Betterな分析環境を作る。
転職したときに最初にやったJupyterでの分析環境作りです。
再現性高くできたんで、どこに行っても通じるかと。
端末
MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)
OS:macOS Sierra 10.12.6
やること
- pyenv, pyenv-virtualenvを入れて、作業用環境を作ってそこにいろいろライブラリを突っ込む。
- Jupyter から MagicFunctionを使ってTreasure Dataに簡単にアクセス。
- Treasure Dataから持ってきたデータで分析する。
何でpyenv?
これまで、Pythonを適当にインストールしてて使ってたけど、しばらくするとpipが汚れて、新しいツールがインストールできないことがしばしば。
直接、インストールだともとに戻すのも一苦労だし、そもそも業務で使っているから、そんな時間はないので、
リセットとかが簡単にできる仮想環境系が良いと考えて。
ちなみに最初はAnacondaでやってた
この記事を書いているとき、AnacondaのVerが変わったことで、仮想化がしにくくなった。
https://qiita.com/y__sama/items/f732bb7bec2bff355b69
あと、こちらの記事にもあるように、Anacondaへの畏怖を感じて今回は使わないことにした。
https://qiita.com/shibukawa/items/0daab479a2fd2cb8a0e7
やり方
1. Homebrewをインストール
Homebrewのインストールコマンドはこちらの公式サイトにあるので、最新をなるべく取りにいく。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2. pyenv、virtualenvをインストール
brew install pyenv
brew install pyenv-virtualenv
※インストール時、Xcodeのエラーが出てくるかも。
そういうときは、素直にXcodeのVerを最新化しましょう。
Xcodeは、MacのOS Verに依存するところがあります。
今回は、Sierraだったので、Xcode 9.2を入れました。
参考:Xcodeの旧バージョンをインストールする方法
3. .bash_profileに入力
以下を入力します。
※.bash_profileはrootにあるはず。
PYENV_ROOT=~/.pyenv
export PATH=$PATH:$PYENV_ROOT/bin
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
入力終わったら、sourceコマンドで反映。
source ~/.bash_profile
4. pythonをインストール
今回は、3系で環境構築したいので、最新の3.7.0をインストールします。
2系がいい場合は、そのVerを調べていれます。
まず、現在pyenvでインストールできるpython環境の一覧を確認する。
pyenv install --list
※anacondaを入れたい場合、anaconda2-x.x.xが2系、anaconda3-x.x.xが3系です。(という認識。。。)
インストールコマンドはこちら。先程調べたVerを指定します。
pyenv install 3.7.0
インストールが終わったら、これでanacondaを指定します。
pyenv global 3.7.0
※pyenvがanaconda環境を指しているか確認する方法
pyenv versions
5. virtualenvとディレクトリを紐付ける
適当に作業用のディレクトリを作ります。
ここに、pythonのライブラリなどを入れていく感じになります。
とりあえず、rootにpyworkディレクトリを作成。
mkdir ~/pywork
次に、このディレクトリとpyenvのpythonを紐付ける。
pyenv virtualenv 3.7.0 pywork
pyworkディレクトリに移動し、このディレクトリ内に入ったとき、pythonが切り替わるようにする。
こうすると、rootディレクトリでは、systemのpython。
pyworkディレクトリでは、anacondaのpythonに切り替わる。
cd ~
pyenv local system
cd ~/pywork
pyenv local pywork
pyenv versionsを実行すると、ディレクトリと各環境が紐付いているのがわかる。
※ pyenvを削除するとき
pyenv uninstall ~/pywork
6. Pythonライブラリを入れる
ライブラリを入れる前に、ちょっとだけ管理の仕方について決めておく。
ここがPython管理の構築で後々、一番困るところなので。
Pythonライブラリの管理は、requirementsファイルにてライブラリ名を外部管理する
分析で使うPythonライブラリは、どんどん増えていくので、毎回一つずつ実行していくのは面倒。
環境構築がすぐできるように、requirements.txtを使うのがいいらしい。
私は、 pip-requirements.txt というファイルを作り、そこに欲しいライブラリをガンガン追加していってます。
↓こんな感じ。
# connect Treasure Data
td-client
pandas-td
# python data scientist
numpy
pandas
matplotlib
jupyter
scikit-learn
※もし、Anacondaを入れて、condaでパッケージ管理するときは、
condaとpipを両方使うのは依存パッケージのVer違いで詰むことがあるので、できるだけどちらかに統一する。
実際のインストール
requirementsファイルができたら、インストールコマンドを実行する。
pip でのインストール
pip install -r pip-requirements.txt
(Anacondaを使っている場合)conda でのインストール
conda install -c conda-forge --file conda-requirements.txt
※ オプションの -c conda-forgeはいくつかあるcondaのchannelを指定しています。
※ pipを使うと、conda側と同名のライブラリを入れてしまい、version違い問題が起きる可能性がある。
その場合は、以下のサイトを参考にする。
参考:condaとpip:混ぜるな危険
7. jupyter周りの設定
ここまでできたら、jupyter notebookが使える状況になっています。
一度、実行できるか確認しましょう。
jupyter notebook
ブラウザ上で実行されるはずです。

※ jupyter 自体の使い方については、別のQiita記事を参考に。
jupyter自体を終了するときは、terminal上で Control + C で終了できます。
次に、毎回同じライブラリを呼び出すは面倒なので、JupyterでPython起動時に、自動でライブラリを読み込む設定をします。
まず、これで、~/.ipython/profile_default/ipython_config.pyというファイルを自動で作ります。
ipython profile create
※ ちなみに、jupyterにも環境ファイルがありますが、ipython側と挙動が違うらしい。
詳しくはこちらのサイトに見解が載っています。
参考:jupyter notebookでPythonを使って解析するための設定
該当のファイルを開いて、下記を参考にconfigを入力します。
いろいろデフォルトで書いてますが、上のところに適当に追記します。
※ Treasure Dataを使わない場合、pandas-tdは不要です。
参考: IPythonのカスタマイズ
c = get_config()
c.InteractiveShellApp.extensions = [
# Pandas-TD のマジック関数
'pandas_td.ipython',
]
c.InteractiveShellApp.exec_lines = [
# 画像の埋め込みを有効にする
'%matplotlib inline',
# よく使うモジュールをロードする
'import numpy as np',
'import pandas as pd',
'import pandas_td as td',
]
あと、TreasureDataに接続するため、API Keyを環境変数に設定しておきます。
.bash_profileにでも入れておきましょう。(セキュリティ気になる人は他の方法で汗)
export TD_API_KEY="{...}"
最後に、source .bash_profileをお忘れなく。
8. Jupyter から Treasure Dataに接続する。
これで、MagicFunctionを使って、SQLで直接Treasure Dataと接続できます。

いくつか、便利な使い方をご紹介します。
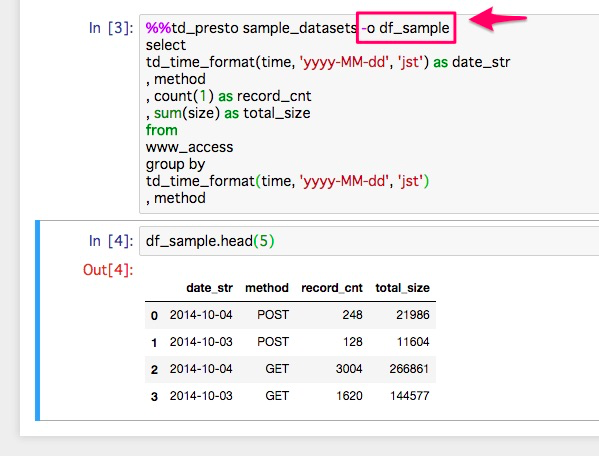
① SQLの結果を、DataFrameに保存する。
MagicFunctionに -o {DataFrame名}をオプションを指定します。
すると、SQLの結果を、DataFrameとして保存でき、その後の加工やレポーティングがしやすくなります。
② 結果をグラフで表示する。
同じく、 -- plotオプションをつけるだけで、結果を折れ線グラフで表示してくれます。
データの中身を簡単に確認したいときは最速です。

まとめ
Jupyterで簡単にDB(Treasure Data)からデータを引っ張り、
可視化や分析ができます。
分析を始める上で、環境構築は割とハードルなんで、再現性高く安定した環境作りは大事です。
PC環境や、pyenvなどのVerによっては上手くいかないこともありますが、
そんときはご了承ください。
Appendix
載せきれなかったリンク集
pyenvなどのpython環境入れはこちらを参考にしました。
http://qiita.com/nakazonor/items/258496fc442f7937c478
http://qiita.com/shizuma/items/027167c6257f1c9d2a6f
Treasre Data のMagicFunctionについて
https://qiita.com/toru-takahashi/items/74fe9f3cb97b6102165b
https://qiita.com/k24d/items/d6e8b8200108353b5354