はじめに
LoRAは、2022年に論文で紹介されている大規模言語モデルの効率的なファインチューニングを実現するための手法です。大規模言語モデル入門にも紹介されているのでLLMの基礎から学習するのであればこちらの本がお勧めです。
LoRAとそれ以外の代表的なチューニング手法との違いは以下のようになります。
-
LoRA(LOW-RANK ADAPTATION):
少数の学習パラメータでタスクに対して調整するという考え方。 -
RAG(Retrieval-Augmented Generation):
辞書的に外部の知識を与えてモデルに回答してもらうという考え方。 -
In-Context learning/Few-Shot Learningや、Promptエンジニアリング:
モデルは十分な能力を備えているのでモデルからうまく回答を生成するという考え方。
LoRAの仕組み
アプローチとしては、非常にシンプルでモデルの重み $W$ (上の図の青色部分)に対して並列に $\varDelta W = BA$ (上の図のオレンジ色部分)を追加し、モデルの重み $W$ は固定して$\varDelta W $ だけを学習するという手法です。
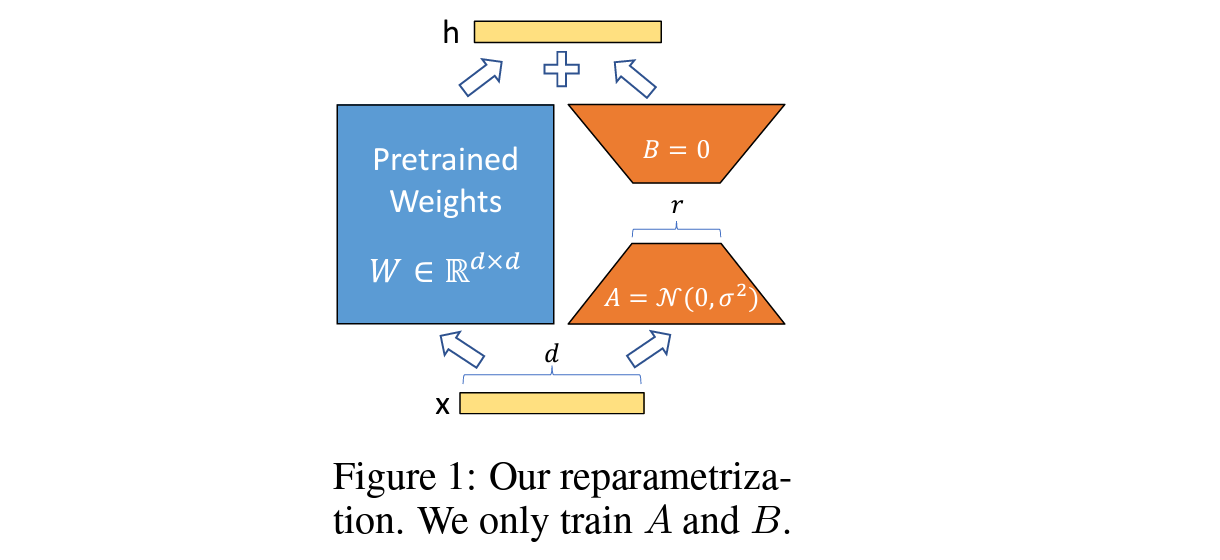
(引用元:論文)
そのため、以下のような特徴があります
- タスクの切り替えが簡単(ベースモデルはそのままにLoRA層を差し替えるだけ)
- 保存容量が小さい(ベースモデルは変更不要。LoRA層だけ保存すれば良い)
- $\varDelta W $の少ないパラメータだけを学習すれば良いため、学習コストを下げられる
- 推論コストが増加しない(推論時、$W + \varDelta W $ のように1つのパラメータとして扱える)
論文で行われている実験とその結果
論文では単純化のために$W_q$ と $W_v$ のみにLoRAを適用しています(仕組みのうえでは、全ての重みに対してLoRAを適用可能。性能面では2つで十分?)。
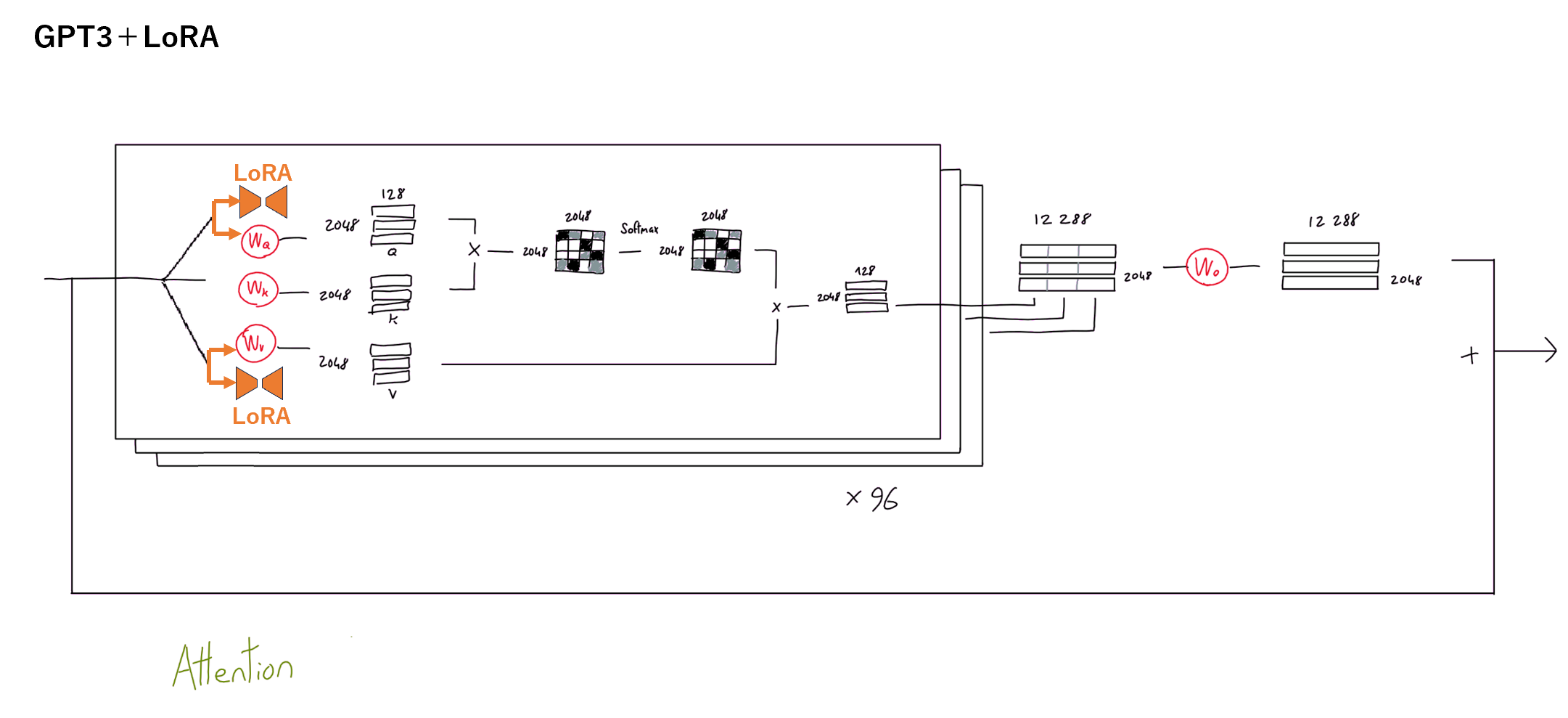
(https://dugas.ch/artificial_curiosity/GPT_architecture.html を元に加筆)
ポイント1:性能がすごい
LoRAはモデルパラメータ全体を更新するファインチューニングや Adapter や Prefix Tuning などと比較しても、同等の性能を達成。Fine-Tuningよりも上回る性能もでているようです。
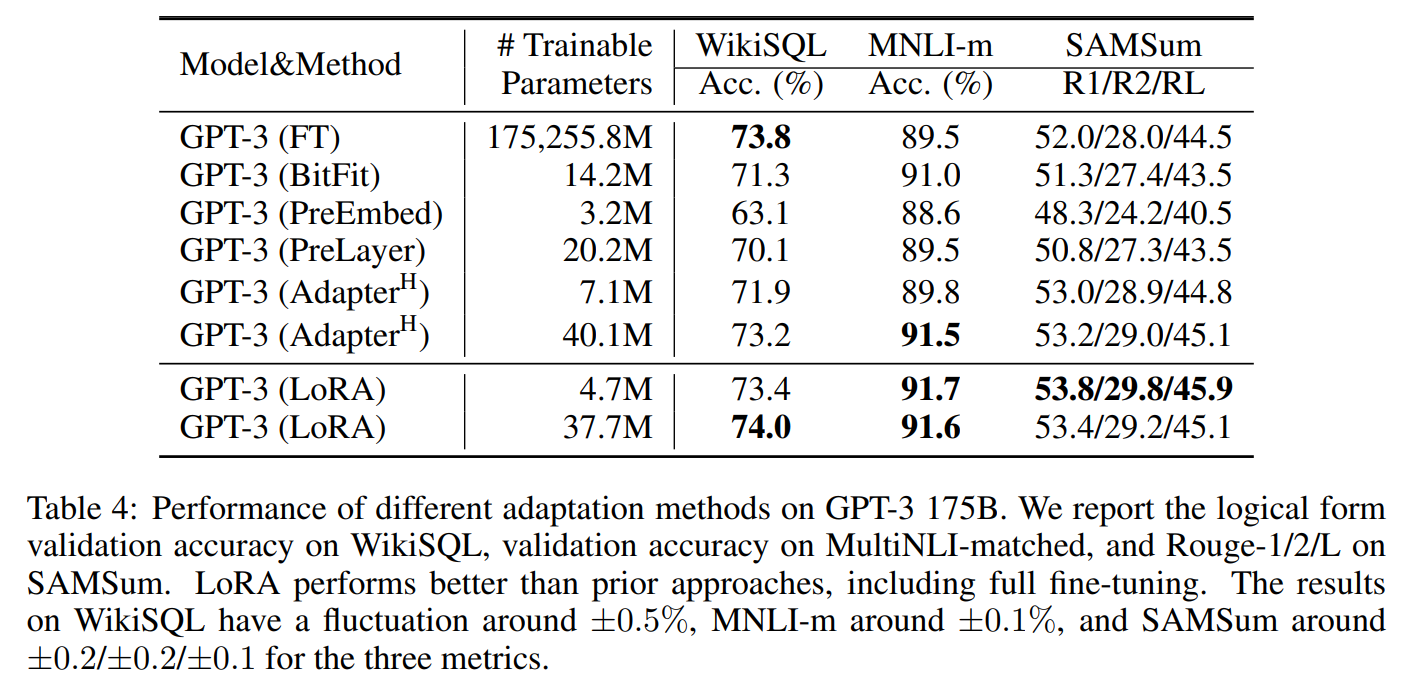
(部分的な微調整方法の中での違い)
-
BitFit:
モデルのバイアス項のみ更新する。 -
Adapter:
モデルにタスク専用の層を追加する。※ LoRAは、Adapterの一種。 -
Prefix-Tuning:
タスク専用の入力ベクトル+モデルの一部のみ更新する。 -
Promt Tuning:
タスク専用の入力ベクトルのみ更新する。
ポイント2:学習パラメータ数に対して頑健(安定している)
Prefix Tuningに比べてLoRAは安定しているようです。
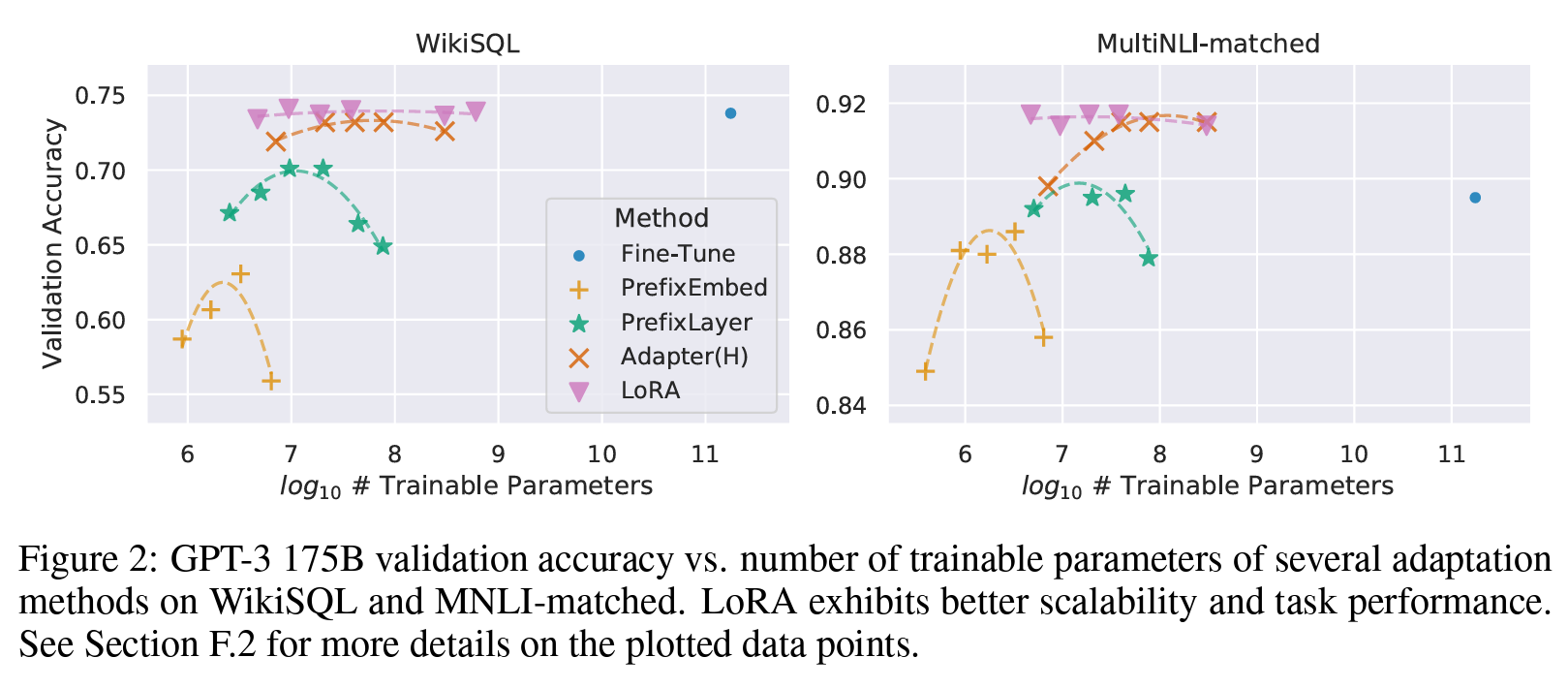
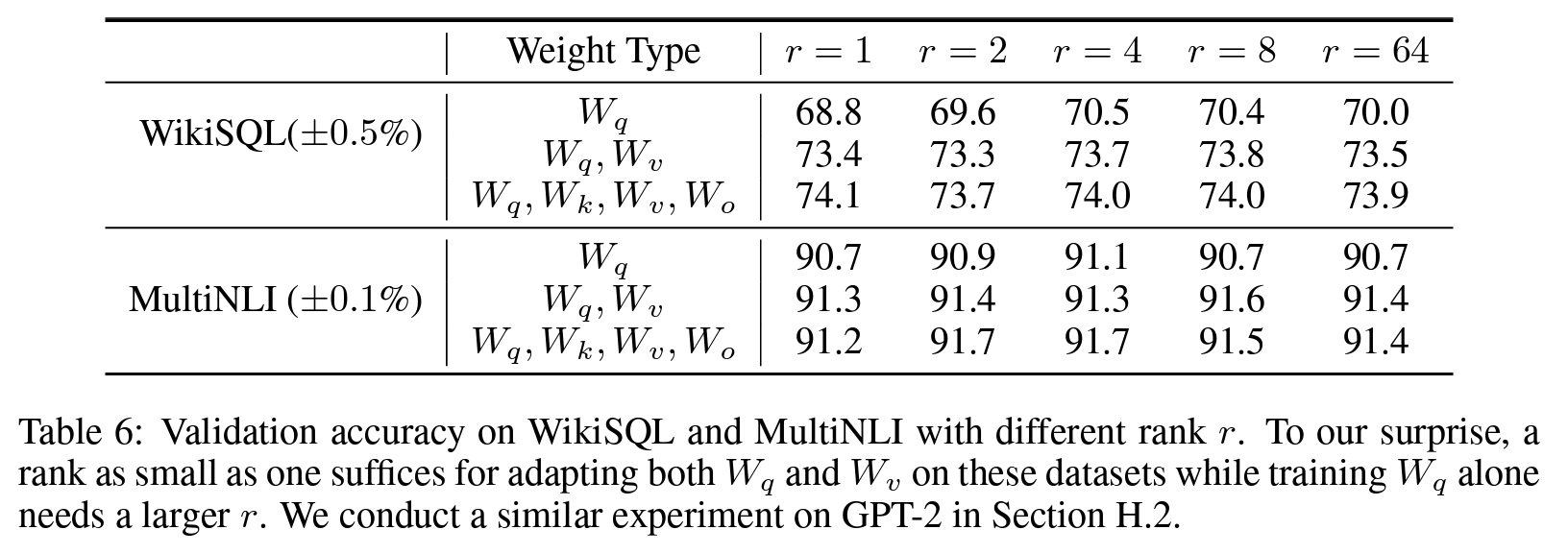
ポイント3:LoRAは低ランクでも機能する
LoRAのハイパーパラメータであるランク$r$は、論文中では2~64程度の小さい値が用いられおり、小さい次元数でも高い性能が出せることがわかります。
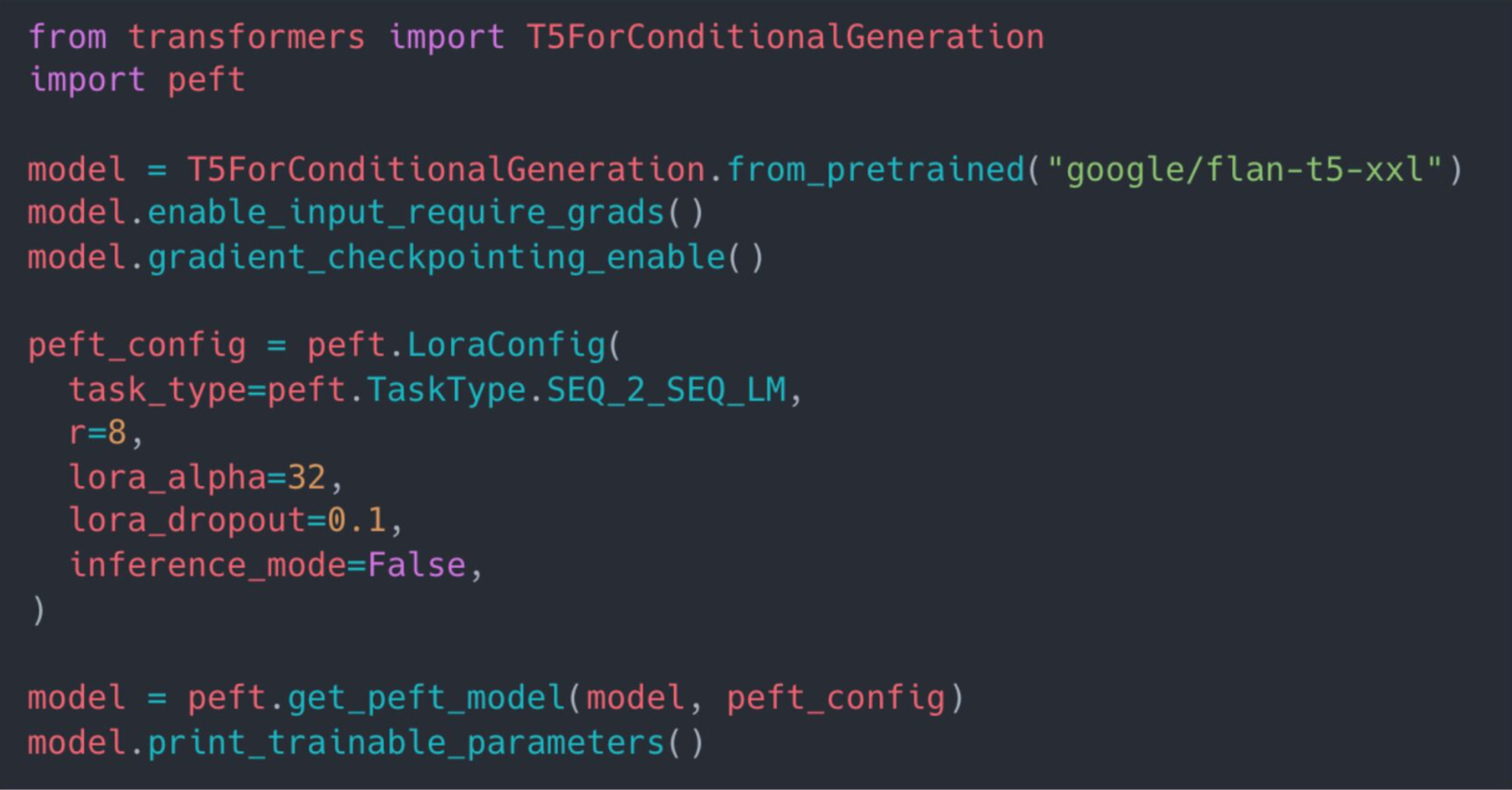
LoRAを使ってみるには
HuggingFaceでは、LoRAやPromptTuning、AdaLoRAなどが実装されているライブラリ:PEFT(Parameter-Efficient Fine-Tuning)が提供されています。
[PETFを用いたLoRAによる微調整の流れ]
- ベースモデルとなるモデルを用意
- ベースモデルの層の一部をLoRAの層に置換
- LoRAの層以外の層を固定
- LoRA部分のみを学習
(参考)
(引用元:[輪講資料] LoRA: Low-Rank Adaptation of
Large Language Models)
画像タスクでの活用
StableDiffusion
論文では言語モデルとなっていますが、画像タスクへの適用ニーズも高いです。
StableDiffusionの学習環境
その他参考
いくつかのLoRAの実装などを紹介します。
LoRAの実装(Microsoft)
LoRAの実装(HuggingFace)
LangChain(blog)
HuggingFace(チュートリアル)
おわりに
元のモデルの性能を活かしてベースモデルに既にある意識をタスクに応じて強調すると言われているLoRA。論文ではさらに多くの実験が行われていますのでぜひ興味がある方はぜひ論文も見てみていただければと思います。個人的な印象では、基盤モデルの影響を多分にうけて期待する性能は得られない?ようにも感じましたが、いろいろなモデルで実験しながら使いこなしていきたいですね。
参考