はじめに
みなさんこんにちは。りいたです。
DWHを作っている他の会社さんの参考になったり、データ分析をしているけれど、DataOps的な考え方をこれから導入しようと考えている人の参考になればいいなと思って書いています。
ちょうど一年前くらいから、株式会社Journeyという会社でデータエンジニアチームをリードしています。
プレシリーズAくらいの小さな会社なのですが、この会社がやっているミニッツというサービスは、後払いの旅行サイトです。
後払いという特徴を持っているために、支払いが正しく済まされないお客さんがあとを立たないという課題を抱えていました。
そこで、機械学習を用いた不正検知を実装して、回収率を上げていくというプロジェクトの責任者として、この会社にジョインすることになりました。
そこで、当然必要になってくるのが、DataPlatformです。
前提
データ基盤の3分類 + 1
| 分類 | 役割 | 主なツール |
|---|---|---|
| DataLake | 行動ログやDBのデータを分析用にとりあえず置いておくところ。データソース(水源)から流れてきたデータをそのまま蓄える場所なのでレイク(湖) | BigQuery, BigTable |
| DataWareHouse | 事業のドメインに従って、再集計、加工したもの。基本的にはドメインにつながりのあるテーブルをjoinしたり、時差の修正をしたり。意味のあるものである必要はない。分析しやすいことが大事 | BigQuery, Dataproc |
| DataMart | SQLやPythonになれていないBiz向けにデータを加工・整理したものですね。完成品を取り揃えていることからマート(市場)と呼ぶらしいです。ここでは、GUIで必要なデータが取り出せることが重要事項と考えています。 | BigQuery, metabase, dataprep |
| FeatureTable | 機械学習の特徴量はここに追加していきます。BigQueryMLやAutoMLへの活用もしやすく、jupyterでのデータ加工も楽になります。 | BigQuery, csv, bigtable |
実際は、FeatureTableを除いた三つの分け方を、データ基盤の3分類と呼ぶことが多いと思います。
いわゆるDataOpsという界隈では、ゆずたそさんの提唱する進化的データモデリングはすごく有名だと思います。
https://www.amazon.co.jp/exec/obidos/ASIN/B087R6P8NZ/yuzutas0-22/
データサイエンティストや機械学習エンジニアのかたは、ぜひ一度読んでみてください。
そもそもData Lakeがなかった
この会社には、機械学習のモデルを作ってくれと言われて入ったのですが、最初に入った時はAIどころの騒ぎではなかったです。
というのも、特徴料として使えるデータが何も取れていなかったのです。
なので、まずは、DataLakeを作るところから始める必要がありました。
DataLakeを作る
データレイクには、BigQueryを採用しました。
BigQueryの利点は、
- 安い。数十GBくらいなら無料枠でやっていける。
- 使ってる人が多いので、文献が多い。
BigQueryは計算が非常に高速なので、開発体験もいいかなと思います。
SQLは普遍的なスキルで書きやすいので、Sparkなどを使うよりも誰でも簡単にデータの整形ができるところも非常に大きなメリットです。
BigQueryにとりあえず、入れると決めたので、設計ができました。
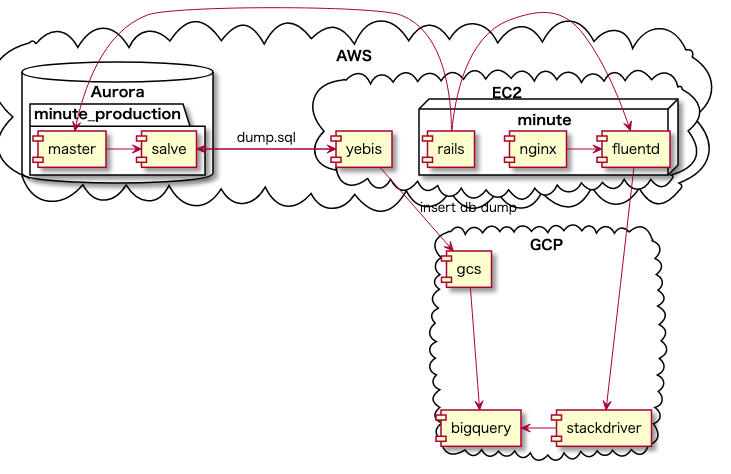
そして、データレイクを作成するときには、二箇所からデータを引っ張って来る必要がありました。
- アプリケーションから取れるアクセスログ
- MySQLから取れるデータベースの中身
アクセスログ
こちらは、LoggerとFluentdを活用して、Stackdriver経由でBigQueryに溜めました。
rails -> fluentd -> stackdriver ->bigquery
MySQLのデータ
slaveでdumpを作成して、それをGCSにあげるバッチを作成しました。
そして、GCS→BigQueryに流れるようになっています。
このバッチはdigdagを使って1日に一回動くようにしました。
Embulkを使ってBulk処理する方法も考えましたが、dailyであればdumpが十分に取れる程度のデータ量だったので、dumpを作成する方針を選びました。
from fluentd to bigquery
取りたいログをaccess.logに出力するために、Loggerを作る必要があります。
弊社はRailsを使っていたので、デフォルトのLoggerを活用したほうが賢いので、モンキーパッチをあてました。
module Server
module Logger
class Formatter < ::Logger::Formatter
include ActiveSupport::TaggedLogging::Formatter
GoのAPIに対しては、、github.com/TV4/logrus-stackdriver-formatterとgithub.com/plutov/echo-logrusを使って実装すると以下のようになりました。
package middleware
type (
Log struct {
Logger *logrus.Logger
}
)
func (l *Logs)getLogs(c echo.Context, next echo.HandlerFunc) error {
logFields := map[string]interface{}{
"time_rfc3339": time.Now().Format(time.RFC3339),
"remote_ip": c.RealIP(),
"host": req.Host,
"uri": req.RequestURI,
"method": req.Method,
"path": p,
"referer": req.Referer(),
"user_agent": req.UserAgent(),
"status": res.Status,
"latency": strconv.FormatInt(stop.Sub(start).Nanoseconds()/1000, 10),
"latency_human": stop.Sub(start).String(),
"bytes_in": bytesIn,
"bytes_out": strconv.FormatInt(res.Size, 10),
"claims": claims,
}
l.Logger.WithFields(logFields).Info()
}
from mysql to bigquery (yebis)
MySQLからデータ取ってきて、頑張ってCVS作って、S3に上げておいてください。
今度はそれを取ってきて、BigQueryに上げています。
load_job = dataset.load_job(table_id, file_path, skip_leading: 1, schema: schema)
load_job.wait_until_done!
こんな感じの関数があるので、意外と簡単にできます。
定期実行を担っている、digdagの設定ファイルは以下のようなものを利用しています。
timezone: Asia/Tokyo
schedule:
daily>: 04:00:00
_export:
slack_webhook_url: https://hooks.slack.com/services/********
slack_webhook_channel: "#general"
+setup:
sh>: bundle install
+run:
sh>: ruby main.rb
データ基盤の3分類を始める。
解決すべき課題(Issue to be Solved)
- 特徴量を増やすのが大変すぎる
- 地道にSQLを大量に書かないといけない
- 書いたからといって、精度があがるとは限らない
- 現状、欲しいデータがいつでもすぐに管理できているとは言えない
- 依頼、レスポンスまでの時間がある程度ある
- 一度に大量の依頼をしても返せない
- GUIで分析できたらそれはそれで便利では(metabase, dataprep)
- KPIの管理がイマイチ
- SQLを書いたはいいけど、ビジネス視点でクリティカルじゃない
- Dashboardは正しくルールを決めて管理するべきなのでは
- クエリ管理ができてない
- 書いたクエリの厳密な定義がもはや記憶にない
- 書いたクエリにどんなものがあったか覚えていない
分析というのが、アドホックな検証という役割だけでなく
行動や属性から、ユーザーをクラスタリングし、
それによってどのようなクラスの属性にどの施策が刺さったのかを考える
仮説構築の手助けができるようなものを目指してく方がいい。
というのが、当時のPRDに僕が書いたものです。
簡潔に言えば、BigQueryから頑張って引っ張ってくればいいというフェーズに限界がきていたんです。
- 同じようなデータセットをなんども作り直すのが大変すぎる
- ちょっとしたKPIの要件変更に対して、全てのクエリを修正しないといけない
という2点です。
ビジネスの分析のために取得する必要があるデータというのは無数にあって、ちょっと定義が違うデータを取るために、非常に大きなSQLを書いているとキリがなくなってきます。
定義の変更は本当に厄介で、200ものクエリを全部読んで、またちょこっと変更なんてことをしないといけなかったので、DataWareHouseにKPIに関わるような重要な定義は外だしにしてあげて、DataMart側はFROM句でそこを参照するような形にしておかないとやってられないというのは強くありました。
そこで、中間テーブル的な存在のものが必要になってきているという、現場感覚的な課題を感じていて、データ基盤の3分類を始めました。
実際に、Datawarehouseを活用することで200行のクエリを30行にするくらいの威力がありました。
データ基盤の3分類を実現するアーキテクチャ
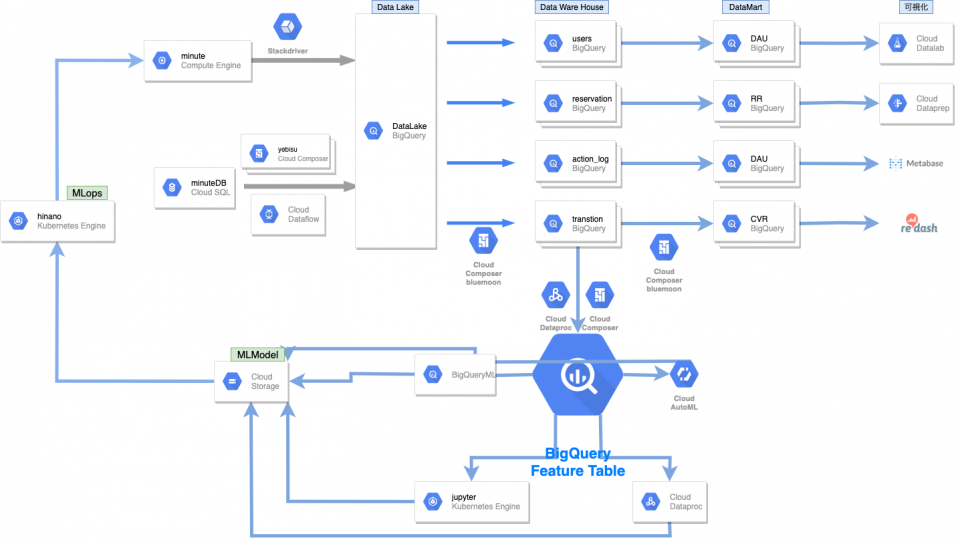
Cloud Composer (bluemoon)
Airflowのマネージドサービスですが、BigQuery Operatorが用意されていて、非常に簡単に利用することができました。実際に利用しているコードを以下に記述しますが、本当に簡単に利用できたのでオススメです。
Cloud Composer自体は、Terraformを使ってIaCを実現していました。
terraform {
backend "gcs" {
bucket = "bluemoon-tf-state"
path = "composer.tfstate"
credentials = "account.json"
}
}
provider "google" {
credentials = file("account.json")
project = "minute-journey"
region = "asia-northeast1"
}
resource "google_composer_environment" "composer-environment" {
name = "cloud-composer"
project = "minute-journey"
region = "us-central1" # 当時はdataprocとかdataflowがasia対応してなかったので
config {
node_count = 3
node_config {
zone = "us-central1-a"
machine_type = "n1-standard-1"
disk_size_gb = 20
}
software_config {
airflow_config_overrides = {
core-dag_concurrency = 20
}
}
}
}
ディレクトリ構成
.
├── tf...
├── data_source_a.py
├── data_source_b.py
└── data_source_c.py
└── sql
├── data_source_a.sql
├── data_source_b.sql
└── data_source_c.sql
import datetime
import codecs
from airflow import models
from airflow.contrib.operators import bigquery_operator
from airflow.operators import bash_operator
with codecs.open('/home/airflow/gcs/plugins/sql/data_source_a.sql', 'r', 'utf-8') as f:
query = f.read()
DAG_NAME = 'base_query'
default_dag_args = {
'start_date': datetime.datetime(2018, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=10),
'project_id': "minute-journey"
}
with models.DAG(
dag_id=DAG_NAME,
schedule_interval="@daily",
default_args=default_dag_args) as dag:
start = bash_operator.BashOperator(
task_id='start',
bash_command='echo Start Workflow'
)
bq_to_bq = bigquery_operator.BigQueryOperator(
task_id='query',
write_disposition='WRITE_TRUNCATE',
create_disposition='CREATE_IF_NEEDED',
allow_large_results=True,
sql=query,
use_legacy_sql=False,
destination_dataset_table='minute-journey.data_ware_house.data_source_a'
)
start >> bq_to_bq
実行方法
gcloud composer environments storage dags import --location us-central1 --environment cloud-composer --source base_query.py
gcloud composer environments storage plugins import --location us-central1 --environment cloud-composer --source sql/
定期実行
定期実行のジョブ自体は、朝九時にのみ実行されます。
一日中Cloud Composerのクラスタが立ち上がっている状態だと、勿体無いので、8:45に起動して、9:30に削除するようにしています。この仕組みを作る際にも、前述のTerraformを活用しました。
CircleCIのcron使って、午前8:45にterraform applyして、9:30にterraform destroyしています。
Cloud Composerが立ち上がったタイミングで終了できるような仕組みですか?そんなものはないです笑
version: 2
jobs:
create:
working_directory: ~/bluemoon
docker:
- image: hashicorp/terraform:light
steps:
- checkout
- run:
name: Slack notification
command: sh start_slack.sh
working_directory: .
- run:
name: Init terraform
command: terraform init
working_directory: tf/cloud-composer
- run:
name: Apply terraform
command: terraform apply -auto-approve
working_directory: tf/cloud-composer
destroy:
working_directory: ~/bluemoon
docker:
- image: hashicorp/terraform:light
steps:
- checkout
- run:
name: Slack notification
command: sh end_slack.sh
working_directory: .
- run:
name: Init terraform
command: terraform init
working_directory: tf/cloud-composer
- run:
name: Destroy terraform
command: terraform destroy -auto-approve
working_directory: tf/cloud-composer
deploy:
working_directory: ~/bluemoon
docker:
- image: google/cloud-sdk
steps:
- checkout
- run:
name: initialize gcloud
command: |
gcloud auth activate-service-account --key-file=tf/cloud-composer/account.json
gcloud --quiet config set project minute-journey
- run:
name: import sql files
command: gcloud composer environments storage plugins import --location us-central1 --environment cloud-composer --source sql/
- run:
name: import dag files
command: gcloud composer environments storage dags import --location us-central1 --environment cloud-composer --source base_query.py
workflows:
version: 2
start_workflow:
triggers:
- schedule:
cron: "45 23 * * *"
filters:
branches:
only:
- master
jobs:
- create
- deploy:
requires:
- create
filters:
branches:
only: master
end_workflow:
triggers:
- schedule:
cron: "30 0 * * *"
filters:
branches:
only:
- master
jobs:
- destroy
MLOps (hinano)
不正かどうかの確率を計算して返すAPIです。
GCSからモデルのpickleファイルを取ってきて、APIコールで特徴量をもらってそれを計算して返すって感じです。
def load_model():
project_name = "minute-journey"
storage_client = storage.Client(project_name)
bucket_name = 'hinano'
bucket = storage_client.get_bucket(bucket_name)
#アップロードしたファイルをダウンロード
blob_download = bucket.get_blob('xgb_reservation_model.pickle')
loaded_model = pickle.loads(blob_download.download_as_string())
return loaded_model
def score_predict(clf, reservation_log):
y_pred_proba = clf.predict_proba(reservation_log)
y_pred = clf.predict(reservation_log)
return y_pred[0], y_pred_proba[0][0]
APIにはFlask使っています。
推論後のモデルを取ってきて、APIとして推論結果を返します。
GCSにアップロードされているモデルは、Mutableに更新をしています。
継続的にMLモデルを更新する仕組みをJupyter Notebookに持たせていて、
その際にpickleファイルを上書きするようにしています。