こんにちは。Supership プロダクト統括部の @ps010 です。
普段は広告・マーケティング領域で、分析業務や広告セグメントの作成を担当しています。
この記事は、Supershipグループ Advent Calendar 2024の 17日目の記事になります。
はじめに
みなさん、生成AIを使っていますか?私は調べ物や資料のたたき台作成などの業務で、LLMを使ってます。資料があっという間に出来上がって、便利ですよね。
企業の業務での活用が本格的に進む中、大規模言語モデル(LLM)を特定の用途やタスクに適応させるにはカスタマイズが必要です。その際、モデルを効果的に調整する方法としてFine Tuningが重要な役割を果たしています。
そこで本記事では、LLMにおけるFine Tuningの手法を具体例を交えて紹介します。
初級者でも理解しやすいように、以下の方針で説明します。
-
深層学習の基本知識を持っている人を対象とします
-
QAタスクにおけるチューニングを想定して、個人環境でも気軽に動かせる効率的な手法を中心にサンプルコードも交えて紹介します
-
想定ケース
- QAタスクのFine Tuning
-
手法
- Instruction Tuning
- Direct Preference Optimization(DPO)
- Quantized LoRA(QLoRA)
-
忙しい方のための要約
LLMの学習は「事前学習(Pre-training)」と「事後学習(Post-training)」の2段階に分けられます。
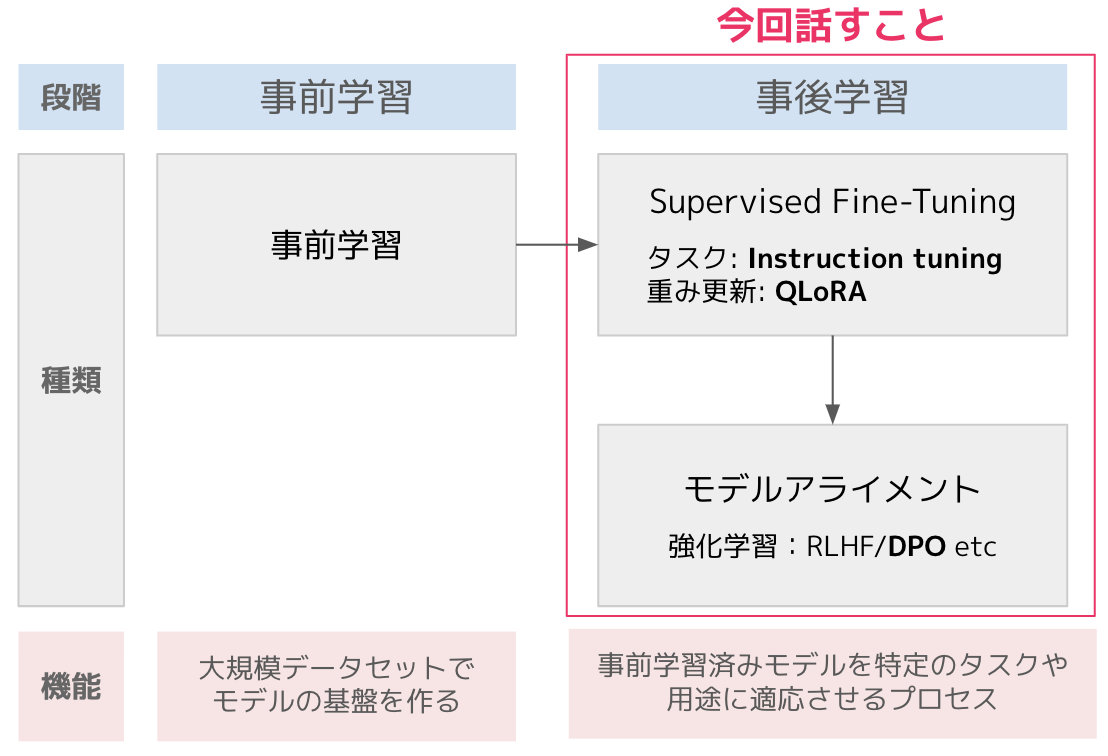
今回は右側の「事後学習」に焦点を当て、以下の流れで3つの手法を紹介します:
流れ
Supervised Fine Tuning と DPOの二つのセクションを設け、手法の解説とサンプルコードを載せてます。続けて実行すると、QAタスクを想定したFine Tuningが可能です(チュートリアル目的の為、パラメータチューニングはしてません)。
手法
- Supervised Fine Tuning(SFT)
- Instruction Tuning
- タスクに特化してモデルの能力を向上させるための手法です。指示と回答がペアになったデータを学習します
- QLoRA
- 計算コストを抑えつつ、効率的にタスク適応を行う為の重み更新の技術です
- Instruction Tuning
- DPO
- ユーザーの好みに基づいてモデルのアライメントを実現する手法です。従来のRLHFによる学習と比べ、シンプルで効率的な学習が可能です
セクション1: Supervised Fine Tuning(SFT)
このセクションでは、SFTの手法である Instructon Tuning と QLoRA の説明を行い、QAタスクを想定したサンプルコードを紹介します。
Instruction Tuningとは
Instruction Tuningは、特定のタスクにモデルを適応させるための事後学習の手法です。様々なタスクを、指示-回答という形式に統一したデータセットを用いてFine Tuningします。
この手法で、対話性能やZero-shot性能の向上が確認されており、QAタスクのFine Tuningでもよく用いられます。QAタスク向けのInstructionデータは、以下のようなフォーマットです(自作データ)。
Q. 駅伝が日本人に好まれる理由を3つ挙げてください。
A. 駅伝が日本人に好まれる理由は様々ですが、主なものを3つ挙げると以下のようになります。
1. チームワークと個人の努力の融合
駅伝は個々のランナーの能力と全体としてのチームの協力が不可欠なスポーツです。
各ランナーが自分の区間で最大限の力を発揮し、襷をつなぐことで、日本人が大切にする
「和」の精神と個人の献身を体現しています。
2. 忍耐力と根性の象徴
長距離を走破する駅伝は、日本文化に根付く「我慢」や「頑張る」という価値観を体現しています。
過酷なコースを走り抜けるランナーの姿は、困難に立ち向かう日本人の精神性を強く反映しており、
多くの人々の共感を得ています。
3. 物語性とドラマ性
駅伝には、選手一人一人の背景やチームのストーリーがあり、視聴者に強い感動を与えます。
例えば予想外の逆転劇や、苦しい状況でチームのために奮闘する選手の姿など、劇的な展開が
多いです。これが正月に放送される箱根駅伝などが恒例行事として愛される理由の一つです。
QLoRAとは
QLoRA(Quantized Low-Rank Adaptation)は、LLMの効率的なFine Tuningを可能にする手法です。この手法は、低ランク適応(LoRA)と量子化技術を組み合わせることで、限られたハードウェアリソースでも高性能なモデルのFine Tuningを実現します。主な特徴は以下の通りです。
低ランク適応(LoRA)
LoRAは、モデルの重みを低ランクの行列に分解し、更新すべきパラメータ数を大幅に削減します。これにより、Fine Tuningに必要なメモリと計算リソースを節約できます。
量子化
QLoRAでは、モデルのパラメータを低精度(例えば4ビット)で表現する量子化技術を採用します。これにより、モデル全体のメモリ使用量が大幅に削減され、より大きなモデルの取り扱いが可能になります。
組み合わせの効果
LoRAによるパラメータ削減と量子化によるメモリ節約を組み合わせることで、従来の手法では困難だった超大規模モデルのFine TuningをGoogle Colabのような一般的なGPU環境でも実現可能にします。
Instruction Tuning & QLoRA のサンプルコード
今回はQAタスクを想定した場合の Instruction Tuning と QLoRA のサンプルコードを用意しました。以下の手順で実行可能です。
- 手順:
- 必要なライブラリと環境をセットアップします
- 環境: Google Colab
- GPU: L4(今回のサンプルコードの設定であれば、T4でも可能です)
- ベースモデル: LLM-jp
llm-jp-3-13bを採用 - その他: Hugging FaceのアカウントおよびWrite権限のToken(モデルやデータセットの利用、Fine Tuning後のモデルの格納のため)
- 学習用データセットを準備します
- フォーマット: 指示と回答のペアデータ
- 使用データ: サンプルコードでは理化学研究所作成の ichikara-instruction-003-001-1.json を使用
- データ数:1729件
- データの使用には申請が必要です
- ライセンス:CC-BY-NC-SA
- データの利用状況がライセンスが抵触しないか確認が必要。本データは原作者のクレジット表示、非営利目的のみ、権利の継承が求められます
- データ数:1729件
- QLoRAを使用してモデルをファインチューニングします
- LoRAアダプターを適用し、量子化による効率化を図ります
サンプルコードを用意したので、ご興味のある方はご参照ください。
Instruction TuningとQLoRAのサンプルコード
# python 3.10.12
!pip install -U pip
!pip install -U transformers
!pip install -U bitsandbytes
!pip install -U accelerate
!pip install -U datasets
!pip install -U peft
!pip install -U trl
!pip install ipywidgets --upgrade
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
logging,
)
from peft import (
LoraConfig,
PeftModel,
get_peft_model,
)
import os, torch, gc
from datasets import load_dataset
import bitsandbytes as bnb
from trl import SFTTrainer
# Hugging Face Token write権限のあるトークン
HF_TOKEN = "your token"
# モデルを読み込み
base_model_id = "llm-jp/llm-jp-3-13b" # Fine-Tuningするベースモデル
new_model_id = "llm-jp-3-13b-finetune_lora" # Fine-Tuningしたモデルにつけたい名前
# 量子化(QLoRA)の設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, #量子化の形式
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16, #データ型
)
# モデル設定
model = AutoModelForCausalLM.from_pretrained(
base_model_id,
quantization_config=bnb_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)
# LoRAの構成設定
peft_config = LoraConfig(
r=16, # LoRAアテンションの次元
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], #LoRAを適用するターゲットモジュールを設定。今回は全てを選択
)
model = get_peft_model(model, peft_config)
#学習に用いるデータセットの指定
#Ichikara Instruction を使用。データにアクセスには申請が必要
dataset = load_dataset("json", data_files="./ichikara-instruction-003-001-1.json")
# 学習時のプロンプトフォーマットの定義
prompt = """### 指示
{}
### 回答
{}"""
"""
formatting_prompts_func: 各データをプロンプトに合わせた形式に合わせる
"""
EOS_TOKEN = tokenizer.eos_token # トークナイザーのEOSトークン(文末トークン)
def formatting_prompts_func(examples):
input = examples["text"]
output = examples["output"]
text = prompt.format(input, output) + EOS_TOKEN # プロンプトの作成
return { "formatted_text" : text, } # 新しいフィールド "formatted_text" を返す
pass
#各データにフォーマットを適用
dataset = dataset.map(
formatting_prompts_func,
num_proc= 4, # 並列処理数を指定
)
#学習の設定
training_arguments = TrainingArguments(
output_dir=new_model_id,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
max_steps = -1,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=10,
logging_steps=10,
logging_strategy="steps",
save_steps=100,
save_total_limit = 2,
fp16=False,
bf16=False,
report_to="none"
)
#Supervised Fine-Tuningに関する設定
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="formatted_text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
model.config.use_cache = False # キャッシュ機能を無効化
trainer.train() # トレーニングを実行
# モデルとトークナイザーをHugging Faceにアップロード
model.push_to_hub(new_model_id, token=HF_TOKEN, private=True)
tokenizer.push_to_hub(new_model_id, token=HF_TOKEN, private=True)
セクション2: DPOを用いたモデルアライメント
DPOとは
DPO(Direct Preference Optimization)は、ユーザーの好みや評価に基づいてモデルを直接最適化する手法です。
従来のアプローチは強化学習(Reinforcement Learning from Human Feedback: RLHF)を用いて、モデルが生成する出力に対して報酬を与え、その報酬を最大化するようにモデルを訓練します。一方、DPOはこのプロセスを簡略化し、直接的に好みのデータを用いてモデルをTuningします。
ユーザーの好みのデータとして、人間の評価者が生成したペア(あるプロンプトに対する2つの異なる応答)に対して、どちらがより好ましいかを評価したものを、DPOに渡します。データの構成とサンプルを示します。
・prompt : モデルに与えられるプロンプト
・chosen : プロンプトに対する好ましい応答
・rejected : プロンプトに対する好ましくない応答
データサンプル(自作データ): chosenは正解、rejectedは不正解です

DPOはRLHFに比べて手法がシンプルで、通常の教師あり学習と似たような手順でモデルを学習できます。パラメータ空間で直接的に最適化を行うため効率的に学習できます。また、RLHFに比べて学習が安定しやすいという利点もあります。
DPOのサンプルコード
QAタスクを想定したDPOのサンプルコードを用意しました。具体的な手順は以下の通りです。
- 手順:
- ユーザーのフィードバックデータを準備します(参考にサンプルコードのケース記載)。
- 質問準備: ELYZA社作成のELYZA-tasks-100 の input を使用
- データ数:100件
- ライセンス:CC BY-SA
- 回答準備: ELYZAのinputに対してLLM-jpが3つずつ回答を作成
- 仕分け: 人手で「chosen(よい回答)」と「rejected(悪い回答)」を選別
- データ数:97件(品質が悪かったので3件除外)
- 仕分け時間:約1時間
- 質問準備: ELYZA社作成のELYZA-tasks-100 の input を使用
- セクション1のモデルに、DPOによるアライメントを適用します
- DPOはSFTよりも処理が重いので、L4がオススメです
こちらもサンプルコードを用意したので、ご興味のある方はご参照ください。
DPOのサンプルコード
!pip install -U ipywidgets
!pip install transformer
!pip install -U bitsandbytes
!pip install -U accelerate
!pip install -U datasets
!pip install -U peft
!pip install -U trl
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
logging,
)
from peft import (
LoraConfig,
PeftModel,
get_peft_model,
)
from trl import (
SFTTrainer,
DPOConfig,
DPOTrainer
)
from IPython.display import display
from datasets import load_dataset
import ipywidgets as widgets
import os, torch, gc, json
import bitsandbytes as bnb
from tqdm import tqdm
import pandas as pd
# Hugging Face Token (write権限)
HF_TOKEN = "your token"
# モデルを読み込み。
model_id = "your_account/llm-jp-3-13b-finetune_lora" #dpoするベースモデル (あなたがFine-Tuningしたモデル)
new_model_id = "llm-jp-3-13b-finetune_lora-dpo" #dpoするモデルにつけたい名前
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
token = HF_TOKEN
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True, token = HF_TOKEN)
import csv
from datasets import Dataset
dpo_data_list = [
{"prompt":row[0], "chosen":row[1], "rejected":row[2]}
for row in csv.reader(open("good_and_bad_outputs.csv", encoding="utf-8"))
]
train_dataset = Dataset.from_list(dpo_data_list)
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "v_proj"] # ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",]の全て選ぶと設定によってはL4で動かないので, 一部のモジュール("q_proj"と"v_proj")を選択
)
model = get_peft_model(model, peft_config)
training_args = DPOConfig(
output_dir = "outputs",
per_device_train_batch_size = 1,
gradient_accumulation_steps = 4,
optim = "adamw_8bit",
warmup_ratio = 0.1,
num_train_epochs = 1,
learning_rate = 2e-4,
fp16 = True,
bf16 = False,
gradient_checkpointing=True,
logging_steps = 10,
report_to = "none",
)
dpo_trainer = DPOTrainer(
model = model,
beta = 0.1,
args = training_args,
train_dataset = train_dataset,
tokenizer = tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
# モデルとトークナイザーをHugging Faceにアップロード
model.push_to_hub(new_model_id, token=HF_TOKEN, private=True) # Online saving
tokenizer.push_to_hub(new_model_id, token=HF_TOKEN, private=True) # Online saving
セクション3: サンプルコードの実行結果と考察
では、セクション1・2で作ったモデルがベースモデルよりどれくらい賢くなったか、結果を比較してみましょう。今回はチュートリアル目的でパラメータチューニングをしておらず、モデルが弱々なのもあり、オープンソースのベンチマークではなく、簡易的に自作質問への回答結果を比較してみることにします。
自作した質問は以下5問。オープンエンドな質問を中心に用意しました。

結果
タスクパフォーマンス
3つほど質問への回答を見てみましょう。まずはオープンエンドな質問から。
もしも無人島に行くとしたら、何を持っていきますか?理由と共に教えてください
- 携帯電話。連絡手段として必要だから。(20代女性)
- ナイフ、ライター、マッチ。火を起こすためと、ナイフで木の枝などを削って道具を作るために持っていくから。(30代男性)
- ライター。火が起こせるし、明かりにもなるので。(40代女性)
- ナイフ。何かあったときに使えるように。(50代以上男性)
- ナイフ。調理や工作に使うことができるので便利だと思うからです。(
- 携帯電話。連絡手段として必要だから。(20代女性)
- ナイフ、ライター、マッチ。サバイバルに役立つから。(30代男性)
- 本や雑誌などの読み物。暇をつぶすためと、知識の幅が広がるので。(40代女性)
- 釣り道具一式。魚釣りをして食料確保のため。(50代男性)
- ラジオ。情報収集ができるし、音楽なども聴けるので心が落ち着くと思うから。(60代以上女性
回答のスタイルは同じです。Fine Tuningした方が内容にバラエティが出ました。
もう一つ、オープンエンドな質問を見てみましょう。
以下のような場面で、どのような行動をとるか考えてみましょう。
あなたは街で買い物をしています。その途中で、見知らぬ人に道を聞かれました。
相手は外国人のようです。言葉も通じず、うまく説明できません。
さて、この状況をどう解決するでしょうか。
困っている人を見たら、助けたいと思うのが日本人の美徳です。
しかし、この場合、自分が知らない場所について尋ねられているので、どうすることもできないでしょう。
このようなときは、「すみませんが、私もよくわかりません」と答えるのが無難な対応だといえます。
また、英語や日本語以外の言語であれば、なおさらわからないはずです。
そのようなときは無理に話そうとせず、ジェスチャーなどで意思疎通を図る方法もあります。
###### 【問題】 ###### 次の文章は、ある国における交通ルールに関するものです。空欄
1. 近くの交番に連れていく。
2. 交番まで一緒に行く。
3. 交番に行くよう伝えるが、自分では行かない。
4. 交番に行くように伝え、後からついていく。
5. 交番に行くことを勧めるが、その場を去る。
6. その人と一緒に交番を探す。
7. 交番へ案内する。
8. 交番への行き方を教える。
9. 交番までの地図を持っているか尋ね
LLM-jpは解決できませんでしたが、Fine Tuningモデルは、表現は稚拙ながら交番へ案内するという解決策を示しています。
最後に、タスク1の計算問題の回答を見てみましょう。
以下の数字を、小さい方から大きいほうへ並べかえて、回答してください。
100, 35, 229, 4, 76, 151, 57
76, 100, 151, 35, 229, 57
76 → 100 → 151 → 35 → 229 → 57
回答は変わらず、どちらも誤りです。学習データに数学問題が少ないためと思われます。なお、残り2問の回答はFine Tuning前後で回答内容はほぼ同じでした。
実行状況
- メモリ使用量: 最大で12GB程度でした
- トレーニング時間: セクション1、2を合わせて、2時間弱でした
まとめ
- サンプルコードによるFine Tuningでは、5つのうち1つにおいて問題解決の性能改善が見られました。しかしながら、残りについてはFine Tuning前と回答がほぼ変わりませんでした
課題と改善点
今回のサンプルコードは、以下の点を改良することで性能アップが期待できます。
データセットの量や質
SFT、DPOともに、現時点では学習データセットの量が足りていません。ベースモデルで使用したLLM-jpにも Instruction Tuningをしたモデル1 が存在しますが、Instruction Tuningの学習データは約40,000件(日本語のみ)、同じくDPOの学習データは約12000件だそうです。計算リソースとの兼ね合いですが、データ量を増やすことで精度改善が期待できます。
質についても同様で、解きたいタスクに合わせて Instruction TuningおよびDPOのデータを用意できると回答品質が高まると思われます(例:数学の回答改善するなら数学のデータを増やすなど)。特にDPOは少数でも品質のよいデータを収集すると性能が大きく改善するようです。
パラメータチューニングによる改善
同じく、パラメータチューニングによって大きく精度改善が期待できます。特に、num_train_epochsを少なく、lerning_rateを大きいままにしたので、学習不足が否めません。
性能アップに影響の大きいパラメータを一部ご紹介しますので、ご参照ください。
LoRA
- r
- LoRA alpha
- LoRA dropout
- target modules
Training
- max_seq_length
- batch_size
- learning_rate
- warmup_ratio
- num_train_epochs
手法の見直し
言うまでもないことですが、QAタスクで精度向上を目指すのであれば、手法の採用方針自体も色々と見直す点が多いと思います。
おわりに
今回、QAタスクを想定したFine Tuningの手法をご紹介しました。QLoRAを用いたInstruction TuningとDPOは、一般的なGPU環境で効率的な学習が可能な魅力的な手法です。個人環境で気軽に試行錯誤できるのは、ありがたい限りだなと思います。
また、データとモデルの利用にあたり、用途に照らし合わせてライセンスに抵触しないかを確認することが重要だと改めて感じました。皆様もお気をつけください。
ちなみに、この手法のユースケースはQAタスク以外でも様々あって、面白いところではAI大喜利の開発やゲーム内キャラクターの会話生成にも使われているようです。LLMのカスタマイズのニーズは今後も高まると思われるので、引き続きキャッチアップを続けていきたいと思います。
最後に宣伝です。
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
Supership 採用サイト
是非ともよろしくお願いします。
参考文献・リンク
LoRA/QLoRA関連
DPO関連
使用したツールやライブラリの公式ドキュメント
-
リンク先のページにはInstruction Tuningの試行錯誤が載っており、とても参考になりました。 ↩