Glue ジョブ の Python shell
Glueのジョブタイプは今まではSpark(PySpark,Scala)だけでしたが、新しくPython Shellというジョブタイプができました。GlueのジョブとしてPythonを実行できます。もちろん並列分散処理するわけではないので以下のようにライトなタスクでの用途を想定しています。そのため料金も秒課金になっています。ETLの前や後や途中のライトな処理に活用できるかと
ユースケース アイデア
Serverless Edge Node for triggering, light transformations, uncompress, tar extract, Parquet conversion
AWS GlueのPython Shell出たってばよ!
— Hirokazu Kobayashi (@hiro_koba_jp) January 21, 2019
わざわざSparkのフレームワークを使う必要のない簡単な処理を、Glueのジョブの依存関係に仕込めそう。
思いつくのはAWS SDKの操作、入力データのメタデータを使った設定処理、転送後のデータ確認とかかな。https://t.co/EvjuIUSeJzhttps://t.co/exhvOdplue
思いつくのはAWS SDKの操作、入力データのメタデータを使った設定処理、転送後のデータ確認とかかな
Python shellを使ったジョブを作る
内容
- 1つ目のジョブ(pyspark):csvデータをparquetフォーマットに変換し、パーティションを切り、出力ファイルを1つにする。
- 2つ目のジョブ(python shell):1つ目のジョブの出力ファイル part-xxxxx.snappy.parquetのファイル名をリネームする
流れ
- 1つ目のPySparkのジョブを実行 => 2つ目のPythonShellのジョブを実行
まず1つ目のジョブ
内容
1つ目のPySparkジョブは以下のリンクの後半にあるse2_job3とほぼ同じ内容です
https://qiita.com/pioho07/items/523aec26ca5dc5bc9697
上記読んでいただければ1つ目のジョブの内容はわかります。簡単に概要だけ説明します。
以下のcsvデータをparquetフォーマットに変換し、'country', 'year','month','day','hour'でパーティションを切ります。一箇所追加したのはrepartition(1)で出力ファイルを1つにしています。
ソースデータ(19件)
※①と同じデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
ジョブ名
se2_job15(se2_job3とほぼ同じ内容)
クローラー名
se2_in0
S3
in0 (入力)
out15 (出力)
ジョブの実行と確認
以下のジョブを実行する
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
### add
df = dropnullfields3.toDF()
partitionby=['country','year','month','day','hour']
output='s3://test-glue00/se2/out15/'
codec='snappy'
df.repartition(1).write.partitionBy(partitionby).mode("overwrite").parquet(output,compression=codec)
# df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").format('com.databricks.spark.avro').save(output,compression=codec)
### add
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out15"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out15"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
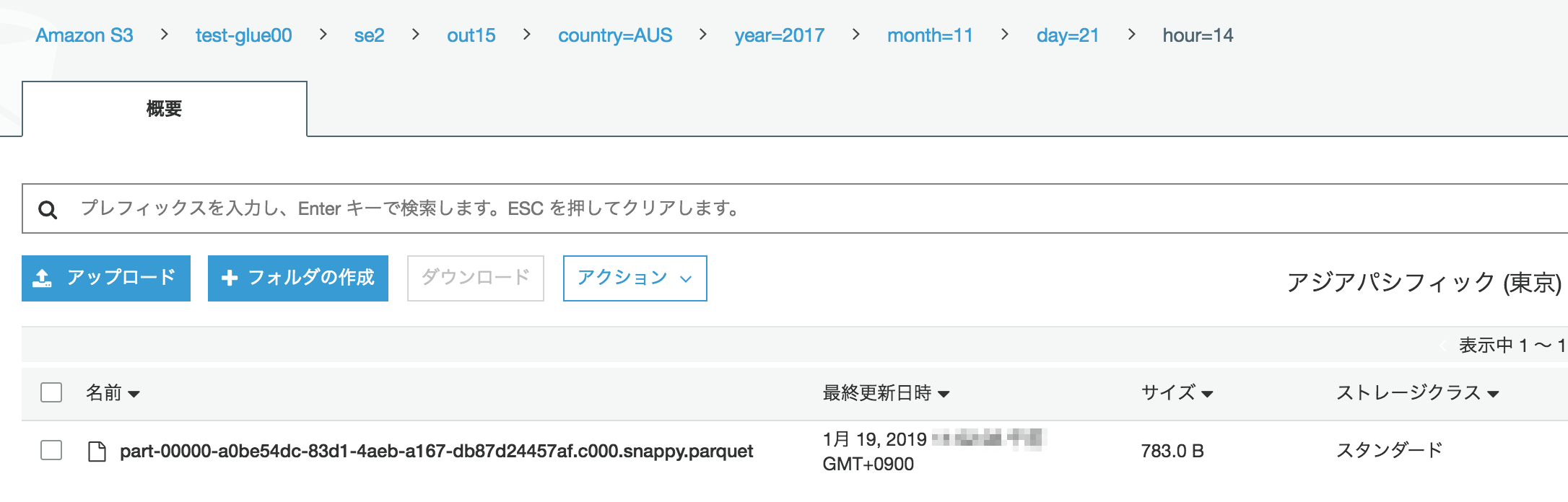
S3上の出力ファイルを確認
"part-00000-a0be54dc-83d1-4aeb-a167-db87d24457af.c000.snappy.parquet"という名前のファイルが出力されている
次に2つ目のジョブ
内容
part-xxxというオブジェクト名を、パーティションのディレクトリの一部の"country=xxx"という名前にリネームする
ジョブ名
se2_job16
S3
out15 (入力/出力)
python shellのジョブの作成と実行
Glueの画面から"ジョブ"->[ジョブの追加]をクリックする
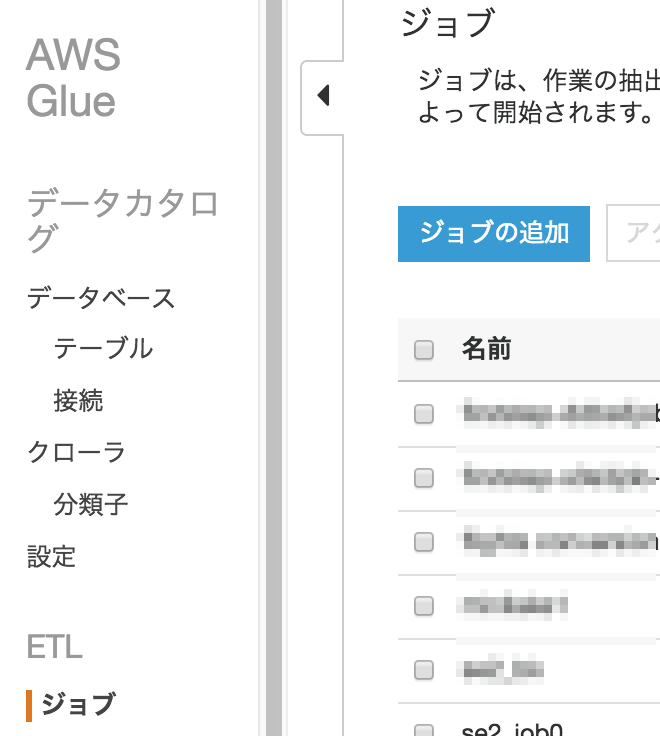
ジョブ名"se2_job16"、Typeで"Python shell"を選択し、"ユーザーが作成する新しいスクリプト"にチェックを入れる。
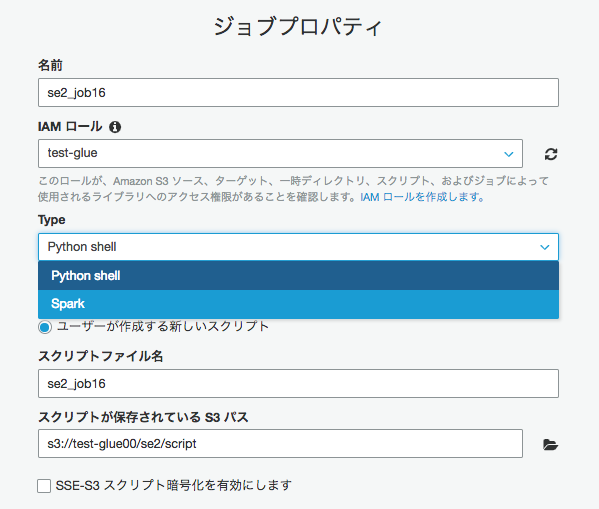
"セキュリティの設定"箇所をクリックしオプションを確認してみる。Maximum capacityはデフォルトが0.0625となっている。[次へ]をクリックする
次の画面で"接続"は必要ないので、そのまま[ジョブを保存してスクリプトを編集する]をクリックする
※Capacity:このジョブの実行時に割り当てることができるAWS Glueデータ処理ユニット(DPU)の最大数。 DPUは4vCPU,16GBメモリ。値は0.0625または1に設定できます。デフォルトは0.0625です
非常にシンプルな画面が出る
コードを書き[保存]をクリックする
今回はpart-xxxxxの長い名前を、パーティションで切っている国名にファイル名をリネームする(オブジェクトコピーして元オブジェクトをデリートだが).
# -*- coding: utf-8 -*-
import boto3
import re
s3 = boto3.resource('s3')
bucket = s3.Bucket('test-glue00')
bucket_name='test-glue00'
for object in bucket.objects.filter(Prefix='se2/tmp2/country='):
#print(object.key)
old_file = object.key
pattern1 = r'.*part.*'
result1 = re.match(pattern1, old_file)
if result1:
Copy_from = result1.group()
Copy_to = result1.group().rsplit('/', 1)[0] + '/' + result1.group().split("/")[2]
s3.Object(bucket_name,Copy_to).copy_from(CopySource=bucket_name + '/' + Copy_from )
s3.Object(bucket_name,Copy_from).delete()
作成されたジョブにチェックを入れ、アクションからジョブの実行を行う
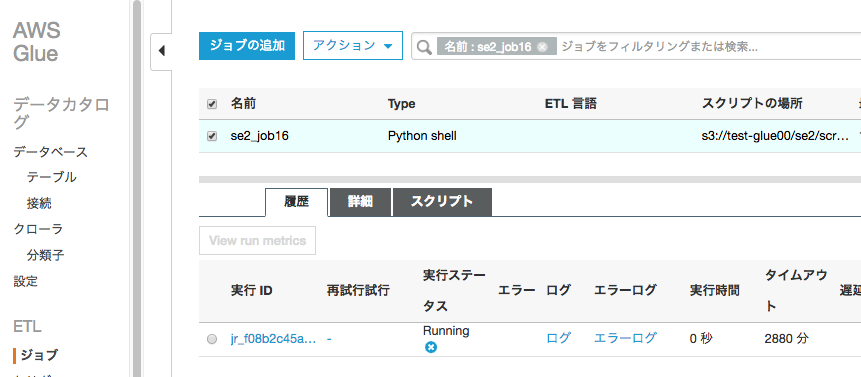
ジョブが成功し"country=AUS"の名前でリネームされた。
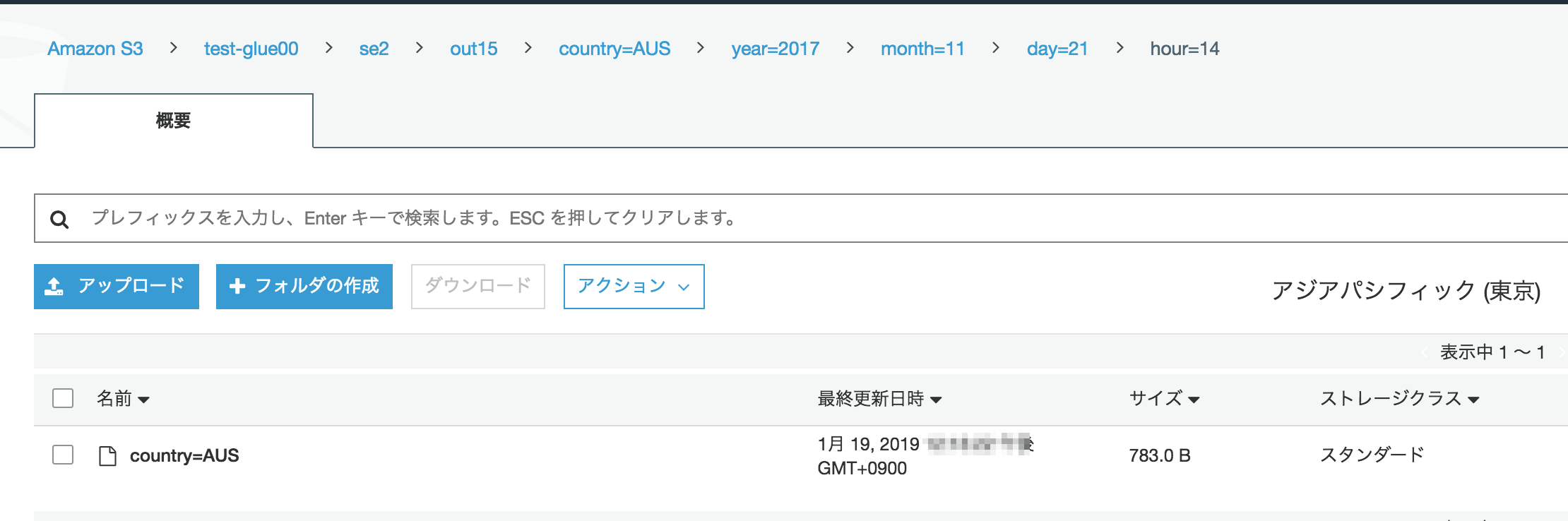
S3 selectで確認
"アクション"から"S3 Select"をクリックし

"Parquet"にチェックを入れ、[ファイルプレビューの表示]をクリックし、データが表示されることを確認できる

これジョブなので
Glue のトリガとしても設定できます
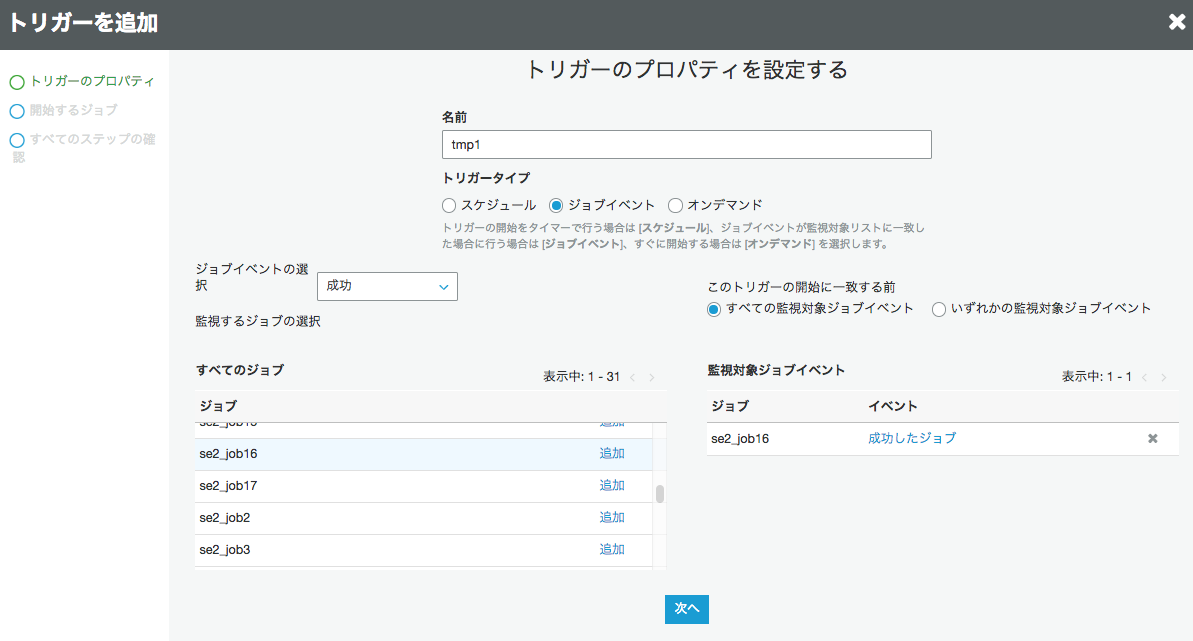
StepFunctionで直接よびだせます
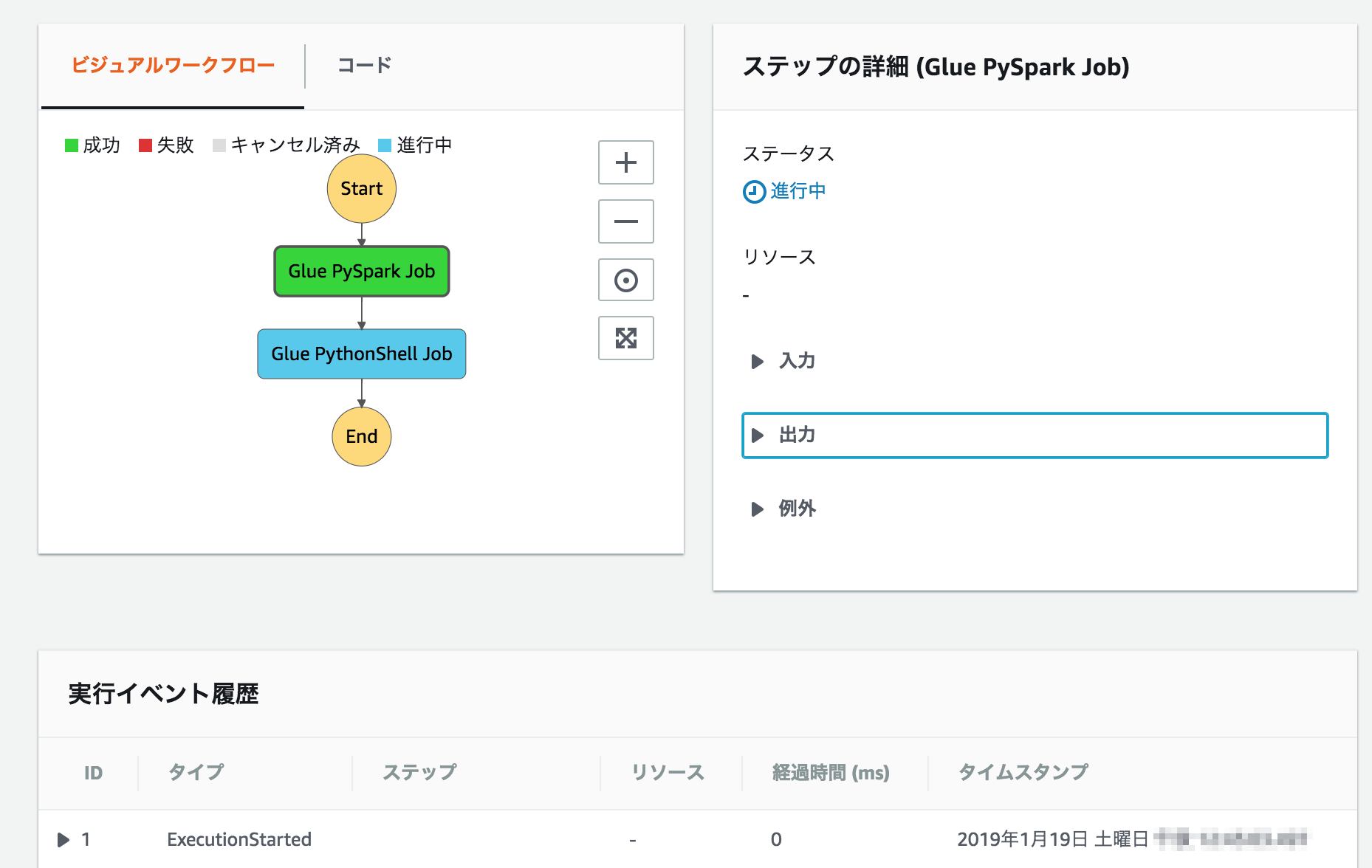
ジョブ1->ジョブ2の単純なフローを作る
{
"Comment": "A state machine that submits a Job to Glue Batch and monitors the Job until it completes.",
"StartAt": "Glue PySpark Job",
"States": {
"Glue PySpark Job": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "se2_job15"
},
"Next": "Glue PythonShell Job",
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
},
"Glue PythonShell Job": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "se2_job16"
},"End": true,
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
}
}
}
その他
料金
1秒あたりに課金され、PythonシェルタイプのETLジョブごとに最小1分で、1 DPU時間あたり0.44ドル。最小1分なので0.0625DPUだと1実行が最小で0.05円くらい(多分)。
正確にはWebをご確認ください
https://aws.amazon.com/glue/pricing/
ライブラリとか
Python 2.7互換スクリプト
サポートライブラリ:
Boto3
collections
CSV
gzip
multiprocessing
NumPy
pandas
pickle
re
SciPy
sklearn
sklearn.feature_extraction
sklearn.preprocessing
xml.etree.ElementTree
zipfile
こちらも是非
Python Shell Job in Glue
https://docs.aws.amazon.com/glue/latest/dg/add-job-python.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f
re:Invent 2018での説明
https://www.slideshare.net/AmazonWebServices/building-serverless-analytics-pipelines-with-aws-glue-ant308-aws-reinvent-2018