はじめに
AWS re:Invent 2018 にて、SageMakerに以下のアップデートがありました。SageMaker RLやDeepRacerにばかり気を取られていて、しばらく気が付きませんでした。不覚。
TensorflowコンテナがスクリプトモードとPython3に対応
- 従来のSageMakerではmodel_fn, train_input_fn, eval_input_fn とコンポーネントを分けて記述する必要があった
- これが__main__ の中に直接モデル定義とデータ読み込み,学習処理をすべて書けるようになったので,既存のTensorflow スクリプトをそのまま持ってきて動かすことが容易になった
- あわせてtf.keras を使うことで,既存のKeras コードを移植して学習させることも容易に
- また従来のPython 2 だけでなく,Tensorflow 1.11 以降ではPython 3 に対応
tf.kerasを使うことで, 既存のKerasコードを移植して学習させることも容易に…!
約一か月前に以下のような投稿をしましたが、この時点では容易とはほど遠くかなり苦戦しました。
Amazon SageMaker で Keras を使用する
では、どの程度容易になったのか、以前利用したコードをスクリプトモードに書き換えて確認します。
なお、SageMaker Python SDKのGithubリポジトリのREADMEには、以下のように記載されており、私が以前投稿した内容は今回のアップデートで既にレガシー扱いになったようです。早いなぁ。この書きっぷりからすると、今からレガシーモードを習得するメリットは無く、今後はスクリプトモードだけ覚えていけば良さそうです。
Warning
We have added a new format of your TensorFlow training script with TensorFlow version 1.11. This new way gives the user script more flexibility. This new format is called Script Mode, as opposed to Legacy Mode, which is what we support with TensorFlow 1.11 and older versions. In addition we are adding Python 3 support with Script Mode. Last supported version of Legacy Mode will be TensorFlow 1.12. Script Mode is available with TensorFlow version 1.11 and newer.
Script Mode 概要
スクリプトモードでも学習用コードを書き、その学習用コードをSageMaker Python SDKから呼んでやるという大枠の構造は変わりません。ですが、レガシーモードに比べてかなり直感的に理解しやすい流れになっています。
スクリプトモードでfitをコールすると、estimator作成時に指定したタイプのインスタンスが立ち上がり、インスタンス内部で学習用コードのスクリプトがまるごと実行されます。基本的にはそれだけです。ユーザから見て不透明な動きがあまり無く、スクリプトが書いてある通りに実行されるだけなので、非常に簡単です。
学習用コード
今回スクリプトモード用に再編集した学習用コードは以下です。
import argparse
import os
import numpy as np
import tensorflow as tf
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.python.keras.layers import Conv2D, MaxPooling2D
from tensorflow.python.keras.optimizers import RMSprop
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
HEIGHT = 150
WIDTH = 150
DEPTH = 3
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# estimator実行時に指定したハイパーパラメータは
# コマンドライン引数としてスクリプトに渡される
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=100)
parser.add_argument('--num-classes', type=int, default=10)
# 入力データ、学習後のモデル、ログファイルなどの格納場所は
# 環境変数で設定されているので、その値をコマンドライン引数に渡しておく
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
parser.add_argument('--train-dir', type=str, default=os.environ['SM_CHANNEL_TRAIN'])
parser.add_argument('--valid-dir', type=str, default=os.environ['SM_CHANNEL_VALID'])
parser.add_argument('--output-dir', type=str, default=os.environ['SM_OUTPUT_DATA_DIR'])
args, _ = parser.parse_known_args()
########################################################
## ここから先はローカルでKerasを動かしていた時とほぼ同じ
########################################################
# ImageDataGeneratorで画像を読み込み
train_datagen = ImageDataGenerator(rescale=1./255)
valid_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
args.train_dir,
target_size=(HEIGHT, WIDTH),
batch_size=args.batch_size,
class_mode='categorical'
)
validation_generator = valid_datagen.flow_from_directory(
args.valid_dir,
target_size=(HEIGHT, WIDTH),
batch_size=args.batch_size,
class_mode='categorical'
)
# モデルの定義
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(HEIGHT, WIDTH, DEPTH)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(args.num_classes, activation='softmax'))
# モデルのコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['acc']
)
# モデルの学習
history = model.fit_generator(
train_generator,
steps_per_epoch=120,
epochs=args.epochs,
validation_data=validation_generator,
validation_steps=24
)
# 学習結果を出力 (CloudWatchからも参照可能)
print('train accuracy:', history.history['acc'])
print('validation accuracy:', history.history['val_acc'])
########################################################
## ここまでローカルでKerasを動かしていた時とほぼ同じ
########################################################
# 学習させたモデルをTensorFlow Serving用に変換し保存
sess = K.get_session()
tf.saved_model.simple_save(
sess,
os.path.join(args.model_dir, 'model/1'),
inputs={'inputs': model.input},
outputs={t.name: t for t in model.outputs})
前回書いたレガシーモードのコードと比較すると、スクリプトモードの学習用コードはかなりローカル実行時のものに近いです。
追加・修正が必要な部分は、前半のコマンドライン引数を取るところと、後半のモデルを保存するところだけです。学習部分は学習用コード内で完結するので、ImageGeneratorもそのままfit_generator()に渡せますし、処理結果もprint()すればそのままログに出力されます。
なお、学習用コード内で出力されたファイルは学習が終わるとインスタンスごと消えてしまいますが、環境変数であらかじめ設定されているSM_MODEL_DIR, SM_OUTPUT_DATA_DIRに出力しておくと、S3のSageMaker用バケットにも保存されます。スクリプトモードでは学習したモデルの保存も自分でやらないといけないので、ここだけ注意が必要です。
Jupyterノートブック
ノートブックの方はレガシーモードの方とほとんど変わりませんが、estimatorの定義の部分が以下のように変わります。レガシーモードの時はepoch指定が明示的にできなかったので、複数のハイパーパラメータでゴチャゴチャ設定しなければいけませんでしたが、スクリプトモードでは明示的に学習スクリプト内でepoch指定が可能なので、ノートブック側からパラメータとしてそのまま渡すことが可能です。
hyper_param = {
'batch-size': 20,
'num-classes': 20,
'epochs': 50
}
estimator = TensorFlow(
entry_point = "entry_point_script.py",
role=sagemaker_role,
train_instance_count=1,
train_instance_type="ml.m4.xlarge",
framework_version="1.11.0",
py_version='py3',
script_mode=True,
hyperparameters=hyper_param
)
estimator.fit({'train': s3_input(S3_PATH_TRAIN), 'valid': s3_input(S3_PATH_VALID)})
estimator.fit()を実行すると、(学習用インスタンスの立ち上げ、学習用のデータダウンロード完了後に、)以下のような出力がされます。確かに学習用スクリプトがそのまま実行されているだけだということがよく分かります。
Invoking script with the following command:
/usr/bin/python script_hist.py --batch-size 20 --epochs 10 --model_dir s3://sagemaker-ap-northeast-1-783528257735/sagemaker-tensorflow-scriptmode-2018-12-17-11-11-35-312/model --num-classes 20
なお、estimator.fit()に引数として渡した学習用データ(のS3上のパス)は、インスタンスを立ち上げた後に、自動的に環境変数SM_CHANNEL_xxxxで指定されたディレクトリへS3からダウンロードされます。なので学習用コードでは、このSM_CHANNEL_xxxxからデータを取得して学習を行うよう実装する必要があります。xxxxの部分は、estimator.fit()に渡したパラメータ名が入ります。上記の私のコードでは「train」「valid」というパラメータをfitに渡しているので、学習用コード内でもSM_CHANNEL_TRAIN, SM_CHANNEL_VALIDを参照しています。
デプロイと推論実行
デプロイはレガシーモードと同じです。なお、学習用コードで学習後のモデルを保存する処理を忘れていると、ここでエラーになります。
predictor = estimator.deploy(instance_type='ml.m4.xlarge', initial_instance_count=1)
推論実行もレガシーモードと変わらず、predictor.predict()をコールするだけです。レガシーモードではKerasからTensorFlowにモデル変換を行ったため、推論の入出力をTensorProtoにする必要がありましたが、スクリプトモードではローカル実行したときと同じ型で入力すればOKです。ここでは画像をnumpy配列にして渡しています。
import numpy as np
from PIL import Image
import io
file_stream = io.BytesIO()
# 推論対象の画像もS3上に置いてあるものを使う
s3 = boto3.client('s3')
s3.download_fileobj(SAGEMAKER_BUCKET, TO_PREFIX + '/test/001/001.jpg', file_stream)
img = Image.open(file_stream)
# 画像をNumpy行列に変換
image_array = np.asarray(img.resize((HEIGHT,WIDTH)))
image_array = image_array.reshape((1,) + image_array.shape)
# 推論実行
predictor.predict(image_array)
省略しますが、推論結果のフォーマットもレガシーモードと変わりません。
Boto3から推論実行
これもレガシーモードとほとんど変わりませんが、渡すパラメータをJSON文字列にしてやらないとダメなようです。
import boto3
import json
sage = boto3.client('sagemaker-runtime')
response = sage.invoke_endpoint(
EndpointName=predictor.endpoint,
ContentType='application/json',
Body=json.dumps(image_array.tolist()),
)
推論結果もレガシーモードと同じフォーマットですが、JSON文字列で返ってくるのでデコードが必要です。
json.loads(response['Body'].read())
その他に確認したこと
TensorBoard非対応
スクリプトモードではTensorBoard非対応のようです。fit()実行時にrun_tensorboard_locally=Trueを付けると以下のようなワーニングが表示されます。
WARNING: sagemaker:Tensorboard is not supported with script mode. You can run the following command: tensorboard --logdir None --host localhost --port 6006 This can be run from anywhere with access to the S3 URI used as the logdir.
学習用コード内でSM_OUTPUT_DATA_DIRにTensorBoardに必要なログを吐いた上で、S3にアクセスできる環境から自分でTensorBoard立ち上げろってことみたいですね。
Historyオブジェクトからメトリクスを確認できる
そこまでTensorBoardにこだわらない(というか、そもそもレガシーモードの時は学習時のメトリクスを取得する方法がわからず、ある意味仕方なくTensorBoardを使っていた)ので、単純にKerasのhistoryオブジェクトを学習用コード内でprintして、その結果で学習の過程を確認しようと思います。Kerasを学習するのに参考にした書籍もこの方法で学習過程の確認を行っていました。
学習用コードに以下のコードを記述すれば
print('train accuracy:', history.history['acc'])
print('validation accuracy:', history.history['val_acc'])
estimator.fit()の出力に以下のように表示されます。
train accuracy: [0.1660256450995803, 0.44807693554709355, 0.6173077090953787, (後略)]
validation accuracy: [0.4230769360437989, 0.4487179604669412, 0.5480769400795301, (後略)]
これをコピペしてmatplotlibで出力すれば、学習過程が確認できます。
%matplotlib inline
import matplotlib.pyplot as plt
train_acc = [0.1660256450995803, 0.44807693554709355, 0.6173077090953787, (後略)]
valid_acc = [0.4230769360437989, 0.4487179604669412, 0.5480769400795301, (後略)]
epochs = range(1, len(train_acc) + 1)
plt.plot(epochs, train_acc, 'bo', label='Traing acc')
plt.plot(epochs, valid_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
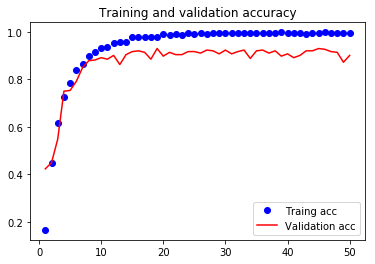
レガシーモードでやってた時は、Training AccuracyをTensorBoardに表示させる方法がわからなくて、正答率の比較が出来なかったんですが、スクリプトモードでようやく(そして簡単に)出来るようになりました。
なお、ログからコピペなんてアナログなことしなくても、CloudWatchログから取るとか、学習用コードの中でファイル吐き出すとか他にもやりようはあると思います。
コールバックを使ってEarly Stoppingできる
上記のグラフを見ると、10エポックあたりから正答率が上がっていないので、以降の学習が無駄なことがわかります。ただ、学習を始める前に最適なエポック数を予測するのは困難なため、レガシーモードではとりあえず過学習が始まるのに十分なエポック数で最初に学習を行い最適なエポック数を割り出した後で、このエポック数を使ってまた一から学習を行っていました。
本来、Kerasにはコールバックという機能があり、この機能によって学習の途中でも損失値の改善が見られなくなった時点で学習を打ち切ることができます。しかし、レガシーモードではこのコールバックがサポートされていなかったため、途中で学習を打ち切ることができませんでした。
確認したところ、スクリプトモードでは、このコールバックも通常通り使うことが出来るようです。例えば、以下のコールバック関数を定義して使用すれば、2エポック以上にわたって正解率が改善しない場合に学習を中止することができます。
from tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint
# コールバックの定義
callbacks_list = [
# 学習の途中で学習を中止するためのコールバック関数
EarlyStopping(monitor='val_acc', patience=1),
# 学習の途中のモデルを保存するためのコールバック関数
# 以下の設定では最良のモデルのみ保存する
ModelCheckpoint(
filepath=os.path.join(args.output_dir,'my_best.hdf5'),
monitor='val_loss',
save_best_only=True
)
]
# モデルの学習
history = model.fit_generator(
train_generator,
steps_per_epoch=120,
epochs=args.epochs,
validation_data=validation_generator,
validation_steps=24,
callbacks=callbacks_list, # fit実施にコールバック関数を渡す
verbose=0
)
1点注意が必要なのは、EarlyStoppingで学習を中止した場合、その時点のモデルは最良ではないということです。なので、学習終了後のmodelをそのままTensorFlow Serving用の変換処理にかけてしまうと、最良ではないモデルをデプロイすることになってしまいます。そこで、変換処理の前にModelCheckpointで保存しておいた最良のモデルをロードし直します。
model.load_weights(os.path.join(args.output_dir,'my_best.hdf5'))
これで無駄なエポックを積み重ねなくても最良のモデルをデプロイすることができます。ただ実際には正解率は上下を繰り返しながら少しずつ上がっていく傾向があるので、patienceの値をいくつにするかは別途検討が必要になるかもしれません。
インスタンスカウントを2以上にしても意味ない?
estimator定義時にtrain_instance_countを2以上の値に設定してもエラーなく動きます。(レガシーモードではエラーになって実行できませんでした。)しかし、単純に複数個のインスタンスで、それぞれ学習しているだけで学習を分担しているように見えません。例えば、20エポック、10分かかる処理をインスタンス2つでやったとしても、それぞれのインスタンスで20エポックを並列で学習するだけなので、所要時間も変わらず10分かかっています。その割に出来るモデルは1つなのですが、このモデルがインスタンス1つで20エポック学習したものと精度が変わりません。
この結果だけ見ると、インスタンスカウント2以上でも動くには動くが意味はないと思われます。
結論
スクリプトモード、かなり便利です。ライトユーザにとって、救いの手となるのではないでしょうか。
参考
この投稿は以下のリポジトリの「keras_tensorflow」を参考にしています。ありがとうございます。
https://github.com/harusametime/sagemaker-notebooks