はじめに
AWS LambdaとPythonを利用してWebスクレイピングの処理をマイクロサービス化し、ほかのLambdaや外部システムから呼び出せるようにした「headlessms」を作った際のメモ。
このheadlessmsにboto3やAPI Gateway経由でPythonのコードを投げると、そのコードに従ってheadless chromeとseleniumによるWebスクレイピングを実行し結果を返してくれる。
前提環境
- Amazon Web Serbices
- AWS CLI
- Docker
- jqコマンド、gitコマンド
- 構築手順はAmazon Linux 2(AWS Cloud9)上で検証した
headlessms構築手順
- 変数初期化
$ app_name=headlessms
$ workdir=${PWD}/$app_name
$ backet_name=${app_name}-$(echo -n $(aws sts get-caller-identity | jq -r .Account) | md5sum | cut -c 1-10)
- 構築用プログラム一式を作成する。(githubにも上げてあるので以下のコマンドでクローンしてもOK)
$ git clone https://github.com/r-wakatsuki/${app_name}.git $workdir
- プログラム一式のファイルパスは以下の通り。
headlessms/
├ headlessms-aws-function-00/
│ └ lambda_function.py
├ headlessms-aws-layer-00/
│ └ Dockerfile
└ headlessms-aws-stack-00.yml
- Dockerfile
headless chromeやseleniumなどのパッケージが含まれたLambda Layer用のzipを作成するためのDockerfile。
FROM python:3.7
WORKDIR /work
CMD apt update && \
apt install -y zip && \
mkdir -p python/bin && \
pip install -t ./python requests lxml selenium && \
curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip && \
unzip headless-chromium.zip -d python/bin/ && \
rm headless-chromium.zip && \
curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip && \
unzip chromedriver.zip -d python/bin/ && \
rm chromedriver.zip && \
zip -r ./zipdir/layer.zip python
- lambda_function.py
Lambdaに配置するコード。別のLambdaや外部システムから受け取ったスクレイピングコードを/tmp/<uuid>.pyに書き込んでimportし、起動済みのheadless chromeをmodule.scrape_process(driver)で渡して実行する。
import json,sys,uuid,importlib
from base64 import b64decode
from selenium import webdriver
def lambda_handler(event, context):
global driver
options = webdriver.ChromeOptions()
options.binary_location = "/opt/python/bin/headless-chromium"
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument('--blink-settings=imagesEnabled=false')
driver = webdriver.Chrome("/opt/python/bin/chromedriver",chrome_options=options)
def return200(res_body):
return{
'statusCode': 200,
'body': res_body
}
moduleName = str(uuid.uuid4())
with open('/tmp/%s.py' % moduleName, mode='w') as f:
if event.get('viaRestApi','') == True:
f.write(b64decode(event['body']).decode())
else:
f.write(event['body'])
sys.path.insert(0, '/tmp/')
module = importlib.import_module(moduleName)
return(return200(module.scrape_process(driver)))
- headlessms-aws-stack-00.yml
headlessmsの構成要素となるLambda、Layer、API GatewayなどのAWSリソースをCloud Formationで作成するためのyamlテンプレート。
Parameters:
appName:
Type: String
backetName:
Type: String
stageName:
Type: String
Default: dev
usagePlanQuotaLimit:
Type: Number
Default: 200
usagePlanQuotaPeriod:
Type: String
Default: MONTH
AllowedValues:
- DAY
- WEEK
- MONTH
usagePlanThrottleBurstLimit:
Type: Number
Default: 10
usagePlanThrottleRateLimit:
Type: Number
Default: 5
Resources:
Role00:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub ${appName}-aws-role-00
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- 'sts:AssumeRole'
Policy00:
Type: AWS::IAM::Policy
DependsOn:
- Role00
Properties:
PolicyName: !Sub ${appName}-aws-policy-00
PolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Action:
- 'logs:CreateLogGroup'
- 'logs:CreateLogStream'
- 'logs:PutLogEvents'
Resource: '*'
Roles:
- !Ref Role00
Layer00:
Type: AWS::Lambda::LayerVersion
Properties:
LayerName: !Sub ${appName}-aws-layer-00
CompatibleRuntimes:
- python3.7
Content:
S3Bucket: !Ref backetName
S3Key: layer.zip
Function00:
Type: AWS::Lambda::Function
DependsOn:
- Policy00
- Layer00
Properties:
FunctionName: !Sub ${appName}-aws-function-00
Code:
S3Bucket: !Ref backetName
S3Key: function.zip
Role: !GetAtt Role00.Arn
Runtime: python3.7
Handler: lambda_function.lambda_handler
MemorySize: 512
Timeout: 120
Layers:
- !Ref Layer00
Api00:
Type: AWS::ApiGateway::RestApi
Properties:
Name: !Sub ${appName}-aws-api-00
ApiKeySourceType: HEADER
Method00:
Type: 'AWS::ApiGateway::Method'
Properties:
ApiKeyRequired: true
RestApiId: !Ref Api00
ResourceId: !GetAtt Api00.RootResourceId
HttpMethod: POST
AuthorizationType: NONE
Integration:
Type: AWS
IntegrationHttpMethod: POST
Uri: !Join
- ''
- - 'arn:aws:apigateway:'
- !Ref 'AWS::Region'
- ':lambda:path/2015-03-31/functions/'
- !GetAtt Function00.Arn
- /invocations
RequestTemplates:
application/octet-stream: "{\n \"body\": \"$input.body\",\n \"viaRestApi\": true\n}"
IntegrationResponses:
- StatusCode: '200'
MethodResponses:
- StatusCode: '200'
LambdaPermission00:
Type: 'AWS::Lambda::Permission'
DependsOn:
- Method00
Properties:
FunctionName: !Ref Function00
Action: 'lambda:InvokeFunction'
Principal: apigateway.amazonaws.com
SourceArn: !Join
- ''
- - 'arn:aws:execute-api:'
- !Ref 'AWS::Region'
- ':'
- !Ref 'AWS::AccountId'
- ':'
- !Ref Api00
- /*/POST/
Deployment00:
Type: AWS::ApiGateway::Deployment
DependsOn:
- LambdaPermission00
Properties:
RestApiId: !Ref Api00
StageName: !Ref stageName
ApiKey00:
Type: AWS::ApiGateway::ApiKey
DependsOn:
- Deployment00
Properties:
Name: !Sub ${appName}-aws-apikey-00
Enabled: true
StageKeys:
- RestApiId: !Ref Api00
StageName: !Ref stageName
UsagePlan00:
Type: AWS::ApiGateway::UsagePlan
DependsOn:
- ApiKey00
Properties:
UsagePlanName: !Sub ${appName}-aws-usageplan-00
ApiStages:
- ApiId: !Ref Api00
Stage: !Ref stageName
Quota:
Limit: !Ref usagePlanQuotaLimit
Period: !Ref usagePlanQuotaPeriod
Throttle:
BurstLimit: !Ref usagePlanThrottleBurstLimit
RateLimit: !Ref usagePlanThrottleRateLimit
UsagePlanKey00:
Type: AWS::ApiGateway::UsagePlanKey
DependsOn:
- UsagePlan00
Properties:
KeyId: !Ref ApiKey00
KeyType: API_KEY
UsagePlanId: !Ref UsagePlan00
- Dockerを利用してheadless chromeやseleniumが含まれたLambda Layer用のzipを作成する。
$ cd $workdir
$ docker build -t hm_layer_image ${workdir}/${app_name}-aws-layer-00
$ docker run -v ${workdir}:/work/zipdir hm_layer_image
- Lambda関数用のzipを作成して、Layer用のzipと合わせてS3にアップロードする。
$ zip -j ${workdir}/function.zip ${workdir}/${app_name}-aws-function-00/*
$ aws s3 mb s3://$backet_name
$ aws s3 mv ${workdir}/function.zip s3://${backet_name}/function.zip
$ aws s3 mv ${workdir}/layer.zip s3://${backet_name}/layer.zip
- CloudFormationでAWSにデプロイ。
$ aws cloudformation create-stack --stack-name ${app_name}-aws-stack-00 \
--template-body file://${workdir}/${app_name}-aws-stack-00.yml \
--capabilities CAPABILITY_NAMED_IAM \
--parameters ParameterKey=appName,ParameterValue=$app_name \
ParameterKey=backetName,ParameterValue=$backet_name
headlessmsの利用例
ほかのLambda関数(Python)から使う場合
func.pyに記載されたPythonコードをlambda_main.pyがboto3によりheadlessmsに送信し、スクレイピングされた結果のレスポンスをlambda_main.pyがさらに処理するサンプルを記載する。
送信するfunc.py内のコードにdef scrape_process(driver)を定義すればheadlessmsが(driver)に起動済みのheadless chromeを渡してくれる。
また、Lambdaの実行ロールには最低でも以下の権限を持つポリシーをアタッチすること。
{
"Action": [
"lambda:InvokeFunction"
],
"Resource": "*",
"Effect": "Allow"
}
sample1
IDとパスワードでログインをしたあとに別のページを開き、javascriptで生成されたdomから要素を取得する。
import boto3,json,os
from base64 import b64decode
def lambda_handler(event, context):
kms = boto3.client('kms')
login_id = kms.decrypt(CiphertextBlob=b64decode(os.environ['login_id']))['Plaintext'].decode('utf-8')
login_password = kms.decrypt(CiphertextBlob=b64decode(os.environ['login_password']))['Plaintext'].decode('utf-8')
input_event = {
"body": open('func.py').read().replace('__loginId__',login_id).replace('__loginPassword__',login_password)
}
response = boto3.client('lambda').invoke(
FunctionName = 'headlessms-aws-function-00',
InvocationType = 'RequestResponse',
Payload = json.dumps(input_event)
)
val = json.loads(response['Payload'].read().decode())['body']
import lxml.html
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
def scrape_process(driver):
driver.get('https://www.sample1.com/login')
WebDriverWait(driver, 9).until(ec.presence_of_all_elements_located)
driver.find_element_by_name('email').send_keys('__loginId__')
driver.find_element_by_name('password').send_keys('__loginPassword__')
driver.find_element_by_xpath("//input[@class='btn btn-primary']").click()
driver.get('https://www.sample1.com/users/notice')
WebDriverWait(driver, 9).until(ec.presence_of_all_elements_located)
dom = lxml.html.fromstring(driver.page_source)
return(dom.xpath('//div[@class="gb_timeline_list"]/ul/li[1]/span/text()')[0])
sample2
AngularJSが使用されているWebページで生成されたdomから複数の要素を配列で取得して処理する。
import json,boto3
import urllib.request
def lambda_handler(event, context):
input_event = {
"body": open('func.py').read()
}
response = boto3.client('lambda').invoke(
FunctionName = 'headlessms-aws-function-00',
InvocationType = 'RequestResponse',
Payload = json.dumps(input_event)
)
res_ary = json.loads(response['Payload'].read().decode('utf-8'))['body']
for item in res_ary[2]:
bodybinary = urllib.request.urlopen(item).read()
import lxml.html
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
def scrape_process(driver):
driver.get("https://sample2.jp/description/program2/detail")
WebDriverWait(driver, 20).until(ec.presence_of_element_located((By.CLASS_NAME, 'episode-image')))
dom = lxml.html.fromstring(driver.page_source)
number = dom.xpath('//*[@class="title ng-binding"]')[0].text
title = dom.xpath('//*[@class="title program-title-animate ng-binding"]')[0].text
img_urls = dom.xpath('//*[@class="episode-image ng-scope"]/img/@src')
comment_enum = dom.xpath('//*[@class="episodes"]//*[@class="ng-binding"]')
comment = ''
if len(comment_enum) == 0:
pass
else:
for item in comment_enum:
if item.text is not None:
comment = comment + '<br />' + item.text
return(number, title, img_urls, comment)
sample3
IDとパスワードでログインをして取得したクッキーを使って指定のURLから画像データをダウンロードし、そのバイナリを配列で取得して処理する。
import re,json,boto3,os
from base64 import b64decode
def lambda_handler(event, context):
kms = boto3.client('kms')
login_id = kms.decrypt(CiphertextBlob=b64decode(os.environ['login_id']))['Plaintext'].decode('utf-8')
login_password = kms.decrypt(CiphertextBlob=b64decode(os.environ['login_password']))['Plaintext'].decode('utf-8')
img_urls = []
img_urls = re.findall('https://bmimg.sample3.jp/image/chXXXXXXX/.+\.jpg',event['body'])
input_event = {
"body": open('func.py').read().replace('__imgUrls__',str(img_urls)).replace('__loginId__',login_id).replace('__loginPassword__',login_password)
}
response = boto3.client('lambda').invoke(
FunctionName = 'headlessms-aws-function-00',
InvocationType = 'RequestResponse',
Payload = json.dumps(input_event)
)
img_ary = json.loads(json.loads(response['Payload'].read())['body'])
import requests,json
from base64 import b64encode
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
def scrape_process(driver):
driver.get('https://account.sample3.jp/login')
WebDriverWait(driver, 5).until(ec.presence_of_all_elements_located)
driver.find_element_by_id('input__mailtel').send_keys('__loginId__')
driver.find_element_by_id('input__password').send_keys('__loginPassword__')
submitButton = driver.find_element_by_id('login__submit')
submitButton.click()
session = requests.session()
for cookie in driver.get_cookies():
session.cookies.set(cookie['name'], cookie['value'])
img_urls = __imgUrls__
img_contents = []
for url in img_urls:
img_contents.append(b64encode(session.get(url).content).decode('utf-8'))
return(json.dumps(img_contents))
curlから使う場合
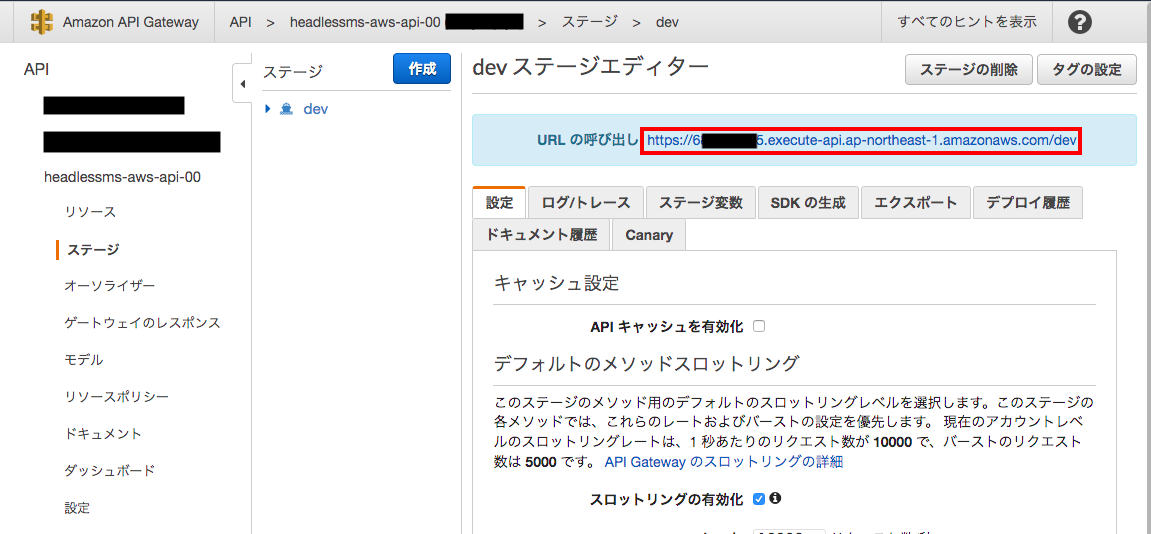
ブラウザからAPI Gatewayのコンソールを開く。
[headlessms-aws-api-00] -> [ステージ] -> [dev] -> [devステージエディター]よりAPIのURLを確認する。
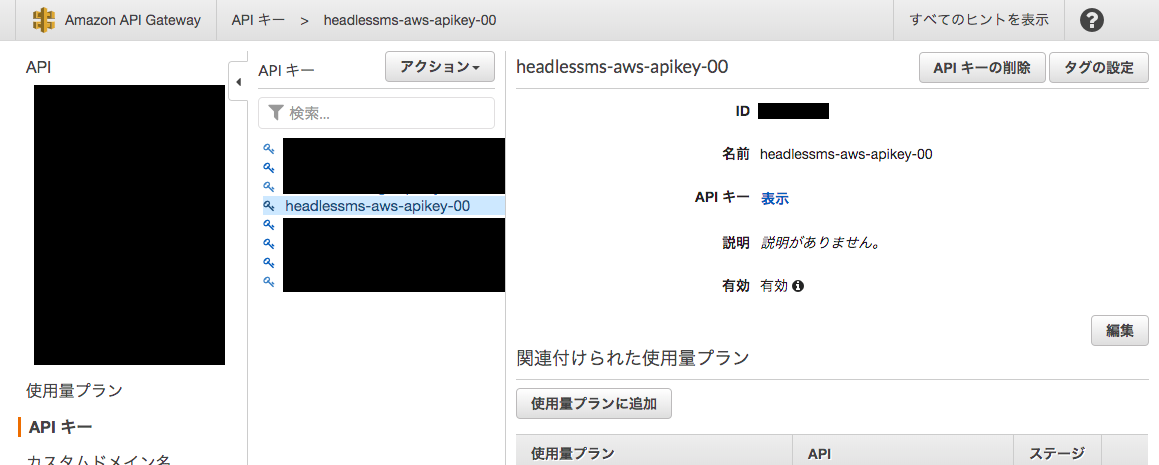
[APIキー] -> [headlessms-aws-apikey-00]より[表示]をクリックしてAPIキーを確認する。
Pythonコードを記載したfunc.pyを配置し、<APIキー>と<APIのURL>を指定して以下のようにcurlを実行すると、headlessmsからスクレイピングの結果を取得することができる。
func.pyの書き方は「ほかのLambda関数から使う場合」と同じである。リクエストのデータにはbase64エンコードして指定すること。
$ base64 -w0 func.py | curl -X POST -H "content-Type: application/octet-stream" -H "x-api-key: <APIキー>" -d @- <APIのURL>
利用例では使わなかったが、pandasやbeautifulsoup4などほかのスクレイピング用の定番パッケージもあると思うので、使いたい人はDockerfile内のpip install -t ./python ~の並びにパッケージ名を追記すればよい。
参考
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d
https://takuya-1st.hatenablog.jp/entry/2018/02/20/014236
https://qiita.com/r-wakatsuki/items/4076e3b8032d06f85aea
https://qiita.com/r-wakatsuki/items/1cdb9493749dbc36bed2
以上