概要: Rustの Arc 型の実装は宝の宝庫です。そこで、これを隅から隅まで解説してみます。
第4回「アトミック変数とメモリ順序」では、Arc のマルチスレッド処理を読むにあたって必要な事前知識を解説します。第4回は1~3には依存せず読めるはずです。
- 第1回 Arc/Rcの基本
- 第2回 Rcを読む基本編
- 第3回 Rcを読む発展編
- 第4回 アトミック変数とメモリ順序
- 第5回 Arcを読む
はじめに
第2回~第3回にかけて、 Arc のシングルスレッド版である Rc の実装を読んできました。残るは Arc 特有の部分ですが、それに入る前にアトミック変数に関する事前知識を解説します。
まとめ
- 一般論としてマルチスレッドプログラミングでは競合状態が問題になるため、ミューテックスなどの並行性プリミティブを用いて競合を防ぐ必要がある。
- C++やRustなどより低レイヤを扱うプログラミング言語では、ミューテックスより原始的な仕組みであるアトミック変数もよく用いられる。
- C++やRustなど最適化を重要視するプログラミング言語では、非アトミック変数の競合はデータ競合というより重大な問題につながる。
- C++やRustなど最適化を重要視するプログラミング言語では、アトミック操作にも保証のレベルが段階的に設定されており、メモリ順序と呼ばれている。最も強いメモリ順序では逐次一貫性とよばれる直感的な性質が成立するが、弱いメモリ順序では驚くような方法で操作が入れ替えられることがある。
- Rustのメモリ順序の仕様はC++20のドラフトを参照する形で定義されている。C++20のメモリ順序の仕様はC++17から一部改訂されている。
- release-acquireの一般論は、スレッド内順序であるsequenced beforeとrelease-acquireの結果生じるsynchronizes withによってhappens beforeが定義される、という形で進行する。
- release-acquireの個別論では、個別のメモリ領域が観測するメモリ順序がmodification order, reads fromという関係によって定義され、happens beforeとの関係が規定される、という形で進行する。
- 逐次一貫性はrelease-acquireの規格に被せる形で定義されている。release-acquireと併用した場合に難しい問題が発生する。
- メモリモデルは逐次実行のモデルと分離して定義されているが、そのせいでOOTAという厄介な規格上の問題が発生している。
ミューテックス
本稿の主眼はアトミック変数ですが、その前により広く親しまれている並行プリミティブであるミューテックス (相互排他) について軽く説明します。
逐次一貫モデルと競合状態
まずは素朴なモデルからはじめましょう。
シングルスレッドなプログラムは、プログラムに書かれた順番に実行されます。詳細な規則はプログラミング言語によって異なりますが、たとえば、
print("foo")
print("bar")
と書いたら、これは上から下に実行されます。むしろ、下から上に実行されたら驚天動地ですね。
では、マルチスレッドなプログラムはどのように実行されるでしょうか。最も素朴な解釈では、「あるスレッドを途中まで実行して、次に別のスレッドを少しだけ実行して……」という風に、1度にひとつのスレッドを、少しずつ動かす形で実行される(のと等価)と考えることができます。この世界観を**逐次一貫性 (sequential consistency)**といいます。RubyやPythonなど、GIL/GVL (グローバルインタープリタロック/グローバル仮想機械ロック) を持つ多くのインタープリタ言語の動作は、この見方でおおよそ正しく捉えることができます。
競合状態
さて、逐次一貫モデルで考えるとして、以下のプログラムは正しく動作するでしょうか。2つのスレッドで1つのカウンタを共有し、それぞれがカウンタを500万回インクリメントしています。
import threading
counter = 0
def count_up():
global counter
for i in range(0, 5000000):
counter += 1
thread = threading.Thread(target=count_up)
thread.start()
count_up()
thread.join()
print(f"counter = {counter}")
答えは否です。筆者の手元の環境 (x86-64 Linux WSL, CPython 3.7.2) では以下のような結果になりました。
$ python count_example.py
counter = 6359819
$ python count_example.py
counter = 6314099
$ python count_example.py
counter = 7071096
$ python count_example.py
counter = 6068423
$ python count_example.py
counter = 6587500
なぜこうなるかの洞察を得るために、CPythonの dis ライブラリを使ってバイトコードを表示してみます。
>>> import test
counter = 6792048
>>> import dis
>>> dis.dis(test.count_up)
7 0 SETUP_LOOP 26 (to 28)
2 LOAD_GLOBAL 0 (range)
4 LOAD_CONST 1 (0)
6 LOAD_CONST 2 (5000000)
8 CALL_FUNCTION 2
10 GET_ITER
>> 12 FOR_ITER 12 (to 26)
14 STORE_FAST 0 (i)
8 16 LOAD_GLOBAL 1 (counter)
18 LOAD_CONST 3 (1)
20 INPLACE_ADD
22 STORE_GLOBAL 1 (counter)
24 JUMP_ABSOLUTE 12
>> 26 POP_BLOCK
>> 28 LOAD_CONST 0 (None)
30 RETURN_VALUE
仕様上どうかは別として、仮に上の命令列の区切りでスレッドが切り替わると考えてみます。ループの内部では以下のようなコードが実行されています。
-
LOAD_GLOBAL counterでcounterから値を読み込み、スタックの先頭に積む。 -
LOAD_CONST 1でスタックの先頭に定数 1 を積む。 -
INPLACE_ADDでスタックの先頭2つを取り除き、その合計値をスタックの先頭に積む。 -
STORE_GLOBAL counterでスタックの先頭の値をcounterに保存する。
これは確かに counter += 1 の操作に対応していそうです。ここで、カウンタが100の状態で、2つのスレッドで次のような順番で命令が実行されたとするとどうなるでしょうか。
| スレッド1 | スタック | スレッド2 | スタック | counter |
|---|---|---|---|---|
[] |
[] |
100 | ||
LOAD_GLOBAL counter |
[100] |
[] |
100 | |
[100] |
LOAD_GLOBAL counter |
[100] |
100 | |
LOAD_CONST 1 |
[100, 1] |
[100] |
100 | |
INPLACE_ADD |
[101] |
[100] |
100 | |
STORE_GLOBAL counter |
[] |
[100] |
101 | |
[] |
LOAD_CONST 1 |
[100, 1] |
101 | |
[] |
INPLACE_ADD |
[101] |
101 | |
[] |
STORE_GLOBAL counter |
[] |
101 |
この順番で実行されると、両方のスレッドで counter += 1 が1回ずつ実行されているのに、実際の counter は1しか増えていないことになります。このような現象を一般に**競合状態 (race condition)**と呼びます。
このカウンタの問題は競合条件の単純化された例としてよく出てきますが、実際のところこれ自体が重要な問題です。本シリーズの主眼である Rc/Arc の参照カウンタがまさにこの問題そのものであることに気付いたでしょうか。
ミューテックス
上のプログラムで問題だったのは、「読み込み→変更→保存」という一連の操作の間に割り込まれる可能性があったことです。これに対応するためによく使われる仕組みがミューテックスです。
先ほどのPythonコードをミューテックスを使うように置き換えると以下のようになります。 (より時間がかかるようになるので、ループ回数を減らしました)
import threading
counter = 0
# ミューテックスを作成
lock = threading.Lock()
def count_up():
global counter
for i in range(0, 500000):
# この中は一度に1スレッドしか同時に入れない
with lock:
counter += 1
thread = threading.Thread(target=count_up)
thread.start()
count_up()
thread.join()
print(f"counter = {counter}")
このように書くと、 with lock: 内には一度に1スレッドしか入れなくなります。これによって競合条件は発生しなくなり、このプログラムは常に1000000を出力するようになります。
アトミック変数
前節では、ミューテックスを適切に使うことで競合状態を回避することができることをカウンタを例にして紹介しました。実のところより複雑な並行性制御 (reader/writer lock や bounded queue, connection pool など) も、このミューテックス(と条件変数)を組み合わせることによって実現可能です。
では、このミューテックス(と条件変数)が最も基本的な並行性プリミティブなのかというと、そんなことはありません。ほとんどのCPU(特にOSが書けるようなCPU)は整数に対するアトミック操作 (不可分操作) や同期命令を実装しています。ミューテックスはこのアトミック操作や同期命令、そしてOSが提供する futex(2) のようなスレッドを休眠させるプリミティブから作ることができます。
ミューテックスのようなより高度な仕組みとは異なり、アトミック操作はCPUの命令と1対1に近い関係をもちます。たとえば fetch_add は、x86系CPUでは以下のように lock add という単独の命令に翻訳されます。 https://godbolt.org/z/3ZRE5K
use std::sync::atomic::AtomicUsize;
use std::sync::atomic::Ordering::SeqCst;
pub fn f(p: &AtomicUsize) {
p.fetch_add(1, SeqCst);
}
example::f:
lock add qword ptr [rdi], 1
ret
ミューテックスとの性能差
アトミック操作を直接使えば、ミューテックスよりも効率的なプログラムを書ける場合があります。たとえば以下は先ほどのカウンタの問題をRustのミューテックスで実装したものです。
(※Rustのミューテックスは、「「本来の意味でのミューテックス + ミューテックスが保護するデータ」のセットで提供されているため、 Mutex<T> という型をもちます。)
use lazy_static::lazy_static;
use std::sync::Mutex;
use std::thread::spawn;
lazy_static! {
static ref COUNTER: Mutex<usize> = Mutex::new(0);
}
fn count_up() {
for _ in 0..50000000 {
let mut counter = COUNTER.lock().unwrap();
*counter += 1;
}
}
fn main() {
let thread = spawn(count_up);
count_up();
thread.join().unwrap();
eprintln!("counter = {}", *COUNTER.lock().unwrap());
}
これをアトミック変数で実装し直すと以下のようになります。
use std::sync::atomic::AtomicUsize;
use std::sync::atomic::Ordering::SeqCst;
use std::thread::spawn;
static COUNTER: AtomicUsize = AtomicUsize::new(0);
fn count_up() {
for _ in 0..50000000 {
// 「1を足す」操作をアトミックに行う
COUNTER.fetch_add(1, SeqCst);
}
}
fn main() {
let thread = spawn(count_up);
count_up();
thread.join().unwrap();
eprintln!("counter = {}", COUNTER.load(SeqCst));
}
手元での計測結果は以下の通りです。Rustの性能にあわせて回数を10倍に増やしたので、 --release をつけないと厳しいかもしれません。
$ time target/release/mutex-test
counter = 100000000
target/release/mutex-test 9.39s user 7.00s system 193% cpu 8.491 total
$ time target/release/atomic_counter
counter = 100000000
target/release/atomic_counter 1.53s user 0.02s system 196% cpu 0.786 total
はっきりとわかる性能差がありそうです。 (parking_lot を使うともう少し差は縮まるかもしれません)
スピンロック
すでに出てきましたが、ミューテックスはアトミック変数の利用例として非常に重要です。そこで本稿でもスピンロック (spin lock) に基づくミューテックスの簡易的な実装を書いてみます。(既存ライブラリでは spin が有名です。)
スピンロックは、ロックが獲得できない間無限ループによってロックの解放を待つような仕組みのことです。システムコールが不要で実装が単純という特徴があります。かわりに、ロック待ち時間が長い状況 (high contention) ではCPU資源を無駄に消費する可能性があります。
(※Rustのミューテックスは、「本来の意味でのミューテックス + ミューテックスが保護するデータ」のセットで提供されているため、 Mutex<T> という型をもちます。)
use std::cell::UnsafeCell;
use std::ops::{Deref, DerefMut};
use std::sync::atomic::{AtomicBool, spin_loop_hint};
use std::sync::atomic::Ordering::SeqCst;
pub struct Mutex<T> {
// 本来の意味でのミューテックス。
// 「ロックされていない」「ロックされている」の2状態のみからなる。
locked: AtomicBool,
// ミューテックスが保護するデータ。
inner: UnsafeCell<T>,
}
// ミューテックスがスレッドセーフであると宣言する
unsafe impl<T: Send> Send for Mutex<T> {}
unsafe impl<T: Send> Sync for Mutex<T> {}
impl<T> Mutex<T> {
pub fn new(value: T) -> Mutex<T> {
Self {
// 初期状態ではロックされていない
locked: AtomicBool::new(false),
inner: UnsafeCell::new(value),
}
}
pub fn lock(&self) -> MutexGuard<'_, T> {
loop {
// 「ロックされているか調べ、されていなかったらロックを取得する」
// という処理をする。
// ただし、一気にやらないと競合状態が発生してしまう。
// Compare-and-swapによって上記を一度に行う。
let old_locked = self.locked.compare_and_swap(false, true, SeqCst);
// 戻り値は元の値。
if old_locked != false {
// 元の値がtrue → 他の人がロックしていた。
// 無限ループによって次の機会を待つ。
spin_loop_hint();
continue;
}
// 元の値がfalse → ロック成功
break;
}
MutexGuard {
locked: &self.locked,
inner: unsafe { &mut *self.inner.get() },
}
}
}
// ロックを保持するRAIIガード
pub struct MutexGuard<'a, T> {
locked: &'a AtomicBool,
inner: &'a mut T,
}
impl<T> Drop for MutexGuard<'_, T> {
fn drop(&mut self) {
// アンロック時は競合状態は気にしなくてよいので、単にfalseを保存する。
self.locked.store(false, SeqCst);
}
}
impl<T> Deref for MutexGuard<'_, T> {
type Target = T;
fn deref(&self) -> &Self::Target {
self.inner
}
}
impl<T> DerefMut for MutexGuard<'_, T> {
fn deref_mut(&mut self) -> &mut Self::Target {
self.inner
}
}
ポイントは Mutex::lock 内の以下の処理です。
loop {
// 「ロックされているか調べ、されていなかったらロックを取得する」
// という処理をする。
// ただし、一気にやらないと競合状態が発生してしまう。
// Compare-and-swapによって上記を一度に行う。
let old_locked = self.locked.compare_and_swap(false, true, SeqCst);
// 戻り値は元の値。
if old_locked != false {
// 元の値がtrue → 他の人がロックしていた。
// 無限ループによって次の機会を待つ。
spin_loop_hint();
continue;
}
// 元の値がfalse → ロック成功
break;
}
ここに出てくる AtomicBool::compare_and_swap はCASと呼ばれ、アトミック変数を使った処理では欠かせないプリミティブです。LL-SCなどの亜種を含めると、CASは(本稿で扱うような)CPUでは必ず実装されています。
今回やりたいことは**「false だったら true に変更する、そうでなかったら何もしない (成功/失敗を報告する)」**という処理なので、 compare_and_swap はほぼそのまま使えます。その上で、書き込み失敗 (ロック済み) だったらループの先頭に戻ります。より一般的に、複雑なアトミック操作はCAS loopという手法を用いて実装することができます。
勘のいい人は気付いたかもしれませんが、この処理は compare_and_swap を使わずに以下のように書くこともできます。
// trueを保存し、元の値を返す
let old_locked = self.locked.swap(true, SeqCst);
しかしこれは一般性に乏しい (たまたま2値しかないために使える・後述するメモリ順序を弱くしたときに意図した挙動にならない) ことから、ここではこの書き方は推奨しないことにします。
非アトミック変数とデータ競合
アトミックについてわかったところで、最初のPythonのコードを思い出しましょう。
counter += 1
このコードは「counter から値を読み取る」→「読み取った値に1を足す」→「counter に書き込む」という処理でした。そして、この一連の操作の途中で割り込まれることが問題だったわけですが、「読み取る」操作の途中や「書き込む」操作の途中で割り込まれる可能性は考えていませんでした。(そして実際のところ、そうした割り込みはないことが期待されているはずです。) その意味では、多くのプログラミング言語の変数は読み込み(ロード)と保存(ストア)だけできるアトミック変数とみなせます。
一方C/C++やRustの通常の変数は最適化のために真の非アトミック変数とみなされます。たとえば、以下のプログラムは非アトミックなグローバル変数を0にリセットする処理をしています。 (ここでは例示のために static mut を使っていますが、大変危険なので実用するのはおすすめしません。)
# [used]
static mut FROB: [u32; 100] = [0; 100];
pub unsafe fn f() {
FROB = [0; 100];
}
これは以下のようにコンパイルされることがあります。 https://godbolt.org/z/bXnBH3
example::f:
lea rdi, [rip + example::FROB]
mov edx, 400
xor esi, esi
jmp qword ptr [rip + memset@GOTPCREL]
example::FROB:
.zero 400
mov ではなく memset を呼ぶ処理に変換されています。このような最適化をmemcpyoptといいます。memcpyやmemsetは中でワード単位でコピーする保証はないため、これはアトミックに動作するとは限りません。途中のバイトまで書き込まれた値を他のスレッドが読む可能性があるからです。
他にも、順序の入れ替えなど多くの最適化を可能にするために、C/C++やunsafe Rustでは以下のルールが用意されています。
- 以下の条件を満たす2つのメモリ操作の組み合わせはデータ競合 (data race) を引き起こす。
- 2つの操作は、同じメモリ領域(重複するメモリ領域)に対する操作である。
- 少なくともどちらかの操作は、非アトミックな操作である。
- 少なくともどちらかの操作は、書き込みをともなう操作である。
- 2つの操作は同期されていない(happens before関係にない)。
- データ競合は未定義動作である。つまり、コンパイラはデータ競合がないものとして最適化をしてよく、実際にデータ競合があった場合のプログラムの動作は全く予期しないものになる可能性がある。
たとえば、以下のコードは未定義動作を含んでいます。 (試すには compile_error! の行をコメントアウトしてください)
use std::thread::spawn;
static mut COUNTER: usize = 0;
fn count_up() {
for _ in 0..50000000 {
// 「1を足す」操作を非アトミックに行う
unsafe {
COUNTER += 1;
}
}
}
compile_error!("This sample code implies UB! Don't use it in real software.");
fn main() {
let thread = spawn(count_up);
count_up();
thread.join().unwrap();
eprintln!("counter = {}", unsafe { COUNTER });
}
しかし、実際にはこのコードをReleaseモードでビルドすると、むしろ想定に近い出力(100000000)をしてくれます。理由はアセンブリを見るとわかります: https://godbolt.org/z/LTtRHJ
example::count_up:
mov rax, qword ptr [rip + example::COUNTER@GOTPCREL]
add qword ptr [rax], 50000000
ret
example::COUNTER:
.zero 8
count_up のループが丸め上げられて、単なる「50000000を足す処理」になっています。同期されていないCPU命令になっていますが、この行は全体で2回しか実行されないので、同時に実行される確率はほぼ0です。たまたま最適化が適度に効いて、たまたまうまくいったわけですが、このように強力な最適化が効くのも非アトミック性のおかげだと考えられます。
読み取り専用の非アトミック変数
データ競合の条件に以下が含まれているのに気付いたでしょうか。
- 少なくともどちらかの操作は、書き込みをともなう操作である。
このルールは以下のような使い方を許容するのに必要です。
// 非アトミックだが読み取り専用なので、複数のスレッドから安全に利用できる
static STEP: usize = 1;
弱いメモリ順序
「逐次一貫のアトミック変数」は最も強い保証、「非アトミック変数」は最も弱い保証を提供してくれます。しかし、よりよくプログラムを最適化するためには、さらに細かい保証レベルがあったほうが便利なこともあります。このために用意されているのが**メモリ順序 (Memory Ordering)**という概念です。Rustは以下の5種類のメモリ順序を提供しています。
-
Relaxed... 同期を行わない。最弱。 -
Acquire... 読み取り操作を、対応するRelease書き込みと同期する。 -
Release... 書き込み操作を、対応するAcquire読み取りと同期する。 -
AcqRel... 読み取り部分をAcquire、書き込み部分をReleaseとして扱う。 -
SeqCst...AcqRelに加えて、逐次一貫モデルに基づく順序を保証する。最強。
x86の場合
比較のために、以下のコードをコンパイルしてみます。
use std::sync::atomic::AtomicUsize;
use std::sync::atomic::Ordering::{Acquire, Relaxed, Release, SeqCst};
pub fn f_seq_cst(p: &AtomicUsize, q: &AtomicUsize) -> usize {
p.store(1, SeqCst);
q.load(SeqCst)
}
pub fn f_acq_rel(p: &AtomicUsize, q: &AtomicUsize) -> usize {
p.store(1, Release);
q.load(Acquire)
}
pub fn f_relaxed(p: &AtomicUsize, q: &AtomicUsize) -> usize {
p.store(1, Relaxed);
q.load(Relaxed)
}
pub fn f_nonatomic(p: &mut usize, q: &mut usize) -> usize {
*q = 1;
*p
}
結果は以下の通りです。 https://godbolt.org/z/nSk487
example::f_seq_cst:
mov eax, 1
xchg qword ptr [rdi], rax
mov rax, qword ptr [rsi]
ret
example::f_acq_rel:
mov qword ptr [rdi], 1
mov rax, qword ptr [rsi]
ret
example::f_relaxed:
mov qword ptr [rdi], 1
mov rax, qword ptr [rsi]
ret
example::f_nonatomic:
mov qword ptr [rsi], 1
mov rax, qword ptr [rdi]
ret
SeqCstの場合だけ結果が違うのがわかるでしょうか。x86では逐次一貫性を確保するために、アトミック書き込みに mov ではなく xchg を使っているようです。Jeff Preshing氏の記事によると、これはx86がある種のメモリ操作の並び替えを許しているからだそうです。上の関数を参考に、以下のコードを考えます。(これも同記事から取った例です)
use std::sync::atomic::AtomicUsize;
use std::sync::atomic::Ordering::{Acquire, Release};
use std::thread::spawn;
fn f(p: &AtomicUsize, q: &AtomicUsize) -> usize {
p.store(1, Release);
q.load(Acquire)
}
static X: AtomicUsize = AtomicUsize::new(0);
static Y: AtomicUsize = AtomicUsize::new(0);
fn main() {
// スレッド2を立ち上げる
let th = spawn(|| f(&X, &Y));
// スレッド1でも同時に処理をする
let x = f(&Y, &X);
// スレッド2を待ち、結果を出力する
let y = th.join().unwrap();
eprintln!("(X, Y) = ({}, {})", x, y);
}
さて、これは何を出力する可能性があるでしょうか。0と1しか代入していないので考えられるのは4通りです。
逐次一貫性のもとでは、(0, 1), (1, 0), (1, 1) の3通りしか考えられません。理由は簡単です。スレッド1の store 処理とスレッド2の store 処理の実行順序で場合分けして考えてみます。
- もしスレッド1の
storeが先だった場合 ... 「スレッド1のstore→ スレッド2のstore→ スレッド2のload」がこの順で実行されることは確実です。そのため、スレッド2のloadはスレッド1のstoreが保存した1を観測するはずです。そのため考えられる結果は (0, 1) か (1, 1) のどちらかです。 - もしスレッド2の
storeが先だった場合 ... 「スレッド2のstore→ スレッド1のstore→ スレッド1のload」がこの順で実行されることは確実です。そのため、スレッド1のloadはスレッド2のstoreが保存した1を観測するはずです。そのため考えられる結果は (1, 0) か (1, 1) のどちらかです。
ところが、上記のソースコードのように AcqRel 以下のメモリ順序を指定した場合、実際には (0, 0) がありえるというのです。それはCPUが仕様の許す範囲内で命令を並び替えるから、そしてその仕様はデフォルトでは逐次一貫よりも緩い挙動として指定されているからです。この場合は store と load が異なるメモリ領域を指しているため、 store の結果がグローバルに反映される前に load が読み込みを開始することが許されています。
ARMの場合
ARMなどRISC系のCPUを中心として、デフォルトの同期保証がより弱いものが存在しています。そのようなCPUでは Acquire/Release と Relaxed で異なる挙動をする場合があります。
実際に32bit ARMv7で先ほどのコードをコンパイルしてみます。 https://godbolt.org/z/sx8P_5
example::f_seq_cst:
mov r2, #1
dmb ish
str r2, [r0]
dmb ish
ldr r0, [r1]
dmb ish
bx lr
example::f_acq_rel:
mov r2, #1
dmb ish
str r2, [r0]
ldr r0, [r1]
dmb ish
bx lr
example::f_relaxed:
mov r2, #1
str r2, [r0]
ldr r0, [r1]
bx lr
example::f_nonatomic:
mov r2, #1
str r2, [r1]
ldr r0, [r0]
bx lr
コンパイラによる並び替え
上記のようなCPUによる並び替えの他に、メモリ順序が弱いことによってコンパイラがメモリ操作を並び替えることが可能になる場合があります。ただしLLVMはmonotonic (RustでいうRelaxed) より弱いunorderedというメモリ順序があり、unordered程度の強さでないとほとんど並び替えは行わないようです。
Acquire / Release を使ったミューテックス
Acquire / Release のインフォーマルな定義をあらためて書きます。
Acquire... 読み取り操作を、対応するRelease書き込みと同期する。Release... 書き込み操作を、対応するAcquire読み取りと同期する。
この名前はロックの取得 (acquire)・解放 (release)となぞらえて理解することができます。ただしここでいう「(AcquireとRelease)の対応」とは「ロック→アンロック」ではなく、「アンロック→次のロック」の対応関係であることに注意が必要です。次の4つの操作がこの順序で観測されることを保証するのがミューテックスにおけるAcquire / Releaseのポイントです。
- (すでにロックを取得している) スレッドAが、非アトミックな操作をする。
↓ (スレッド内順序) - スレッドAが、ロックを解放する。 (Release書き込み)
↓ (Release-Acquire同期) - スレッドBが、ロックを取得する。 (Acquire読み込み+Relaxed書き込み)
↓ (スレッド内順序) - スレッドBが、非アトミックな操作をする。
Release-Acquire間の同期によって、最初の操作と最後の操作の間に順序関係 (happens-before) が保証されます。これによって、この2つの操作が非アトミックでありながらデータ競合にならないこともまた保証されるというわけです。
これを使うと、スピンロックの実装をより効率的にすることができます。
use std::cell::UnsafeCell;
use std::ops::{Deref, DerefMut};
use std::sync::atomic::{AtomicBool, spin_loop_hint};
use std::sync::atomic::Ordering::{Acquire, Release};
pub struct Mutex<T> {
// 本来の意味でのミューテックス。
// 「ロックされていない」「ロックされている」の2状態のみからなる。
locked: AtomicBool,
// ミューテックスが保護するデータ。
inner: UnsafeCell<T>,
}
// ミューテックスがスレッドセーフであると宣言する
unsafe impl<T: Send> Send for Mutex<T> {}
unsafe impl<T: Send> Sync for Mutex<T> {}
impl<T> Mutex<T> {
pub fn new(value: T) -> Mutex<T> {
Self {
// 初期状態ではロックされていない
locked: AtomicBool::new(false),
inner: UnsafeCell::new(value),
}
}
pub fn lock(&self) -> MutexGuard<'_, T> {
loop {
// 「ロックされているか調べ、されていなかったらロックを取得する」
// という処理をする。
// ただし、一気にやらないと競合状態が発生してしまう。
// Compare-and-swapによって上記を一度に行う。
// 直前のアンロックと同期するためにAcquireを指定する。
let old_locked = self.locked.compare_and_swap(false, true, Acquire);
// 戻り値は元の値。
if old_locked != false {
// 元の値がtrue → 他の人がロックしていた。
// 無限ループによって次の機会を待つ。
spin_loop_hint();
continue;
}
// 元の値がfalse → ロック成功
break;
}
MutexGuard {
locked: &self.locked,
inner: unsafe { &mut *self.inner.get() },
}
}
}
// ロックを保持するRAIIガード
pub struct MutexGuard<'a, T> {
locked: &'a AtomicBool,
inner: &'a mut T,
}
impl<T> Drop for MutexGuard<'_, T> {
fn drop(&mut self) {
// アンロック時は競合状態は気にしなくてよいので、単にfalseを保存する。
// 次のロックと同期するためにReleaseを指定する。
self.locked.store(false, Release);
}
}
impl<T> Deref for MutexGuard<'_, T> {
type Target = T;
fn deref(&self) -> &Self::Target {
self.inner
}
}
impl<T> DerefMut for MutexGuard<'_, T> {
fn deref_mut(&mut self) -> &mut Self::Target {
self.inner
}
}
フェンス
アトミック変数を用いて同期を行うには、アトミック操作そのものにRelease/Acquire以上のメモリ順序を指定するほかに、フェンス (fence) を使う方法もあります。
フェンスは(メモリ順序指定以外に)引数・戻り値のない単純な関数で、その前後のアトミック操作を他のスレッドと同期させる効果があります。たとえば、スレッド1で
// ←この位置の操作が同期対象
fence(Release);
// ←この位置の操作は同期されない
X.store(false, Relaxed);
を行い、その結果をスレッド2の以下の処理
X.compare_and_swap(false, true, Relaxed); // => false
// ←この位置の操作は同期されない
fence(Acquire);
// ←この位置の操作が同期対象
が読み取ったとします。このとき2つのフェンス命令に同期関係が成立し、スレッド1の fence より前の操作はスレッド2の fence 以降の操作で読み取れるようになります。
これは以下の点で通常のアトミック操作よりも強力な同期を提供します。
- 特定のメモリ領域を指定せず、前または後に実行された全てのアトミック操作が同期対象になる。
一方、以下の点で通常のアトミック操作よりも弱い同期だとも考えられます。
- メモリ操作のタイミングと同期のタイミングをずらすことができる。 (アトミック操作とフェンスの間に別の処理があった場合、それらの操作は同期の対象にならない)
仕様書を読む
ここまででアトミック操作とメモリ順序についてインフォーマルな理解は得ることができました。しかし、実際により複雑な操作をしようとしたときに、どこまで弱いメモリ順序で大丈夫なのかを考えるのはなかなかに難しいです。そこで、メモリ順序についてより正確な仕様が書かれている文献に当たることを考えます。
Rustの std::sync::atomics には何と書いてあるでしょうか:
Each method takes an
Orderingwhich represents the strength of the memory barrier for that operation. These orderings are the same as the C++20 atomic orderings. For more information see the nomicon.
C++20の規格に丸投げしていますね。
それではC++20の仕様書ドラフト [n4842] を読みましょうと言いたいところですが、その正確な解釈や形式化は仕様書だけでは難しい場合があり、それだけでプログラミング言語の一流のカンファレンスの論文として立派に成立する内容です。ちゃんと読んだわけではないですが例えば [Batty11], [Blanchette11], [Batty16], [Kang17], [Lahav17] などの論文があるようです。
解釈に困ったときはこのような論文を参考にするとよさそうです。
また、Rust側のドキュメントからリンクされているcppreferenceの説明はバージョン間の違いも明記されておりわかりやすいので、こちらを参考にしてもよいでしょう。
以降は仕様書の最新ドラフトをHTML化している http://eel.is/c++draft/ へのリンクを貼りながら解説していきます。
Rust特有の事情: consume
C++の規格を読むにあたって、全ての記述を読むのは時間の無駄です。実は仕様のかなりの部分がconsumeメモリ順序のための定義に割かれています。Rustにはconsumeメモリ順序は定義されていないので、このことを念頭に置いてうまく記述をスキップしたいと思います。 (ただし、crossbeamが独自に定義しているので、これを扱う場合は理解する必要があるかもしれない)
本稿におけるアトミック操作の図示
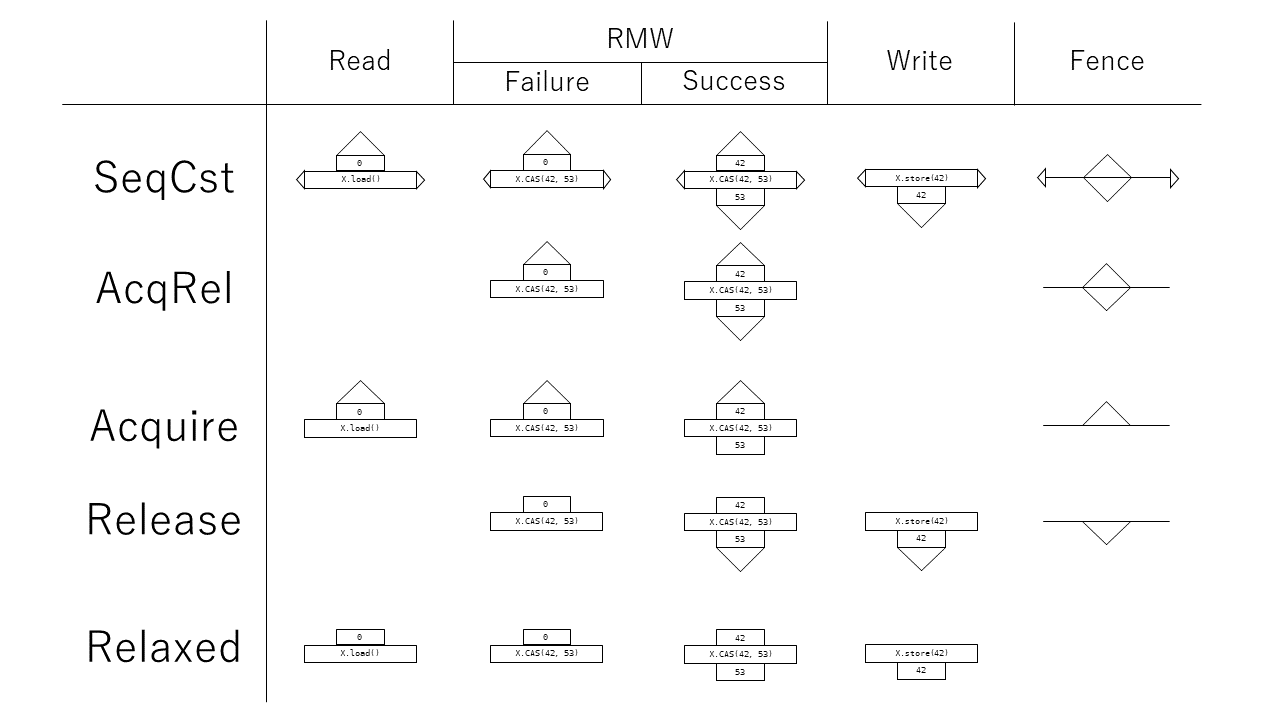
Acquire/ReleaseとLoad/Storeの関係をわかりやすく図示するために、本稿では以下の独自記法を導入します。
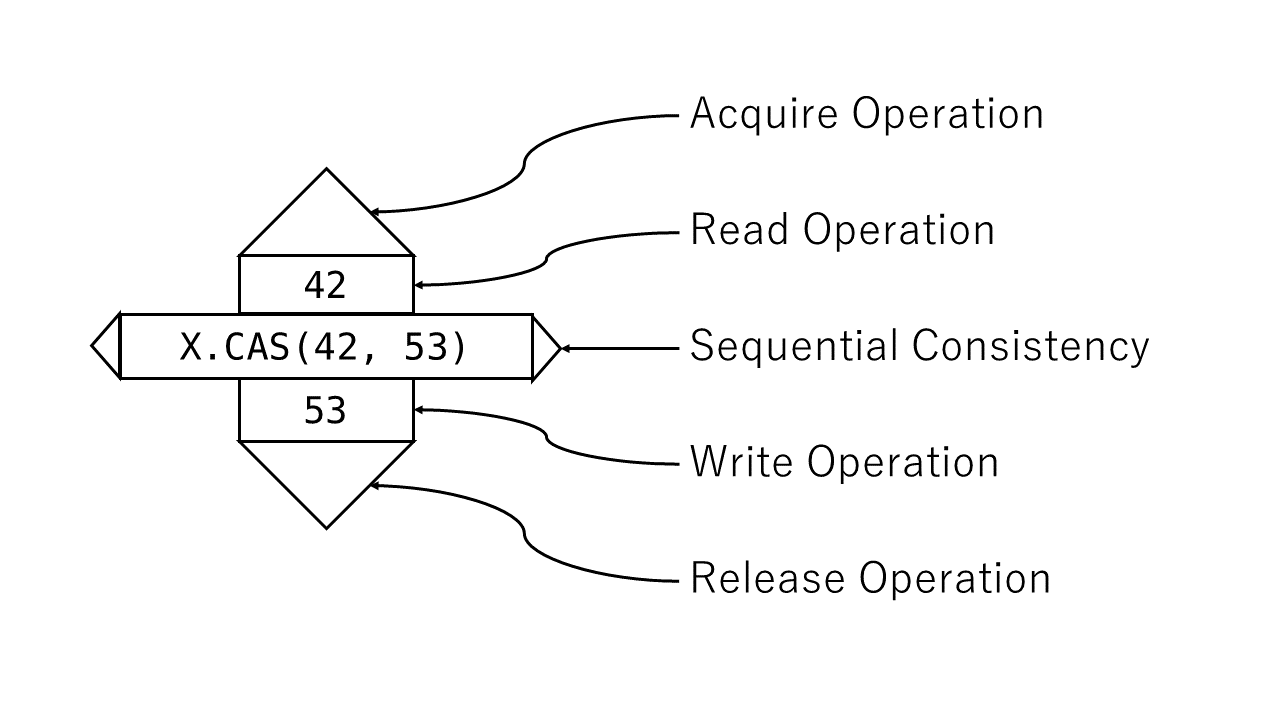
原則としてメモリ操作はスレッド内順序に沿って上から下に記載します。
上側には読み取られた値とAcquire操作の有無をそれぞれ四角形、三角形で図示します。Acquireは読み取り操作に付随するということと、Acquireはそれより前に行われるReleaseと対応づけられるということを表すためにこのように記載しています。
下側には書き込まれた値とRelease操作の有無をそれぞれ四角形、三角形で図示します。Releaseは書き込み操作に付随するということと、Releaseはそれより後に行われるAcquireと対応づけられるということを表すためにこのように記載しています。
横にある三角形はSeqCst制約の有無をあらわしています。
また亜種としてフェンス命令は三角形のついた横棒で記載します。各種命令をそれぞれのメモリ順序で実行した場合、以下のような図になります。
メモリモデルにおける基本的な考え方
まず、仕様を読む前に、ここでの仕様の定義の仕方について大まかに説明してしまいます。
まず、ここで定義するメモリモデルにはループ・分岐・四則演算のようなスレッド内で完結するような内容は出てきません。メモリモデルの仕事は、「共有メモリに対する操作ログが、メモリモデル的にありえるログなのか、ありえないログなのかを判定する(基準を提供する)」ことです。操作ログというのは以下のようなイメージのものです。
- スレッド1の操作ログ:
- スレッド開始。
- メモリ領域
Xに0を非アトミックに書き込んだ。 - メモリ領域
Yに0を非アトミックに書き込んだ。 - スレッド2を起動した。
-
Xから値を読み取った。結果は0だった。 -
Yに1を書き込んだ。 - スレッド2の終了を待機した。
- スレッド終了。
- スレッド2の操作ログ:
- スレッド開始。
-
Yから値を読み取った。結果は0だった。 -
Xに1を書き込んだ。 - スレッド終了。
この操作ログ自身は、書き込んだ値がどのように計算されたのか、読み取った値をどのように利用したのか一切触れていないことに注意してください。実際のプログラムとの整合性は仕様の別の部分で定義されていて、メモリモデルは関与しません。上の例では、例えば以下のようなプログラムのログである可能性があります。
-
Xから値を読み取って、1を足してYに書き込む。 -
Xから値を読み取って、1をORしてYに書き込む。 -
Xから値を読み取って、それとは関係なく1をYに書き込む。
また、逐次一貫よりも弱いモデルを前提にして考えるので、操作ログというのは操作の列というよりもグラフのようなイメージで扱うのがよいでしょう。
もちろん、実際の処理系はわざわざグラフを作ったりしているわけではありません。仕様ではこのような仰々しい抽象機械を定義していますが、実際の処理系はその表面上の動作を真似するように実装されていればOK、という風に考えられています。
メモリ操作とは
たとえば以下の例を考えます。
let x = X.load(SeqCst);
Y.store(x, SeqCst);
これはいくつのメモリ操作からなるでしょうか。
-
X.loadによるXからの読み取り。 -
Y.storeによるYへの書き込み。 - ローカル変数への
xへの書き込みは? -
AtomicUsize::loadの引数self,orderもスタック上に置かれる可能性があります。この書き込みは?読み取りは? -
AtomicUsize::storeの引数self,val,orderも(以下略)
こうして考えるときりがないですが、明らかにスレッド内で完結するものは含めても無視しても大して問題にはなりません。問題を簡単にするために、以下の議論ではこういった操作は基本的に含めないようにします。上の例では X.load と Y.store だけを考えます。
RMW操作の扱い
また、「Read-Modify-Write (RMW) アトミック操作」は1つの操作として数えます。たとえば以下のような操作です。
-
AtomicUsize::swap- 古い値を読み、別の値を書き込み、古い値を返す。
-
AtomicUsize::compare_and_swap- 古い値を読み、それが期待通りだったら別の値を書き込み、古い値を返す。
-
AtomicUsize::fetch_add- 古い値を読み、それに1足した値を書き込み、古い値を返す。
特にRMW操作のひとつである AtomicUsize::swap はWrite操作である AtomicUsize::store の上位互換ですが、WriteとRMWは明確に区別して扱います。WriteとRMWに異なる同期保証を与えるためです。
compare_and_swap のように、失敗する可能性のあるRMW操作は、結果として成功した場合はRMW操作、失敗した場合はRead操作として扱います。操作ログという観点から言うと、「成功した compare_and_swap」と「失敗した compare_and_swap」が別々にあると解釈すればよいはずです。
ライブラリ呼び出しの扱い
ブラックボックス化されているライブラリ呼び出しで、同期効果があるものもメモリ操作に準じて取り扱うことにします。たとえば、
let lock = mutex.lock().unwrap();
というコードでは「mutexのロック」と「アンロック」という2つの操作がありますが、これもマルチスレッドでの挙動を考えるにあたって欠かせないので、メモリ操作に準じて取り扱います。スレッドの立ち上げやスレッドとのjoinも同様です。
二項関係と順序集合
関係を数学的に扱うための基本的な概念を導入しておきます。本節では抽象的な定義しか書かないので、次の節に行ってから必要に応じて戻ってきたほうが手っ取り早いかもしれません。 (ただし、半順序の定義が $<$ を念頭に置いたものになっている点は注意してください。)
二項関係
まずは順序よりも一般的な枠組みとして「二項関係」を導入します。
集合 $A$ と集合 $B$ の**二項関係 (binary relation)**とは、 $A$ の要素と $B$ の要素の組み合わせごとに、関係が成り立つ・成り立たないを定める関数のことです。数学的には $A \times B$ の部分集合として定義されることが多いですが、 $A \times B \to \mathbf{bool}$ という関数だと思っても差し支えありません。以降は $A = B$ の場合しか考えないので、 $A \times A \to \mathbf{bool}$ と考えます。 $R(x, y) = \mathbf{true}$ となることを $x R y$ と書くことがあります。これは $x \leq y$ や $x < y$ という記法を意識しています。
$A \times A \to \mathbf{bool}$ によって定められる二項関係は、有向グラフと呼ばれることもあります。(多重辺を許さない場合)
半順序
二項関係は「順序」というには弱すぎます。そこで以下の2つの性質を考えます。
二項関係 $R$ が推移的 (transitive) であるとは、どんな $x$, $y$, $z$ についても $x R y$ かつ $y R z$ ならば $x R z$ となることです。たとえば実数の $<$ では、「$x < y < z$ なら $x < z$」という性質が成り立ちます。
二項関係 $R$ が非反射的 (irreflexive) であるとは、どんな $x$ についても $R(x, x) = \mathbf{false}$ となることです。たとえば実数の $<$ では、「どんな $x$ についても $x < x$ とはならない」という性質が成り立ちます。
二項関係 $R$ が**(半)順序 ((partial) order)** であるとは、 $R$ が推移的かつ非反射的であることをいいます。
これを聞いて疑問に思った人もいるかもしれません。半順序を「推移的・反射的・反対称的」と定義することも多いからです。前者の方法は $<$ を、後者は $\leq$ を念頭に置いた定義になっていて、反射閉包を取ることで前者の定義と後者の定義を1対1で対応づけることができます。ここでは規格書で前者の方法がとられているのにあわせて「推移的・非反射的」の方針で定義します。
全順序
半順序は、「大小関係が必ず定まるわけではない」という性質があります。実数のように必ず大小関係が決まるような順序は「全順序」という名前で呼ばれています。
二項関係 $R$ が全順序 (total order) であるとは、 $R$ が半順序であって、しかも以下の**全順序性 (totality)**を満たすことを言います: どんな $x$, $y$ についても、 $x R y$, $x = y$, $y R x$ のいずれかが成立する。
推移閉包
順序ではない二項関係から、順序を作りたくなる場合があります。そのときによく使われるのが以下の概念です。
二項関係 $R$ の推移閉包 (transitive closure) $R^+$ は以下のように定義されます: $x R^+ y$ であるとは、ある $z_1, z_2, \ldots, z_n$ ($n > 1$) があって、 $x = z_1$, $z_1 R z_2$, $z_2 R z_3$, ..., $z_{n-1} R z_n$, $z_n = y$ が成立することです。
インフォーマルには、もとの二項関係を加工して、推移的になるようにしたのが推移閉包です。
さて、これが順序になるためにはさらに非反射律を満たす必要がありました。そのために必要なのが以下の条件です。
二項関係 $R$ が非巡回的 (acyclic) であるとは、どのように $x_1, x_2, \ldots, x_n$ ($n > 0$) をとっても、 $x_1 R x_2$, $x_2 R x_3$, ..., $x_{n-1} R x_n$, $x_n R x_1$ とはならないことです。
定理. $R$ が非巡回的であるとき、 $R^+$ は半順序である。
全順序化
半順序から全順序を作ることもできます。
定理. $R$ が半順序であるとき、以下を満たすような全順序 $R'$ が存在する: どんな $x$, $y$ についても、 $x R y$ ならば $x R' y$ である。
証明 有限の場合に関しては帰納法によって示せる。一般の場合に関してはZornの補題によって示せる。
ただし、これは自動的に1個の全順序が決まるということを意味していないことに注意してください。あくまで、そういう全順序が少なくとも1つはあるということだけを主張しています。
同期関係の一般論を定義する
C++の仕様書のメモリ順序の規定は、メモリ順序を理解するという観点からはあまり整理されているとは言えません。そもそも記述が §6.9 (Program Execution) と §31 (Atomic operations library), §32 (Thread support library) に分散しており、この順番に読んでも全体像はあまり掴みやすくはありません。
むしろ、メモリ順序の規定は以下のように大きく3段階に分けるほうが理解しやすいでしょう。
- 同期関係の一般論を定義する
- 同期関係の個別論を定義する
- 逐次一貫性を定義する
本節ではまず同期関係の一般論を定義します。同期関係の一般論は、「sequenced before (sb)とsynchronizes with (sw) から happens before (hb) を定義する」という流れになっています。
Sequenced before (sb)
Sequenced before (sb) 自身はマルチスレッドの概念ではなく、スレッド内実行順序を定めます。そのためこれは §6.9.1 (Sequential Execution) に定義されています。
Sequenced before is an asymmetric, transitive, pair-wise relation between evaluations executed by a single thread ([intro.multithread]), which induces a partial order among those evaluations. Given any two evaluations $A$ and $B$, if $A$ is sequenced before $B$ (or, equivalently, $B$ is sequenced after A), then the execution of $A$ shall precede the execution of $B$.
sequenced beforeは半順序であると規定されています。その後、C++の場合におけるsequenced beforeの成立条件が列挙されています。
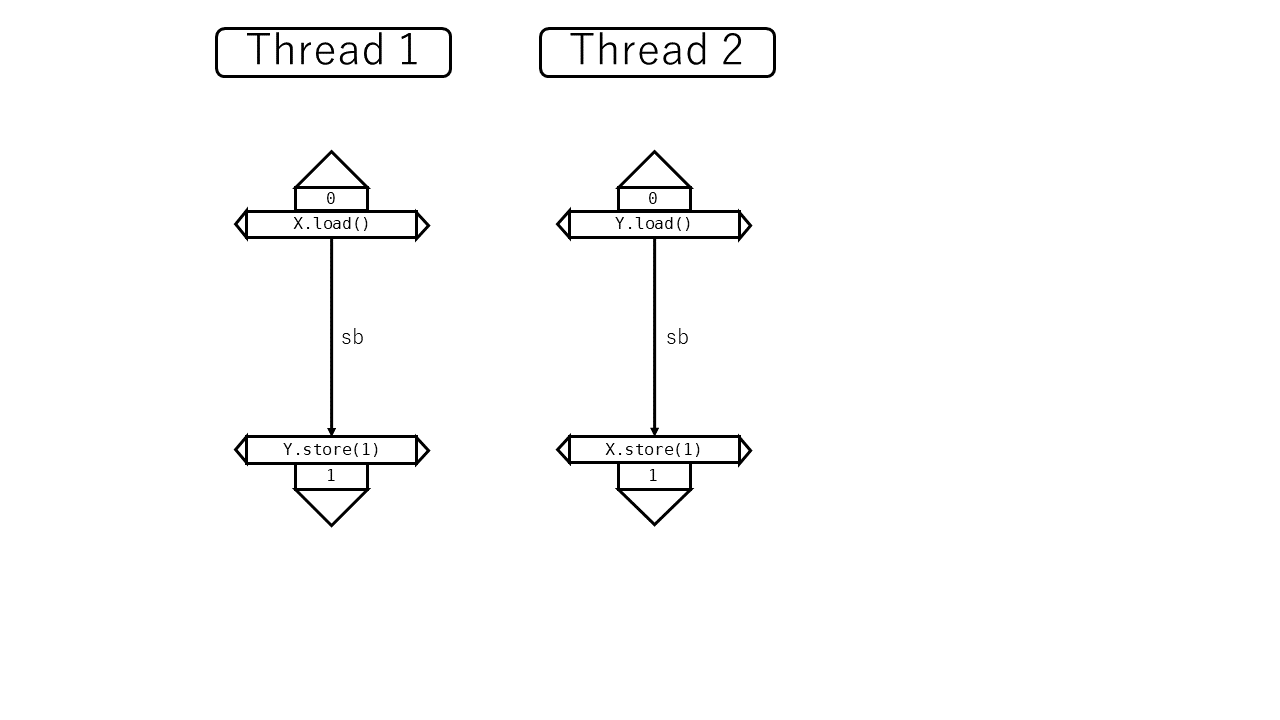
たとえば、以下の例では X.load is sequenced before Y.load といえます。
let x = X.load(SeqCst);
let y = Y.load(SeqCst);
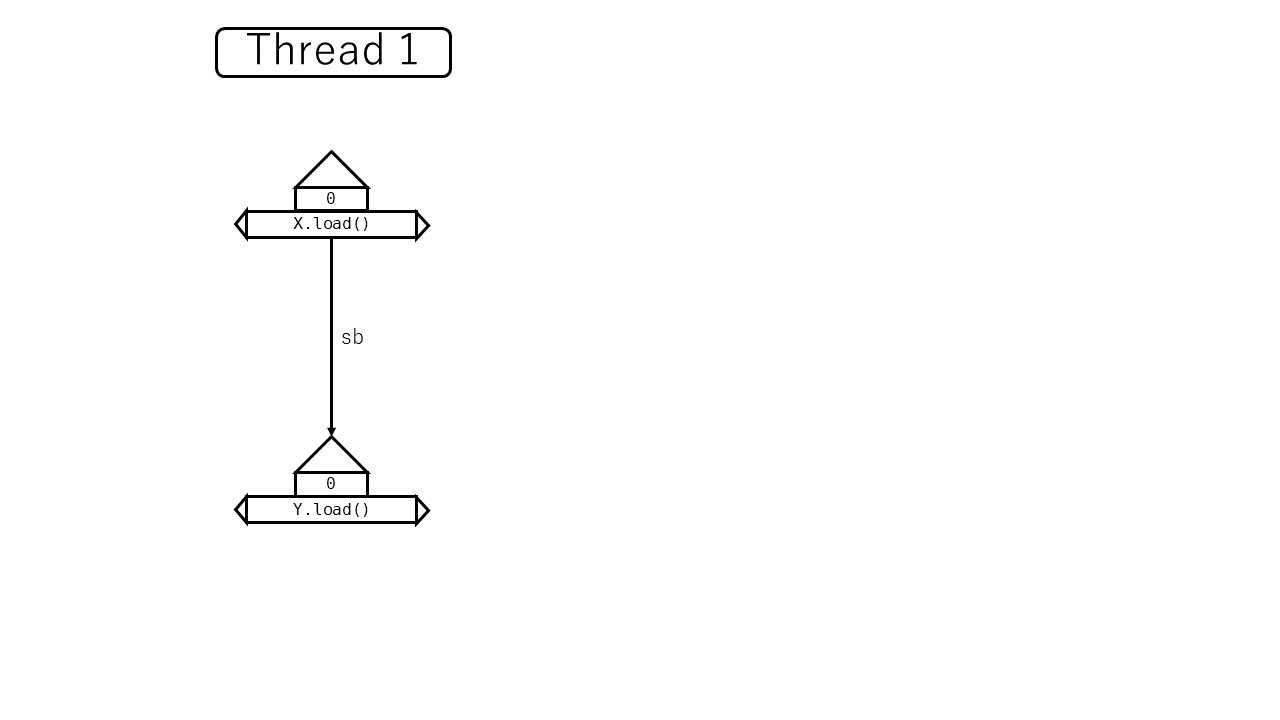
しかし、以下の例では X.load と Y.load の間にsequenced before関係はありません。異なるスレッド間で実行されているからです。 そのかわり、spawn→join→Y.load の3者の間にはこの順にsequenced before関係があります。これらは同じスレッド内でこの順に実行されるからです。
let x = spawn(|| X.load(SeqCst)).join().unwrap();
let y = Y.load(SeqCst);
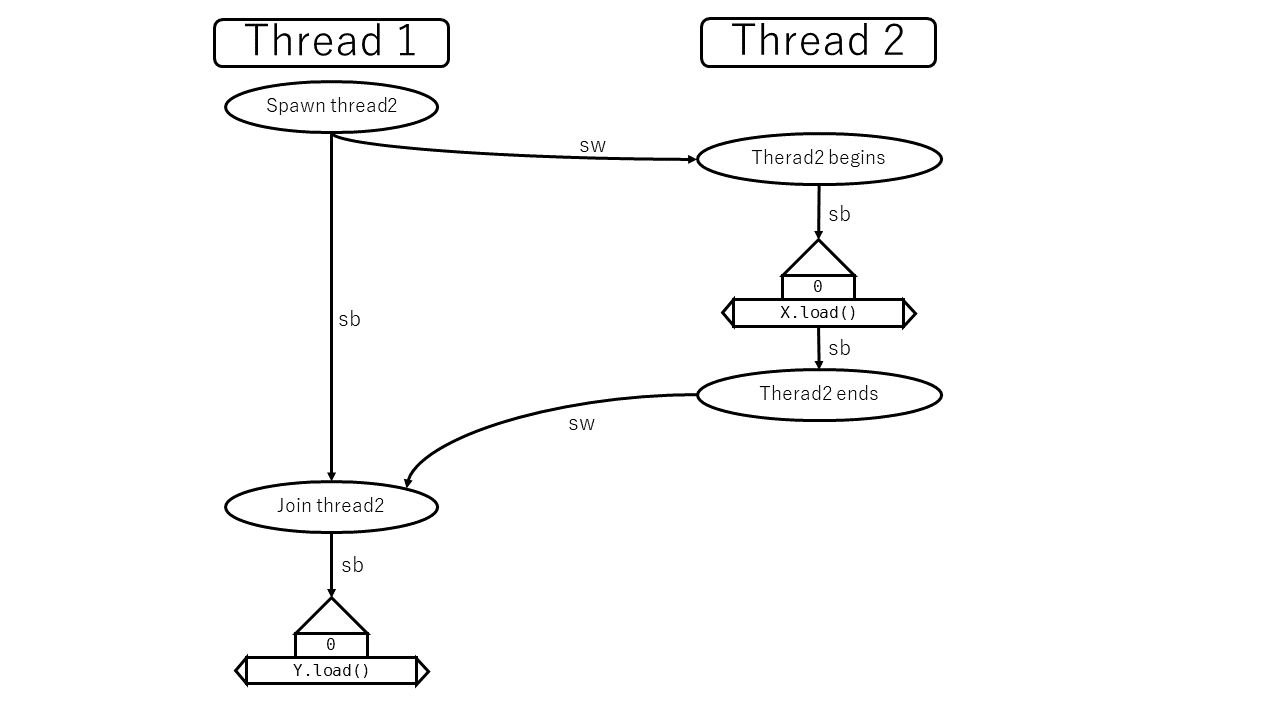
では、スレッド内ではどうでしょうか。
C/C++ではスレッド内の実行順序が確定しないケース (indeterminately sequenced である場合と unsequenced である場合) がありますが、Rustはそうではありません。たとえば、
let z = X.load(SeqCst) + Y.load(SeqCst);
では X.load is sequenced before Y.load が成立します。Rustでは原則として式や文は左(上)から右(下)に評価され、それに依存したプログラムを書いていいことになっています。Rustの仕様書はまだないので推測の域を出ませんが、**Rustでは「各スレッド内のsequenced before関係は全順序である」**とみなして問題ないはずです。
Rustにおけるsequenced beforeの個別の成立条件については、マルチスレッドの議論を逸脱しているのと、この部分が大きく問題になることはないことから、省略します。
Synchronizes with (sw)
Synchronizes with (sw) は名前通り、スレッド間同期が発生するタイミングを記述します。これも二項関係ですが、半順序ではありません。
Certain library calls synchronize with other library calls performed by another thread. For example, an atomic store-release synchronizes with a load-acquire that takes its value from the store ([atomics.order]). [ Note: Except in the specified cases, reading a later value does not necessarily ensure visibility as described below. Such a requirement would sometimes interfere with efficient implementation. — end note ] [ Note: The specifications of the synchronization operations define when one reads the value written by another. For atomic objects, the definition is clear. All operations on a given mutex occur in a single total order. Each mutex acquisition “reads the value written” by the last mutex release. — end note ]
synchronized withの個別の成立条件は次の節で見ていきますが、ひとつ上の行にもあるように例を拾っておきましょう。スレッド1で
X.store(42, Release);
を実行し、スレッド2で
let x = X.load(Acquire); // => 42
を実行した結果、スレッド2がスレッド1の書いた値を読み取ったとします。このとき X.store は X.load と同期する (synchronizes with) と言います。名前から紛らわしいのですが、逆は成立しない (X.load は X.store と同期していない) ことに注意が必要です。
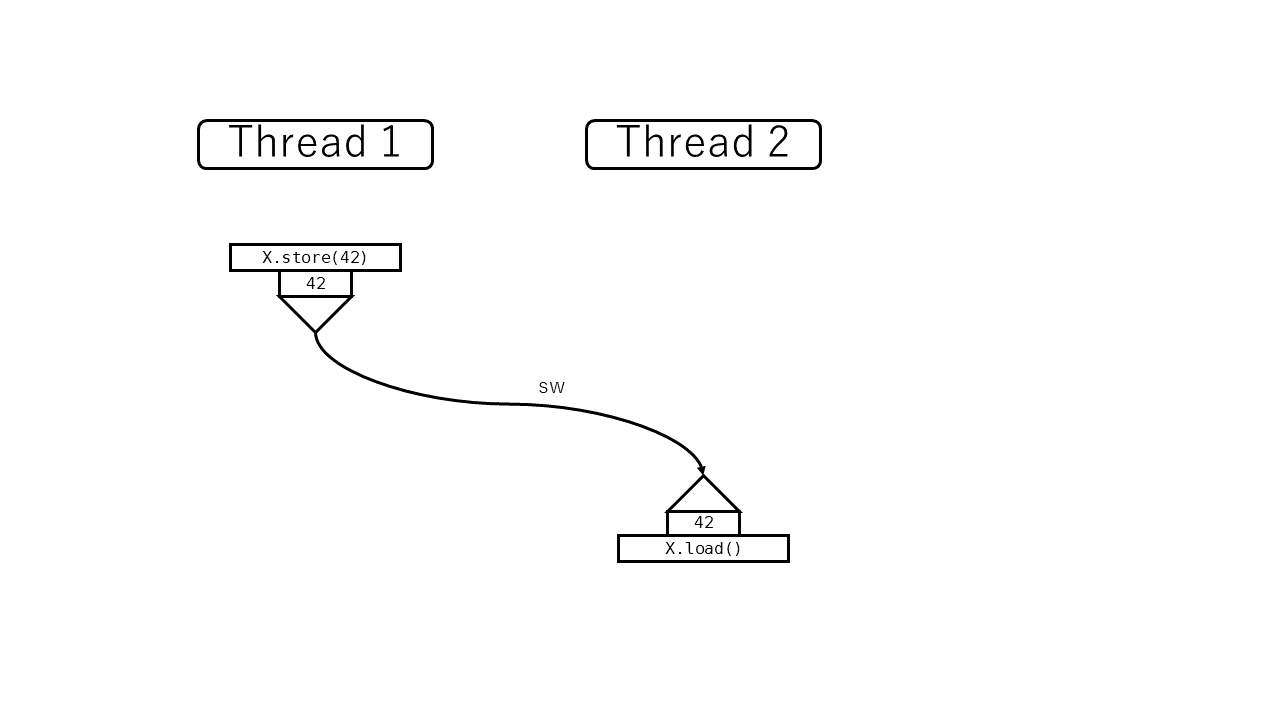
Happens before (hb)
sequenced before と synchronizes with を定義したことで、 happens before (hb) を定義できるようになりました。happens before は、インフォーマルには「同期によって発生した前後関係」です。たとえば、以下の例を考えます。
let thread = spawn(|| {
let mut counter = COUNTER.lock().unwrap();
*counter += 1;
});
{
let mut counter = COUNTER.lock().unwrap();
*counter += 1;
}
thread.join().unwrap();
ここでは以下のメモリ操作(およびライブラリ呼び出し)が発生しています。
- (A) スレッド1による、スレッド2の起動 (spawn)
- スレッド1内での以下の操作
- (B)
COUNTERのロックの取得 - (C)
COUNTER内の値の非アトミック読み取り - (D)
COUNTER内の値への非アトミック書き込み - (E)
COUNTERのロックの解放
- (B)
- スレッド2内での以下の操作
- (F)
COUNTERのロックの取得 - (G)
COUNTER内の値の非アトミック読み取り - (H)
COUNTER内の値への非アトミック書き込み - (I)
COUNTERのロックの解放
- (F)
- (J) スレッド1による、スレッド2の終了待ち (join)
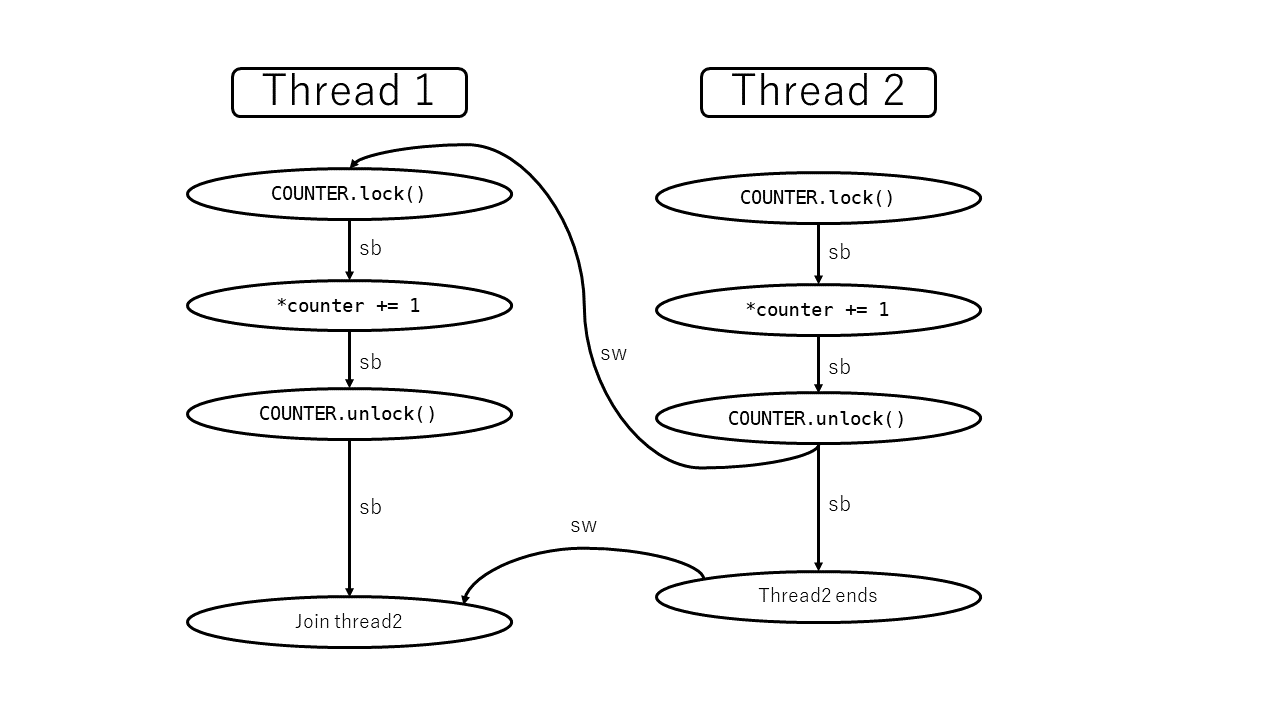
仮に、ロックがスレッド1→スレッド2の順番で取得されたとします。このとき、たとえば (D) happens before (G) が成立します。 (もっと言うと、この場合は (A)→(B)→(C)→(D)→(E)→(F)→(G)→(H)→(I)→(J) の順にhappens before関係にあるとみなせます。)
しかし、何らかの意味で順序が発生したとしても、それが同期によって発生したとはみなされない場合もあります。以下の例を考えます。
let thread = spawn(|| {
X.store(42, SeqCst);
});
X.store(53, SeqCst);
thread.join().unwrap();
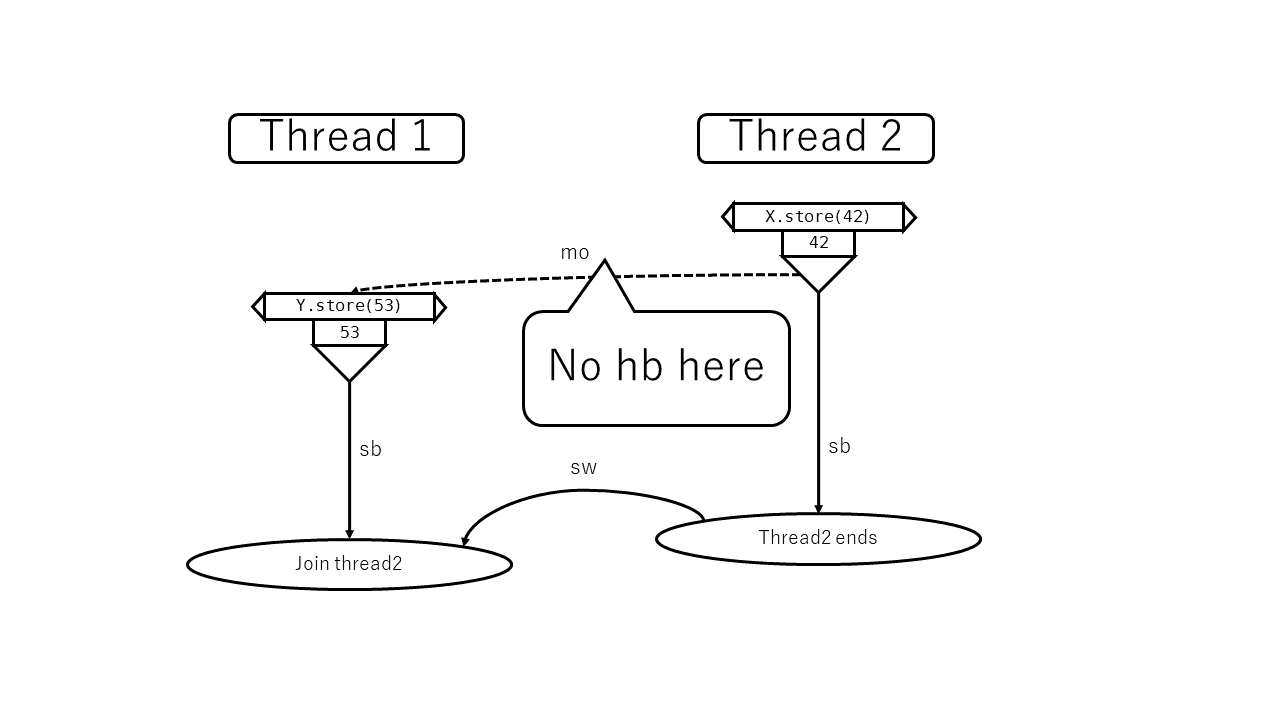
この場合以下の操作が発生しています。
- (A) スレッド1による、スレッド2の起動 (spawn)
- スレッド1内での以下の操作
- (B)
Xへの53の書き込み
- (B)
- スレッド2内での以下の操作
- (C)
Xへの42の書き込み
- (C)
- (D) スレッド1による、スレッド2の終了待ち (join)
このとき、 X の最終的な値は 42 か 53 のどちらかです。仮に42だったとして、 (B) happens before (C) とは言えません。(もちろん (C) happens before (B) でもありません。)
最終的な値が 53 だったときも同様で、 (C) happens before (B) とは言えません。(もちろん (B) happens before (C) でもありません。)
さて、ではそのhappens beforeの定義を見てみましょう。
An evaluation $A$ carries a dependency to an evaluation $B$ if ...
An evaluation $A$ is dependency-ordered before an evaluation $B$ if ...
An evaluation $A$ inter-thread happens before an evaluation $B$ if
- $A$ synchronizes with $B$, or
- $A$ is dependency-ordered before $B$, or
- for some evaluation $X$
- A synchronizes with $X$ and $X$ is sequenced before $B$, or
- A is sequenced before $X$ and $X$ inter-thread happens before $B$, or
- A inter-thread happens before $X$ and $X$ inter-thread happens before $B$.
An evaluation $A$ happens before an evaluation $B$ (or, equivalently, $B$ happens after $A$) if:
- $A$ is sequenced before $B$, or
- $A$ inter-thread happens before $B$.
とても長くて難しそうですね。ところが実はこの部分は丸っと読み飛ばしてOKです。その次の段落を見てみましょう。
An evaluation $A$ simply happens before an evaluation $B$ if either
- $A$ is sequenced before $B$, or
- $A$ synchronizes with $B$, or
- $A$ simply happens before $X$ and $X$ simply happens before $B$.
[ Note: In the absence of consume operations, the happens before and simply happens before relations are identical. — end note ]
consume操作を無視すれば、happens beforeとsimply happens beforeは同じと書いてあります。そしてそのsimply happens beforeは名前のとおりとても単純です。Rustはconsume操作を持たないので、simply happens beforeで考えればよさそうです。
あらためてこのsimply happens beforeの定義を見てみます。3つ目の記述は、推移閉包を取るという操作をするときによく使う記述方法の一つです。結果としてこれは以下のように言い換えられます。
定義. happens before関係は、「sequenced before または synchronizes with である」という関係の推移閉包である。
非巡回性
さて、happens beforeは推移閉包によって定義されていました。わざわざ推移閉包を取るということは、happens beforeを半順序にしたいという意図があると予想されます。
仕様書には、happens beforeが半順序であることが読み取れる記述がいくつかあります。たとえば、
let x = X.load(Acquire);
Y.store(42, Release);
let y = Y.load(Acquire);
X.store(42, Release);
という2つのスレッドがあり、2つの load がどちらも互いの42を読み取る可能性はあるでしょうか。もしそうなった場合、 X.load→Y.store→Y.load→X.store→X.load の順で巡回的にhappens beforeが成立してしまい、反射律に反してしまいそうです。ただしこのケースは、対応するload-store間に逆順のhappens beforeが生じてはいけない、という規則によって除外されます。
ただ、アトミック操作に限らない、同期の一般論として非巡回性を議論している場所は一見した限りではなさそうです。では数学的に形式化する場合はどうでしょうか。[Batty11] で答え合わせしてみましょう。
In any execution, this must be acyclic:
$$ \mathrm{consistent\_inter\_thread\_happens\_before} = \mathrm{irreflexive}(\xrightarrow{\mathit{inter-thread-happens-before}}) $$
明示的に非巡回性を導入していました。CppMemでも consistent_hb という規則で同様の制約が導入されているようです。
同期関係の個別論を定義する
一般論は定義できました。そこで、個別のマルチスレッド処理に関する動作の定義をしていきます。
非アトミック操作
非アトミック操作の挙動を定義する上でまず重要なのがデータ競合の定義です。
Two expression evaluations conflict if one of them modifies a memory location ([intro.memory]) and the other one reads or modifies the same memory location.
-- http://eel.is/c++draft/intro.multithread#intro.races-2
Two actions are potentially concurrent if
- they are performed by different threads, or
- they are unsequenced, at least one is performed by a signal handler, and they are not both performed by the same signal handler invocation.
The execution of a program contains a data race if it contains two potentially concurrent conflicting actions, at least one of which is not atomic, and neither happens before the other, except for the special case for signal handlers described below. Any such data race results in undefined behavior. [ Note: ... — end note ]
今回はシグナルハンドラのことは考えないので一旦無視します。またRustではスレッド内操作はsequencedであることが保証されていると考えられるので、「異なるスレッド」という条件を明記する必要はなさそうです。すると、データ競合は以下の条件で発生することになります。
- ある2つの操作 $A$, $B$ であって、以下の条件を全て満たすものが存在する。
- $A$, $B$ は同じメモリを操作する。
- $A$, $B$ のうちどちらかは書き込み操作を行い、もう一方は書き込みか読み取り操作を行う。
- $A$, $B$ のうち、少なくともどちらかは非アトミック操作である。
- $A$ happens before $B$ でもなければ、 $B$ happens before $A$ でもない。
そして、データ競合が発生した場合は未定義動作です。
ところで、この規定は他の規定とは少し違うことに注意しましょう。他のメモリ順序の規定は、「そもそもそういった動作をすることはない」と宣言することで抽象機械の動作を限定し、それによって実際のプログラムの動作も限定するという働きがありました。しかし、上記の規定は「抽象機械がこのような動作をした場合は、未定義動作とみなす」という規定であるため、実際のプログラムの動作は何でもよいと規定する働きをしています。いずれにせよ、ひとたび未定義動作が発生してしまえば他の規定はどうでもよくなるので、以降はデータ競合が発生しなかった場合のことを考えていきます。
データ競合が発生しなかった場合、その値は以下のように規定されます。
A visible side effect $A$ on a scalar object or bit-field $M$ with respect to a value computation $B$ of $M$ satisfies the conditions:
- $A$ happens before $B$ and
- there is no other side effect $X$ to $M$ such that $A$ happens before $X$ and $X$ happens before $B$.
The value of a non-atomic scalar object or bit-field $M$, as determined by evaluation $B$, shall be the value stored by the visible side effect $A$. [ Note: If there is ambiguity about which side effect to a non-atomic object or bit-field is visible, then the behavior is either unspecified or undefined. — end note ] [ Note: This states that operations on ordinary objects are not visibly reordered. This is not actually detectable without data races, but it is necessary to ensure that data races, as defined below, and with suitable restrictions on the use of atomics, correspond to data races in a simple interleaved (sequentially consistent) execution. — end note ]
データ競合がない以上、状況はとても単純です。端的に言えば直前に代入された値が1つに決まるので、それが観測されるということを規定しています。
アトミック操作
アトミック操作の場合はデータ競合は起きません。かわりに、操作がどのような順番で反映されうるのか、そのありうるパターンを規定する必要があります。その軸になるのが以下の modification order (mo) です。
All modifications to a particular atomic object $M$ occur in some particular total order, called the modification order of $M$. [ Note: There is a separate order for each atomic object. There is no requirement that these can be combined into a single total order for all objects. In general this will be impossible since different threads may observe modifications to different objects in inconsistent orders. — end note ]
各アトミック変数ごとに、書き込み操作の全順序が決まると書いてあります。アトミック操作は基本的にRead, Write, RMWの3種類で、ここではWriteとRMW操作の間に全順序が決まるということを言っています。
また、読み取りについては reads from (rf) という二項関係があります。これは規格書では暗黙的に定義されていますが、[Batty11]などでは明示的に扱われています。あるアトミック読み取り (ReadまたはRMW) がどの書き込み (WriteまたはRMW) の値を読み取るか、ということをあらわす二項関係です。
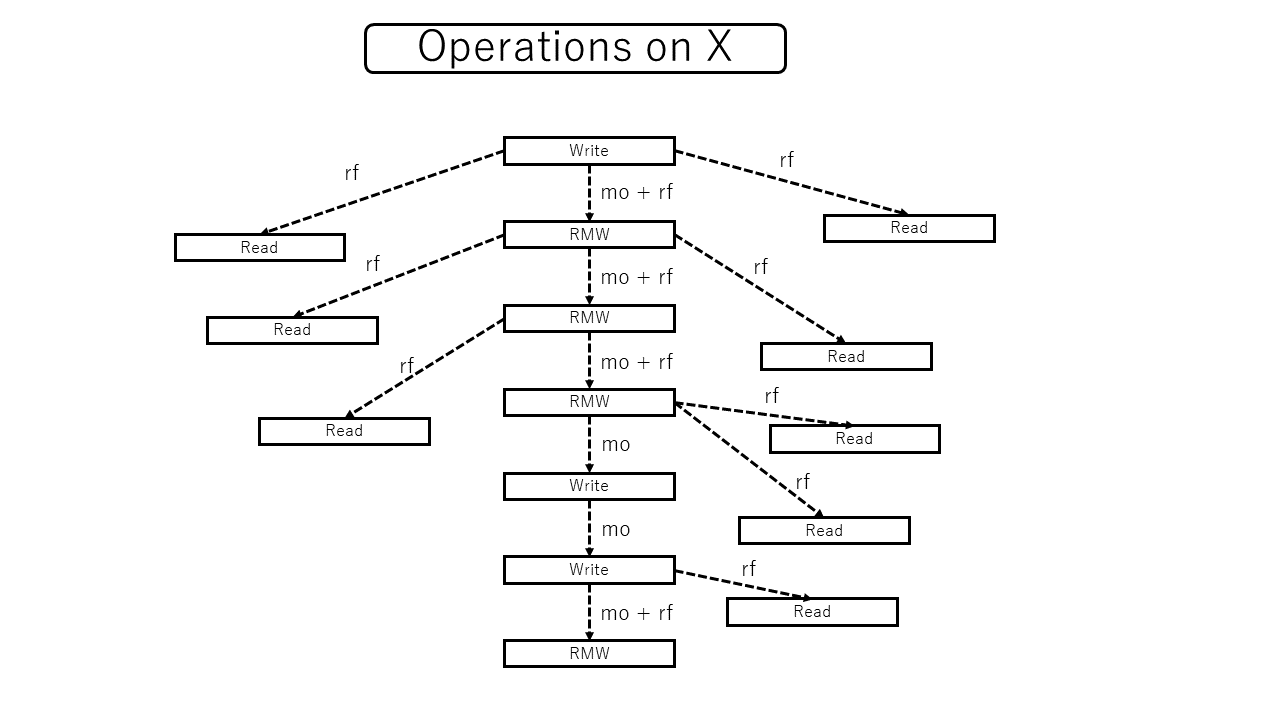
先ほど引用した部分の注釈では、この全順序を全てのオブジェクトの間の全順序に統合することはできないと言っています。本当でしょうか?実際のところ、適当に組み合わせて全順序を作ること自体はできるはずです。しかし、意味のある全順序が作れるとは限りませんよということがここで言いたいようです。その「意味のある」というのを規定するのが次に述べる規定です。
The value of an atomic object $M$, as determined by evaluation $B$, shall be the value stored by some side effect $A$ that modifies $M$, where $B$ does not happen before $A$. [ Note: The set of such side effects is also restricted by the rest of the rules described here, and in particular, by the coherence requirements below. — end note ]
If an operation $A$ that modifies an atomic object $M$ happens before an operation $B$ that modifies $M$, then $A$ shall be earlier than $B$ in the modification order of $M$. [ Note: This requirement is known as write-write coherence. — end note ]
If a value computation $A$ of an atomic object $M$ happens before a value computation $B$ of $M$, and $A$ takes its value from a side effect $X$ on $M$, then the value computed by $B$ shall either be the value stored by $X$ or the value stored by a side effect $Y$ on $M$, where $Y$ follows $X$ in the modification order of $M$. [ Note: This requirement is known as read-read coherence. — end note ]
If a value computation $A$ of an atomic object $M$ happens before an operation $B$ that modifies $M$, then $A$ shall take its value from a side effect $X$ on $M$, where $X$ precedes $B$ in the modification order of $M$. [ Note: This requirement is known as read-write coherence. — end note ]
If a side effect $X$ on an atomic object $M$ happens before a value computation $B$ of $M$, then the evaluation $B$ shall take its value from $X$ or from a side effect $Y$ that follows $X$ in the modification order of $M$. [ Note: This requirement is known as write-read coherence. — end note ]
[ Note: The four preceding coherence requirements effectively disallow compiler reordering of atomic operations to a single object, even if both operations are relaxed loads. This effectively makes the cache coherence guarantee provided by most hardware available to C++ atomic operations. — end note ]
[ Note: The value observed by a load of an atomic depends on the “happens before” relation, which depends on the values observed by loads of atomics. The intended reading is that there must exist an association of atomic loads with modifications they observe that, together with suitably chosen modification orders and the “happens before” relation derived as described above, satisfy the resulting constraints as imposed here. — end note ]
-- http://eel.is/c++draft/intro.multithread#intro.races-14
Atomic read-modify-write operations shall always read the last value (in the modification order) written before the write associated with the read-modify-write operation.
最初の規定で、アトミック読み取り $B$ の結果は、何かしらの書き込み $A$ の結果に由来するという基本的な制約を述べています。さらに、この $A$, $B$ の間に $B$ happens before $A$ という関係は成り立たないということを述べています。もし $B$ happens before $A$ だとすると、同期されているのにもかかわらず時間遡行が発生していることになってしまうからです。
そして、次の4つの規定がコヒーレンス要求と呼ばれる4つの要求です。実は最初の規定はこのコヒーレンス要求のうちread-writeコヒーレンスに含まれると考えることもできます。
- write-writeコヒーレンス: $A$ happens before $B$ なら、modification orderにおいて $A$ の書き込みは $B$ の書き込みよりも手前にある。
- read-readコヒーレンス: $A$ happens before $B$ なら、modification orderにおいて $A$ の読み取る書き込みは $B$ の読み取る書き込みと等しいか手前にある。
- read-writeコヒーレンス: $A$ happens before $B$ なら、modification orderにおいて $A$ の読み取る書き込みは $B$ よりも手前にある。
- write-readコヒーレンス: $A$ happens before $B$ なら、modification orderにおいて $A$ は $B$ の読み取る書き込みと等しいか手前にある。
いずれも「$A$ happens before $B$ なら、modification orderにおいて……」という形式で、happens beforeとmodification orderの関係を述べています。そして、 $A$ が読み取り/書き込みの場合と $B$ が読み取り/書き込みの場合で4つの規則に分かれています。 ($A$, $B$ が RMW 操作の場合は複数の規則が該当します)
最後の規則はRMW操作におけるmodification orderとreads fromの関係を規定しています。これがないと、RMW操作のreadが読み取る元を限定できません。
インフォーマルには、これらの規定によって次のことが保証されます。
- メモリ操作は、各メモリ領域ごとに一貫した順番で実行されているとみなせる。(ただし、グローバルに一貫した順序とは限らない)
- happens before関係が成立するときは、その順番に違反するような結果が得られることはない。
アトミック操作による同期
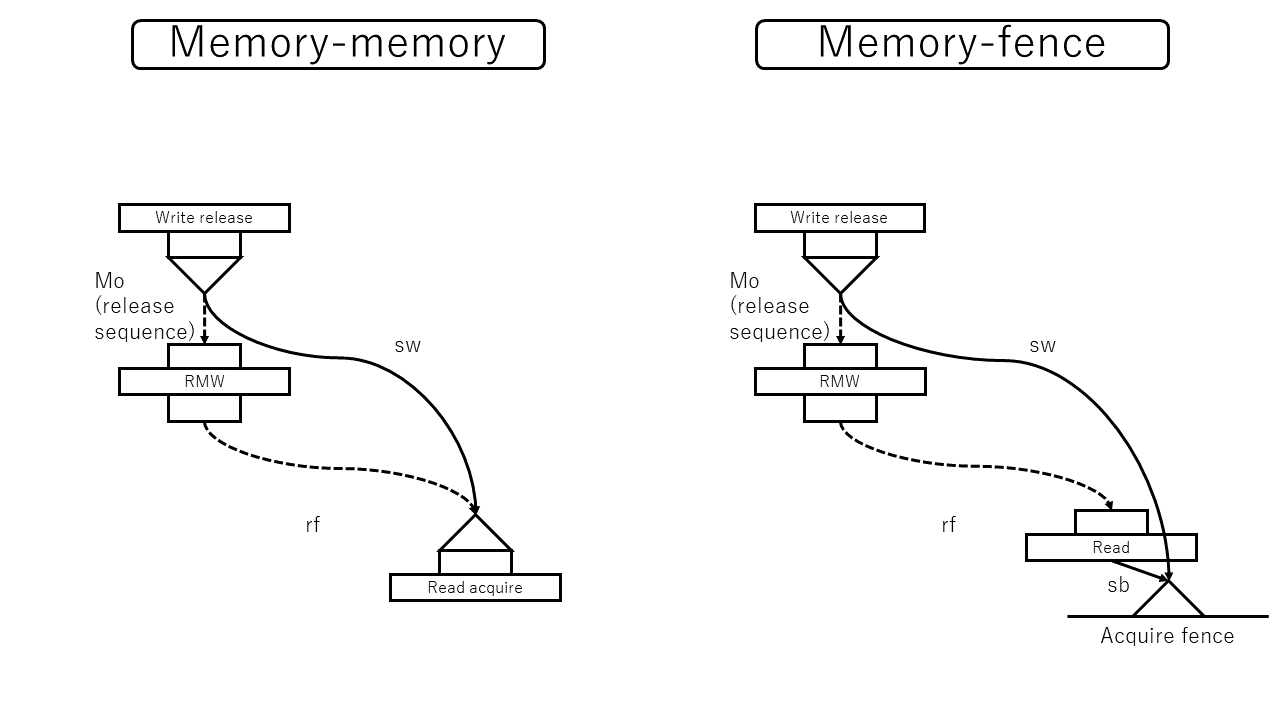
release書き込みと、その値を読むacquire読み取りは同期します。このことを規定しているのが以下の行です。
An atomic operation $A$ that performs a release operation on an atomic object $M$ synchronizes with an atomic operation $B$ that performs an acquire operation on $M$ and takes its value from any side effect in the release sequence headed by $A$.
この文をよく読むと、acquire読み取りは必ずしもrelease書き込み自体の結果を読む必要はなく、後続する書き込みを読んだ場合も条件次第では同期が成立すると書いてあります。その定義が書かれているのが以下の行です。
A release sequence headed by a release operation $A$ on an atomic object $M$ is a maximal contiguous sub-sequence of side effects in the modification order of $M$, where the first operation is $A$, and every subsequent operation is an atomic read-modify-write operation.
modification orderに含まれる操作はWriteかRMWのどちらかですが、RMW操作が続く限りは(仮にそれがRelaxed操作であっても)同期の対象になるということです。逆に言うと単純Write操作をすることでrelease sequenceは途切れるということを意味しています。つまり、スレッド1で
X.store(42, Release);
を行い、スレッド2で
X.fetch_add(11, Relaxed);
を行い、スレッド3で
let x = X.load(Acquire); // => 53
を行って、スレッド3が53 (= 42 + 11) を観測したとします。
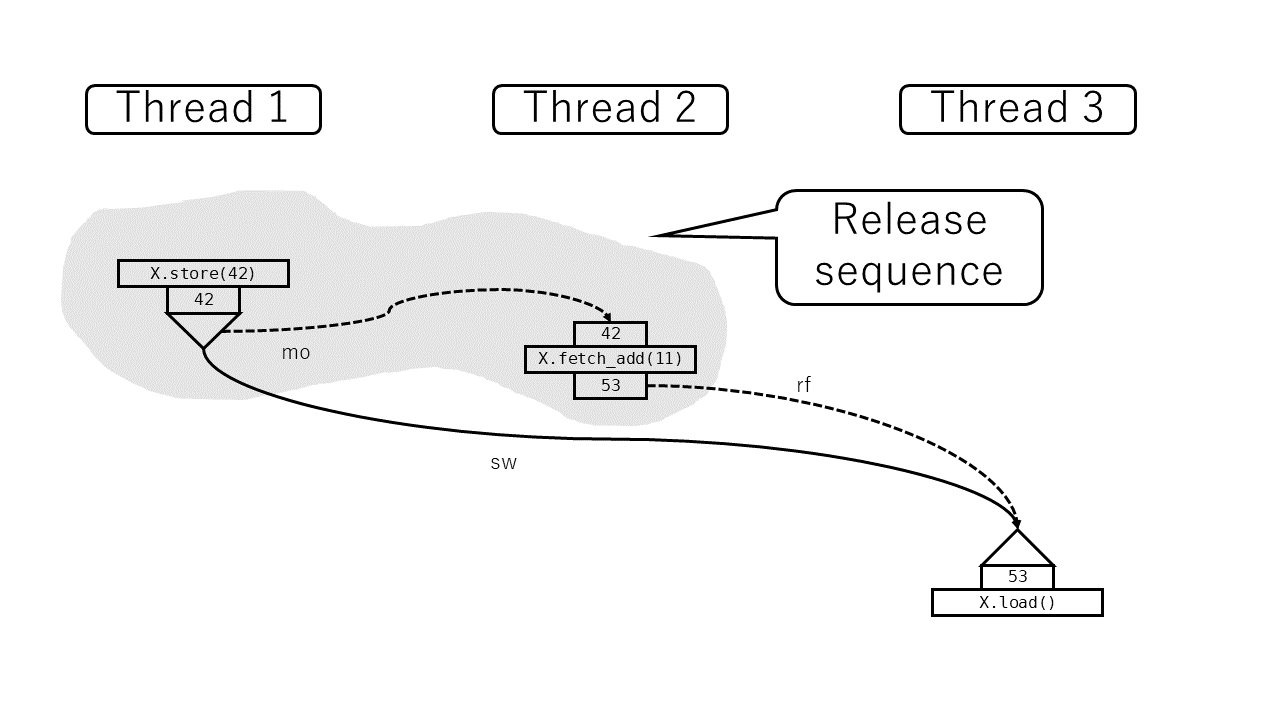
このとき X.store→X.load 間に同期関係が成立します (直接その値を読んでいないにもかかわらず)。
逆に、 X.fetch_add→X.load に同期関係は成立しません。この fetch_add はRelaxedだからです。これはミューテックスよりも複雑な状態管理が必要なときにしばしば有用です。たとえば以下のようなシンプルなスピンロックベースのreader-writerロックを考えます。
- 誰もロックしていないときは
0。 - 書き込みロックがあるときは
1。 - 読み取りロックがあるときは、 (読み取りロックの個数) × 2。
- 飢餓状態に対する対策は行わない。
このとき各操作は以下のようになります。
- 書き込みロック:
state.compare_and_swap(0, 1, Acquire)して、失敗したらやり直し。 - 読み取りロック: CAS loopで実装する。あらかじめ
stateの値をrelaxed loadして予測しておき、偶数だったらstate.compare_and_swap(state, state + 2, Acquire)する。奇数だった場合と、CASに失敗した場合はやり直し。 - 書き込みアンロック:
state.store(0, Release) - 読み取りアンロック:
state.fetch_sub(2, Relaxed)
さて、ここで書き込みアンロック(A)→読み取りロック(B)→読み取りロック(C)の順で操作が成功したとします。このとき (C) は (B) と同期する必要はありませんが、 (A) と同期する必要はあります。release sequenceの規則はこれが期待通りになることを保証してくれるわけです。
ところで、上の規定ではsynchronized withがreads fromに依存しています。そのreads fromの動作はhappens beforeに縛られていて(前小節参照)、そのhappens beforeはsynchronizes withに依存しています(前節参照)。これは循環論法にならないのでしょうか。これは次の注釈で解決されています。
[ Note: The value observed by a load of an atomic depends on the “happens before” relation, which depends on the values observed by loads of atomics. The intended reading is that there must exist an association of atomic loads with modifications they observe that, together with suitably chosen modification orders and the “happens before” relation derived as described above, satisfy the resulting constraints as imposed here. — end note ]
reads fromが最初にあり、そこからhappens beforeが導出される。そして、その導出したhappens beforeがreads fromとコヒーレントであるというのはreads fromに対する制約である、という風に解釈することになっています。
フェンス
フェンスは、自分自身が同期対象であるにもかかわらず、同期されるかどうかは他のアトミック操作に依存するという特性があります。フェンスの同期を規定しているのが以下です。
This subclause introduces synchronization primitives called fences. Fences can have acquire semantics, release semantics, or both. A fence with acquire semantics is called an acquire fence. A fence with release semantics is called a release fence.
A release fence $A$ synchronizes with an acquire fence $B$ if there exist atomic operations $X$ and $Y$, both operating on some atomic object $M$, such that $A$ is sequenced before $X$, $X$ modifies $M$, $Y$ is sequenced before $B$, and $Y$ reads the value written by $X$ or a value written by any side effect in the hypothetical release sequence $X$ would head if it were a release operation.
A release fence $A$ synchronizes with an atomic operation $B$ that performs an acquire operation on an atomic object $M$ if there exists an atomic operation $X$ such that $A$ is sequenced before $X$, $X$ modifies $M$, and $B$ reads the value written by $X$ or a value written by any side effect in the hypothetical release sequence $X$ would head if it were a release operation.
An atomic operation $A$ that is a release operation on an atomic object $M$ synchronizes with an acquire fence $B$ if there exists some atomic operation $X$ on $M$ such that $X$ is sequenced before $B$ and reads the value written by $A$ or a value written by any side effect in the release sequence headed by $A$.
まずフェンスの種類は3種類(acquire, release, または両方)と規定されています。そのあとに3つの規則が規定されていますが、これは
- フェンスとフェンスの同期
- フェンスとアトミック操作の同期
- アトミック操作とフェンスの同期
の3つです。すでに説明した「アトミック操作とアトミック操作の同期」とあわせると4=2×2個あることになります。
acquireフェンスの効果
acquireフェンスまたはacq_relフェンスはスレッド内の先行する読み取りアトミック操作にacquire的な効果を持たせる能力があります。ただし、同期はアトミック操作が行われた瞬間には行われず、フェンスが発生するまで遅延されます。
releaseフェンスの効果
releaseフェンスまたはacq_relフェンスはスレッド内の後続する書き込みアトミック操作にrelease的な効果を持たせる能力があります。ただし、アトミック操作が行われた瞬間ではなく、フェンスが発生した瞬間までの内容しか同期されません。
releaseアトミック操作の効果は後続するrelease sequenceにも影響がありました。これをフェンス由来の同期に対しても定義するために hypothetical release sequence という概念が定義されています。これは簡単で、release sequenceの定義から「先頭のアトミック操作がrelease操作である」という条件を除いたものです。
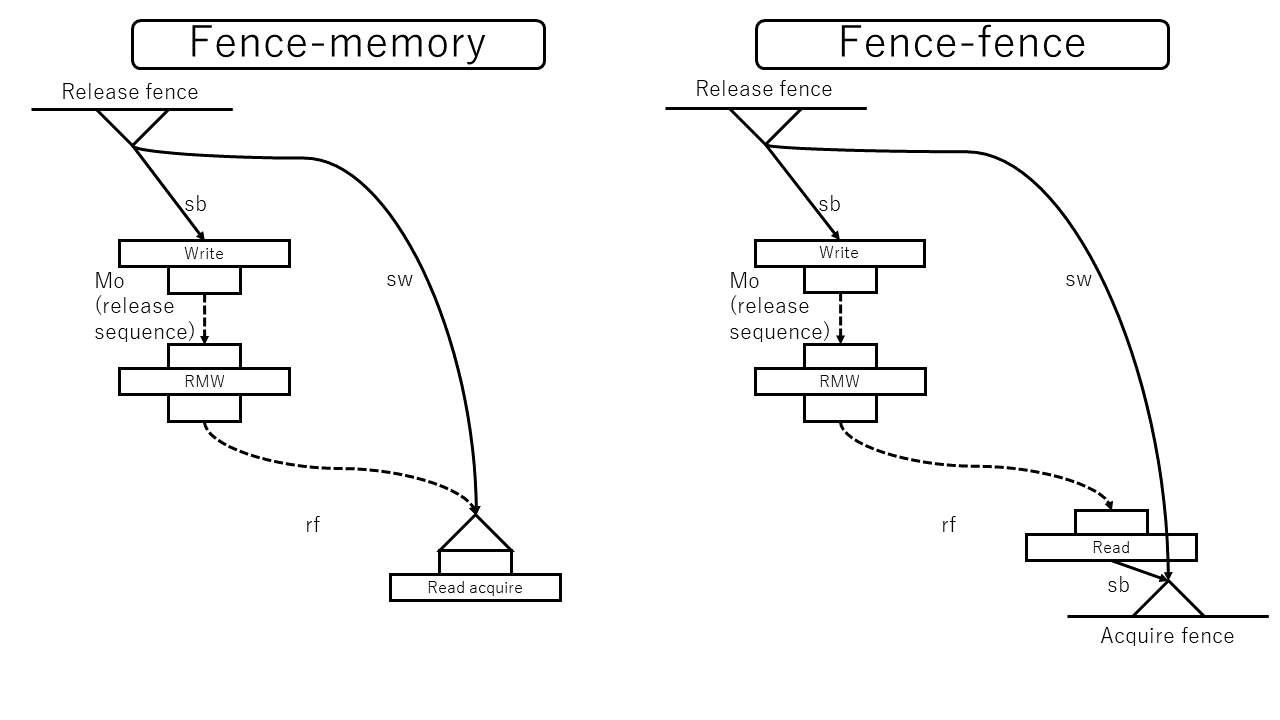
ミューテックス
ミューテックスの挙動についてはミューテックスの節で規定されています。(本来はRust側のドキュメントを参照するべきですが、該当する記述がないためC++のものを参考にします)
The implementation provides lock and unlock operations, as described below. For purposes of determining the existence of a data race, these behave as atomic operations ([intro.multithread]). The lock and unlock operations on a single mutex appears to occur in a single total order. [ Note: This can be viewed as the modification order of the mutex. — end note ] [ Note: Construction and destruction of an object of a mutex type need not be thread-safe; other synchronization should be used to ensure that mutex objects are initialized and visible to other threads. — end note ]
The expression
m.lock()is well-formed and has the following semantics:
- ...
- Synchronization: Prior
unlock()operations on the same object synchronize with ([intro.multithread]) this operation.- ...
The expression
m.try_lock()is well-formed and has the following semantics:
- ...
- Synchronization: If
try_lock()returnstrue, priorunlock()operations on the same object synchronize with this operation. [ Note: Sincelock()does not synchronize with a failed subsequenttry_lock(), the visibility rules are weak enough that little would be known about the state after a failure, even in the absence of spurious failures. — end note ]- ...
The expression
m.unlock()is well-formed and has the following semantics:
- ...
- Synchronization: This operation synchronizes with subsequent lock operations that obtain ownership on the same object.
- ...
unlock が、後続する lock または後続する成功した try_lock と同期することが規定されています。
スレッドの起動と終了
スレッドの起動と終了は以下のような同期関係があります。
- スレッドのspawnは、起動されたスレッドの先頭と同期します。
- スレッドの末尾は、そのスレッドに対する別スレッドのjoin操作と同期します。
後者はRustのドキュメント https://doc.rust-lang.org/std/thread/struct.JoinHandle.html でも言及されています。
In terms of atomic memory orderings, the completion of the associated thread synchronizes with this function returning. In other words, all operations performed by that thread are ordered before all operations that happen after
joinreturns.
逐次一貫性を定義する
逐次一貫性はここまでで見てきた「同期」の概念よりもさらに強いため、今までの定義にレイヤを1つ被せる形で定義していきます。
逐次一貫メモリ順序
ここまではreleaseの有無、acquireの有無に合わせて4種類の順序 (Relaxed, Release, Acquire, AcqRel) を定義してきました。逐次一貫性を保証するために、これに加えてSeqCstという順序を定義します。SeqCstは以下の能力 (ここまで定義した中で一番強い保証 + 逐次一貫性) を持ちます。
- SeqCstなRead操作は、acquire操作としての機能 + 逐次一貫性保証を有する。
- SeqCstなWrite操作は、release操作としての機能 + 逐次一貫性保証を有する。
- SeqCstなRMW操作は、acquire操作としての機能 + release操作としての機能 + 逐次一貫性保証を有する。
- SeqCstなフェンスは、acquire操作としての機能 + release操作としての機能 + 逐次一貫性保証を有する。
このことは以下で定義されています。
The enumeration
memory_orderspecifies the detailed regular (non-atomic) memory synchronization order as defined in [intro.multithread] and may provide for operation ordering. Its enumerated values and their meanings are as follows:
- ...
memory_order::release,memory_order::acq_rel, andmemory_order::seq_cst: a store operation performs a release operation on the affected memory location.- ...
memory_order::acquire,memory_order::acq_rel, andmemory_order::seq_cst: a load operation performs an acquire operation on the affected memory location.
[ Note: ... — end note ]-- http://eel.is/c++draft/atomics.order#1
extern "C" void atomic_thread_fence(memory_order order) noexcept;Effects: Depending on the value of order, this operation:
- ...
- ...
- ...
- ...
- is a sequentially consistent acquire and release fence, if
order == memory_order::seq_cst.
順序 S
SeqCstの目的は、「全部SeqCstで書けば、逐次一貫性が成り立つ」という保証を提供することです。のためにそのものずばり、 sequential consistency (sc) という順序を定義します。仕様書では $S$ と命名されています。
There is a single total order $S$ on all
memory_order::seq_cstoperations, including fences, that satisfies the following constraints. ...
全ての SeqCst 操作の間のグローバルな全順序です。「全部SeqCstで書けば、逐次一貫性が成り立つ」をそのまま実現しようとしていますね。
これはhappens beforeの逐次一貫性版と考えることができます。実際、これがアトミック操作やフェンスとどう関係するかが次に定義されます。
happens beforeとの関係
SeqCstはインフォーマルには全ての同期 + 逐次一貫性なので、**「happens before関係が成立するなら、 $S$ での前後関係が成立する」**という性質が成立してほしいところです。しかし何らかの事情があるようで、例外条件つきの規約になっています。
そのために使われるのが以下の定義です。(同名の定義がC++17以前にもありますが別物なので注意してください)
An evaluation $A$ strongly happens before an evaluation $D$ if, either
- $A$ is sequenced before $D$, or
- $A$ synchronizes with $D$, and both $A$ and $D$ are sequentially consistent atomic operations ([atomics.order]), or
- there are evaluations $B$ and $C$ such that $A$ is sequenced before $B$, $B$ simply happens before $C$, and $C$ is sequenced before $D$, or
- there is an evaluation $B$ such that $A$ strongly happens before $B$, and $B$ strongly happens before $D$.
[ Note: Informally, if $A$ strongly happens before $B$, then $A$ appears to be evaluated before $B$ in all contexts. Strongly happens before excludes consume operations. — end note ]
名前の通り、strongly happens beforeはhappens beforeよりも狭い定義になっています。happens beforeは「sequenced beforeとsynchronizes withを1個以上つなげたもの」でしたが、その両端が以下のどちらかでなければいけないという制約が追加されています:
- sequenced before
- SeqCst操作同士のsynchronizes with
このstrongly happens beforeを用いて以下のような制約が与えられています。
First, if $A$ and $B$ are
memory_order::seq_cstoperations and $A$ strongly happens before $B$, then $A$ precedes $B$ in $S$.
さて、このstrong happens before関係はなぜ必要なのでしょうか。C++の仕様は現在GitHubで管理されている https://github.com/cplusplus/draft ので、blameで追跡ができました。以下がその理由のようです。
Existing implementation schemes on Power and ARM are not correct with respect to the current memory model definition. These implementation schemes can lead to results that are disallowed by the current memory model when the user combines acquire/release ordering with seq_cst ordering. On some architectures, especially Power and Nvidia GPUs, it is expensive to repair the implementations to satisfy the existing memory model. Details are discussed in (Lahav et al) http://plv.mpi-sws.org/scfix/paper.pdf (which this discussion relies on heavily). The same issues were briefly outlined at the Kona SG1 meeting. We summarize below.
-- http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0668r5.html
リンク先は[Lahav17]の公開版PDFです。
問題はSeqCst操作とRelease操作を混在させたときの実装にあるようです。Powerのメモリモデルに詳しくないこともあり筆者には一瞥して理解はできませんが、SeqCstのために挟まれるlwsync命令がRelease操作の先のhappens-before関係にある命令まで適切に値を伝搬するのが困難だというような話のようです。
これらの実装をパフォーマンスを維持しつつ元々の仕様に合わせるのは難しく、またそもそもSeqCstとAcquire/Releaseを混在させた時の保証はあまり重要ではないため、仕様側を緩めることにした、という経緯のように見えます。
modification order, reads from との関係
happens beforeと同様、 $S$ が効力を発揮するには、アトミック操作との関係を定める必要があります。そのためにまず以下の定義を導入します。
An atomic operation $A$ on some atomic object $M$ is coherence-ordered before another atomic operation $B$ on $M$ if
- $A$ is a modification, and $B$ reads the value stored by $A$, or
- $A$ precedes $B$ in the modification order of $M$, or
- $A$ and $B$ are not the same atomic read-modify-write operation, and there exists an atomic modification $X$ of $M$ such that $A$ reads the value stored by $X$ and $X$ precedes $B$ in the modification order of $M$, or
- there exists an atomic modification $X$ of $M$ such that $A$ is coherence-ordered before $X$ and $X$ is coherence-ordered before $B$.
modification order が書き込み操作の順序だったのに対し、この coherence-ordered before はRead/Write/RMWを全て含めた順序を定義しています。最後の1つはいつもどおり推移閉包を取る呪文ですが、残り3つは以下の条件に対応します。
- modification orderに従っていること。
- reads fromに従っていること。
- あるreadがあるwriteを**(writeのほうが遅かったために)読まなかった**という順番を反映していること。
これによって、coherence-ordered beforeは各メモリ領域にごとに、同一値のread同士を除いて全順序になります。
(happens before とアトミック操作の関係も、このcoherence-ordered beforeを使って記述したほうが綺麗だと思うのですが、今のところそうはなっていないようです。)
... Second, for every pair of atomic operations $A$ and $B$ on an object $M$, where $A$ is coherence-ordered before $B$, the following four conditions are required to be satisfied by $S$:
- if $A$ and $B$ are both
memory_order::seq_cstoperations, then $A$ precedes $B$ in $S$; and- ...
coherence-ordered beforeならば、 $S$ で前後関係が成立するとしています。シンプルですね。
フェンスとの関係
先ほどの続きでフェンス操作にも触れられています。
- ...
- if $A$ is a
memory_order::seq_cstoperation and $B$ happens before amemory_order::seq_cstfence $Y$, then $A$ precedes $Y$ in $S$; and- if a
memory_order::seq_cstfence $X$ happens before $A$ and $B$ is amemory_order::seq_cstoperation, then $X$ precedes $B$ in $S$; and- if a
memory_order::seq_cstfence $X$ happens before $A$ and $B$ happens before amemory_order::seq_cstfence $Y$, then $X$ precedes $Y$ in $S$.
これもacquire-releaseにおけるフェンスの役割と似ています。SeqCstなフェンスは前後のアトミック操作にSeqCstに準ずる能力を与える (ただし実際に順序関係が成立するのはフェンス命令) というものです。
ミューテックスとの関係
ミューテックスにSeqCstの概念はありませんが、以下の注釈があります。
... [ Note: It can be shown that programs that correctly use mutexes and
memory_order::seq_cstoperations to prevent all data races and use no other synchronization operations behave as if the operations executed by their constituent threads were simply interleaved, with each value computation of an object being taken from the last side effect on that object in that interleaving. This is normally referred to as “sequential consistency”. However, this applies only to data-race-free programs, and data-race-free programs cannot observe most program transformations that do not change single-threaded program semantics. In fact, most single-threaded program transformations continue to be allowed, since any program that behaves differently as a result must perform an undefined operation. — end note ]
他の操作を全てSeqCstにしておけば、ミューテックスも逐次一貫性保証の仲間入りをすることが他の性質からわかるということが示唆されています。
OOTA問題
もうひとつ、メモリ順序を考える上で欠かせない題材がOOTA (Out-of-thin-air) 問題です。たとえば以下のプログラムを考えます。(X, Y ともに0で初期化されているとします)
// thread 1
let x = X.load(Relaxed);
Y.store(x, Relaxed);
eprintln!("x = {}", x);
// thread 2
let y = Y.load(Relaxed);
X.store(y, Relaxed);
eprintln!("y = {}", y);
このプログラムが x = 42, y = 42 を出力する可能性はあるでしょうか。42が出てくる理由がどこにもないので、ありえないと考えるのが普通です。ところが、ここまでで説明した規則だけでは、このような結果を禁止することができないのです。どこからともなく値が湧き出てくるこの現象のことをOOTA (Out-of-thin-air) 問題と呼んでいます。
このような問題が起きる原因のひとつが、メモリモデルが値の依存関係を正確に追跡していないことにあります。先ほどと微妙に異なる次のようなプログラムを考えてみます。
// thread 1
let x = X.load(Relaxed);
Y.store(42, Relaxed); // ←ここが変わっている
eprintln!("x = {}", x);
// thread 2
let y = Y.load(Relaxed);
X.store(y, Relaxed);
eprintln!("y = {}", y);
これが42を出す可能性はあるでしょうか(あります)。スレッド1のメモリ操作が入れ替わるので多少非直感的ですが、これなら42の出所もわかるし納得できると思います。
問題は、このプログラムが42を出すときのグラフと、最初のプログラムが42を出すときのグラフは区別できないということにあります。どちらもログの上では以下のようになってしまうからです。
- スレッド1
-
Xからrelaxed loadを行い、42を読み取った。 -
Yに42を入れるrelaxed storeを行った。
-
- スレッド2
-
Yからrelaxed loadを行い、42を読み取った。 -
Xに42を入れるrelaxed storeを行った。
-
さらにきわどい例として以下のようなものもあります。
// thread 1
let x = X.load(Relaxed);
if x == 42 {
Y.store(42, Relaxed);
}
eprintln!("x = {}", x);
// thread 2
let y = Y.load(Relaxed);
X.store(y, Relaxed);
eprintln!("y = {}", y);
これ(が42を出力する可能性)も、ここまで述べてきた仕組みで禁止するのは困難です。
C++20の現行ドラフトでは、これについて以下のようにお茶を濁しています。
Implementations should ensure that no “out-of-thin-air” values are computed that circularly depend on their own computation.
[ Note: For example, with x and y initially zero,
// Thread 1: r1 = y.load(memory_order::relaxed); x.store(r1, memory_order::relaxed); // Thread 2: r2 = x.load(memory_order::relaxed); y.store(r2, memory_order::relaxed);should not produce
r1 == r2 == 42, since the store of 42 toyis only possible if the store toxstores 42, which circularly depends on the store toystoring 42. Note that without this restriction, such an execution is possible. — end note ]
おそらくですが、こういった現象を許容するような最適化があるとはあまり考えにくく、またシミュレーターを実装するさいも厄介な問題であるため、OOTAを禁止したいというのが全体の流れだと思われます。とはいえ、これを禁止する適切なルールはまだ作れていないようです。[Kang17] が関連する問題に挑戦しているようなので見てみると面白いかもしれません。
まとめ
- 一般論としてマルチスレッドプログラミングでは競合状態が問題になるため、ミューテックスなどの並行性プリミティブを用いて競合を防ぐ必要がある。
- C++やRustなどより低レイヤを扱うプログラミング言語では、ミューテックスより原始的な仕組みであるアトミック変数もよく用いられる。
- C++やRustなど最適化を重要視するプログラミング言語では、非アトミック変数の競合はデータ競合というより重大な問題につながる。
- C++やRustなど最適化を重要視するプログラミング言語では、アトミック操作にも保証のレベルが段階的に設定されており、メモリ順序と呼ばれている。最も強いメモリ順序では逐次一貫性とよばれる直感的な性質が成立するが、弱いメモリ順序では驚くような方法で操作が入れ替えられることがある。
- Rustのメモリ順序の仕様はC++20のドラフトを参照する形で定義されている。C++20のメモリ順序の仕様はC++17から一部改訂されている。
- release-acquireの一般論は、スレッド内順序であるsequenced beforeとrelease-acquireの結果生じるsynchronizes withによってhappens beforeが定義される、という形で進行する。
- release-acquireの個別論では、個別のメモリ領域が観測するメモリ順序がmodification order, reads fromという関係によって定義され、happens beforeとの関係が規定される、という形で進行する。
- 逐次一貫性はrelease-acquireの規格に被せる形で定義されている。release-acquireと併用した場合に難しい問題が発生する。
- メモリモデルは逐次実行のモデルと分離して定義されているが、そのせいでOOTAという厄介な規格上の問題が発生している。
次回最終回はとうとう Arc の実装を読んでいきます。今回アトミックの難しいところは全部やりきったはずなので、第5回はそんなに長くならないはず……?
参考文献
- [n4842]: ISO/IEC. Working Draft, Standard for Programming Language C++. Accessed at 2019-12-29. Acquired from http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/n4842.pdf
- [Batty11]: Mark Batty, Scott Owens, Susmit Sarkar, Peter Sewell, and Tjark Weber. 2011.
Mathematizing C++ concurrency. In Proceedings of the 38th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages (POPL '11). ACM Press, New York, NY, 55-66. DOI: https://doi.org/10.1145/1926385.1926394 - [Blanchette11]: Jasmin Christian Blanchette, Tjark Weber, Mark Batty, Scott Owens, and Susmit Sarkar. 2011. Nitpicking C++ concurrency. In Proceedings of the 13th international ACM SIGPLAN symposium on Principles and practices of declarative programming (PPDP '11). ACM Press, New York, NY, 113-124. DOI: https://doi.org/10.1145/2003476.2003493
- [Batty16]: Mark Batty, Alastair F. Donaldson, and John Wickerson. 2016. Overhauling SC atomics in C11 and OpenCL. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL '16). ACM Press, New York, NY, 634-648. DOI: https://doi.org/10.1145/2837614.2837637
- [Kang17]: Jeehoon Kang, Chung-Kil Hur, Ori Lahav, Viktor Vafeiadis, and Derek Dreyer. 2017. A promising semantics for relaxed-memory concurrency. In Proceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL '17). ACM Press, New York, NY, 175-189. DOI: https://doi.org/10.1145/3009837.3009850
- [Lahav17]: Ori Lahav, Viktor Vafeiadis, Jeehoon Kang, Chung-Kil Hur, and Derek Dreyer. 2017. Repairing sequential consistency in C/C++11. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation PLDI '17). ACM Press, New York, NY, 618-632. DOI: https://doi.org/10.1145/3062341.3062352