えます。
そうするとcross entropyを計算することができます。
# 推論時間を計測
%%time
loss_list = []
with torch.no_grad():
# メモリが足りなくなるので、1サンプルずつ処理
for i in range(len(sentences)):
# メモリが足りなくなるので、長い文はスキップ
if len(sentences[i]) > 10000:
continue
token_ids = tokenizer(sentences[i], return_tensors="pt").to(model.device)
outputs = model(**token_ids, labels=token_ids["input_ids"])
loss_list.append(outputs.loss.item())
print(np.mean(np.exp(loss_list)))
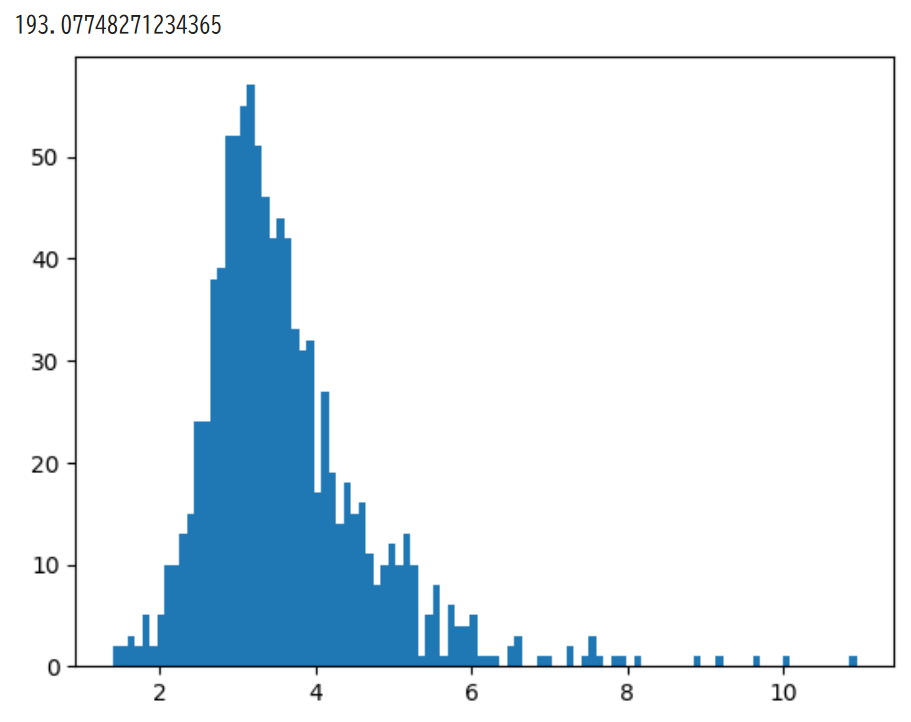
plt.hist(loss_list, bins=100)
plt.show()
おわりに
今回の結果
perplexityを計算することができました。
lossの分布を確認すると、予測がうまくいっている文と、そうでない文があることが分かります。
次にやること
LLMの性能を向上させる方法を試してみたいと思います。
参考資料
- meta-llama/Llama-3.2-1B-Instruct
https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct - suolyer/pile_enron
https://huggingface.co/datasets/suolyer/pile_enron - GPT-2を使って文のパープレキシティを計算する
https://gotutiyan.hatenablog.com/entry/2022/02/23/133414