過去にも書いていますが最近入れる機会があったので気になった部分を追加して最新に更新しました。
過去の記事は以下から。
- 2019年: Windows10 + TF2.0.0 + GPU の環境
- 2022年: Windows11 + TF2.10(tensorflow-gpu) + GPU の環境
- 2023年: Windows11 + TF2.12 + WSL2 + GPU の環境
- 2025年: ここ
はじめに
TensorFlowのGPUですが、Windowsだと公式では対応しなくなりWSL2経由で使うことが推奨されています。
なので本記事ではWSL2経由で動作する環境を構築します。
PyTorchはWindowsでも動作するのでそのまま入れています。
- 本記事の動作環境
- Windows11
- GeForce RTX 3060
ドライバの更新
グラボのドライバを最新にしておきます。(再起動が必要)
インストールするバージョンの確認
本記事ではTensorFlow/PyTorchとCUDAのバージョンに関して扱いますが、グラボとCUDAバージョンの対応に関しては扱いません。(結構複雑だったので…)
以下記事などを参考にしてください。
・GPUの型番にあったCUDAバージョンの選び方
・[nvidia公式ドキュメント] グラボの Compute Capability の確認表
・[nvidia公式ドキュメント] ドライバのバージョンとCUDAのバージョンの対応表
CUDA/cuDNN のバージョン確認
CUDA/cuDNNのバージョンは重要で、TensorFlow/PyTorchが対応したバージョンを入れないと認識しません。
まずはバージョンの確認方法から見ていきます。
TensorFlow
以下からPython、CUDA、cuDNNのバージョンを確認します。
※英語版を見ます(日本語版だと最新がなかったり)
※WSL2上で動作させるのでLinuxのバージョンを見ます
本記事では記載時最新の TF2.18.0 に準拠した以下を入れます。
TensorFlow-2.18.0
Python3.12
CUDA12.5
cuDNN9.3
※入れる先はWSL2です。
PyTorch
Python と CUDA のバージョンは公式ページの GET STARTED から確認できます。
現在最新の 2.6.0 だとPythonは 3.9-3.12、CUDAは11.8/12.4/12.6 がサポートされているようです。
ただ、リリースノートを見るとベータ版ですがPython3.13に対応とあるので試しに入れてみようと思います。
(過去のバージョンは Previous PyTorch Versions を参照)
cuDNNのバージョンですが公式ページのFootnotes[1]より、CUDA12.x とcuDNNの最新バージョンは常に互換性があるようです。(CUDA11.xは互換性がないので対応バージョンを入れる必要あり)
本記事では記載時最新 PyTorch2.6.0 に準拠した以下を入れます。
PyTorch2.6.0
Python3.13
CUDA12.6
cuDNN9.6.0
※入れる先はWindows11です。
※cuDNNですがいろいろと試した所、最新の9.8.0はCUDA12.8の対応に見えたので少し下げて入れています
※ただ、9.6.0を入れてもPyTorchでcuDNNが9.5.1に見えるのでもしかしたらPyTorchが自動で最適なcuDNNを入れているかもしれません
TensorFlow
PyTorchのみ入れる場合はここは飛ばしてください。
TensorFlowをWSL2配下に入れます。
WSLの準備
1. Hyper-V の有効化
WSL2を使えるようにするために Hyper-V を有効化します。
- スタートメニューから「Windowsの機能の有効化または無効化」を検索して開きます
- 以下を有効化(再起動が必要)
- 「Hyper-V」
- 「Linux 用 Windows サブシステム」
2. WSL2にUbuntuをインストール
コマンドプロンプト(またはPowerShell)を管理者で実行します。
まずは、インストールするディストリビューション一覧を確認します。
PS C:\WINDOWS\system32> wsl --list --online
インストールできる有効なディストリビューションの一覧を次に示します。
'wsl.exe --install <Distro>' を使用してインストールします。
NAME FRIENDLY NAME
Debian Debian GNU/Linux
SUSE-Linux-Enterprise-15-SP5 SUSE Linux Enterprise 15 SP5
SUSE-Linux-Enterprise-15-SP6 SUSE Linux Enterprise 15 SP6
Ubuntu Ubuntu
Ubuntu-24.04 Ubuntu 24.04 LTS
kali-linux Kali Linux Rolling
openSUSE-Tumbleweed openSUSE Tumbleweed
openSUSE-Leap-15.6 openSUSE Leap 15.6
Ubuntu-18.04 Ubuntu 18.04 LTS
Ubuntu-20.04 Ubuntu 20.04 LTS
Ubuntu-22.04 Ubuntu 22.04 LTS
OracleLinux_7_9 Oracle Linux 7.9
OracleLinux_8_7 Oracle Linux 8.7
OracleLinux_9_1 Oracle Linux 9.1
OSは好みですが、Ubuntuの最新である Ubuntu-24.04 をインストールしました。
PS C:\WINDOWS\system32> wsl --install Ubuntu-24.04
ダウンロード中: Ubuntu 24.04 LTS
インストール中: Ubuntu 24.04 LTS
ディストリビューションが正常にインストールされました。'wsl.exe -d Ubuntu-24.04' を使用して起動できます
初回のみwslに入ると初期設定を聞かれるのでユーザ名とパスワードを設定します。
このパスワードはsudoコマンド使用時に必要になります。
PS C:\WINDOWS\system32> wsl -d Ubuntu-24.04 # 指定のWSLに入る
Provisioning the new WSL instance Ubuntu-24.04
This might take a while...
Create a default Unix user account: qiita # 好きなユーザ名を入れる
New password: # パスワード
Retype new password: # パスワード確認用
passwd: password updated successfully
(略)
qiita:/mnt/c/WINDOWS/system32$ exit # WSLから抜ける
3. CUDAのインストール(WSL2 - Ubuntu)
事前に確認したバージョン(CUDA12.5)をいれます。
参考:NVIDIA公式 : WSL 2 の CUDA サポート
まずWSLに入り、古いGPGキーを削除します。
> wsl -d Ubuntu-24.04
$ sudo apt-key del 7fa2af80
以下ページより、特定のCUDAをインストールします。
今回は12.5の最新である12.5.1を入れました。
選択した項目は以下です。
Operating System: Linux
Architecture : x86_64
Distribution : WSL-Ubuntu
Version : 2.0
Install Type : deb(local)
するとインストールコマンドが表示されるのでそれ通りに入力します。
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.5.1/local_installers/cuda-repo-wsl-ubuntu-12-5-local_12.5.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-5-local_12.5.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-5-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-5
確認は以下です。
$ /usr/local/cuda/bin/nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Jun__6_02:18:23_PDT_2024
Cuda compilation tools, release 12.5, V12.5.82 # <-- release 12.5
Build cuda_12.5.r12.5/compiler.34385749_0
4. cuDNN のインストール(WSL2 - Ubuntu)
以下より特定のバージョンをインストールします。
今回は上記で調査した9.3の最新である9.3.0をインストールしました。
選択肢は以下です。
Operating System: Linux
Architecture : x86_64
Distribution : Ubuntu
Version : 24.04
Installer Type : deb(local)
表示されたコマンドを実行します。
wget https://developer.download.nvidia.com/compute/cudnn/9.3.0/local_installers/cudnn-local-repo-ubuntu2404-9.3.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2404-9.3.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2404-9.3.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
sudo apt-get -y install cudnn-cuda-12
確認ですが、素直な確認はよく分かりませんでした。
一応バージョンは以下から確認できます。
$ cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
#define CUDNN_MAJOR 9
#define CUDNN_MINOR 3
#define CUDNN_PATCHLEVEL 0
(略)
また、サンプルのmakeによる確認は以下です。
$ sudo apt -y install libfreeimage3 libfreeimage-dev
$ cp -r /usr/src/cudnn_samples_v9/ ~/
$ cd ~/cudnn_samples_v9/mnistCUDNN/
$ make clean && make
$ ./mnistCUDNN
Executing: mnistCUDNN
cudnnGetVersion() : 90300 , CUDNN_VERSION from cudnn.h : 90300 (9.3.0)
Host compiler version : GCC 13.3.0
(略)
Test passed!
5. Pythonのインストール(WSL2 - Ubuntu)
インストールできるPythonのバージョンは以下から確認できます。
$ apt list python3.*
Listing... Done
python3.12-dbg/noble-updates,noble-security 3.12.3-1ubuntu0.5 amd64
(略)
python3.12が使えますね。
ただ、標準で使えるバージョンはあまり多くないので違うバージョンを利用する場合は deadsnakes PPA を使う方法が簡単です。
※ deadsnakes PPA は非公式な点は注意してください。
参考
・https://qiita.com/lilacs/items/fbc1682e86dc58010298
$ sudo apt update
$ sudo apt install -y software-properties-common
$ sudo add-apt-repository -y ppa:deadsnakes/ppa
$ sudo apt update
$ apt list python3.*
# インストールできるpythonの確認
# pythonはvenvも入れておきます。
$ sudo apt install -y python3.12 python3.12-venv
6. venvの構築とTensorFlowのインストール(WSL2 - Ubuntu)
Pythonの環境はvenvで管理します。
venvを作成する場所はどこでもいいですが、後でVSCodeから参照できる場所にします。
$ mkdir ~/venv
$ cd ~/venv
$ python3.12 -m venv py312
$ ls
py312
作成したvenv内で事前に確認したバージョンのTensorFlowをインストールします。
$ source ~/venv/py312/bin/activate
# TFのインストール
(py312)$ pip install tensorflow==2.18.0
# GPUの認識を確認
(py312)$ python -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())"
(略)
, name: "/device:GPU:0" # /device:GPU が見えているはず
device_type: "GPU"
memory_limit: 9970909184
locality {
bus_id: 1
links {
}
}
# CUDA/cuDNNのバージョンを確認
(py312)$ python -c "import tensorflow as tf; print(tf.sysconfig.get_build_info())"
(略)
OrderedDict({'cpu_compiler': '/usr/lib/llvm-18/bin/clang', 'cuda_compute_capabilities': ['sm_60', 'sm_70', 'sm_80', 'sm_89', 'compute_90'], 'cuda_version': '12.5.1', 'cudnn_version': '9', 'is_cuda_build': True, 'is_rocm_build': False, 'is_tensorrt_build': False})
'cuda_version': '12.5.1'、'cudnn_version': '9' と認識していますね。
VSCodeとの連携
1. 準備(VSCode - WSL2)
以前と変わりなく、VSCodeからWSLにリモートアクセスし、その上で作業する形で連携させます。
以下は連携の一例となります。
まず、拡張機能WSLを入れます。
すると左メニューにリモートエクスプローラーが追加されるので、Ubuntu-24.04を右クリックして新しいウィンドウでWSLへアクセスします。
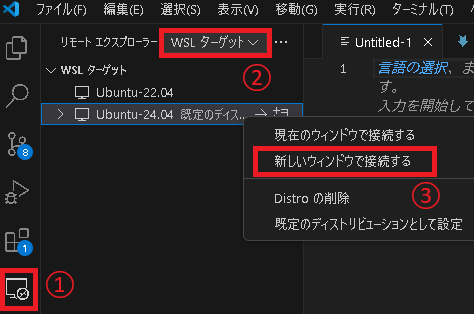
新しいウィンドウが開くので、フォルダを開く から適当な作業ディレクトリを開きます。
※Windows側のディレクトリは /mnt/ 配下にマウントされています。
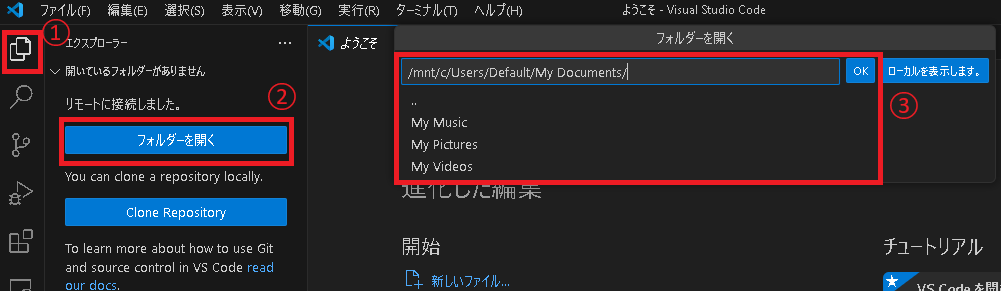
また、新しいウィンドウで開かれたVSCode(WSL側)はWindows側とは管理が別なようで、各拡張機能も別途インストールする必要があります。
Pythonの拡張機能は必須です。
2. venvとVSCodeの紐づけ(VSCode - WSL2)
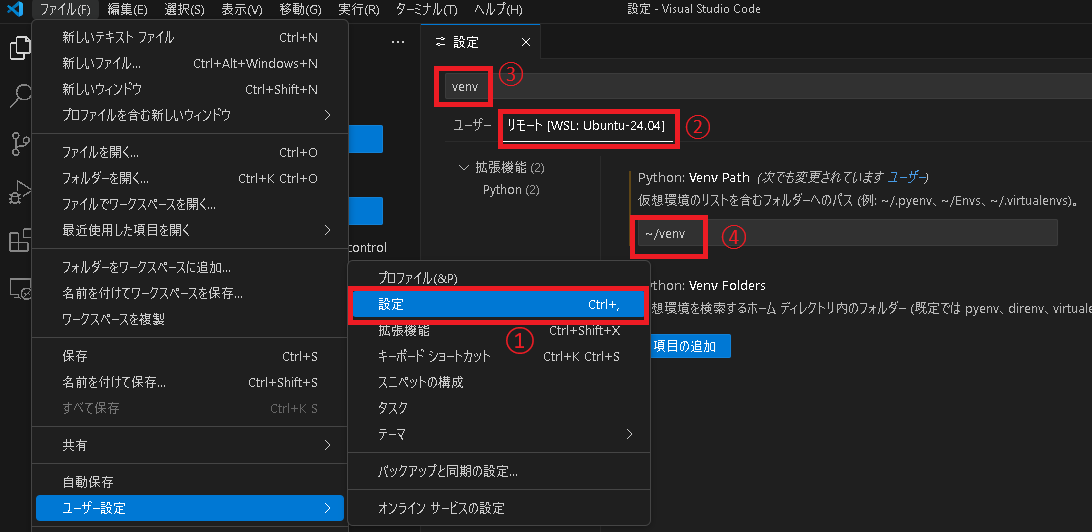
WSL側のVSCodeウィンドウで ファイル → ユーザー設定 → 設定 を選択し、タブから リモート[WSL: Ubuntu-24.04] を選択、検索欄で venv をいれてPythonのVenv Pathに ~/venv を設定します。
(~/venv は上で作成したWSL内のvenvのパスです)
設定したら適当なpythonファイルを開くと右下にインタープリターの選択が出てくるので上で作成したvenvを選びます。
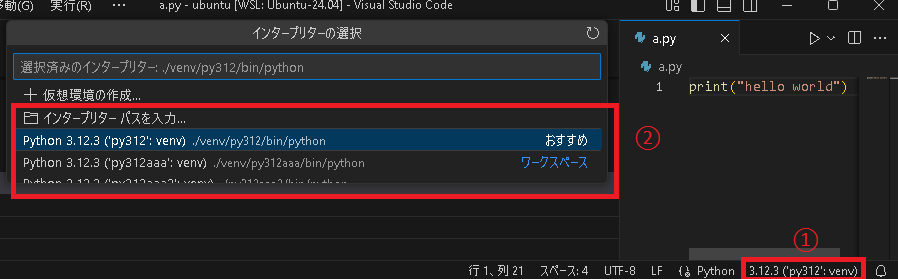
これで設定完了です。
以下は動作確認用のプログラムです。
サンプルプログラム(TensorFlow)
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
print("GPU list:", tf.config.list_physical_devices("GPU"))
print(tf.sysconfig.get_build_info())
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
model = models.Sequential(
[
layers.Input((28, 28, 1)),
layers.Conv2D(32, (3, 3), padding="same", activation="relu"),
layers.MaxPool2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, epochs=1)
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"\nテスト精度: {test_acc}")
PyTorch
PyTorchを入れない場合はここは飛ばしてください。
1. CUDAのインストール(Windows11)
事前に確認したバージョン(CUDA12.6)をいれます。
以下ページより、特定のCUDAをインストールします。
今回は12.6の最新である12.6.3を入れました。
選択した項目は以下です。
Operating System: Windows
Architecture : x86_64
Version : 11
Install Type : exec(local)
インストーラーがあるので実行してインストールします。(cuda_12.6.3_561.17_windows.exe)
2. cuDNN のインストール(Windows11)
9.6.0を入れます。
選択肢は以下です。
Operating System: Window
Architecture : x86_64
Version : 10
Installer Type : exe(local)
インストーラーをダウンロードして実行します。(cudnn_9.6.0_windows.exe)
3. Python/venv/PyTorchのインストール(Windows11)
Pythonは公式からインストーラー Windows installer (64-bit) をダウンロードして実行します。
インストール出来たらコマンドプロンプトよりvenvの環境を作ります。
// venvの場所はVSCodeから参照できる場所
> mkdir c:\venv
> cd c:\venv
> py -3.13 -m venv py313
> dir
py313
PyTorchをインストールします。
選択肢は以下です。
PyTorch Build : Stable(2.6.0)
Your OS : Windows
Package : Pip
Language : Python
Compute Platform: CUDA 12.6
// venvの中に入る
> c:\venv\py313\Scripts\activate.bat
// インストールコマンドを実行
(py313)> pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
// 確認
(py313)> python -c "import torch; print(torch.cuda.is_available()); print(torch.version.cuda); print(torch.backends.cudnn.is_available()); print(torch.backends.cudnn.version())"
True # GPUが有効か
12.6 # CUDAのバージョン
True # cuDNNが有効か
90501 # cuDNNのバージョン
4. venvとVSCodeの紐づけ(Windows11)
VSCodeはPythonの拡張機能が必須なので入れておきます。
ファイル → ユーザー設定 → 設定 を選択し、検索欄で venv をいれてPythonのVenv Pathに C:\venv を設定します。
(C:\venv は上で作成したvenvのパスです)
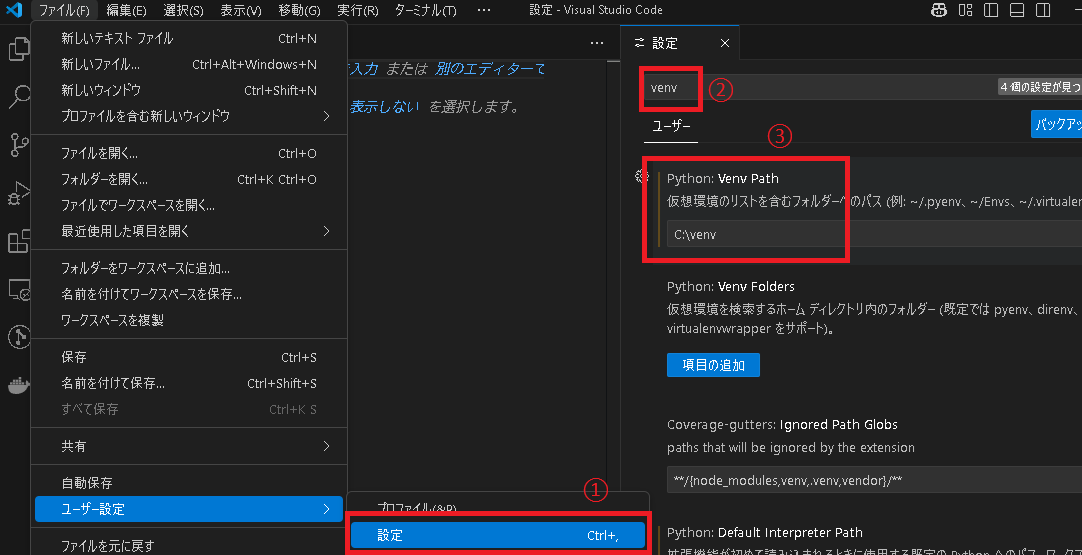
設定したら適当なpythonファイルを開くと右下にインタープリターの選択が出てくるので上で作成したvenvを選びます。
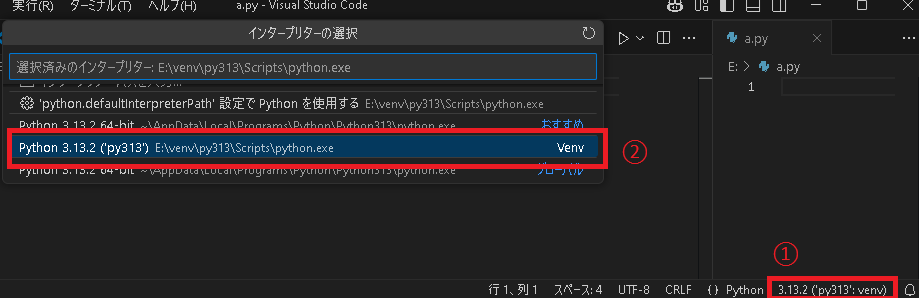
これで設定完了です。
以下は動作確認用のプログラムです。
サンプルプログラム(PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"{device=}")
print(f"{torch.version.cuda=}")
print(f"{torch.backends.cudnn.enabled=}")
print(f"{torch.backends.cudnn.version()=}")
transform = transforms.ToTensor()
train_dataset = torchvision.datasets.MNIST("./data", train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST("./data", train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
class MLP(nn.Module):
def __init__(self) -> None:
super().__init__()
self.fc = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(32 * 14 * 14, 32),
nn.ReLU(),
nn.Linear(32, 10),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.fc(x)
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_eval(model: nn.Module, loader: DataLoader, train: bool = True) -> float:
model.train() if train else model.eval()
total, correct, loss_sum = 0, 0, 0.0
for images, labels in loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
if train:
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
correct += (outputs.argmax(1) == labels).sum().item()
total += labels.size(0)
return (correct / total) * 100 if not train else loss_sum / len(loader)
# 実行
for epoch in range(1):
print(f"Train Loss: {train_eval(model, train_loader):.4f}")
print(f"Test Accuracy: {train_eval(model, test_loader, train=False):.2f}%")
おわりに
バージョンの確認方法やPyTorchの入れ方も毎回調べていたので追加してまとめてみました。
cuDNNがログイン不要でインストーラーになっていたりと細かいところで入れやすくなっていますね。