はじめに
kaggleのTensorFlow Speech Recognition Challengeを紹介し、
Tutorialに従って学習し、結果を送信するまで実践します。
この競技は、1秒の英語音声データの12クラス識別タスクです。
Tensorflowで実行できるモデルが対象で、かつRaspberrypi3上で一定時間内に実行できるモデルである必要があります。
競技ルール
- 1秒のwavファイルが入力で、以下12クラスを識別。unknownは初めの10クラスのどれでもなく、かつsilenceでないもの。
yes, no, up, down, left, right, on, off, stop, go, silence, unknown
-
train/testデータはこちらからダウンロード。
train : TensorflowとAIYのチームが作成・公開したSpeech Commands Data Set v0.01と同じもの。約65000個のwavファイル。上記12クラスだけでなく、全部で31クラスあり、今回該当しないクラスはunknownとして扱う。_background_noise_には長時間のsilenceデータが入っている。
test : 158538個のwavファイル。正解ラベル無し。 -
testデータに対する結果を以下の形式の.csvファイルにし、送信します。
fname,label
clip_000044442.wav,silence
clip_0000adecb.wav,left
clip_0000d4322.wav,unknown
- 学習に、上記のデータ以外は使用してはならない。合成データ等も不可。
- モデルは、TensorFlow 1.4で実行できる、frozen TensorFlow GraphDefである必要がある。このため自前の推論コードは使えない。
- モデルサイズ < 5MB
- モデルの入力は16000個,floatのPCM。出力は各12クラスの確率(softmax)。
- RaspberryPi3(overclock無)上の実行時間 <= 200 msec
- モデルの学習にpretrainedを使っていいかはグレー?
- leaderboardに表示されているScore,順位は、testデータの30%によるもの。実際の順位は残り70%で決められる。
- 何回でもentryできるようだが、最終提出は1アカウントにつき
23つ選択する必要がある。 - 2018.1.8 19時現在、参加チーム数1263。leaderboardの1位Scoreは0.90。
- 賞金や日程は割愛。参加者の初めの500人に$500のGCPクレジット付与もあり。
Speech Commands Dataset
Google Research Blog : Launching the Speech Commands Dataset 和訳
約65000個, 31クラスのwavファイル。Creative Commons BY 4.0 license。
inference用に、4つのAndroidデモアプリが用意されている。 github apk
TF Speechが発話認識アプリ。マイクに発話すると認識したラベルがライトアップする。

Tutorial : Simple Audio Recognition 実践
Tensorflow : Tutorials : Simple Audio Recognitionに従って実践してみます。
学習
Tensorflowのコードツリーを取得しておきます。
https://github.com/tensorflow/tensorflow
このTutorialで使用するのは、tensorflow/examples/speech_commands 以下です。
train.py を実行すると、上記Speech Commands Datasetを/tmpにダウンロードし、学習を始め、18000回iterationを行って終了します。
python tensorflow/examples/speech_commands/train.py
| 展開ディレクトリ | 内容 |
|---|---|
| /tmp/speech_dataset | 上記Speech Commands Dataset |
| /tmp/speech_commands_train | 学習時のTensorflowのワークディレクトリ |
| /tmp/retrain_logs | 学習時のログ |
| 主なコマンドオプション | デフォルト | 内容 |
|---|---|---|
| --how_many_training_steps | 15000,3000 | iteration数 |
| --learning_rate | 0.001,0.0001 | leaning rate |
| --batch_size | 100 | batch size |
| --wanted_words | yes,no,up,down,left,right,on,off,stop,go | 識別するラベル(これ以外はunknown扱い) |
Tensorboardで経過を見ることができます。以下を実行後、http://localhost:6006 を開きます。
tensorboard --logdir /tmp/retrain_logs
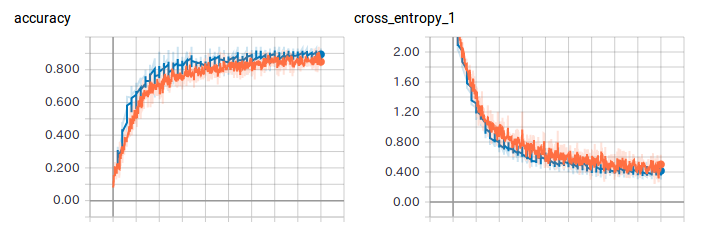
18000回実行後、以下のログで終了します。学習画像セットはtrain,validation,testに分けられますが、今回はvalidationで88.8%, testで88.4%でした。
Confusion Matrixは12クラスのどれが精度良く識別できているか確認するもので、正解クラスが各行に対し推論結果が各列であり、精度100%であれば対角行列になります。
INFO:tensorflow:Step 18000: Validation accuracy = 88.8% (N=3093)
INFO:tensorflow:Saving to "/tmp/speech_commands_train/conv.ckpt-18000"
INFO:tensorflow:set_size=3081
INFO:tensorflow:Confusion Matrix:
[[257 0 0 0 0 0 0 0 0 0 0 0]
[ 1 188 6 2 5 11 1 6 7 0 11 19]
[ 2 2 235 4 2 5 4 1 0 0 1 0]
[ 1 6 0 216 3 12 2 1 0 0 3 8]
[ 2 1 0 0 259 0 3 0 0 2 4 1]
[ 2 4 0 14 2 217 1 0 1 0 1 11]
[ 1 4 11 0 3 1 245 2 0 0 0 0]
[ 2 14 0 0 4 0 2 235 0 2 0 0]
[ 1 4 0 0 2 1 1 2 232 2 0 1]
[ 2 4 0 0 17 1 2 2 8 222 4 0]
[ 0 1 1 0 9 2 2 0 0 2 229 3]
[ 1 9 0 32 5 6 6 1 0 0 2 189]]
INFO:tensorflow:Final test accuracy = 88.4% (N=3081)
freeze化と推論テスト
学習したcheckpointデータから、デバイスで実行するコンパクトなモデルに変換するために、freeze化する必要があります。
python tensorflow/examples/speech_commands/freeze.py \
--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 \
--output_file=出力モデル.pb
1つのwavファイルを識別するテストコードが用意されています。
python tensorflow/examples/speech_commands/label_wav.py \
--graph=出力モデル.pb \
--labels=/tmp/speech_commands_train/conv_labels.txt \
--wav=テスト音声ファイル.wav
top3のスコアが表示されます。
left (score = 0.98706)
_unknown_ (score = 0.00531)
yes (score = 0.00315)
(余談) bazel インストール
Tensorflowの.ccなどをビルド・実行するのにGoogleのビルドツールbazelが必要になります。
私の環境(Ubuntu16.04)では、apt installできる bazel 0.9 ではbazel runがエラーになり、こちらを参考に、bazel 0.8.1を入れるとうまくできました。
0.8.1のインストーラをダウンロードしてインストールします。
Raspberrypi3 benchmark
Raspberrypi3での実行時間を確認する必要があります。
まずTensorflow1.4をインストールします。こちらを参照して以下を実行。
sudo apt-get install libblas-dev liblapack-dev python-dev libatlas-base-dev gfortran python-setuptools
sudo pip2 install http://ci.tensorflow.org/view/Nightly/job/nightly-pi/lastSuccessfulBuild/artifact/output-artifacts/tensorflow-1.4.0-cp27-none-any.whl
ARM用ビルド済みbenchmarkツールが用意されているのでダウンロードします。
(Discussionで、x86用があれば開発促進できるのではという話があって、ソースオープンなので自分でbuildすればいいとのこと)
curl -O https://storage.googleapis.com/download.tensorflow.org/deps/pi/2017_10_07/benchmark_model
chmod +x benchmark_model
実行します。実行にはモデルファイルだけで、データを用意する必要はないようです。
なお、pretrainedモデルconv_actions_frozen.pbも用意されています。
./benchmark_model --graph=モデルファイル --input_layer=decoded_sample_data:0,decoded_sample_data:1 --input_layer_shape=16000,1: --input_layer_type=float,int32 --input_layer_values=:16000 --output_layer=labels_softmax:0 --show_run_order=false --show_time=false --show_memory=false --show_summary=true --show_flops=true
以下のように結果表示され、avg= のところがusec単位の平均実行時間。この値が200msec以下である必要があり、マージンを考えて175msecくらいが推奨とのこと。
2018-01-08 10:16:12.082806: I tensorflow/core/util/stat_summarizer.cc:468] Timings (microseconds): count=134 first=72637 curr=72947 min=71803 max=95794 avg=74473.2 std=4549
2018-01-08 10:16:12.082838: I tensorflow/core/util/stat_summarizer.cc:468] Memory (bytes): count=134 curr=1643420(all same)
2018-01-08 10:16:12.082869: I tensorflow/core/util/stat_summarizer.cc:468] 26 nodes observed
kaggle 結果送信
テストデータの推論を実行し結果csvを出力するツールは用意されてなさそうなので、label_wav.pyを参考に書きました。
結果送信するとすぐに評価が行われます。今回のTutorialそのままで学習したモデルは、Score 0.78 でした。(現在1位は0.90)

Discussionから引用
kaggleのDiscussionでは有用なまとめ・議論がされており参考になります。
いくつか引用します。
43516 主催者の1人、Peteさんから。Tutorialはこの人が書いた。
43520 同じく主催者、Razielさん。"ok Google"等の認識エンジンを開発するグループ所属。
44091 Speech Recognition を始める人のための参照リスト
46839 学習データにノイズを付加してaugmentationする
46945 My Tricks and Solution この方が様々な実験手法を公開していて参考になる
43624 精度87.8%の実装 (pytorch)
44970 train, testのcsvファイルを生成するスクリプト
46981 TUT Acoustic Scene Classificationの紹介
おわりに
- ここまでが準備段階で、これからモデルを精製していく。(締切間近
- Discussionを見ても、テストデータに対する汎化性能を出すのが難しそうです。
- 実際の順位は未発表の残70%で決まるそうで、順位がどのように変わるかも見どころです。
- 運営がルールチェックをどうするのかも気になります。