DataFrameでパーティション分割しAVROで出力するジョブを作る
ジョブの内容
DataFrameを使ってAVRO出力するにはdatabricksなどが作ったライブラリが必要です。GlueのDynamicFrameはAVROフォーマットに対応してるのですが、以前partition byが出来なく、AVROフォーマットでパーティション化したい場合はAVROのライブラリ入れてDataFrameで行う必要がありました。今はDynamicFrameで出来るので需要はないかもしれませんがライブラリの使い方としてナレッジ残します
※"Glueの使い方的な②(csvデータをパーティション分割したparquetに変換)"(以後②とだけ書きます)とほぼ同じ処理
"今回は出力をAVRO形式にします"
その際に以下のjarを使う
spark-avro-assembly-4.1.0-SNAPSHOT.jar
※"Glueの使い方的な①(GUIでジョブ実行)"(以後①とだけ書きます)も時々出てきます
ジョブ名
se2_job6
クローラー名
se2_in0
se2_out5
全体の流れ
- 前準備
- ジョブ作成と修正
- ジョブ実行と確認
- 出力データのクローラー作成、実行、Athenaで確認
- Jupyterで同様のスクリプトを実行
※②の後半で作成した"別カラムでパーティションを切る"スクリプトを修正する形で進めます
前準備
jarファイルダウンロード
このあたりからdatabricksのjarをダウンロードし、s3の s3://test-glue00/se2/lib/ にアップロードしておく
ここにあるものをビルドした気がするが忘れてしまった。。
https://github.com/databricks/spark-avro
こちらにある spark-avro_2.11-4.0.0.jar でも動きました
https://spark-packages.org/package/databricks/spark-avro
ソースデータ(19件)
※①と同じデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
入力テーブルのクローラー
※①で作ったものを使います。
ジョブ作成と修正
ジョブ作成の細かい手順は②をご参照ください。以下の部分を修正します。
- 依存jarパス:s3://test-glue00/se2/lib/

処理内容は"S3の指定した場所に配置したcsvデータを、パーティション化し、指定した場所にAVROとして出力する"です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
### add
df = dropnullfields3.toDF()
partitionby=['country','year','month','day','hour']
output='s3://test-glue00/se2/out5/'
codec='snappy'
# df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").format('com.databricks.spark.avro').save(output,compression=codec)
### add
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out2"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out5"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
以下の部分を修正します。
formatを'com.databricks.spark.avro'としています
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").format('com.databricks.spark.avro').save(output,compression=codec)
ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します
出力が指定したcountryやyaerやmonthでパーティション分割されている。

ファイルもAVROとして出力されている
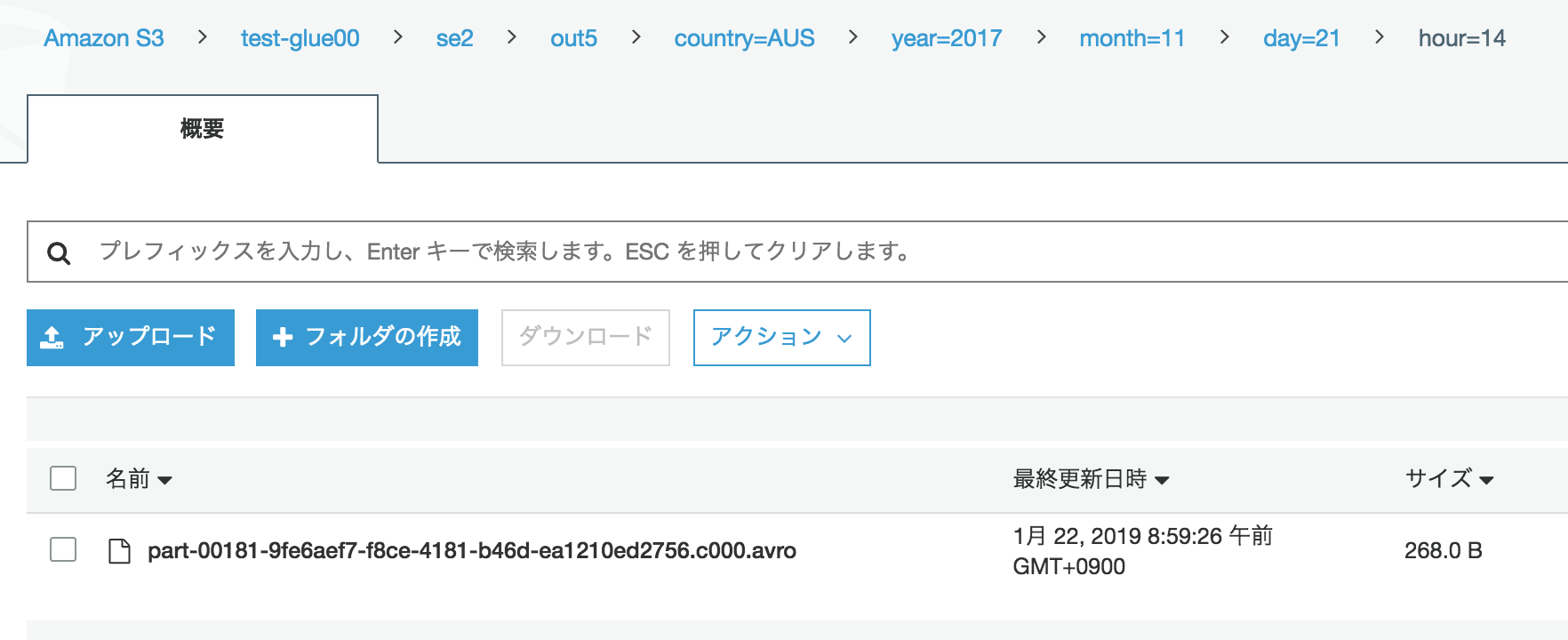
出力データのクローラー作成、実行、Athenaで確認
se2_out5でクローラー作成
以下を設定しクローラーを作成(詳細は②を確認)
- IAMロール:test-glue
- S3パス:s3://test-glue00/se2/out5
- Databaseを選択(今回はse2)
- Prefixを入力(今回はse2_)
クローラー実行
AVROとして分類されたテーブルが作られている

スキーマも、countryやyearやmonthなどで分割したパーティションを認識している

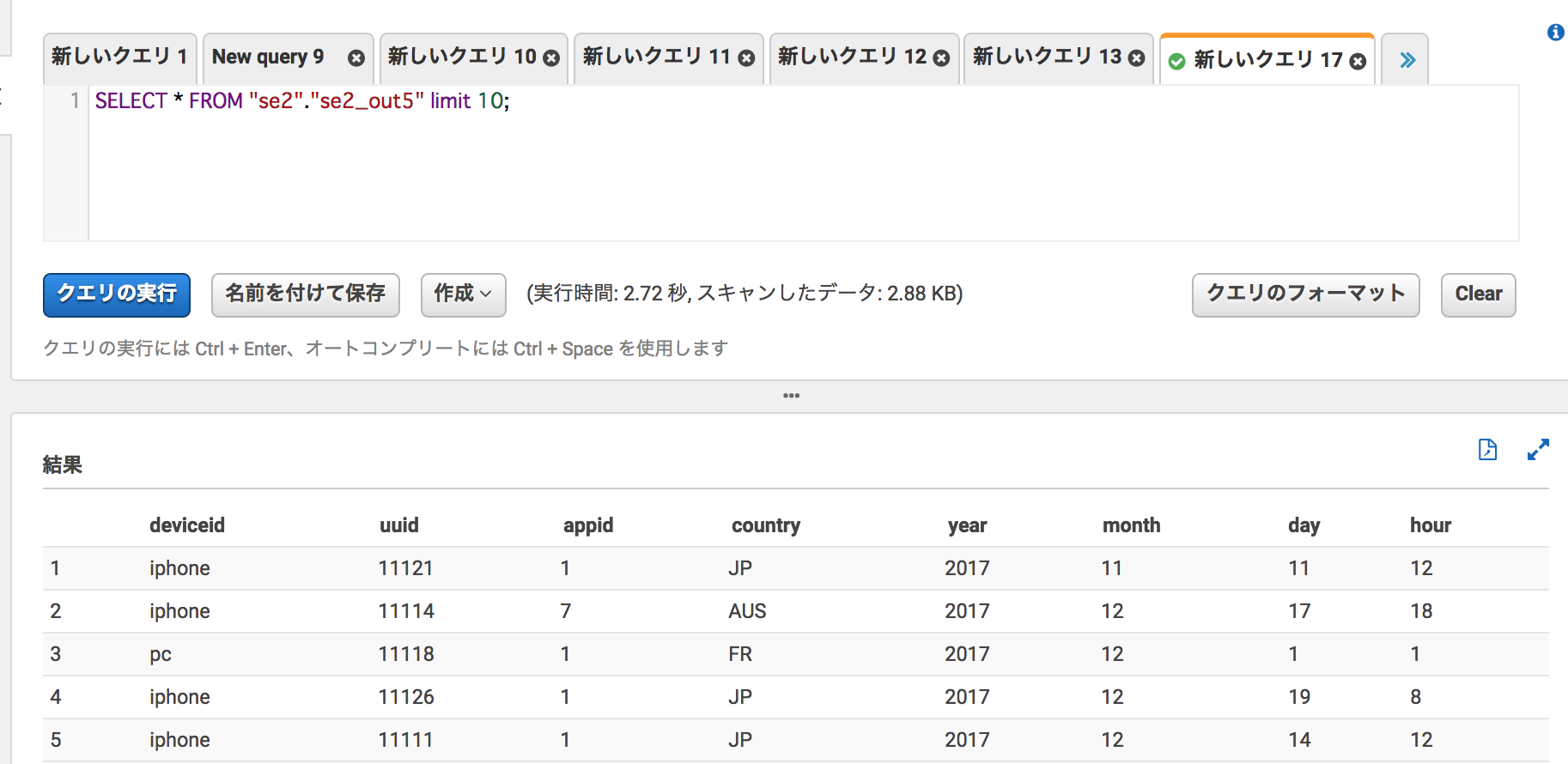
Athenaから確認
左メニューからse2_out5のクエリ実行
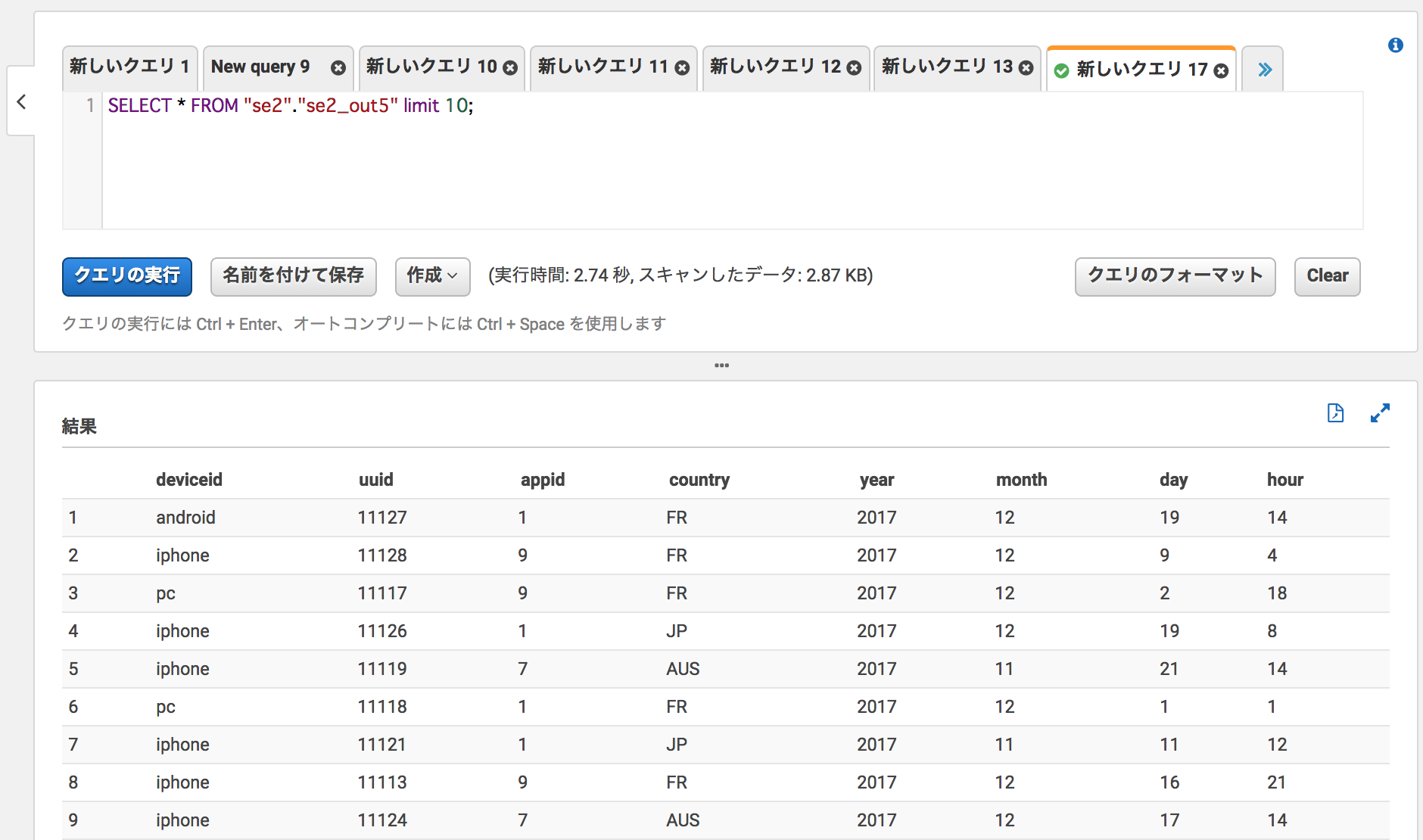
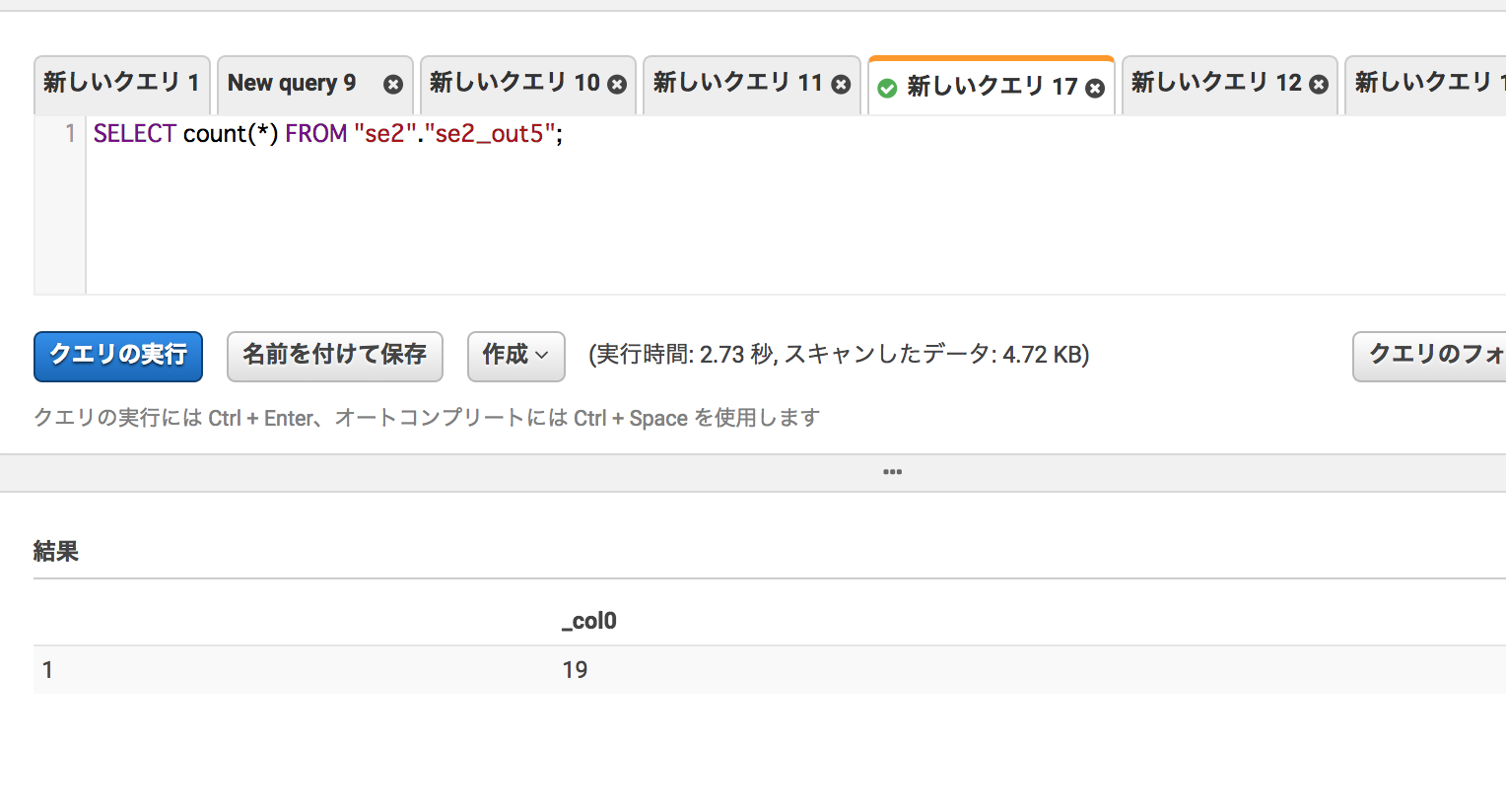
件数も19件で合っている
Jupyterで同様のスクリプト実行を行う
開発エンドポイント作成
Glueのメニューから、"開発エンドポイント"->[エンドポイントの追加]をクリック

以下を入力し、[次へ]->[次へ]->[作成]をクリックし、ステータスが"READY"になるまで数分待つ
- 開発エンドポイント名:se2_endpointo6
- 依存jarパス:s3://test-glue00/se2/lib/spark-avro-assembly-4.1.0-SNAPSHOT.jar

作成された開発エンドポイント"se2_endopoint6"にチェックを入れ、アクション->"Create SageMaker notebook"をクリック
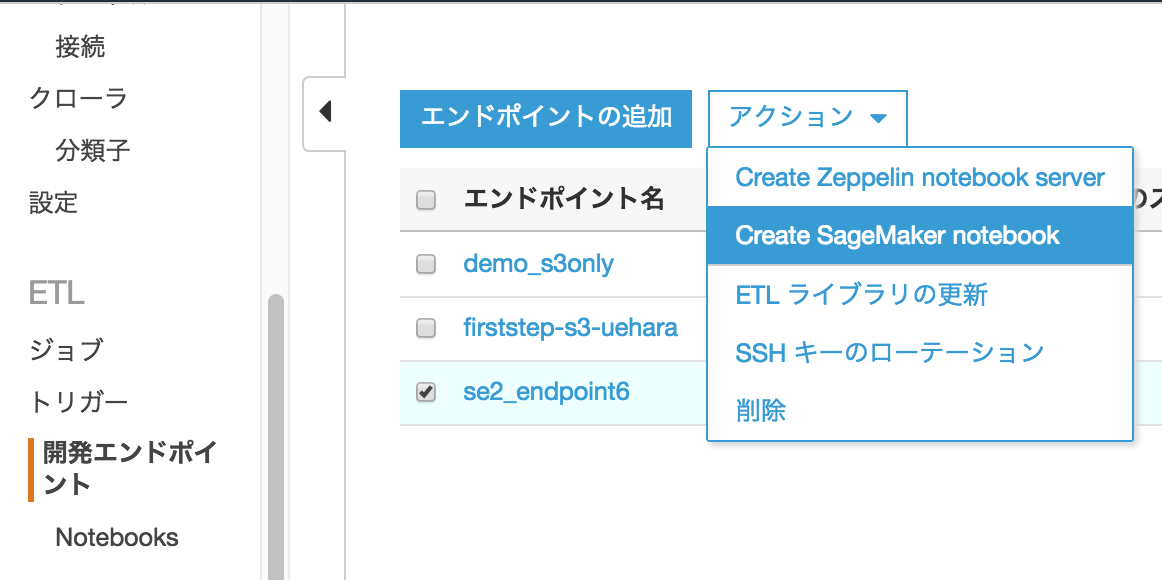
以下を入力し下のほうにある[ノートブックの作成]をクリック
- Notebook name:se2-notebook6
- Attach to development endpoint:se2_endpoint6
- 既存のIAMロールを選択する:チェック
- IAMロール:AWSGlueServiceSageMakerNotebookRole-test
※IAMロール"AWSGlueServiceSageMakerNotebookRole-test"の内容はこちらのリンクを確認ください
https://qiita.com/pioho07/items/29bd779f84b4add9cf2c
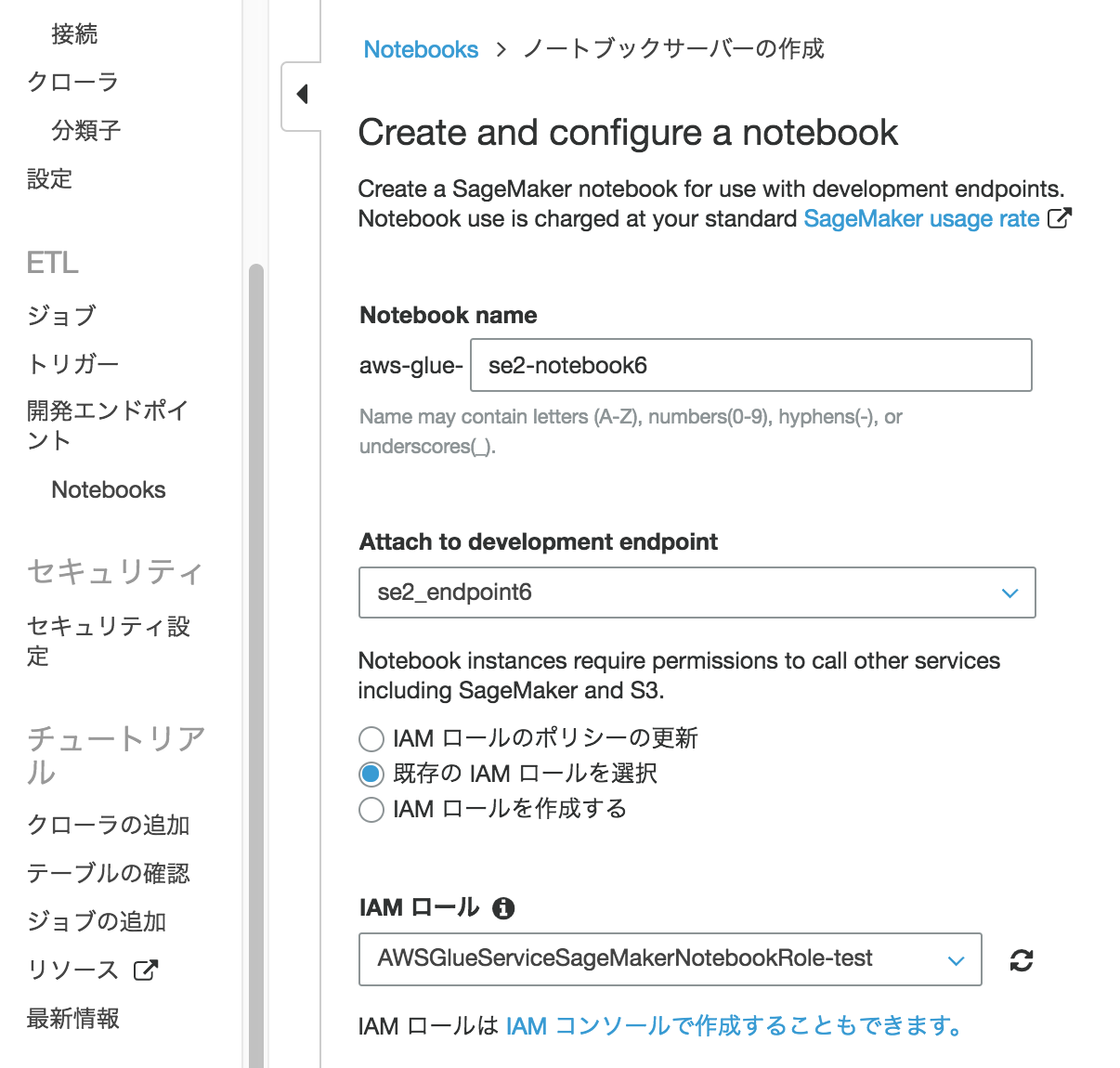
作成されたノートブック"aws-glue-se2-notebook6"にチェックを入れ、[Open notebook]をクリック

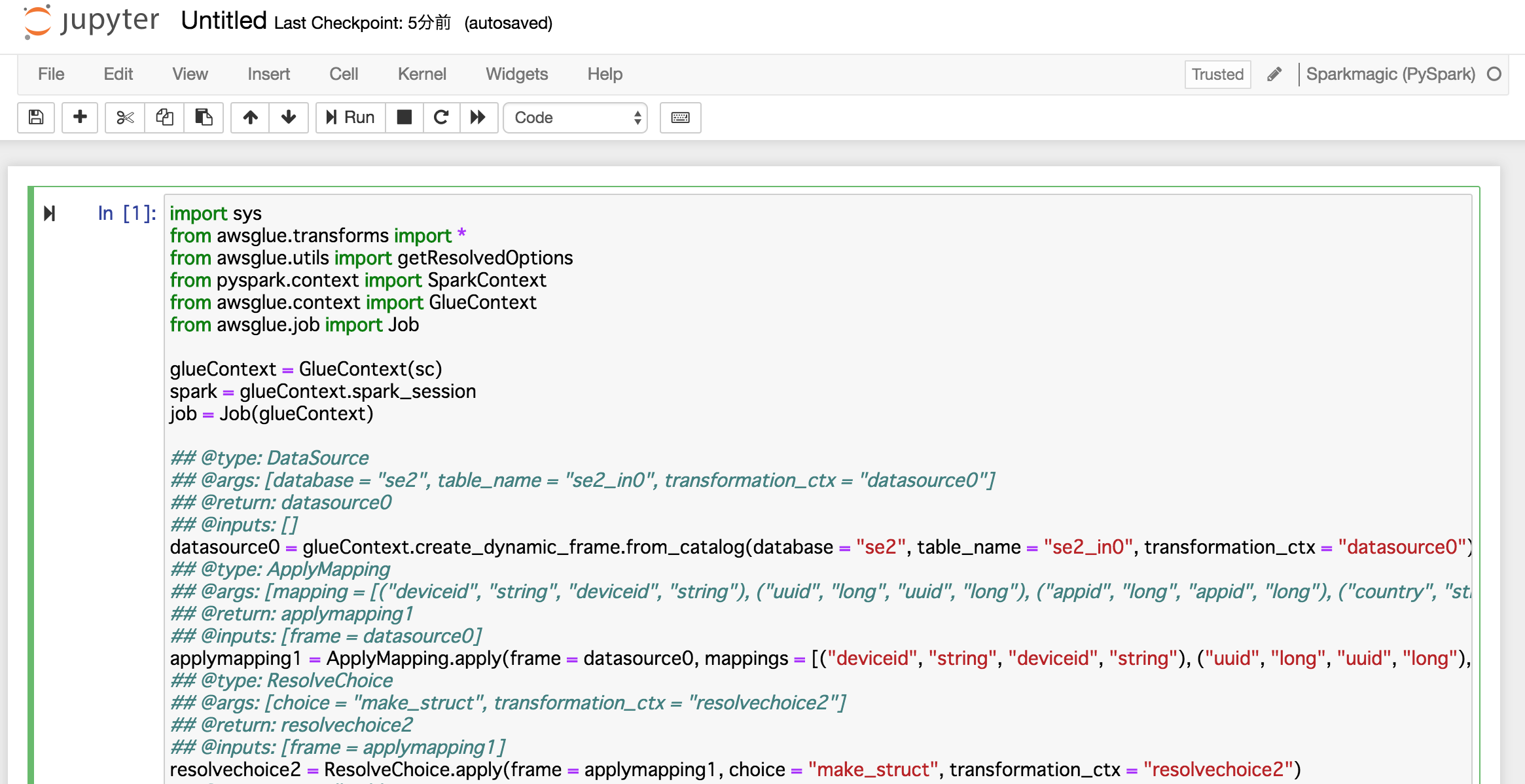
[New]->"PySpark"をクリック

ほぼ同じ内容のスクリプトを貼り付ける
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
### add
df = dropnullfields3.toDF()
partitionby=['country','year','month','day','hour']
output='s3://test-glue00/se2/out5/'
codec='snappy'
# df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
df.repartition(*partitionby).write.partitionBy(partitionby).mode("overwrite").format('com.databricks.spark.avro').save(output,compression=codec)
### add
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out2"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out5"}, format = "parquet", transformation_ctx = "datasink4")
Jupyter notebookに貼り付けたら"shift + enter"で実行
S3に出力される

Athenaでも同様の確認ができる
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f