パーティション分割するジョブを作る
ジョブの内容
※"Glueの使い方的な①(GUIでジョブ実行)"(以後①とだけ書きます)と同様のcsvデータを使います
"csvデータのタイムスタンプのカラムごとにパーティション分割してparquetで出力する"
ジョブ名
se2_job1
クローラー名
se2_in0
se2_out1
全体の流れ
- 前準備
- ジョブ作成と修正
- ジョブ実行と確認
- 出力データのクローラー作成、実行、Athenaで確認
- 別のカラムでパーティション分割
※①のGUIで作成したPySparkスクリプトに最小限の変更を入れる形で進めます
前準備
ソースデータ(19件)
※①と同じデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
データの場所
※①と同じ場所
$ aws s3 ls s3://test-glue00/se2/in0/
2018-01-02 15:13:27 0
2018-01-02 15:13:44 691 cvlog.csv
S3のディレクトリ構成
Glueジョブの入力データは"in0"ディレクトリ配下、出力は"out1"ディレクトリ配下
$ aws s3 ls s3://test-glue00/se2/
PRE in0/
PRE out0/
PRE out1/
PRE script/
PRE tmp/
入力テーブルのクローラー
※①で作ったものを使います。
テーブルの情報は以下です。
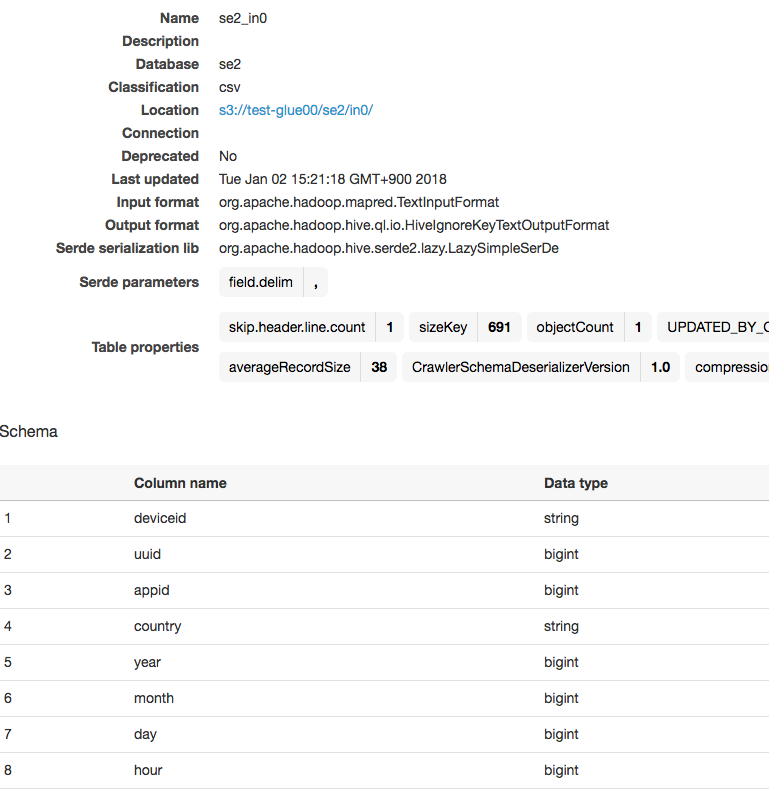
ここから、ジョブ作成とPySparkスクリプト修正、出力データのクローラー作成を行っていきます
ジョブ作成と修正
①と同じ手順のGUIのみの操作でse2_job1ジョブを作成
この段階では①とほぼ同じ内容のジョブです
コードは以下になります。
処理内容は"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
以下の部分を修正します。
35行目の"dropnullfields3"の後に以下を追加
df = dropnullfields3.toDF()
partitionby=['year','month','day','hour']
output='s3://test-glue00/se2/out1/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
toDF:DynamicFrameをDataFrameに変換
write:DataFrameのデータを外部に保存。jdbc, parquet, json, orc, text, saveAsTable
parquetのcompression:none, snappy, gzip, and, lzoから選べる
partitionBy:Hiveパーティションのようにカラム=バリュー形式でパーティション化されたディレクトリにデータを保存
mode:ファイルやテーブルが既に存在してる場合の振る舞い。overwrite(出力先のパーティション含めて削除して書き込むという挙動),append,ignore,error(デフォ)
repartition(numPartitions, *cols)[source]:パーティションの再配置、カッコ内はパーティションする単位を数字かカラムで選ぶ、カラムが優先
最後の方のsink処理をコメントアウト
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
修正したコードです
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
### Add(start)
df = dropnullfields3.toDF()
partitionby=['year','month','day','hour']
output='s3://test-glue00/se2/out1/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
# dropnullfields3 = DynamicFrame.fromDF(df, glueContext, "dropnullfields3")
### Add(end)
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
###
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します
出力が指定したyaerやmonthでパーティション分割されている。
コマンドで確認
s3のparquetファイルを確認
ローカルにダウンロードし、parquet-toolsで内容確認
# aws s3 ls s3://test-glue00/se2/out1/year=2017/month=11/day=14/hour=14/
2018-01-03 16:25:49 926 part-00049-b7b7bd75-25ac-4a17-bd01-642bde94a648.snappy.parquet
# aws s3 cp s3://test-glue00/se2/out1/year=2017/month=11/day=14/hour=14/part-00049-b7b7bd75-25ac-4a17-bd01-642bde94a648.snappy.parquet .
download: s3://test-glue00/se2/out1/year=2017/month=11/day=14/hour=14/part-00049-b7b7bd75-25ac-4a17-bd01-642bde94a648.snappy.parquet to ./part-00049-b7b7bd75-25ac-4a17-bd01-642bde94a648.snappy.parquet
# java -jar /root/parquet/parquet-mr/parquet-tools/target/parquet-tools-1.6.0rc7.jar head part-00049-b7b7bd75-25ac-4a17-bd01-642bde94a648.snappy.parquet
deviceid = iphone
uuid = 11123
appid = 9
country = FR
出力データのクローラー作成、実行、Athenaで確認
se2_out1でクローラー作成
GlueのCrawlersをクリックし、"Add crawler"をクリック
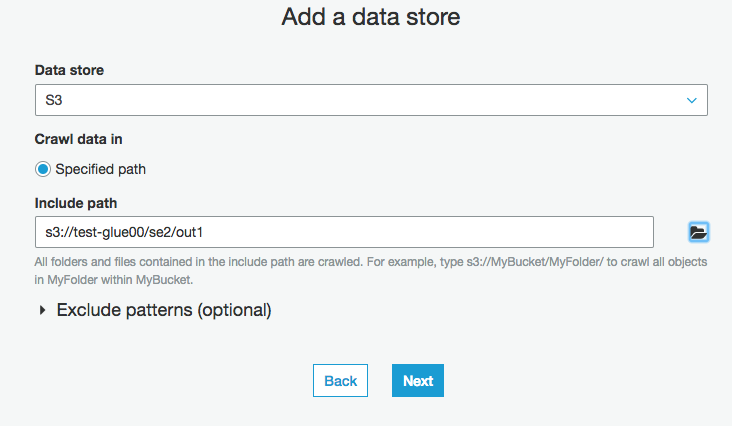
S3の出力パスを入力
そのまま"Next"をクリック
IAM roleに”test-glue"を選択
そのまま"Next"をクリック
Databaseを選択(今回はse2)
Prefixを入力(今回はse2_)
クローラー実行
形式の違うデータが混在しているとテーブルが複数できてしまう

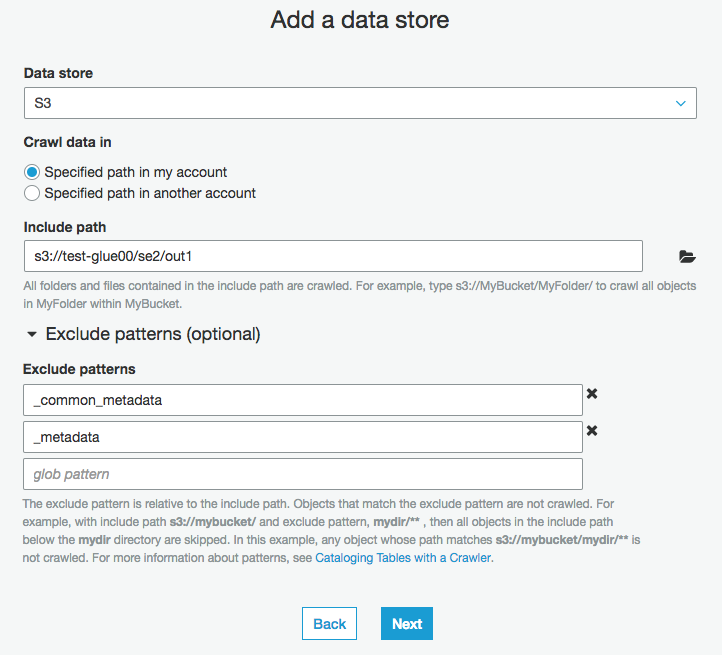
クローラーを作り直し、"Add a data store"の"Exclude patterns"の箇所で
不要なものがあれば除外する。
今回は、_common_metadataと_metadataを除外してる
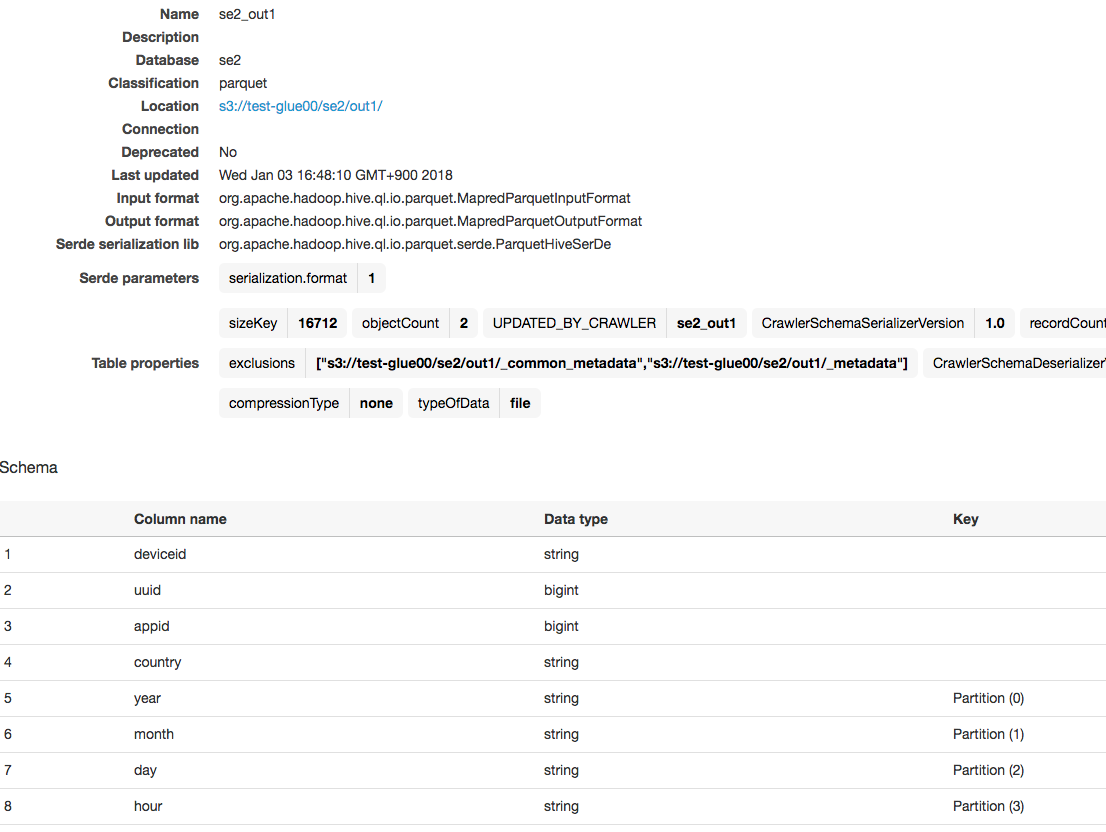
クローラー実行後
1つのテーブルとして認識される

スキーマも、yearやmonthなどで分割したパーティションを認識している
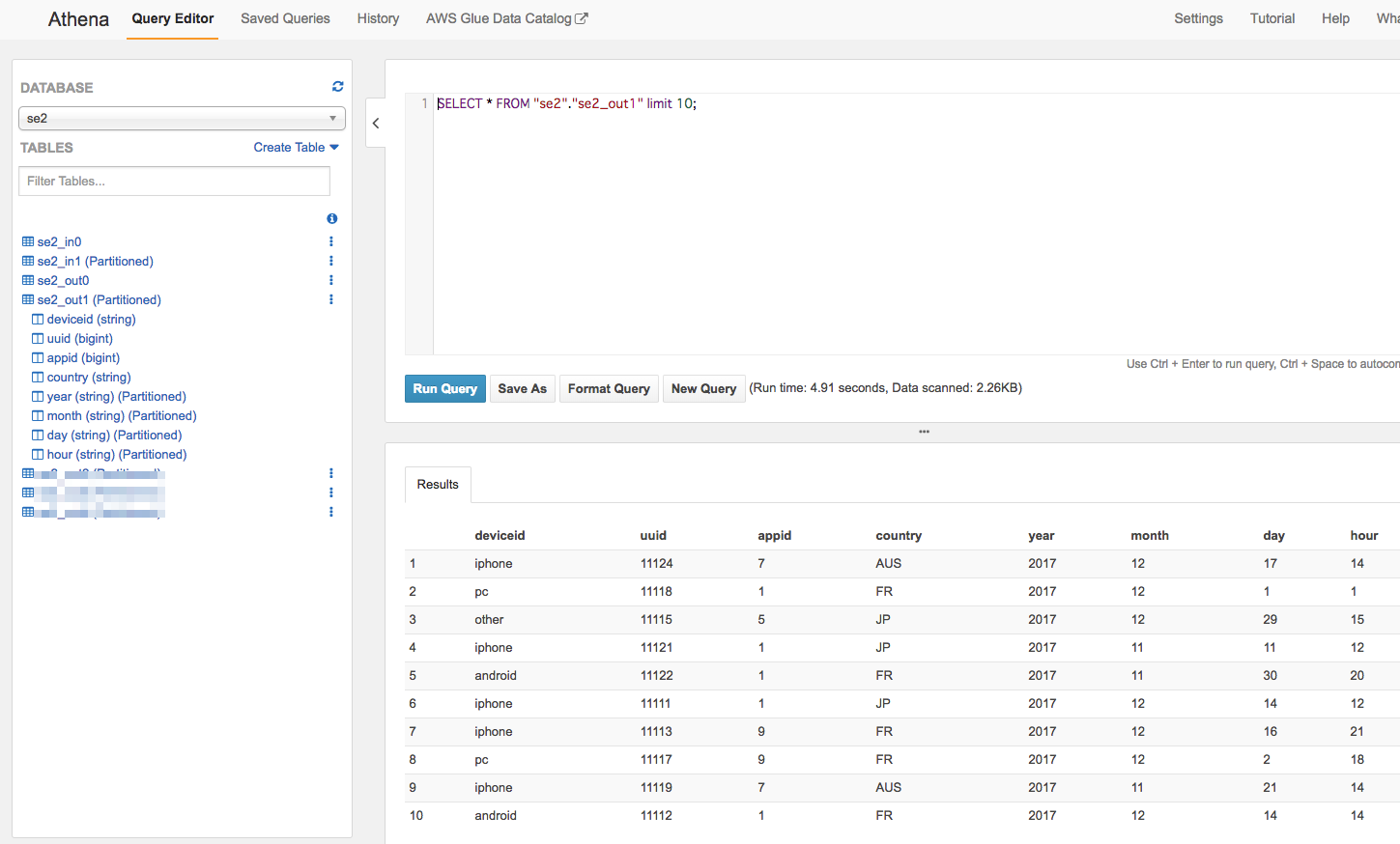
Athenaから確認
左メニューからse2_out1のスキーマ情報確認、クエリ実行
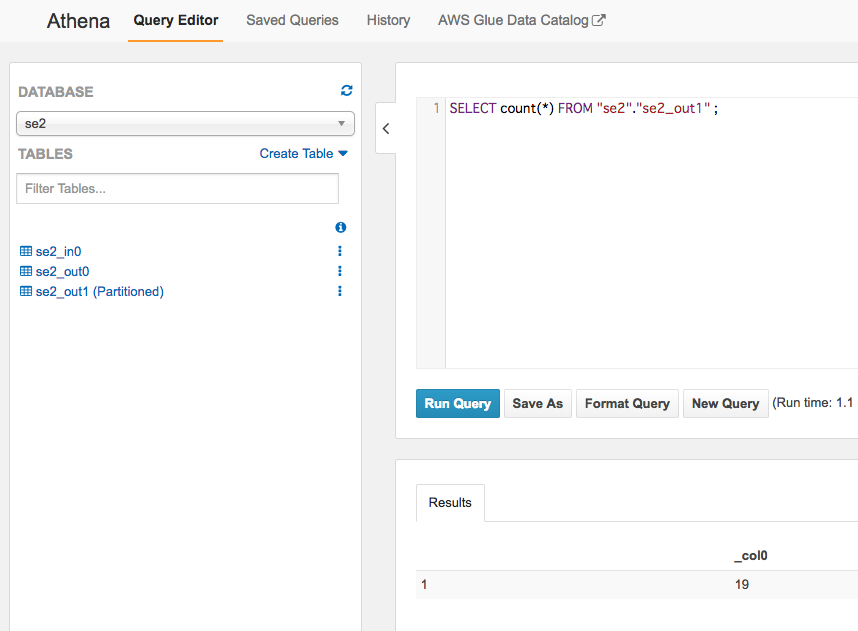
件数も19件で合っている
別のカラムでパーティション切る
タイムスタンプ以外のカラムでももちろんパーティションを切れます。
例えばcountryというカラムがあるので、国ごとに集計をするようなケースが多いならcountryも含めてパーティション分割する
他にもappidとかでアプリごとに集計したり
一時的な調査にも役立つかも
出力に"out2"ディレクトリ作成
①と同様のジョブをse2_job3で作成
作成したジョブのPySparkスクリプトに以下2点修正
35行目の"dropnullfields3"の後に以下を追加
df = dropnullfields3.toDF()
partitionby=['country','year','month','day','hour']
output='s3://test-glue00/se2/out2/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
最後の方のsink処理をコメントアウト
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
ジョブ実行
countryごとにパーティション別れてます
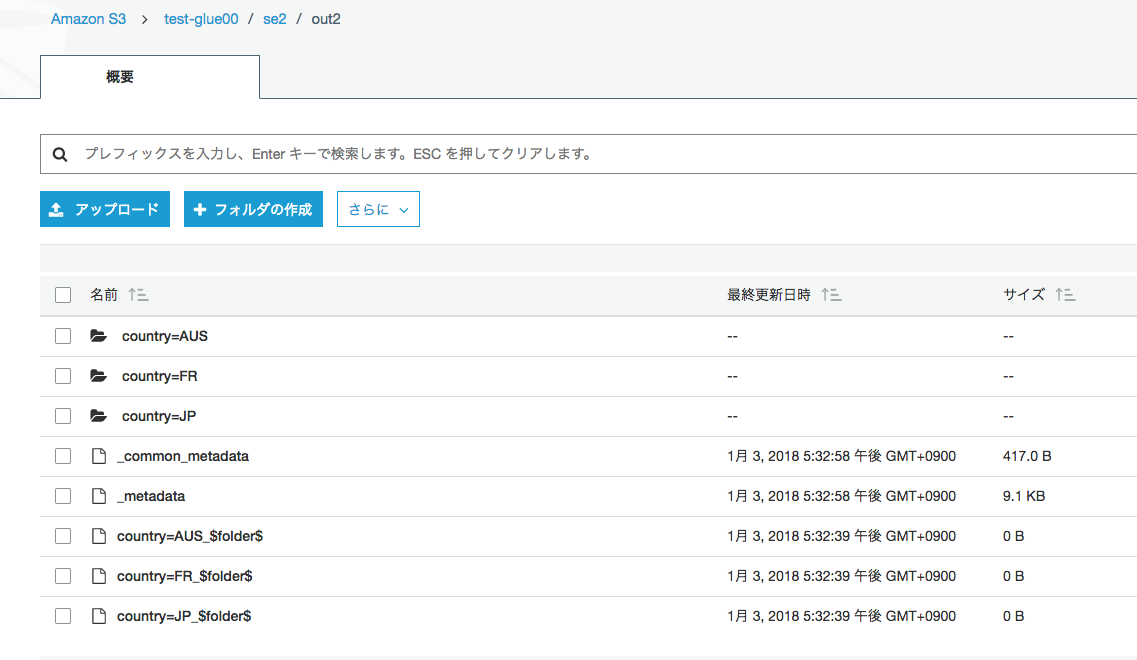
クローラー作成と実行
手順はさっきと同じなので省きます
テーブルが作成され

スキーマはcountryがパーティションに追加されています
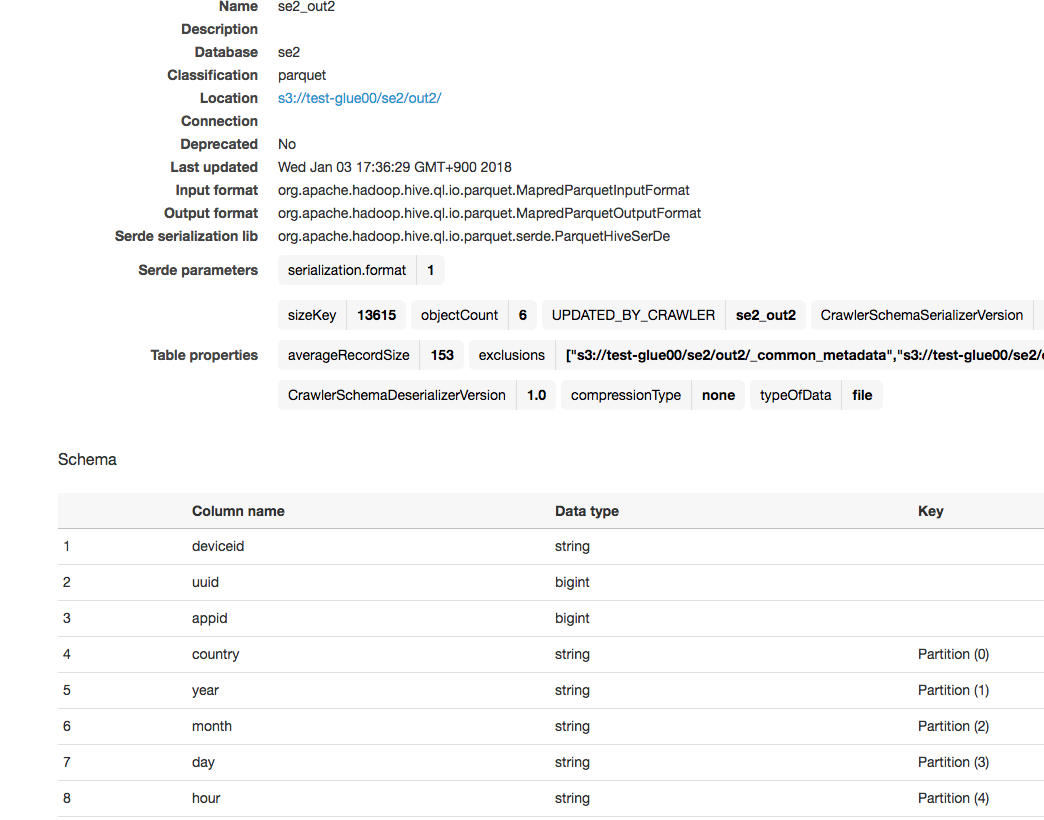
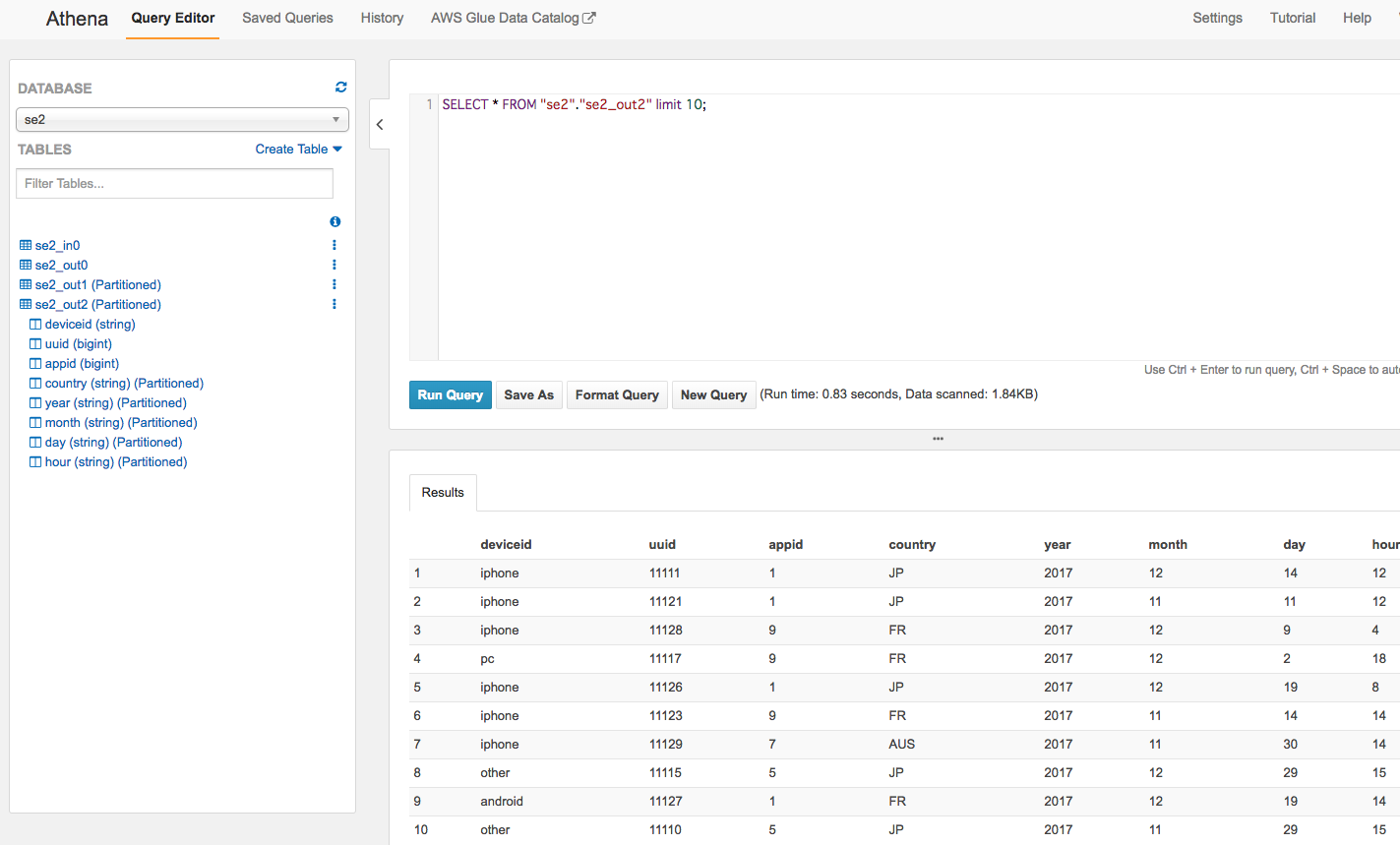
Athenaから確認
左側メニューでスキーマ確認と、クエリ実行
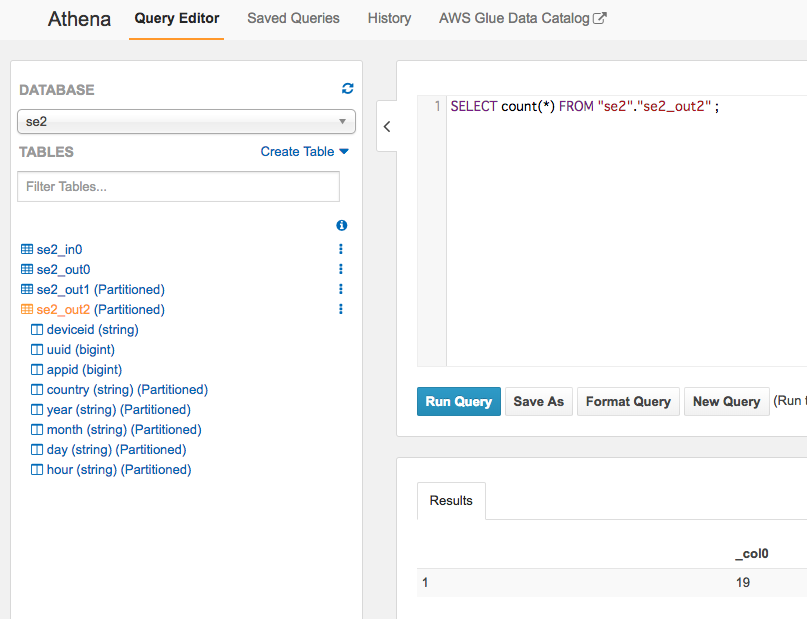
件数も同じく19件
To Be Continue
よくありそうな変換処理ケースを今後書いていければと思います。
こちらも是非
Spark API
https://spark.apache.org/docs/preview/api/python/pyspark.sql.html
https://hackernoon.com/managing-spark-partitions-with-coalesce-and-repartition-4050c57ad5c4
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f