この記事は自作している強化学習フレームワーク SimpleDistributedRL の解説記事です。
Agent57を実装したフレームワークは多分これだけです。(2022/6現在)
前:R2D2
NGU/Agent57
記事を書こうとしましたが、以前書いた記事と大きく変わらなかったのでメインはそちらをご覧ください。
以前は理解できていおらず、気がかりだった内容を追加で説明します。
UVFA(Universal Value Function Approximators)
・参考
(DeepMind社のスライド) Universal Value Function Approximators
(論文) Universal Value Function Approximators
DQNでは状態 $s$ から価値 $V(s;\theta)$ を近似していました。
(状態空間における価値を学習していました)
(便宜上数式は状態価値 V で書いています)
$$
V_{\pi}^*(s) \approx V_{\pi}(s; \theta)
$$
UVFAのアイデアは、状態空間上の価値だけではなくそれ以外の空間も学習できるように、状態空間を拡張する事です。
(Q関数の表現力を上げたい)
例としてゴール空間も学習する場合を考えます。
$$
V_{g, \pi}^*(s) \approx V_{\pi}(s, g; \theta)
$$
一般的な報酬設計では、エージェントの最終ゴール以外に学習難易度を下げるために中間ポイント(サブゴール,疑似報酬)を設定する事も珍しくありません。
(この最終ゴールやサブゴールを含めた報酬空間をゴール空間と言っています)
そして一般的にゴール空間には状態空間と同じぐらいの構造が含まれているそうです。1
例えばPendulum-v1で、これは最適解までの距離を報酬にしています。
ゴールに近くなるほど報酬が大きくなるような環境は状態空間とゴール空間が似た構造になります。
UVFAのメリット
スライドで語られている利点は以下です。
- 価値関数としての表現力が広がる(上記の説明)
- 状態を分解でき、モジュール性が高まる(Agent57で使用)
- 一定期間の抽象的な計画(temporally abstract planning)を学習し、長い視野が持てる
論文では以下です。
- 同じ挙動(same dynamics)で異なる目標を持つ別タスクに転移学習する事ができる
具体的には$V(s,g;\theta)$は、$g$が見えない新しいタスク$V(s;\theta)$の初期値に使用できます。 - 一定期間の抽象的なオプション(temporally abstract options)を生成し、アクションの決定に対してソフトなgreedyとして働く
(temporally abstract options = サブゴールだと思います。ゴールの間にサブゴールを持てることにより、長い視野や長期的な計画が実行可能になるとといった内容かと思います) - UVFAは普遍的なモデル(universal option model)としても使用できる
$V(s,g;\theta)$は疑似報酬(サブゴール; $g$)までの(割引された)価値を学習します。
Agent57におけるUVFA
Agent57では以下の空間を入力としています。
- 状態
- 外部報酬/内部報酬
報酬は上で説明した理由と同じだと思います。 - 内部探索率(アクター)
NGU/Agent57では内部報酬という探索を促す報酬を新しく定義しています。
(内部報酬の反映率を表すものが内部探索率です)
探索率が高い空間とそうじゃない空間は大きく違うことが予想されるのでいれているのかと思います。 - アクション
最後にアクション空間ですがこれは分かりません…。
R2D2からひっそり入っているようですが理由は見当たりませんでした…(見逃していたらすいません)
アクション空間が表すのは過去の履歴ですけど、LSTMで学習できるので必要ないような…?
比較
フレームワーク上の実装はgithubを見てください。
また、Agent57から処理が重いLSTMとmultisteps(retrace)を除いたAgent57_lightも実装しています。
Agent57
Agent57の各要素を比較してみました。
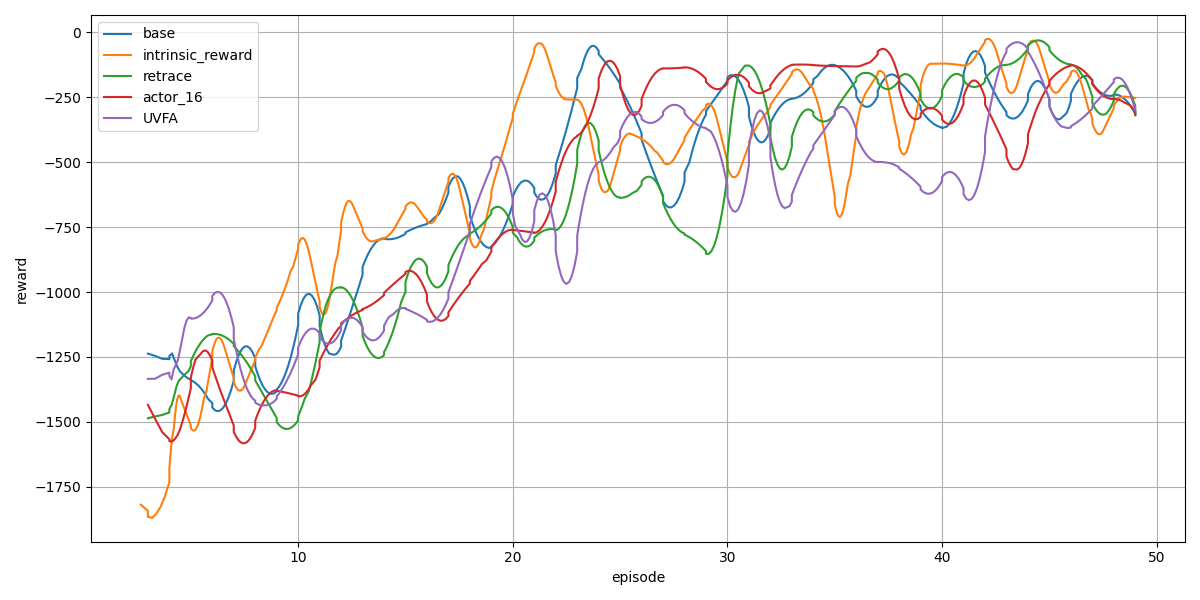
このレベルだとあまり差はでないですね。
実行に使ったコードは github を参照してください。
R2D2 vs Agent57
R2D2とAgent57の比較です。
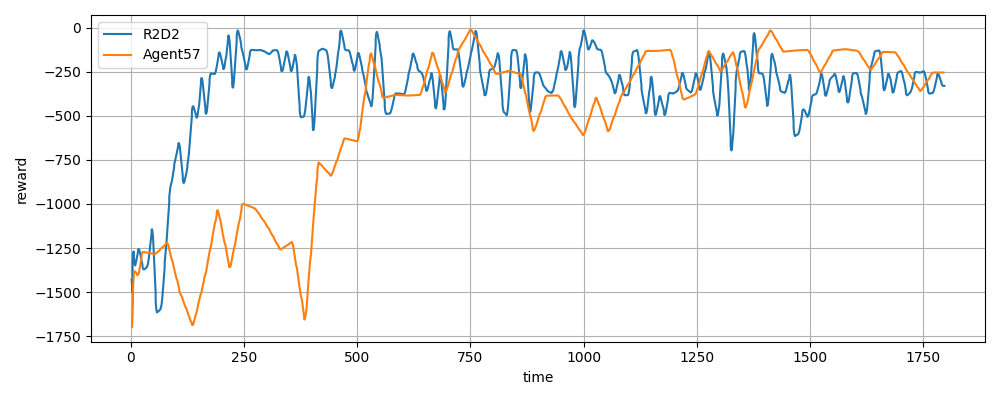
上は横軸は時間(s)の報酬の推移です。
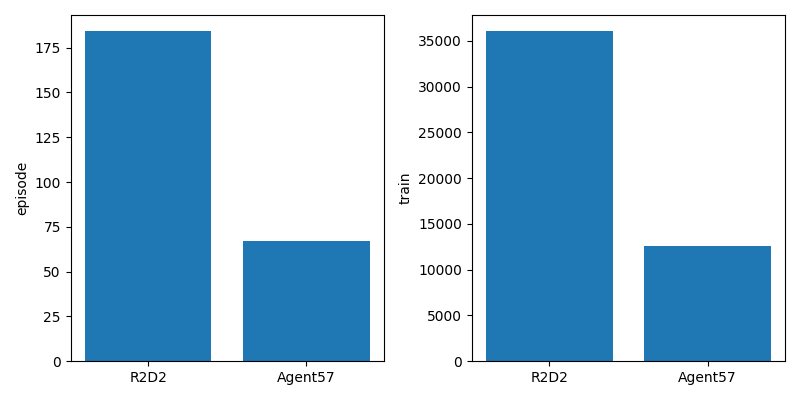
下は学習後のエピソード回数(左)と学習回数(右)です。
Agent57は内部報酬の計算でNNが2つも増えているので、計算にどうしても時間がかかります。
使用コード
※古いバージョンのsrlで書かれているので動かない可能性があります
import matplotlib.pyplot as plt
import srl
from srl import runner
# --- env & algorithm load
import gym # isort: skip # noqa F401
from srl.algorithms import agent57, r2d2 # isort: skip
env_config = srl.EnvConfig("Pendulum-v1")
rl_configs = []
rl_configs.append(("R2D2", r2d2.Config(
lstm_units=128,
hidden_layer_sizes=(128,),
enable_dueling_network=False,
memory_name="ReplayMemory",
target_model_update_interval=100,
enable_rescale=False,
burnin=5,
sequence_length=5,
enable_retrace=True,
)))
rl_configs.append(("Agent57", agent57.Config(
lstm_units=128,
hidden_layer_sizes=(128,),
enable_dueling_network=False,
memory_name="ReplayMemory",
target_model_update_interval=100,
enable_rescale=False,
burnin=5,
sequence_length=5,
enable_retrace=True,
#
enable_intrinsic_reward=True,
actor_num=4,
input_ext_reward=False,
input_int_reward=False,
input_action=False,
)))
# train
results = []
for name, rl_config in rl_configs:
print(name)
config = runner.Config(env_config, rl_config)
_, _, history = runner.train(config, timeout=60 * 30, enable_evaluation=False)
results.append((name, history))
# plot
plt.figure(figsize=(10, 4))
plt.xlabel("time")
plt.ylabel("reward")
for name, h in results:
df = h.get_df()
plt.plot(df["time"], df["episode_reward0"].rolling(5).mean(), label=name)
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()
fig = plt.figure(figsize=(8, 4))
ax1 = fig.add_subplot(1, 2, 1)
ax1.set_ylabel("episode")
names = [n for n, h in results]
episodes = [h.get_df()["episode_count"][-1] for n, h in results]
ax1.bar(names, episodes)
ax2 = fig.add_subplot(1, 2, 2)
ax2.set_ylabel("train")
names = [n for n, h in results]
trains = [h.get_df()["train_count"][-1] for n, h in results]
ax2.bar(names, trains)
plt.tight_layout()
plt.show()
DQN vs Rainbow vs Agent57_light
Agent57_lightはAgent57からLSTMとMultistepsを除いた本フレームワーク独自のアルゴリズムです。
LSTMは処理時間が短くなるように除いており、Multisteps(+retrace)は処理が複雑になるので除いています。
学習は分散+GPUで実行しました。
CPU: Core i9-12900 2.4GHz
GPU: NVIDIA GeForce GTX 3060
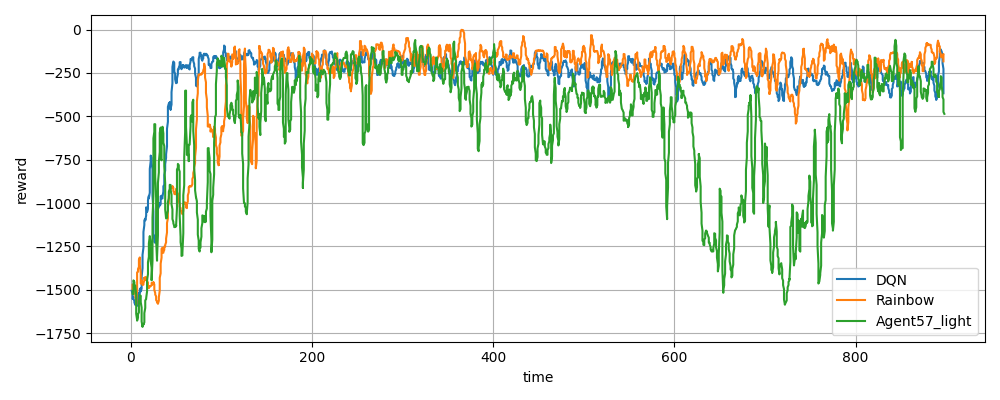
横軸は時間(s)です。
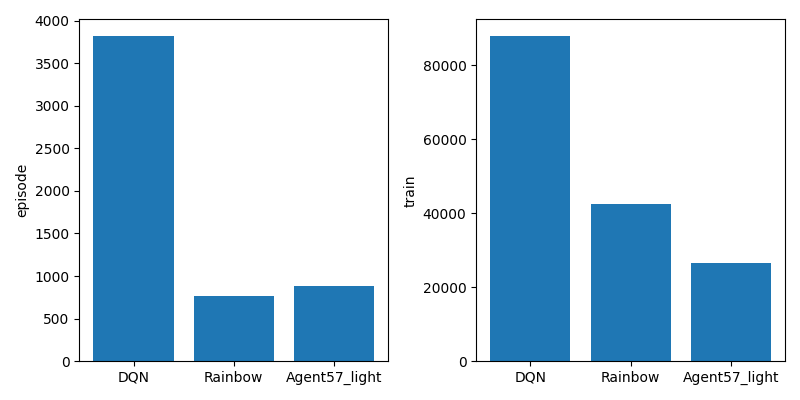
学習後のエピソード回数(左)と学習回数(右)です。
やはりこのレベルだと学習回数がものを言いそうです。
立ち上がり(DQN>Rainbow>Agent57_light)と学習回数(DQN>Rainbow>Agent57_light)の順番が同じですね。
学習回数のわりに学習ができている事からRainbowとAgent57_lightはだいぶ改良されていそうなのは分かります。
使用コード
※古いバージョンのsrlで書かれているので動かない可能性があります
import matplotlib.pyplot as plt
import srl
from srl import runner
# --- env & algorithm load
import gym # isort: skip # noqa F401
from srl.algorithms import dqn, rainbow, agent57_light # isort: skip
def main():
env_config = srl.EnvConfig("Pendulum-v1")
rl_configs = []
rl_configs.append(
(
"DQN",
dqn.Config(
hidden_block_kwargs=dict(hidden_layer_sizes=(128, 128)),
target_model_update_interval=100,
enable_rescale=False,
),
)
)
rl_configs.append(
(
"Rainbow",
rainbow.Config(
hidden_layer_sizes=(128, 128),
target_model_update_interval=100,
enable_rescale=False,
#
enable_double_dqn=True,
enable_dueling_network=True,
memory_name="ProportionalMemory",
multisteps=5,
enable_noisy_dense=True,
),
)
)
rl_configs.append(
(
"Agent57_light",
agent57_light.Config(
hidden_layer_sizes=(128, 128),
target_model_update_interval=100,
enable_rescale=False,
#
enable_double_dqn=True,
enable_dueling_network=False,
memory_name="ReplayMemory",
#
actor_num=4,
enable_intrinsic_reward=True,
input_ext_reward=False,
input_int_reward=False,
input_action=False,
),
)
)
# train
results = []
for name, rl_config in rl_configs:
print(name)
config = runner.Config(env_config, rl_config)
mp_config = runner.MpConfig(1, allocate_trainer="/GPU:0")
_, _, history = runner.mp_train(config, mp_config, timeout=60 * 15, enable_evaluation=False)
results.append((name, history))
# plot
plt.figure(figsize=(10, 4))
plt.xlabel("time")
plt.ylabel("reward")
for name, h in results:
df = h.get_df()
plt.plot(df["time"], df["episode_reward0"].rolling(10).mean(), label=name)
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()
fig = plt.figure(figsize=(8, 4))
ax1 = fig.add_subplot(1, 2, 1)
ax1.set_ylabel("episode")
names = [n for n, h in results]
episodes = [h.get_df()["episode_count"][-1] for n, h in results]
ax1.bar(names, episodes)
ax2 = fig.add_subplot(1, 2, 2)
ax2.set_ylabel("train")
names = [n for n, h in results]
trains = [h.get_df()["train_count"][-1] for n, h in results]
ax2.bar(names, trains)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()