Qiitaに10本記事を書いて学んだ、読まれそうな記事の3つの鍵
「なんのために働いてるんだろう」
「自分のやっていること価値がない気がする」
そんなことをぼんやり思いながら、なんとなく始めたのが、Pythonと株式投資、そしてQiitaでのアウトプットでした。
最初は反響ほぼ無し。自信も実績もないから、やっぱりダメだなぁと思う毎日。
それでも10本目を迎えた今、気づいたことがあります。
- 読まれる記事には、それなりの“型”がある
- 手応えはすぐには返ってこないけど、蓄積すれば必ず何かが動く
- 技術記事にも、書き手の物語はちゃんと滲む(そう信じたい)
本記事では、これまでQiitaに投稿してきた経験をふり返りながら、
- 投稿を始めたきっかけ
- 技術記事のプラットフォームの選び方
- 記事を書く中で試行錯誤した工夫
- 書いて得られた実際のメリット
- 今後に向けた反省
これらについてまとめました。
筆者のこれまでの活動が実績かと言われると難しいですが、少しずつ前進し始めた気がします。
「まだ何者でもないけど、何か始めたい」
そんな人に、記事を書くきっかけになれば嬉しいです。
「何者になれるかどうかは保証できません」
前回のyfinaceのデータセットの話ですが、次回やります。
めんどくさくなった。と言いたいところですが、
10本目なので...、濃厚なポエムを書くのをぜひお許しくださいませ♡
1. 書き始める前の自分
職業:化学メーカー-研究職
入社前に望んでいたこと
何十社もお祈りをいただいて、せっかく内定が取れた待望の研究職、最初は、以下のようなことを「研究者らしい仕事」として期待していました:
- 自ら課題を定義し、仮説を立てる
- トライアンドエラーを繰り返す
- 徐々に得られてくる成果を公表する、その過程で自分もスキルアップする
たとえば大学院では、「この化合物はなぜ効くのか?」という問いに対して、
「特定の酵素に結合して働きを止めているのでは?」と仮説を立て、
実験により検証していました。
うまくいかなければ仮説を見直してやり直す――
そんな仮説検証のサイクルを、何度も回すのが好きでした。
必要があれば、指導教員に嫌がられながらも、 研究室に前例がなかったドッキングシミュレーションや分子動力学計算を取り入れようと試したり、新しい技術を習得したりするのがやり甲斐でした。
いんちき自己啓発セミナーの人みたいですが、唐揚げと相性の良い付け合わせを、何度も何度も試す感覚です。レモンが合うということは酸味のあるキムチもかな?と試して、バシッと決まった時に、
脳汁ドバドバっと出る
あの感覚が、仮説検証で得られる快感です。
入社後に直面した現実
実際に配属されてからの仕事は、想像していた「研究」とはかけ離れていました。
たとえば:
- テーマが与えられない。単発の定型業務だけをやらされる
- テーマの選定や試験設計の裁量はない
- 新しい技術や知識の習得は求められず、「今のやり方をを続けられること」が評価対象
結果として、以下のような気持ちが強まりました。
- 自分で仮説を立てて進める余地がなく、「ただこなすだけ」の仕事でやりがいがない
- 高度なテーマに挑む機会はなく、長期的なスキルの積み重ねにもつながらなかった
- 研究というより、作業者-オペレーターとして働いている感覚に近かった
次第に、「このままでは自分はロボットと変わらないのではないか」と思うようになりました。

エンジニアの皆様も
「課題を見つけて自分で解決するつもりだったのに、
ふたを開けてみたらマニュアル通りの作業ばかりだった」―
ちょっと工夫したら、上司に怒られる
そんな経験、ありませんか? 自分が直面したのも、まさにそれでした。
2. 転機:生成AIの力を実感 株式投資とPythonに出会う
いっそのこと会社を辞めて博士課程へ行きたい。しかし元々、進学を断念した背景には、金銭的な事情がありました。どうすれば経済的に自立しながら、自分の興味を深掘りする生活ができるか─そう考えていたとき、株式投資に興味を持ち始めました。
とはいえ、会社での業務に意欲が持てず、帰宅後はダラダラとYouTubeやSNSを眺め、2年間ほどは、ほとんど何も積み上げられない日々が続いていました。生成AIも入社と同タイミングで有名になったから、使ってみたかったのですが、社内規定で禁止されていて、全く使う機会がありません。
時代に取り残されてメンタルもおかしくなった廃人になりかけていました。
そんな中、突然の異動命令が下りました。
研究は続けられるのですが、専門分野から外れ、まったく畑違いの部署へ。
事実上の戦力外通告?
そう思わざるを得ませんでした。性格をなかなか変えられない、組織に順応しようとしない、自分への罰だったのかもしれません。
自分の工夫や提案が評価されなかったばかりか、実務的にほぼゼロリセット。そこでようやく、「会社という枠に寄り掛かっている限り、この先も同じことの繰り返しだ」と痛感したのです。
だったら、自分で稼ぐ力を付けるしかない。
そんなとき、たまたま当時(2025年4月初旬)保有していた日清食品ホールディングスの株が大きく下落していて、「この先、上がるのか、もっと下がるのか」をどうしても知りたくなりました。そこで、ChatGPTに「Seq2SeqTransformerを使って株価の時系列予測をするコードを書いてほしい」と頼み、Pythonで未来の株価を予測してみることにしました。
当時書いてもらってたコード
精度は当てにしないでください。参考までに。
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
# -----------------------------
# 1. データ取得 & 特徴量作成
# -----------------------------
ticker = "2897.T"
df = yf.download(ticker, start="1995-01-01", end="2025-04-04")
df = df[["Open", "High", "Low", "Close", "Volume"]].dropna()
# --- テクニカル指標(変更禁止) ---
df["MA_5"] = df["Close"].rolling(window=5).mean()
df["MA_25"] = df["Close"].rolling(window=25).mean()
df["MA_75"] = df["Close"].rolling(window=75).mean()
delta = df["Close"].diff()
delta = delta.values.reshape(-1)
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
rs = avg_gain / (avg_loss + 1e-10)
df["RSI"] = 100 - (100 / (1 + rs))
df["Volatility"] = (df["High"] - df["Low"]) / df["Close"]
df["MA5_diff"] = (df["Close"].values.reshape(-1) - df["MA_5"].values.reshape(-1)) / df["MA_5"].values.reshape(-1)
df["MA25_diff"] = (df["Close"].values.reshape(-1) - df["MA_25"].values.reshape(-1)) / df["MA_25"].values.reshape(-1)
df["MA75_diff"] = (df["Close"].values.reshape(-1) - df["MA_75"].values.reshape(-1)) / df["MA_75"].values.reshape(-1)
df["Return"] = df["Close"].pct_change()
df["LogReturn"] = np.log(df["Close"] / df["Close"].shift(1))
df = df.dropna()
# -----------------------------
# 2. sequence-to-sequence用データ作成
# -----------------------------
features = ["Close", "Volume", "RSI", "Volatility", "MA5_diff", "MA25_diff", "MA75_diff", "Return", "LogReturn"]
data = df[features].values.astype(np.float32)
target = df["LogReturn"].values.astype(np.float32)
close_series = df["Close"].values.astype(np.float32)
date_index = df.index
seq_len = 90
pred_len = 30 # 30日先の予測
# ★ 30点ahead対応 create_sequences ★
def create_seq2seq(data, target, close_series, date_index, seq_len, pred_len):
xs, ys, cs, ds = [], [], [], []
for i in range(len(data) - seq_len - pred_len):
xs.append(data[i:i+seq_len])
ys.append(target[i+seq_len:i+seq_len+pred_len])
cs.append(close_series[i+seq_len:i+seq_len+pred_len])
ds.append(date_index[i+seq_len:i+seq_len+pred_len])
return np.array(xs), np.array(ys), np.array(cs), np.array(ds)
x_seq, y_seq, c_seq, d_seq = create_seq2seq(data, target, close_series, date_index, seq_len, pred_len)
train_size = int(len(x_seq) * 0.8)
x_train, y_train, c_train, d_train = x_seq[:train_size], y_seq[:train_size], c_seq[:train_size], d_seq[:train_size]
x_test, y_test, c_test, d_test = x_seq[train_size:], y_seq[train_size:], c_seq[train_size:], d_seq[train_size:]
train_dataset = TensorDataset(torch.tensor(x_train), torch.tensor(y_train))
test_dataset = TensorDataset(torch.tensor(x_test), torch.tensor(y_test))
# -----------------------------
# 3. seq2seq Transformer
# -----------------------------
class Seq2SeqTransformer(nn.Module):
def __init__(self, input_dim, d_model=64, nhead=4, num_layers=2, pred_len=30):
super().__init__()
self.input_linear = nn.Linear(input_dim, d_model)
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.output_linear = nn.Linear(d_model, pred_len)
def forward(self, x):
x = self.input_linear(x)
x = self.transformer(x.permute(1, 0, 2))
x = x.mean(dim=0)
return self.output_linear(x)
model = Seq2SeqTransformer(input_dim=len(features), pred_len=pred_len)
# -----------------------------
# 4. 学習
# -----------------------------
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
for epoch in range(30):
model.train()
losses = []
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
output = model(batch_x)
loss = criterion(output, batch_y)
loss.backward()
optimizer.step()
losses.append(loss.item())
print(f"Epoch {epoch+1}, Loss: {np.mean(losses):.6f}")
# -----------------------------
# 5. 予測 & 復元 & グラフ(過去の株価と未来の予測をつなげる)
# -----------------------------
model.eval()
pred_logret_seq = model(torch.tensor(x_test)).detach().numpy()
# 予測結果の復元
c_test = np.array(c_test)
if c_test.ndim == 3:
c_test = c_test.squeeze(-1)
predicted_close_seq = c_test * np.exp(np.cumsum(pred_logret_seq, axis=1))
actual_close_seq = c_test * np.exp(np.cumsum(y_test, axis=1))
# 1. 予測と実測の誤差を示す
sample = -1 # 例として最後のサンプルを使用
plt.figure(figsize=(12, 5))
# 実際の株価と予測された株価のプロット
plt.plot(d_test[sample], actual_close_seq[sample], label="Actual Close", color="blue")
plt.plot(d_test[sample], predicted_close_seq[sample], label="Predicted Close", color="orange")
# 予測と実測の誤差を計算して表示
error = actual_close_seq[sample] - predicted_close_seq[sample]
plt.plot(d_test[sample], error, label="Error (Actual - Predicted)", color="red", linestyle="--")
plt.legend()
plt.title("Actual vs Predicted Close Price (Error Plot)")
plt.xlabel("Date")
plt.ylabel("Price")
plt.gcf().autofmt_xdate()
plt.show()
# 2. 過去の株価に予測値をつなげてグラフ化
# 実際の株価(過去の)をプロット
plt.figure(figsize=(12, 5))
plt.plot(df.index, df['Close'], label="Actual Close", color="blue")
# 予測された株価(未来)をつなげてプロット
plt.plot(d_test[sample], predicted_close_seq[sample], label="Predicted Close (Future)", color="orange")
plt.legend()
plt.title("Past Stock Prices and Predicted Future Close Price")
plt.xlabel("Date")
plt.ylabel("Close Price")
plt.gcf().autofmt_xdate()
plt.show()
# -----------------------------
# 6. 30日後の予測結果(30日後を予測)
# -----------------------------
latest_data = df[features].tail(seq_len).values.astype(np.float32) # (90, 特徴量数)
latest_close = float(df["Close"].iloc[-1]) # スカラー化しておく
# 30日後のログリターンを推論
future_pred_logret = model(torch.tensor(latest_data).unsqueeze(0)).detach().numpy()
predicted_future_logret = np.cumsum(future_pred_logret, axis=1)[0] # shape = (30,)
# 株価に復元(30個のベクトル)
predicted_future_close = latest_close * np.exp(predicted_future_logret) # shape = (30,)
# プロット
plt.figure(figsize=(12, 5))
plt.plot(range(1, 31), predicted_future_close,
label="Predicted 30-day Future Close", color="purple")
plt.title("2897.T (Nissin Foods Holdings Co.,Ltd.)-Predicted Close Price for the Next 30 Days", fontname='Meiryo')
plt.xlabel("Days Ahead")
plt.ylabel("Predicted Close Price")
plt.legend()
plt.show()
結果として、モデルは「今が底値でこれから上がる」と予測。実際、その後に株価は戻り、底値で売らずに済むという経験をしました。この体験がきっかけで、「あれ、生成AIに聞きながら、Pythonでコードを組んで、投資をするのって思っていた以上に使えるのでは」と感じ、本格的にコードを書き始めるようになりました。
簡易的な精度の検証

2025年4月4日から1ヶ月後の日清食品の終値の予測値
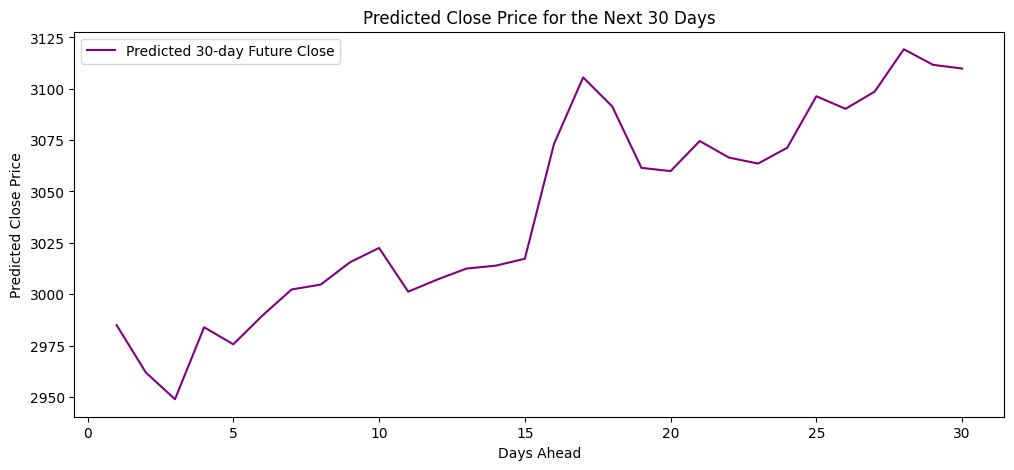
実際の日清食品の価格推移
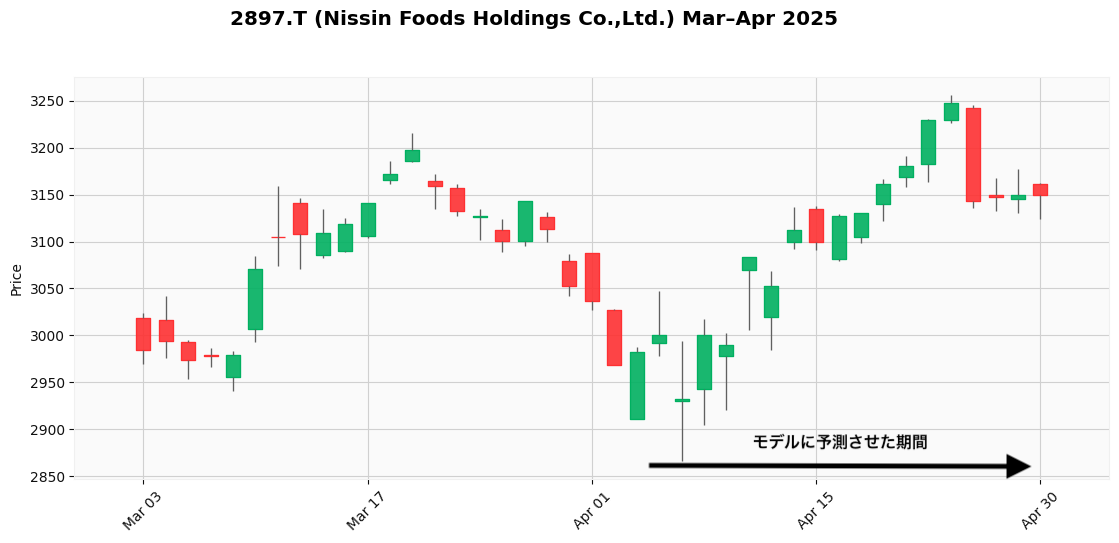
*当時は十分なバックテストをしていないので、たまたま当たっただけだと思います。このコードはさらなる改善が必要です。こんな単純なテクニカル指標だけで精度が出るはずがない...ただ、当時の自分は、AIの言うことを信用しすぎてしまっていた。
*それでもたまたまにしては、最初の数日は少し下がったり、15日付近で一旦上がったり、みたいな傾向を予測しているところは、完全にデタラメなモデルでもないとも言える。
df = yf.download(ticker, start="1995-01-01", end="2025-04-04")をしているから、絶対に4月4日以降の値はリークしていないはずだし。
3. Note、Zenn、Qiita どれかに投稿してみるか...
データを集めて分析して、コードを書いて─それだけでも楽しかったのですが、
次第に「せっかくなら外に出してみよう」と思うようになりました。
- モチベーションが維持できる
- 第三者の目が入ることで、読みやすさや正確さも意識するようになる
- 自分と似たような境遇の誰かに届いて、その人も行動のきっかけになるかもしれない
そう思い、技術記事を公開する場を探し始めました。
まず、Noteでは技術記事というよりは読み物という感じで、株や投資の話は既にレッドオーシャン。
Zennも候補にありましたが、Qiitaのほうがユーザー数が多く、PVの面では見てもらえる可能性が高いと判断。Zennはいいねをもらいやすいが、そもそものユーザー数が少ないため、ニッチな内容を期待している読者が少なく、筆者の場合、投稿しても読まれないかもしれないと思いました。
一方、Qiitaは技術記事の中でも「Python × 株式投資」という分野はまだ少ないですが、記事を書いているユーザーがいないこともない。過剰ほどではないので、初心者が投稿しても埋もれないと判断。
また、Qiitaのアクティブユーザーは20〜30代が中心で、熟練の金融エンジニアが厳しい目でジャッジしてくる場というよりは、同年代の誰かが、試行錯誤や成長の記録に共感したり、参考にしてくれる場所かもしれない─そんな思いもあり、筆を取るきっかけになりました。
完璧な記事である必要はない。むしろ「うまくいかなかったこと」や「つまずきながら工夫したこと」、すなわち自分の好きな仮説を持って失敗しながら、試行錯誤、徐々に改善していく研究っぽい一連の流れの中に、読み手にとってのリアルな学びがあるのではないか。挑戦の過程そのものが意味を持つ─だからこそ、Qiitaという場で発信し続けようと決めました。
Note、Zenn、Qiitaの比較
| プラットフォーム | 雰囲気 | 向いている投稿 | 自分の印象 | 他情報 |
|---|---|---|---|---|
| Note | 読み物・日記寄り | 体験談や思考整理に最適 | 投資系は人が多すぎて埋もれる | Noteの多用途性・収益化機能あり |
| Zenn | 技術ブログ寄りで洗練 | Tips〜中規模技術記事に向く | UIは良く、GitHub連携も魅力だが読者数が少なめ | Zennは技術特化&GitHub管理可能 |
| Qiita | 技術情報に特化 | コード・検証・再現性ある記事向き | 利用者数がZennよりも多いが、Python×株はニッチで埋もれにくい | Qiitaは技術共有に特化、多くのエンジニアが利用 |
Qiitaユーザー属性(2023年調査データに基づく)
| 属性カテゴリ | 主な情報 |
|---|---|
| 年齢層 | 18〜34歳が全体の約半数(46%)を占める |
| 経験年数 | 未経験者(21%)、経験1〜3年未満(20%)の若手層が多い |
| 主な業種 | 情報通信業が最多(63%)、特にWebサービス分野(60%) |
| 主な職種 | 情報通信業ではバックエンドエンジニアが最も多い(31%) |
プラットフォーム選択の参考
Note
Zenn
Qiita
- エンジニア向け投稿プラットフォーム比較
- Qiita徹底解説とAIトレンド
- Qiitaのメリット・デメリット
- QiitaとZennの人気度を比較したら面白かった
- Qiitaの歴史(Findyブログ)
- 大規模アンケート調査を実施。言語やツールのトレンド・年収・転職・働き方などを解析 - Qiita株式会社
- Qiitaにどんなエンジニアがいるのかを 調査してみた!Webサービス系エンジニアがよく使うプログラミング言語まとめ | Qiita for Business
4. 読まれない記事を読まれるように工夫し始めた話
Qiitaで最初に投稿したイントロ記事 「D進したいが金がない。そうだ株価を予測しよう。」は、驚くほど多くの方に読まれて 10000 view 以上の反響がありました。
ところが、それ以降に書いた記事は撃沈。
財務スクリーニングの方法を解説した記事 → 4000 view以下
テクニカルスクリーニングの方法を紹介した記事 → 3000 view以下
地合いスコア解説記事 → 3000 view以下
そこでちょっと改善を試みた記事
| No | タイトル | 狙い | 反響 |
|---|---|---|---|
| 1 | Pythonで月利3%狙ってるけど、頭と机がごちゃごちゃだったので、まず現実から片付けた話 | エンタメ寄りにして、ニッチなジャンルに興味を持ってもらえることを重視(画像多め) | LGTM100超 / 86000 view / 連動して他の記事の反響が増えた |
| 2 | Python×株式投資:月利3〜5%を狙う自動スクリーニング戦略 | 複数反復でバックテストをして、月にどのくらい収益が出そうかを検証することを重視(データの分布は隠さず示す) | LGTM150超 / 30000 view / Xでプロの人からコメントもらった |
| 3 | Python×株式投資:都度DLはやめた ─ yfinance で爆速テクニカル分析を回したい | 実用面での問題を解決することを重視(自分やって楽になったことを紹介) | LGTM100超 / 87000 view / AIのラジオに取り上げられた |
振り返って感じた 3 つの鍵
記事を書き続けてわかったのは、読者が「面白そうだ」と感じて読み始め、「信頼できそうだ」と納得し、最終的に「役に立つかも」と思ってもらえる、この一連の心理的流れを意識することが重要だということでした。
-
エンタメのひとさじ
読者に「面白そう」と思ってもらう最初のトリガー。技術だけでなく、試行錯誤の過程や日常の小ネタを交えることで、専門外の人も引き込めるように工夫しました。 -
検証・再現性
「信頼できそう」と思ってもらえるためには、単なる主張だけでなく、バックテストやヒートマップなどの客観的データで方法の妥当性を“数字で示す”ことが効果的でした。 -
運用現実性
最後に「実際に使えそう」「役に立ちそう」と思ってもらうため、自動化の難しさや処理の遅さなど、読者が詰まりやすい実用面の課題に対して、先回りして解決策を提示するようにしました。
この3点を意識し始めてから、伸び悩んでいた view 数が回復し、LGTM 3桁の記事が複数出るようになりました。
表にある各記事は、投稿順も内容もバラバラですが、振り返ってみるとどれも「面白さ」「信頼感」「実用性」の要素を(無意識に)盛り込んでいました。
特にどの要素を強調するかは記事ごとに異なりますが、この3つが揃っていたとき、反響が大きくなっていたことに気づきました。
Qiita(勉強になった記事)
他にも、ロジカルな文章な書き方、文章構成などについて書かれた記事を読んで、少し勉強しました。
エンタメすぎて、内容が浅い自分の記事がトレンドに載ることで、他の有用な記事を埋没させてるのかもしれないこともあった。気をつけないと。
5. Pythonと株を勉強しながら、Qiitaを書いて得られたメリット
Qiita に毎週記事を上げることで、次の 3 つの変化がありました。
メンタルが安定した
会社の飲み会でのこと、 プログラミング の話題になって、ちょっとだけPythonを勉強し始めたという話をした際、上の者から「お前の Python なんて、うちのIT人材に比べると幼稚園レベル」と笑われました。

それでも帰り道にスマホを開くと、Xでよくコメントくれる方(最近Qiita始めたらしい。色々頑張っている高校生)から、「記事読みました。面白かったです。」とリプライいただきました。心がスッと落ち着いたのを覚えています。職場でどんな言葉を浴びても、自分の力を活かせる場所が別にあると思えるようになったので、あまり気にしなくなりました。

嬉しさのあまり耳が 「1対」 増えてしまった。
さらに、今、自分がしていることは、最初にも述べた、
- 自分なりの問いを見つけて深掘りし、仮説と戦略を立てる
- その問題の答えを、失敗を繰り返しながら見つけ、それを公表する
- その過程で、新しい技術や知識を吸収し、自分自身も成長する
まさにこのプロセスをしているじゃないですか。
- 問いと仮説の提案:投資で収益を得るの仕組みをPythonで作ることができるのではないか
- 試行錯誤と公開:テクニカル選抜の自動化のコードでリターンがでそうだ→Qiita投稿
- 技術習得: その過程で、コーディングの方法、AIの使い方、文章の書き方を学ぶ
やりたかった「研究」らしきものができているから、
それはどおりで、充実感がありますわ。論文書いてないですけど...
お小遣いが増えた
5月1日から、Pythonのモデルを使って銘柄選抜をしたり、積み立て投資を始めたり、自分の勘で取引をしたり、少し本格的に株式投資を始めました。
最初の全資産は¥1,094,490。この記事を書く前日(6月12日)に確認したら¥1,153,969に増えてました。
1ヶ月+1週間で+¥59,479なのでちょっとリッチな気分になっちゃいました。
*実は翌日、-¥12,000くらい減りました(いやあ株って難しい)。
でも、いくらか資産は増えました。たまたまだと思いますが。
テクニカル分析で2-4週のスイングトレードをするのが、会社員には合っているし、勉強になるのですが、同時に積み立てもした方が良いと思います。S&P500なんて年利5%以上に到達したこともあるそうですし、どっちが良いと言う訳でなく、リスクは分散させるに越したことはないと思います。投資は自己責任ですが。
あれだけ嫌だった会社がそれほど悪く感じなくなった
そんなこんなで、自力で資金を集める大変さを感じています。
それに比べると、会社員というのは、決められたことをすれば、月にまとまったお金が振り込まれます。某 Network Attached Storage(NAS)だってもらえます。
自分のような、わがまま研究員は大して会社に貢献できていないはずなのに、会社はそれなりの待遇をしてくれます。そんな会社に対して、好きな研究ができない。面白くないというのは、甘えている気がしています。この活動を通して、学びがたくさんありました。
さらに、今の部署は、人当たりが良い人ばかりで、定常業務の延長的な研究というよりは、試行錯誤型の研究をさせてもらえています。それと、好きに実験を増やしても良いので、試行数が増え、ちょっとした成果も出始めています。
人のパフォーマンスって、
ちょっとだけ新しいことをしたり、環境が変わったりするだけで著しく変わるものなのですね。
実力がないし、スキルもないし、実績も出ないし、
自分って無能だなという毎日が続いてましたが、
自分の責任って案外少ないのかもしれないです。
責任逃れはいけません。やらずに逃げるのは良くないです。
かつての自分はそうでしたが...
6. まだ未熟なところ
偉そうに綴ってきましたが、正直に言えば、まだまだ足りないことばかりです。
- コードは少しずつ読めるようになってきたけれど、思った通りに書くのは難しい。
- デバッグや手直しはできても、一から組み立てる力はまだ未熟。
- 統計も、使ってはいるが本当に理解しているとは言えない。
- テクニカル指標は身についてきたけれど、投資全体の流れや判断軸は掴みきれていない。
- 機械学習も、理屈より先にツールを触っている感覚が抜けきらない。
- Pythonだけに頼っていて、他の言語や設計の視点がまだ薄い。
けれど、自分なりに「どうすればよくなるか」を考えて手を動かし、反応を確かめながら試してみる─ その小さな繰り返しの中で、少しずつ、輪郭のある理解を進めているところです。
まだゴールまでは長い道のりが残っています。
自分の歩みは、
人と比べるとかなりゆっくりですが、
これからもマイペースにちょっと焦りながら積み重ねていきたいと思っています。
その繰り返しが、少しずつ手応えに変わっていくと信じています。
7. まとめ
本稿では、Qiitaにおける記事の試行錯誤を通じて、
記事の書き方のコツや自身に起きた変化について振り返りました。
「エンタメ性(ちょっとだけ)」「信頼性」「実用性」の3点が揃った記事が今後も投稿できるように、
まだまだ、課題が多くある自身のスキルや知識を磨いていきたいと思います。
仮説を立てて試し、結果を観察し、必要に応じて見直すという姿勢を通じて、徐々に改善をしていきます。運営の方に怒られない限り、今後もその過程を、Qiitaに投稿しますので、
皆様のお役に立てれば嬉しいです。
ここまで読んでいただいた読者の皆様、本当にありがとうございました。
今後ともrS_alonewolfをよろしくお願いいたします。
Qiitaに10本記事を書いて感じた、“読まれそうな記事”の3つの鍵
読まれるとか書いておいて、この記事読まれなかったら最高のオチだな。
2025年6月15日 ところどころタイトルや文章を修正しました。
2025年6月16日 すみません。また気に入らない文章があったので、加筆しました。