2018年12月18日 追記:
2018年11月末のSageMakerのアップデートによって、TensorFlow(およびtf.keras)を利用する際にスクリプトモードと呼ばれる新しい手法が追加されました。この記事はレガシーモードと呼ばれる古いモードについての記述です。新しいスクリプトモードについては以下に別途投稿しましたのでこちらを参照下さい。
Amazon SageMaker で Keras を使用する(Script Mode)
概要
TensorFlowもKerasもたいして詳しくない私が、Amazon SageMakerの力を借りて、自前のモデルで画像分類を行うAPIを作成するまでに苦労した点の共有です。
SageMakerの日本語での情報はほとんどがビルトインアルゴリズムを使った方法についてのもので、対応フレームワークを使ってカスタムコードを利用したサンプルは少ないです。さらにKerasを使ったものは英語を含めても、ほとんど見当たらない状況です。
そんな状況なので、私のただの苦労話でも誰かの役に立つかもしれない。もしくはキチンとした知見のある人から適切なツッコミを受けられるかもしれない。というモチベーションでこの文章を書きました。
ちなみに結論から言うと、SageMaker使ってもTensorFlowやKerasの知識不足は補えません。結局、フレームワークについて知識が無いなら、大人しくビルトインアルゴリズムを使った方が良さそうです。
一方で、(矛盾するようですが、)ビルトインアルゴリズムも決して分かり易くはなく情報も少ないので、それなら開き直って情報がたくさんある有名フレームワークを勉強して使う、という選択もアリかもしれません。
SageMakerやKerasについては一通り知っている、という方は前置き飛ばして本文から読んで下さい。
また、手っ取り早くソースコードだけ読みたい方は最後にまとめましたので、そちらを参照下さい。
前置き
Amazon SageMakerとは
一言で言い表すのはなかなか難しいサービスですが、AWS公式の言葉を借りるなら、
Amazon SageMaker は、開発者やデータサイエンティストがあらゆる規模の機械学習モデルを短期間で簡単に構築、トレーニング、デプロイできるようにする完全マネージド型プラットフォームです。Amazon SageMaker を使用すると、通常、開発者による機械学習の足手まといになるような障壁をすべて取り除きます。
とのことです。
大量データの学習をしようと思ったらスペックの高いサーバが必要になります。学習後のモデルをデプロイしようと思ったら、これはこれでサーバが必要になります。そうした煩雑な環境構築をコンソール画面からボタン一発(もしくはAPIコール一発)で、環境が構築され、学習が終わると環境が自動で削除される。デプロイも自動で行ってくれる。もう少し具体的に言うとそんなサービスです。
SageMakerを使ったモデルの開発方法には以下の3種類があります。
- 用意されたビルトインアルゴリズムを使う
- 対応フレームワーク(Tensorflow/Chainer/PyTorch/MXNet)を使う
- 1.2.以外の方法(非対応フレームワークを使う、完全に手組みで作る、など)
番号が大きくなるほど大変で、1.は学習用データのみ、2.は学習用データと学習用コード、3.はそもそも学習環境となるコンテナのイメージが必要になります。
せっかくなら自分で組んだコードの学習をさせたい、と思ったので私は2の方法で実装することにしました。
Kerasとは
これも公式の言葉を借りると、
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです.
とのことです。
ざっくり言うと、TensorFlowなどのディープラーニングフレームワークを更に抽象化して、誰でも簡単に書けるようにしてくれるラッパーライブラリです。
私はTensorFlowの最初のMNISTの写経段階であまりの記述量にうんざりしていたところ、Kerasのシンプルさに魅了され、序盤しか読んでないTensorFlowの本を脇において鞍替えしました。
ちょこっとディープラーニング触ってみようかな、くらいのモチベーションであれば、圧倒的にKerasの方が取っつきやすいですし、「ディープラーニングって何なの?」という点も理解しやすいので、スタートはKerasがおススメです。
(逆にTensorFlowは最初に理解しなければいけないお約束が多くてしんどいです。placeholderがどうのとか。)
Keras で Amazon SageMaker を使用する
前述の通り、SageMakerの対応フレームワークはTensorFlow、Chainer、PyTorch、MXNetの4つで、Kerasは入っていません。
しかし、TensorFlowにはtf.kerasというTensorFlowにKeras APIの仕様を実装したコアパッケージが存在します。つまり、tf.kerasを使えば、Kerasの気軽さで組んだコードをSageMakerで学習させることができます。
私のような「とりあえず自分で組んだコードの学習をSageMakerでやってみたい」という人にとっては、まさにうってつけの方法です。と思いました。少なくともその時は。
本文1 とにかく学習させたモデルをデプロイするまで
KerasでSageMakerを使用するにあたり、まずはKeras単体で学習させたいコードを書き、これをSageMaker用に移植していく、というプロセスで進めることにしました。
なので、まずはせっせと学習用の画像を集め、ローカルでKerasに学習をさせます。
Keras単体で学習させたときのコード
以下がKeras単体で書いたときの画像分類モデルのコードです。この書籍の「5.2 小さなデータセットでCNNを一から訓練する」を参考にしました。
書籍では犬か猫かを判別する二値問題ですが、私がやりたかったのは20種類の画像の分類なので、最終的な出力層を20個に変更しました。また、多クラス単一ラベル分類問題なので、活性化関数はsoftmaxに、損失関数はcategorical_crossentropyに変更しました。この変更も同書籍の「表4-1 モデルの最後の層の活性化関数と損失関数の選択」を参考にしています。なお、ImageDataGeneratorのclass_modeもcategoricalとしています。
from keras import layers, models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
HEIGHT = 150
WIDTH = 150
DEPTH = 3
CLASS_NUM = 20
# モデルの定義
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(HEIGHT, WIDTH, DEPTH)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(CLASS_NUM, activation='softmax'))
# モデルのコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc']
)
# ImageDataGeneratorで画像を読み込み
train_datagen = ImageDataGenerator(rescale=1./255)
valid_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'hogehoge/training',
target_size=(HEIGHT, WIDTH),
batch_size=20,
class_mode='categorical'
)
validation_generator = valid_datagen.flow_from_directory(
'hogehoge/validation',
target_size=(HEIGHT, WIDTH),
batch_size=20,
class_mode='categorical'
)
# モデルの学習
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=10,
validation_data=validation_generator,
validation_steps=50
)
たったこれだけの記述量で立派な畳み込みニューラルネットワークが完成し、学習までできるのだから「Kerasすげぇ!」としか言いようがありません。
カレントディレクトリのhogehoge/配下にさらに学習用train/、検証用validation/、テスト用test/のディレクトリを作成し、画像を配置すれば、面倒な画像の読み込みや行列への変換などは全てImageDataGeneratorがやってくれます。まさに至れり尽くせりですね。
で、上記コードを実行すると、コンソールに以下のような表示がされて学習完了です。
Epoch 1/10
100/100 [==============================] - 127s 1s/step - loss: 2.1734 - acc: 0.2765 - val_loss: 1.4904 - val_acc: 0.5043
(中略)
Epoch 10/10
100/100 [==============================] - 132s 1s/step - loss: 0.0423 - acc: 0.9885 - val_loss: 0.1748 - val_acc: 0.9624
学習を終えた後は、学習過程のメトリクスがfit_generator()から返ってくるので、参考書籍ではこれをグラフにして学習の経過を確認したりしてますが、そこは割愛して推論を実行してみます。
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'race/test',
target_size=(150, 150),
batch_size=1,
class_mode='categorical'
)
for data, label in test_generator:
break
result = model.predict_on_batch(data)
テスト用画像の読み込みも面倒なのでImageDataGenratorを使います。
resultは各クラスの確からしさのベクトル、labelはその画像のクラスが1、それ以外が0のワンホットベクトルなので、resultで最も値の大きいindexと、labelが1になっているindexが合っていれば正解になります。
と、ここまでは参考書籍を読みながら、必要なところをちょこちょこ変更していくだけで特に苦労することはありません。
SageMakerにコードを移植
ローカルで動くモデルが出来たので、これをSageMakerに移植していきます。
まず、SageMaker Python SDK のGithubリポジトリにカスタムコードの書き方の解説があるので、これを読みます。(が、長くて途中で挫折します。)
https://github.com/aws/sagemaker-python-sdk/blob/master/src/sagemaker/tensorflow/README.rst
また、SageMakerの使い方のサンプルとして、AWSからJupyter Notebookとエントリポイント用のPythonスクリプト(いわゆる学習用コード)が提供されていますので、これも参考にします。
サンプルコードはSageMakerで起動したJupyter Notebookから確認することができます。または、Githubにも公開されています。tf.kerasを使ったサンプルはtensorflow_keras_CIFAR10.ipynbです。
https://github.com/awslabs/amazon-sagemaker-examples/tree/master/sagemaker-python-sdk/tensorflow_keras_cifar10
なんだか「Kerasのコードをまるっと移植すればOK」というほど単純なものではなく、若干雲行きが怪しくなってきましたが、基本的にはこのサンプルと前述のKeras単体で動く私が書いたコードをうまくマッシュアップできれば、KerasでSageMakerが動くはずです。
SageMakerでカスタムコードを動かすには、SageMaker SDKをキックするJupyter Notebookと学習用コードとなるPythonスクリプトの2つが必要になります。
モデルの定義とデータ編集(学習用コード)
まずは学習用コードの記述から始めます。
学習用コードには最低限以下の関数の記述が必要になります。
| 関数名 | 役割 |
|---|---|
| model_fn() or keras_model_fn() or estimator_fn() |
モデルの定義を行う関数 (tf.kerasを使う場合はkeras_model_fn()を 利用してモデル定義を行う必要がある) |
| train_input_fn() | 訓練用データの編集を行う関数 |
| eval_input_fn() | 検証用データの編集を行う関数 |
| serving_input_fn() | ? |
最後のserving_input_fn()はドキュメントには「In addition, it may optionally contain」と記載されており、must containでは無さそうなのですが、色々試した結果この関数も入れないと動きませんでした。ドキュメントを読んでもソースを読んでもイマイチ何のための関数か、どこで呼ばれているかもわからなかったです。とりあえずサンプルのままで大丈夫だったので、そこはそのままです。
さて、上の表に書いた通りの役割分担なので、元のKeras単体のコードから、それぞれモデル定義の部分、データ編集を行う部分をそれぞれの関数に配置すれば良さそうです。
from tensorflow.python.keras import layers, models
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.training.rmsprop import RMSPropOptimizer
CLASS_NUM = 20
HEIGHT = 150
WIDTH = 150
DEPTH = 3
INPUT_TENSOR_NAME = 'inputs_input'
# model definition
def keras_model_fn(hyperparameters):
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), padding='same', name='inputs', input_shape=(HEIGHT, WIDTH, DEPTH), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(CLASS_NUM, activation='softmax'))
opt = RMSPropOptimizer(learning_rate=hyperparameters['learning_rate'])
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
return model
# input for serving
def serving_input_fn(hyperparameters):
tensor = tf.placeholder(tf.float32, shape=[None, HEIGHT, WIDTH, DEPTH])
inputs = {INPUT_TENSOR_NAME: tensor}
return tf.estimator.export.ServingInputReceiver(inputs, inputs)
def _input_fn(data_dir, input_shape, batch_size):
datagen = ImageDataGenerator(rescale=1./255)
generator = datagen.flow_from_directory(
data_dir,
target_size=input_shape,
batch_size=batch_size,
class_mode='categorical'
)
gen_fn = lambda: generator
dataset = tf.data.Dataset.from_generator(
gen_fn, (tf.float32, tf.float32),
output_shapes=(
[batch_size, HEIGHT, WIDTH, DEPTH],
[batch_size, CLASS_NUM]
)
)
images, labels = dataset.make_one_shot_iterator().get_next()
return { INPUT_TENSOR_NAME: images }, labels
def train_input_fn(training_dir, hyperparameters):
return _input_fn(
training_dir + '/training/',
(HEIGHT, WIDTH),
hyperparameters['batch_size']
)
def eval_input_fn(training_dir, hyperparameters):
return _input_fn(
training_dir + '/validation/',
(HEIGHT, WIDTH),
hyperparameters['batch_size']
)
結果、学習用コードは上記のようになりました。元のコードではfit_generator()にデータジェネレータをそのまま渡していたのですが、SageMakerではそれが出来ないようなので、サンプルコードを参考にしてgeneratorをdatasetに変換する処理をデータ編集に追加しています。また、インポートがkerasではなく、tensorlow.python.kerasに変更になっています。あと、学習用コードは日本語コメントが付けられません。マルチバイト文字が受け付けられないようです。
ちなみに、さらっと書いてますが、ただ上記の変更を入れるまでに結構時間がかかっています。entry_point内のコードはSageMaker SDKから呼び出されるようですが、どんなタイミングでどのように呼び出されるのか、処理の全体像が全然掴めないので苦労しました。Keras単体で動かしたときはあんなに簡単だったのに…
あと、残念な話ですが学習用コードはPython 2.7系で動きますので、そのつもりで記述する必要があります。(SageMaker SDK側からPythonのバージョンを指定するpy_versionという引数があるのですが、3.6を指定するとエラーになります。TensorFlowの場合は未対応だそうです。)
学習コードを実行 (Jupyter Notebook)
Jupyter Notebookの方はほとんどサンプルのままで良さそうです。サンプルから余計な部分を削除して以下のようにしました。SageMakerが自動的に専用バケットを作ってくれるので、そこに学習用の画像を格納しておきます。
import boto3
import json
import os
from sagemaker import Session, get_execution_role
from sagemaker.tensorflow import TensorFlow
from sagemaker.session import s3_input
sagemaker_session = Session()
sagemaker_role = get_execution_role()
SAGEMAKER_BUCKET = sagemaker_session.default_bucket()
# s3上の画像の置き場のprefix
TO_PREFIX = 'hogehoge/image'
S3_INPUT_PATH = 's3://{0}/{1}/'.format(SAGEMAKER_BUCKET, TO_PREFIX)
print(S3_INPUT_PATH)
# 学習の実行
hyper_param = {
'batch_size':20,
'learning_rate': 1e-4,
}
estimator = TensorFlow(
entry_point='entry_point_simple_cnn.py',
role=sagemaker_role,
framework_version='1.11.0',
train_instance_count=1,
train_instance_type='ml.p3.2xlarge',
training_steps=1000,
evaluation_steps=100,
hyperparameters=hyper_param
)
estimator.fit(s3_input(S3_INPUT_PATH))
上記で準備が出来たので、その前に用意した学習用コードを用いてモデルの学習を行います。
Notebookからestimator.fit()を実行すると、学習用のインスタンスが別途立ち上がり、学習用のデータをS3上からインスタンス上にダウンロードし、その後にようやく学習用コードが実行されます。インスタンス起動とデータダウンロードに結構な時間がかかるため、学習用コードに凡ミス(タイポとか)があってエラーになると、待ち時間がパーになり結構落ち込みます。ここら辺のトライ&エラーのし辛さは何とかならないものか…
学習用コードに不備が無ければ、(初見の人は必ずびっくりするであろう大量のログを吐いた後、)学習が完了します。学習が完了すると学習用インスタンスは自動で停止されます。ここまでがestimator.fit()の仕事です。
デプロイと推論を実行 (Jupyter Notebook)
学習が終わったので、モデルをデプロイして推論を実行します。モデルのデプロイはサンプルのままで特に変更点はありません。
この処理を行うと、エンドポイント設定とエンドポイントが作成されます。エンドポイントは起動時にはお金がかかるので、使わないときは削除する必要があります。一方、エンドポイント設定はあくまで設定なのでお金がかかりません。一度、エンドポイントを削除してしまっても、エンドポイント設定が残っていれば、その設定を利用して同じエンドポイントを立ち上げることができます。
# モデルのデプロイ
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.t2.medium')
推論の実行はサンプル通りにいきません。というかサンプルの方は「Prediction is not the focus of this notebook,」と、なぜか説明を放棄してランダムなnumpy行列を入力に推論を実行しています。全く参考になりません。
トライ&エラーを行った結果、TensorProtoという型で画像を渡してやれば良いということがわかったので、以下のようにコードを変更します。ついでに、matplotlibで推論対象の画像を表示する処理も追加しました。
# 推論対象の画像の読み込みと表示
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from PIL import Image
import io
file_stream = io.BytesIO()
# 推論対象の画像もS3上に置いてあるものを使う
s3 = boto3.client('s3')
s3.download_fileobj(SAGEMAKER_BUCKET, TO_PREFIX + '/test/001/001.jpg', file_stream)
img = Image.open(file_stream)
# 画像の表示
plt.imshow(img)
plt.show()
# Numpy行列を経由してTensorProtoに変換
image_array = np.asarray(img.resize((HEIGHT,WIDTH)))
image_array = image_array.reshape((1,) + image_array.shape)
image_tp = tf.make_tensor_proto(
values=np.asarray(image_array),
shape=[1, HEIGHT, WIDTH, DEPTH],
dtype=tf.float32
)
# 推論実行
predictor.predict({'inputs_input': image_tp})
これでエンドポイントから以下のような推論結果が得られます。float_valが出力層の値ですね。
{
'outputs': {
'dense_1':{
'dtype': 1,
'tensor_shape': {
'dim':[
{'size': 1},
{'size': 20}
]
},
'float_val': [
1.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0
]
}
},
'model_spec': {
'name': 'generic_model',
'version': {'value': 1542029834},
'signature_name': 'serving_default'
}
}
Boto3経由で外部から推論を実行(Lambda関数)
上記で推論の実行は出来ているのですが、全てJupyter Notebook上の話です。実際にサービスとして展開する場合には、Jupyter Notebook上で動かすわけにはいきません。
そこで、上記で作ったエンドポイントをLambdaから呼び出して使えるようにします。
推論の実行はboto3にも関数が用意されているので以下で簡単に実行できます。
import boto3
sage = boto3.client('sagemaker-runtime')
response = sage.invoke_endpoint(
EndpointName='<エンドポイント名>',
Body='<推論対象画像を変換したTensorProto>',
)
responseの中身は以下のようになっていますが、最後の'Body'をread()すると前述の推論結果のJSONと同じものが入ってます。
{
'ResponseMetadata': {
'RequestId': '950cfdb7-a4a2-423a-9eed-d754a192fe17',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'x-amzn-requestid': '950cfdb7-a4a2-423a-9eed-d754a192fe17',
'x-amzn-invoked-production-variant': 'AllTraffic',
'date': 'Mon, 19 Nov 2018 04:04:09 GMT',
'content-type': '*/*',
'content-length': '660'
},
'RetryAttempts': 0
},
'ContentType': '*/*',
'InvokedProductionVariant': 'AllTraffic',
'Body': <botocore.response.StreamingBody at 0x7f8474250390>
}
で、「あー、これなら簡単ですねー。」と思うところですが、このロジックを入れてLambda関数としてデプロイしようとすると、パッケージの容量制限でエラーとなってしまいます。
画像をTensorProtoに変換するために、numpyとtensorflowをimportしているのですが、この2つのライブラリ(特に後者)のサイズが大き過ぎて、Lambda関数の60MBという上限を超えてしまうからです。
そもそも、推論のエンドポイントとして公開するのであれば、エンドポイントを呼び出す側が画像をTensorProtoに変換するのではなく、呼び出されるエンドポイント側で受け取った画像を内部で必要な形に変換するべきですよね。
という事で、どうにかする方法はないものかと途中で挫折した公式ドキュメントをちゃんと読むと、そういう用途の処理がきちんと用意されていました。
推論実行時の入出力の編集(学習用コード)
SageMaker Python SDK のドキュメントを確認すると、SageMakerエンドポイントの推論リクエストに対する処理は以下の順に行われるようです。
- input processing
- TensorFlow Serving prediction, and
- output processing
1でエンドポイント外部から受け取った入力(JSON)をデシリアライズして、2で推論を実行して、3で推論結果を再度シリアライズして外部に返却するという手順ですが、この1,3の処理を学習用コード(エントリポイント)に記述した関数で上書きすることができます。input_fn()で入力値の処理の上書き、output_fn()で返却値の処理の上書きです。
今回のケースで言うと、input_fn()に画像データを受け取った後にTensorProtoに変換する、という処理を記述してやれば良さそうです。以下のような記述を追加しました。
def input_fn(serialized_data, content_type):
byte_pickled_image = serialized_data.encode()
pickled_image = base64.b64decode(byte_pickled_image)
image = pickle.loads(pickled_image)
image_array = np.asarray(image.resize((HEIGHT,WIDTH)))
image_array = image_array.reshape((1,) + image_array.shape)
return {
INPUT_TENSOR_NAME : tf.make_tensor_proto(
values=np.asarray(image_array),
shape=[1, HEIGHT, WIDTH, DEPTH],
dtype=tf.float32
)
}
前半部分に今までなかったコードがありますが、これは画像をJSON形式でエンドポイントに渡すための苦肉の策です。画像読み込みから推論実行まで、以下のような変換処理を辿ります。1.~5.までが呼び出し側(今回はLambda関数)、6.~9.が今回input_fnに記述した処理になります。
- 画像をPIL形式で読み込み
- 1.をpickleでバイナリオブジェクトに変換
- 2.をbase64形式にエンコード
- 3.を文字列(utf-8)にデコード
- 4.の文字列を引数にエンドポイント実行
- 4.の文字列をバイト列にエンコード
- 6.のバイト列をbase64形式でデコード
- 7.のバイナリオブジェクトをpickleで復元
- 8.の画像データをTensorProtoに変換
何かもっとスマートな方法がありそうな気もしますが、それを追求するのは今回の目的ではないのでこのまま進めます。とにかくこれで、Lambda関数からエンドポイント実行が可能になりました。
ちなみに、前述したように学習用コードはPython 2.7系で動きますので、Lambda関数が3.6系で書かれている場合は、pickle.dumpsする際に、protocol=2の指定が必要になります。
本文2 学習過程の確認 (TensorBoard、エポック)
さて、ここまではとりあえず組み込み優先でやっていたので、あまり考えていませんでしたが、そもそもこのモデルは正しく学習が行えているのでしょうか。というか、SageMakerでは学習の過程をどのように確認したら良いのでしょうか。
改めて、Kerasのfit()とSageMakerのfit()を見比べると疑問が湧いてきます。
- Kerasの方では学習過程を
fit()の返り値として受け取ることができたが、SageMakerではどうしたら良いか? - Kerasの方では
fit()の引数としてEpochを指定することができたが、SageMakerではどうしたら良いか?
まず、1.については公式ドキュメントを読むと割と早い段階でわかります。SageMakerでfit()を実行すると、前述の通り「初見の人は必ずびっくりするであろう大量のログ」が吐かれるのですが、このログにたまにlossやaccuracyといった指標が書き込まれます。で、このログは自動的にCloudWatchにも出力されているので、このCloudWatch上のログを何らかの手段で解析するか、TensorBoardを使って解析するかです。
CloudWatchの解析は面倒なので、TensorBoardを使う方法を選択します。TensorBoardを使うのは非常に簡単で、fit()の引数にrun_tenosorboard_locally=Trueを追加するだけです。これでfit()を実行すると、SageMakerのノートブックインスタンス上にTensorBoardが立ち上がります。例えば、ノートブックインスタンス名がtestinstance、リージョンが東京だとすると、http://testinstance.notebook.ap-northeast-1.sagemaker.aws/proxy/6006/にアクセスすることでTensorBoardがブラウザに表示されます。6006というポート番号は実行状況によっては別のものになる可能性がありますが、fit()実行時にメッセージとして使用ポートが表示されるのでそこを参照すれば大丈夫です。
次に2.のEpochですが、(公式ドキュメントからは明確な記述を発見できなかったので私個人の意見になりますが、)明示的にEpochを指定する方法は無いようです。というか、Epochという概念がそもそも無いようです。ここら辺を説明するには、少し前置きが必要になります。
tf.estimators
TensorFlowには、High LevelなAPIとLow LevelなAPIがあります。ここでいうHigh-Lowとは、抽象的で簡単に使えるか、細かくて難しいけど詳細な設定ができるか、くらいの意味合いです。もともと、TensorFlowはかなりLow Levelなライブラリでした(だからKerasみたいなものが生まれるワケで。)が、ここ2-3年(?)でHigh LevelなAPIも整備されてきているようです。(Kerasがtf.kerasとして取り込まれたのもその一環だと思われます。)そして、そのHigh Level APIの一つが、tf.estimatorsです。
Estimators
This document introduces tf.estimator—a high-level TensorFlow API that greatly simplifies machine learning programming. Estimators encapsulate the following actions:
- training
- evaluation
- prediction
- export for serving
You may either use the pre-made Estimators we provide or write your own custom Estimators. All Estimators—whether pre-made or custom—are classes based on the tf.estimator.Estimator class.
上記はTensorFlow公式のIntroduction to Estimatorsというセクションの引用です。
訓練、評価、推論、エクスポートをカプセル化して機械学習をシンプルに実行できるようにする。プリメイドのモデルか自分自身で構築したモデル、どちらも使うことができる。なんかSageMakerのやっていることと似てますね。
で、どうやらTensorFlowをSageMakerで動かすと、このtf.estimatorsが内部で使われているようなのです(SageMaker Python SDKがtf.estimatorsをさらにラッピングしているイメージ)。ここら辺、元々TensorFlowを触っていた人なら、SageMakerの説明を読んだだけでピンと来たのかもしれませんが、私のようなSageMakerから入った人間には、なかなかイメージし辛いものがあります。ここら辺が各フレームワークの知識が無いとSageMakerを使うのは難しいなと感じる点です。
トレーニングステップ、エポック
Kerasのfit()では、訓練と評価は直列で実行されています。引数steps_per_epochで指定された回数だけ訓練を行い、その後引数validation_stepsで指定された回数だけ評価を行います。訓練→評価の1セットを1エポックと呼び、引数epochsで指定された回数だけ訓練→評価を繰り返します。
一方、SageMakerのfit()では訓練と評価は独立して実行されているようです。
tf.estimatorsには訓練と評価を実行するtrain_and_evaluate()というメソッドがあり、SageMakerのfit()内ではこのメソッドを利用していると思われます。train_and_evaluate()は分散環境で学習と評価を実行するためのメソッドのため、訓練と評価を独立したプロセスで実行します。つまり訓練が終わったら評価というような順番の処理になりません。そのため明示的なEpochの指定が無いのだと考えられます。
では、どのタイミングで評価が行われるかというと、訓練の最中にCheckpointが作られた後に評価が実行されるようです。
CheckpointとはEstimatorの訓練途中、任意のタイミングで作られる学習途中のモデルのバージョンです。訓練途中に作られたCheckpointを使えば、訓練途中のモデルの評価ができますし、訓練の全ステップが完了した後に作られたCheckpointを使えば、学習後の推論ができます。また、途中で学習を止めて後から再実行する、というようなこともできるようです。
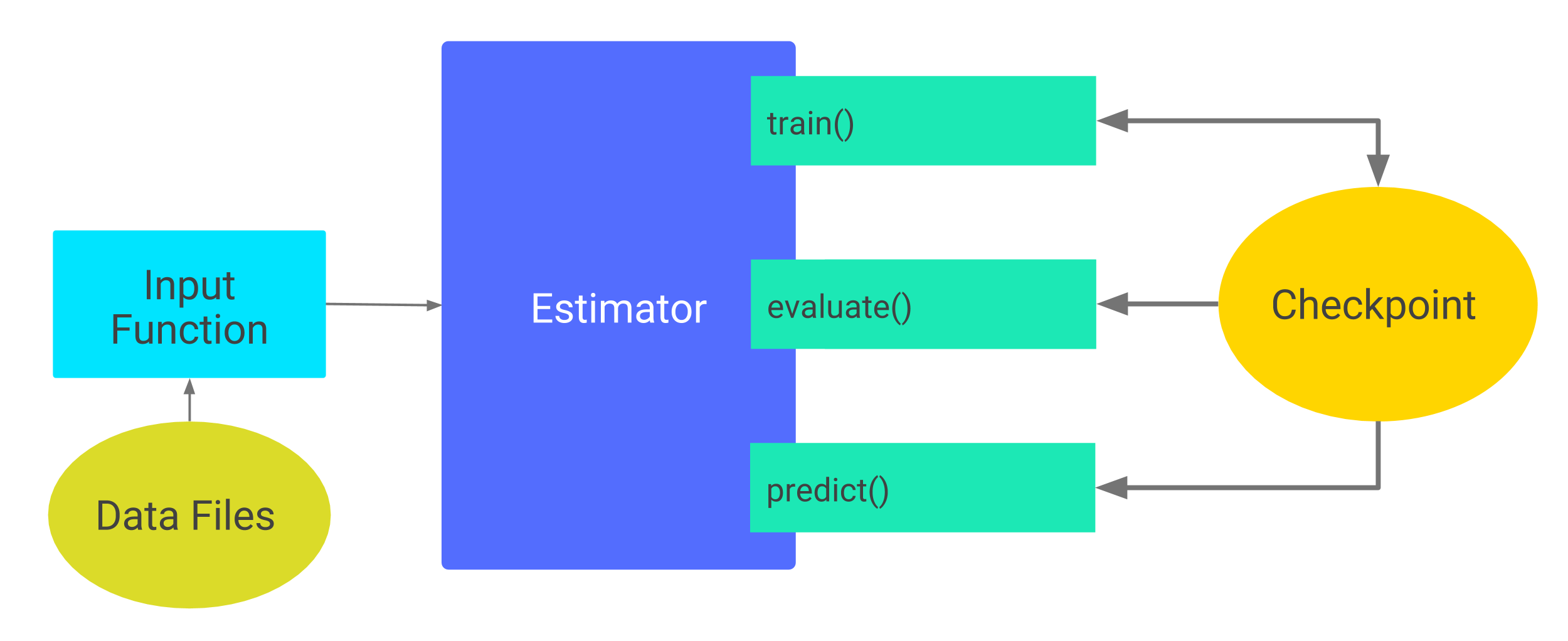
上図はTensorFlow公式のEstimator Checkpointについての図です。train()-Checkpoint間の相互の矢印、Checkpointからevaluate()、predict()への矢印が伸びていることがわかると思います。
SageMakerのfit()が実行されると、訓練のプロセスが起動し引数training_stepsで指定された回数だけ訓練を繰り返します。その途中一定のタイミングでCheckpointが作成されます。評価のプロセスではCheckpointが作成されるまで監視をしており、Checkpoint作成後一定時間経過後に作成されたCheckpointを使って評価を行い、その結果をログに吐き出します。
上記の「Checkpointが作成される一定のタイミング」と「Checkpoint作成後に評価実行するまでの一定時間」は、デフォルトでは両方とも「10分」となっており、これを変更するにはSageMakerでEstimatorを定義する際にハイパーパラメータで指定する必要があります。
デフォルト設定のまま小さいデータセットで学習を動かすと10分経過する前に学習が終わってしまう場合があります。この場合、当然評価は行われずログにもTensorBoardにも何にも表示されません。
私は今回の検証でこの現象に一番苦労しました。偶然、SageMakerではなく本家TensorFlowのGithubリポジトリのIssuesに「Allow tf.estimator.train_and_evaluate evaluation frequency in stepsというポストがあるのに気づき、そこでようやく全体の動きが把握できました。
結果として、Fit実行前のハイパーパラメータ指定を以下のように変更して、ようやく評価のタイミングをコントロールできるようになりました。あとはTensorBoardで学習曲線を見ながら適切なStep数で学習を行えば、OKです。
hyper_param = {
'batch_size':20,
'learning_rate': 1e-4,
'save_checkpoints_secs' : None,
'save_checkpoints_steps' : 100,
'throttle_secs': 0,
}
'save_checkpoints_steps'が訓練中にCheckpointを作成するタイミングの指定です。100を指定したので、100回訓練を行うごとにCheckpointを作成します。
'throttle_secs'がCheckpoint作成後に評価実行するまでの時間の指定です。0を指定したので、Checkpoint作成後即時に評価が実行されます。
これでEstimator定義時にパラメータでtraining_steps=1000と指定してやれば、トータル1000ステップ中、100回ごとに計10回の評価が行われます。これはKerasのfit()でEpochs=10、step_per_epoch=100と指定するのと同義です。これで間接的にではありますが、任意のEpochごとの学習の過程を確認することができるようになりました。
なお、上記のハイパーパラメータで'save_checkpoints_secs': Noneの指定がありますが、これを入れないとエラーになるので注意が必要です。checkpoint作成のタイミングは秒指定、ステップ指定どちらもできますが、どちらか一方にする必要があります。前述の通り、デフォルトでは10分なのでこちらが指定をしていなくても、裏では'save_checkpoints_secs': 600という指定がされた状態になっています。そのため、ユーザが'save_checkpoints_steps'だけを指定すると、裏では両方設定された扱いになりエラーになります。これを防ぐためにユーザ側からあえて、'save_checkpoints_secs': Noneを指定して上書きしてやらなければなりません。
本文3 残る謎
ここまででとりあえず、そこそこの精度を持つ画像分類のAPIを作成することができました。が、全ての謎が解決したわけではありません。以下2点が最後まで謎のままでした。
TensorBoardで別のメトリクスを確認するにはどうしたら良いのか?
これまでの設定でTensorBoardで確認できるメトリクスはeval_accuracy、eval_loss、train_lossの3つです。eval_accuracyが見られるので、だいたい学習が進んでるのかどうかぐらいはわかるんですが、実際に学習後にテスト画像の推論を行うと、どうもeval_accuracyほど正答率が高くありません。
これの原因が色々考えても過学習ぐらいしか思い当たらないのですが、train_accuracyが確認できないので何とも判断が付きません。そして残念ながらtrain_accuracyを追加する方法がわかりません。
推論結果のラベルはどこで設定するべきなのか?
推論エンドポイントのアウトプットは、デフォルトだとモデルの出力層の値がそのまま出てきます。出力層の値は、(当たり前ですが、)訓練データのラベルと同じ形式の出力になります。
例えば、分類する画像が犬、猫、鳥の3種類でそれぞれ/dog、/cat、/birdというディレクトリに格納されていたとします。そうするとImageDataGeneratorがディレクトリ名を名前順に並べてラベルを自動的に付けます。つまり、bird、cat、dogの順なので、もし猫の画像であればラベルは[0, 1, 0]、犬の画像であれば[0, 0, 1]になります。推論結果が[1, 0, 0]であれば、その画像は鳥の画像だと推論されていることになります。
エンドポイントとして公開することを考えると、[1, 0, 0]という結果が返ってくるより、birdという結果が返ってきた方が断然親切です。というか、入力画像をTensorProtoに変換する処理をエンドポイント側でやったように、出力結果をラベルのテキストに変換する処理もエンドポイント側でやるべきだと思います。そして、入力の時と同様に、output_fn()という関数を学習用コードに記述すれば、推論結果の編集処理を上書きすることができます。
しかしそうすると、「ではこのラベルの情報はどこから取ってきてやればいいのか」という問題が残ります。前述した通り、ラベルはImageDataGeneratorが自動で振ってくれます。なので、ImageDataGeneratorのインスタンスが存在している場合は、そのインスタンスのCLASS_INDICESというメンバから直接ラベルの文字列を取得することができます。(例えば、前述の例であれば、['bird', 'cat', 'dog']というリストを取得できます。)しかし、ImageDataGeneratorのインスタンスが存在するのは訓練、評価を実行している時だけで、推論を実行する際には存在しません。そのため、CLASS_INDICESから値を取ることができません。
では、もうoutput_fn()に固定でラベルの値を持てばいいではないか、という案もありますが、これも微妙な気がします。学習用コードでは外側から受け取ったディレクトリ内にある画像に対して、ラベルを付けて学習します。つまり、学習用コードそのものには、画像にどんなラベルが付いていても関係がありません。学習用に用意された画像が/bird, /cat, /dogであっても、/horse, /monkey, /pandaであっても、本来学習用コードに変更を加える必要はありません。しかし、output_fn()に固定でラベルを持ってしまうと、画像の種類ごとに学習用コードを変更しなくてはいけなくなってしまいます。
後書き
以上がKerasでSageMakerを動かす際に苦労したポイントです。こうして書き出すと、単純にSageMakerはまだまだ枯れ切っていないライブラリなので苦労するのは仕方ないという気がしてきます。そもそもTensorFlow自体がかなり動きの激しいライブラリなので、それを利用するSageMakerにもさらに激しい変更が加わっているというのが実情かと思います。
今回、私が検証を行っている間にも、Kerasのサンプルがガラっと変わったり、ドキュメントの構成が変わってこないだまで読んでた情報がどこかに行ってしまったり、ということが多々ありました。最初に私がSageMakerとKerasを触りだしたのは3か月ほど前でしたが、(私の記憶が確かなら、)その時点のKerasのサンプルはコピペしてもエラーが出て動かない状態だったと思います。
あとは、本文中にも書きましたが、とにかくトライ&エラーに時間がかかるのが最大のネックでした。fit()実行して、訓練用コンテナが立ち上がって、訓練用画像ダウンロードし終わって、初めてこちらで書いた学習用コードが動くので、イニシャルコストが大きいです。さらにいうと、input_fn()、output_fn()に至ってはエンドポイントが呼び出されて初めて動くロジックなので、モデルの学習が終わった後、さらにエンドポイントのデプロイが終わって、ようやく試すことができます。
一応、トライ&エラーにかかる時間を短くする策として2つ手段が用意されています。Pipeモードとローカルインスタンスです。
Pipeモードは、学習用データの渡し方のオプションです。デフォルトではS3にある全ての学習用画像を、学習用インスタンスにダウンロードしてから学習を始めますが、Pipeモードを選択するとデータをS3から取得しながら学習を行うことになり、ダウンロードの時間を短縮することができます。
もう一つのローカルインスタンスは、学習用のインスタンスを別途立てるのではなく、ノートブックインスタンス上で学習をさせるオプションです。これにより学習用インスタンスを立ち上げる必要がなくなりイニシャルコストが短縮できます。特に今回のように学習用コードが正しく動くかといった確認用にはちょうど良いオプションだと思います。
Pipeモードもローカルインスタンスもまさに私のような人間にうってつけのオプションなのですが、なぜかどちらもエラーが出て動かすことができませんでした。さすがにトライ&エラーのコストを下げるために、さらにトライ&エラーする気は起きず…この2つも残った謎ですね。
ちなみに、これはサンプルのJupyter Notebookにも記述されていることですが、本来SageMakerのfit()はインスタンスを複数用意して分散学習させることが可能です。(というか、そのためにtf.estimatorを使っているはず。)しかし、KerasでSageMakerを動かす場合は、Issueがあって複数インスタンスは指定できず、インスタンス数は1固定になります。これを知った時には、じゃあ、何のためにtf.estimatorなんで面倒なもの使ってるんだ…とがっかりしました。何か他にもKerasの場合はダメ、というのがあった気がしたのですが、ちょっと失念してしまいました。
これからのSageMakerのアップデートに期待しています。
ソースコード
最後に今回の検証で記述したソースコードの最終形をまとめておきます。
学習用コード
import tensorflow as tf
import numpy as np
import io
import base64
import pickle
import json
from PIL import Image
from tensorflow.python.keras import layers, models
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.training.rmsprop import RMSPropOptimizer
from tensorflow.python.framework import tensor_util
CLASS_NUM = 20
HEIGHT = 150
WIDTH = 150
DEPTH = 3
INPUT_TENSOR_NAME = 'inputs_input'
# model definition
def keras_model_fn(hyperparameters):
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), padding='same', name='inputs', input_shape=(HEIGHT, WIDTH, DEPTH), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(CLASS_NUM, activation='softmax'))
opt = RMSPropOptimizer(learning_rate=hyperparameters['learning_rate'])
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
return model
# input for serving
def serving_input_fn(hyperparameters):
tensor = tf.placeholder(tf.float32, shape=[None, HEIGHT, WIDTH, DEPTH])
inputs = {INPUT_TENSOR_NAME: tensor}
return tf.estimator.export.ServingInputReceiver(inputs, inputs)
def _input_fn(data_dir, input_shape, batch_size):
# logging.info('_input_fn data_dir: {0}'.format(data_dir.split('/')[-2]))
datagen = ImageDataGenerator(rescale=1./255)
generator = datagen.flow_from_directory(
data_dir,
target_size=input_shape,
batch_size=batch_size,
class_mode='categorical'
)
gen_fn = lambda: generator
dataset = tf.data.Dataset.from_generator(
gen_fn, (tf.float32, tf.float32),
output_shapes=(
[batch_size, HEIGHT, WIDTH, DEPTH],
[batch_size, CLASS_NUM]
)
)
images, labels = dataset.make_one_shot_iterator().get_next()
return { INPUT_TENSOR_NAME: images }, labels
def train_input_fn(training_dir, hyperparameters):
return _input_fn(training_dir + '/training/', (HEIGHT, WIDTH), hyperparameters['batch_size'])
def eval_input_fn(training_dir, hyperparameters):
return _input_fn(training_dir + '/validation/', (HEIGHT, WIDTH), hyperparameters['batch_size'])
# Overriding input preprocessing for image to tensor_proto
def input_fn(serialized_data, content_type):
byte_pickled_image = serialized_data.encode()
pickled_image = base64.b64decode(byte_pickled_image)
image = pickle.loads(pickled_image)
image_array = np.asarray(image.resize((HEIGHT,WIDTH)))
image_array = image_array.reshape((1,) + image_array.shape)
return { INPUT_TENSOR_NAME : tf.make_tensor_proto(values=np.asarray(image_array), shape=[1, HEIGHT, WIDTH, DEPTH], dtype=tf.float32) }
Jupyter Notebook
ライブラリのインポート
import boto3
import json
import os
from sagemaker import Session, get_execution_role
from sagemaker.tensorflow import TensorFlow
from sagemaker.session import s3_input
sagemaker_session = Session()
sagemaker_role = get_execution_role()
SAGEMAKER_BUCKET = sagemaker_session.default_bucket()
# s3上の画像の置き場のprefix
TO_PREFIX = '<S3上の画像格納場所のパス>'
S3_INPUT_PATH = 's3://{0}/{1}/'.format(SAGEMAKER_BUCKET, TO_PREFIX)
print(S3_INPUT_PATH)
トレーニングの実行
hyper_param = {
'batch_size':20,
'learning_rate': 1e-4,
'save_checkpoints_secs' : None,
'save_checkpoints_steps' : 100,
'throttle_secs': 0,
}
estimator = TensorFlow(
entry_point='entry_point.py',
role=sagemaker_role,
framework_version='1.11.0',
train_instance_count=1,
train_instance_type='ml.p3.2xlarge',
base_job_name='training_job_name',
training_steps=2000,
evaluation_steps=20,
hyperparameters=hyper_param
)
estimator.fit(s3_input(S3_INPUT_PATH), run_tensorboard_locally=True)
エンドポイントの起動
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.t2.medium')
Lambda関数
S3上に置いてある画像を分類するAPI。入力(クエリ文字列)として対象画像のS3パスを受け取り、推論結果を返却する。
import json
import boto3
import os
import io
import base64
import pickle
from PIL import Image
# 対象画像が格納されているS3バケット名
IMAGE_BUCKET = '<画像が格納されているS3バケット名>'
s3 = boto3.client('s3')
sage_run = boto3.client('sagemaker-runtime')
# 推論結果のラベル
LABELS = [ 'bird', 'cat', 'dog' ...(後略) ]
def lambda_handler(event, context):
image_path = event['queryStringParameters']['path']
# 推論実行
prediction_result = execute_prediction(image_path)
# ラベル判断
prediction_index = prediction_result.index(max(prediction_result))
prediction_return_body = {
'path': image_path,
'label': LABELS[prediction_index]
}
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
'body': json.dumps(prediction_return_body)
}
def execute_prediction(image_path):
# S3の画像をファイルストリームとしてダウンロード
file_stream = io.BytesIO()
s3.download_fileobj(IMAGE_BUCKET, image_path, file_stream)
# PIL Image Objとして読み込んだ後、pickleでbyteコードに変換
pickled_image = pickle.dumps(Image.open(file_stream), protocol=2)
# byteコードをbase64でエンコードした後に、JSONで渡せるように文字列にデコード
byte_pickled_image = base64.b64encode(pickled_image).decode('utf-8')
invoke_response = sage_run.invoke_endpoint(
EndpointName = '<エンドポイント名>',
Body=byte_pickled_image
)
invoke_response_body = json.loads(invoke_response['Body'].read())
return invoke_response_body['outputs']['dense_1']['floatVal']