はじめに
初投稿です。
社内向けにTwitter APIからツイートをBigQueryに取得、公開するデータ基盤をGCP上に構築したので、備忘録と今後のtodoリストも兼ねて投稿します。
データ基盤構築とGCPを利用するのは初めてなので、何か気が付いた方はコメント頂ければ嬉しいです。
開発環境
Google Cloud Platform
python3系
概要
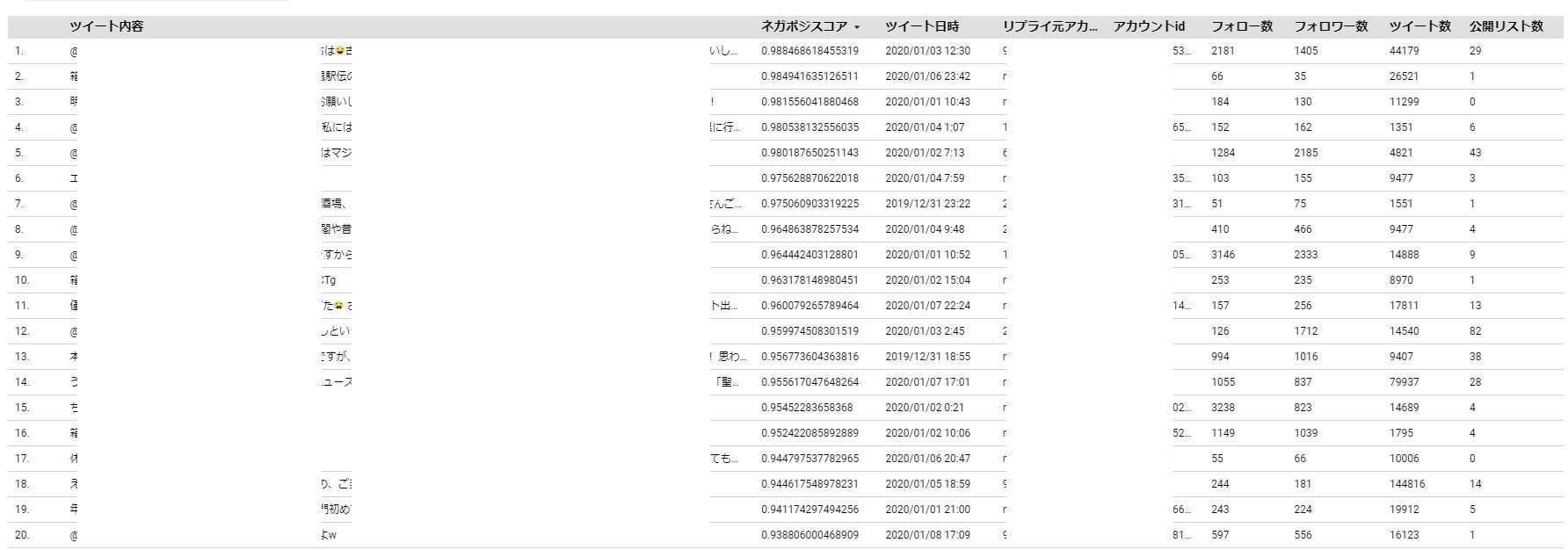
スプレッドシートに記載されているキーワードをもとに、Twitter APIからツイート内容を取得してネガポジスコアを算出し、BigQueryに保存してDataPotalで表示&ダウンロード。
GCSとBigQueryに保管するロジックは、Cloud Functions上にpythonで構築しています。
Cloud Schedulerで1日1回実行するように設定しているため、初期設定さえすれば後は毎日全自動で取得してきてくれます。
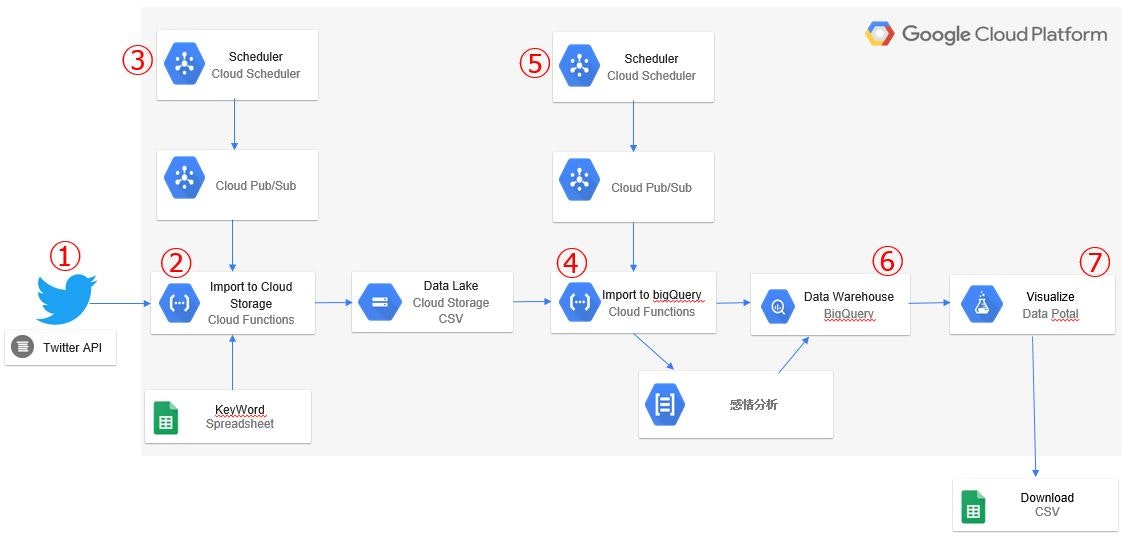
解説
① TwitterAPIでツイートを取得
Standard Search APIを利用するためには、英語で申請が必要です。
申請に関してはこちらを参考にしました。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
また、Standard Search APIによる取得は以下のような制限があります。
・1回で最大100ツイート
・15分で180回リクエスト
・取得できるツイートは過去7日間まで
15分間で最大18000ツイートまでしか取得できません。
15分経過すれば、リクエスト回数が180回に戻ります。
ここら辺はロジックを組めば何とかなりますが、7日以上前のツイートは取得できません。
本格的に取得したい場合は、有償のAPIを利用することでほぼ無制限に取得することができます。(どこまでもお金が必要)
Twitter APIに関してはこちらのページを30回以上見ました。
500万件を超えるTwitter のリツイート データを取得・分析する方法
制限あるならスクレイピングすれば良いじゃん、と思う方もいるかもしれませんが、Twitterのスクレイピングは規約で禁止されているので自重しましょう。
② Cloud FunctionsでツイートをCloud Storageに保管
Cloud FunctionsはJavaScriptやpythonをクラウド上で動作できるサービスです。
2019年からpythonの3系も利用できるようになりました。
Googleドライブ上のスプレッドシートから、あらかじめ入力しておいたキーワードを取得して、Twitter APIに投げます。
帰ってきたjsonをcsvに変換して、1日分のツイートをCloud Storageに保管します。
取得したツイート内容を直接BigQueryに保管しても良かったのですが、データ基盤を勉強している時に「データレイク」「データウェアハウス」「データマート」という概念を知ったので、一度Cloud Storageに保管しています。
データを限定して保管すると、あとから「あ、この項目も欲しかった!」なんてことになるかもしれないですしね。
データ基盤の概念についてはこちらを参考にしました。
データ基盤の3分類と進化的データモデリング
データレイクは「元データをコピーしたもの」と位置付けられているため、本来はcsvではなくjson形式で保管したかったのですが、エラーがでまくってやり方が分からなかったため断念しました。
③ Cloud Schedulerでツイート取得を定期実行
Cloud Schedulerは安価で簡単に利用することの出来るcronサービスで、oogle Pub/Sub のトピックへのメッセージ送信が可能です。
一言でいうと、日時を指定してCloud Functionsの実行が可能です。
ペイロードに値を設定することで、Cloud Functionsでその値を利用することができます。
現在はキーワードを入力しているスプレッドシートの行数を指定しているので、取得したいキーワードの数だけCloud Schedulerを設定しています。
また、①で記載したTwitter APIの制限もあるため、キーワードごとに15分の間隔を空けて実行しています。
有償のTwitter APIを契約できればこの辺りの仕組みは変わってくると思います。
④ Cloud StorageからBigQueryにネガポジスコアを追加して保管
ここでもCloud Functionsを利用しています。
pythonで感情分析を実施し、スコア化しています。
データフレームで処理しているためBigQueryへの保管はto_gbqを使っています。
pandas.DataFrame.to_gbq
to_gbqのtable_schemaでBigQueryのスキーマを指定しておかないと、ほとんどnullの項目(geo等)を保管する際に「スキーマが違う!」と怒られる場合があるので注意が必要です。
感情分析に関しては以下のサイトを参考にしましたが、まだまだ精度が低いため、精度を上げることが今後の課題です。
ツイートのデータセットが手元に約50万件あるので、これを利用してtwitterに特化した感情分析ツールを作成したいと思っています。
ディープラーニングでネガポジ分析アプリを作ってみた(python)
今回は感情分析がメインのため、BOTやリツイートを除外しています。
BOTに関しては、sourceに「twitter.com」が含まれているものだけを選定、
リツイートはツイート本文が「@ RT」で始まっているものを除外しています。
キャンペーン等でハッシュタグのカウントをしたい場合は、ロジックの変更が必要です。
⑤ Cloud Schedulerで④を実行
③とやっていることは同じです。
Cloud Storageへの保管をトリガーにCloud Schedulerで実施します。
⑥ BigQueryに保管
キーワードごとにテーブルが存在します。
Twitterの時刻が協定世界時(UTC)になっている関係で、前日午前9時~当日午前9時のツイート内容を保管しています。
ツイート内容の他に、ツイート日時、アカウント情報、ネガポジスコア等を保管しています。
⑦ DataPotalで公開
会社でGsuiteを契約しており、社員全員がGoogleアカウントを利用できるため、DataPotalでツイート内容を表示&ダウンロードができるようにしています。
csvでダウンロードすればもちろんですが、DataPotal上でもネガポジスコア順に並び替えることができます。
この部分はまだ全然触っていなくて、現在は期間指定のみですが、今後はフィルタや項目を追加していきたいと思います。
Tableauにも興味があったのですが、トライアルに申込したら認証メールが返ってこなくて断念しました。またの機会にチャレンジします。
今後の課題、やりたいこと
・キーワードが増えてきた際に、GCPの課金やロジックを変更しなければならない
・感情分析の精度UP、又はNLPを利用
・分かち書き(Mecab + NEologd)で一緒につぶやかれているワードを表示させる
・ツイートのアカウント情報からインフルエンサー影響スコアを算出、プライベートグラフやインタレストグラフ、ツイ廃等の分類を実施
最後に
python最強。検索すれば95%でてくる。英語分かれば99%でてくる。
小官にとっちゃ毎日が検索、全人類に感激感謝。
JupyterNotebookでGCPを扱うことができるので、コードのテストはJupyter上で行ったほうが良いです。(Cloud Functionsのデプロイがめっちゃ遅い)
他にも嵌った部分があったと思うので、コードも含めて今後公開していきたいと思います。
面白いこと、できることあったら教えてください。