Pandas処理時間をもっと縮める方法?
解決したいこと
Pandasで複数行のデータから判断して特定カラムにデータをセットしています。
処理時間をもっと縮める方法はないでしょうか?
発生している問題・エラー
C:\anaconda3\lib\site-packages\pandas\core\indexing.py:1765: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
isetter(loc, value)
該当するソースコード
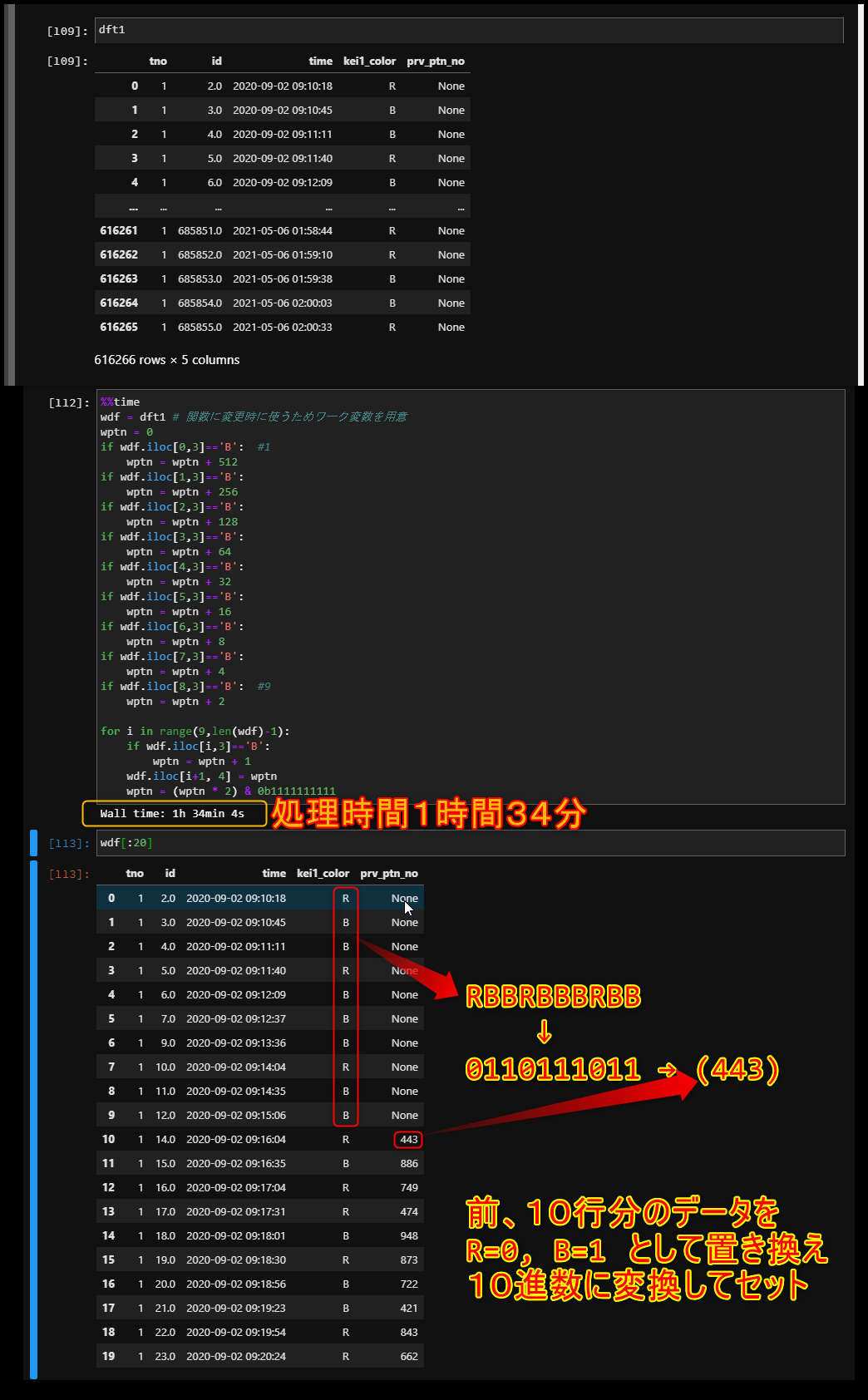
%%time
wdf = dft1 # 関数に変更時に使うためワーク変数を用意
wptn = 0
if wdf.iloc[0,3]=='B': #1
wptn = wptn + 512
if wdf.iloc[1,3]=='B':
wptn = wptn + 256
if wdf.iloc[2,3]=='B':
wptn = wptn + 128
if wdf.iloc[3,3]=='B':
wptn = wptn + 64
if wdf.iloc[4,3]=='B':
wptn = wptn + 32
if wdf.iloc[5,3]=='B':
wptn = wptn + 16
if wdf.iloc[6,3]=='B':
wptn = wptn + 8
if wdf.iloc[7,3]=='B':
wptn = wptn + 4
if wdf.iloc[8,3]=='B': #9
wptn = wptn + 2
for i in range(9,len(wdf)-1):
if wdf.iloc[i,3]=='B':
wptn = wptn + 1
wdf.iloc[i+1, 4] = wptn
wptn = (wptn * 2) & 0b1111111111
自分で試したこと
下図のようにFor分を使い カラム(kei1_color)の直前10行分データを、R=1,B=0と置き換えて 10進数に変換したものを カラム(prv_ptn_no)に順次セットしていく。
0 likes