(この記事は「Elixir Advent Calendar 2018」の23日目です)
fukuoka.ex代表のpiacereです
ご覧いただいて、ありがとうございます ![]()
fukuoka.ex#11で、αバージョンを初お披露目した「Esuna」は、「データ前処理」「機械学習(ディープラーニング)モデル構築/呼出」「ビジュアライゼーション」を搭載した、データサイエンスプラットフォームです
どの機能も、WebUIで操作でき、誰にでも使えることが特徴です
Elixir/Phoenix+Vue.js+Chart.jsで開発しています
モデル構築としては、Kerasのコードを生成することが可能です
今回、このEsunaの「前処理」と「機械学習」の機能を使い、「Kaggle」のチュートリアル的なコンペである「Titanic: Machine Learning from Disaster」、つまり「タイタニック号乗客の生存予測(以降、タイタニック予測と省略)」を解いていく過程を解説したいと思います
なお、「Phoenix」は、ElixirのWebフレームワークです
はじめに
このコラムは、以下の三部構成になっており、うち「第一部:データに前処理を施す」を本コラムで解説、第二部以降は、後編の別コラムで解説します
第一部:データに前処理を施す
第二部:機械学習(Keras)モデル構築とテスト
第三部:テスト結果をKaggleに提出する
後編は、以下になります
|> Elixir+KerasでKaggleタイタニック予測を解いてみた②
~データサイエンスプラットフォーム「Esuna」はUIでAI・MLを生成~
第一部:前処理
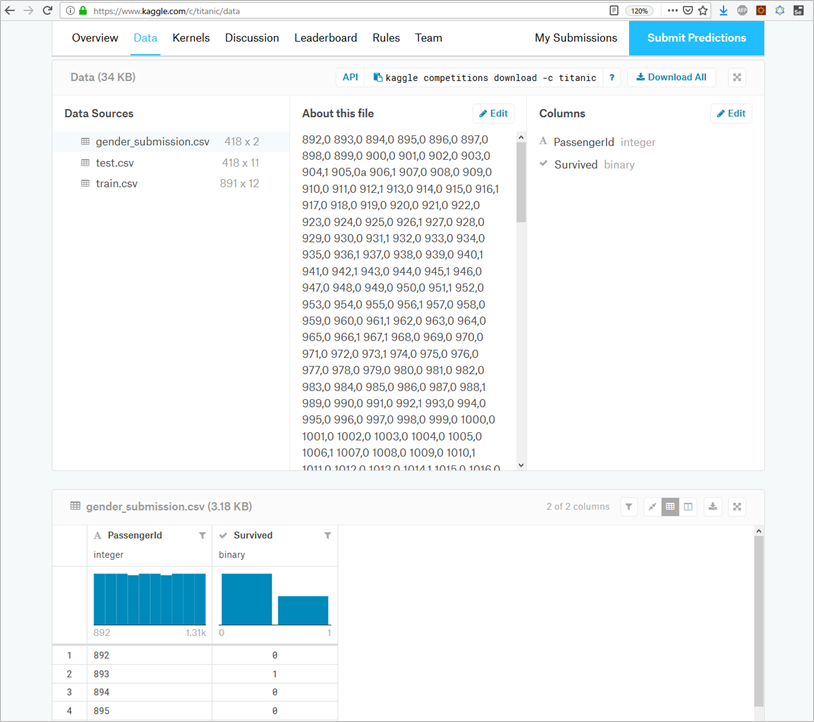
前処理対象のCSVファイルをKaggleからダウンロード
今回は、Kaggleの「Titanic: Machine Learning from Disaster」からダウンロードする2つのCSV(train.csv、test.csv)が対象データとなりますので、手元にダウンロードします
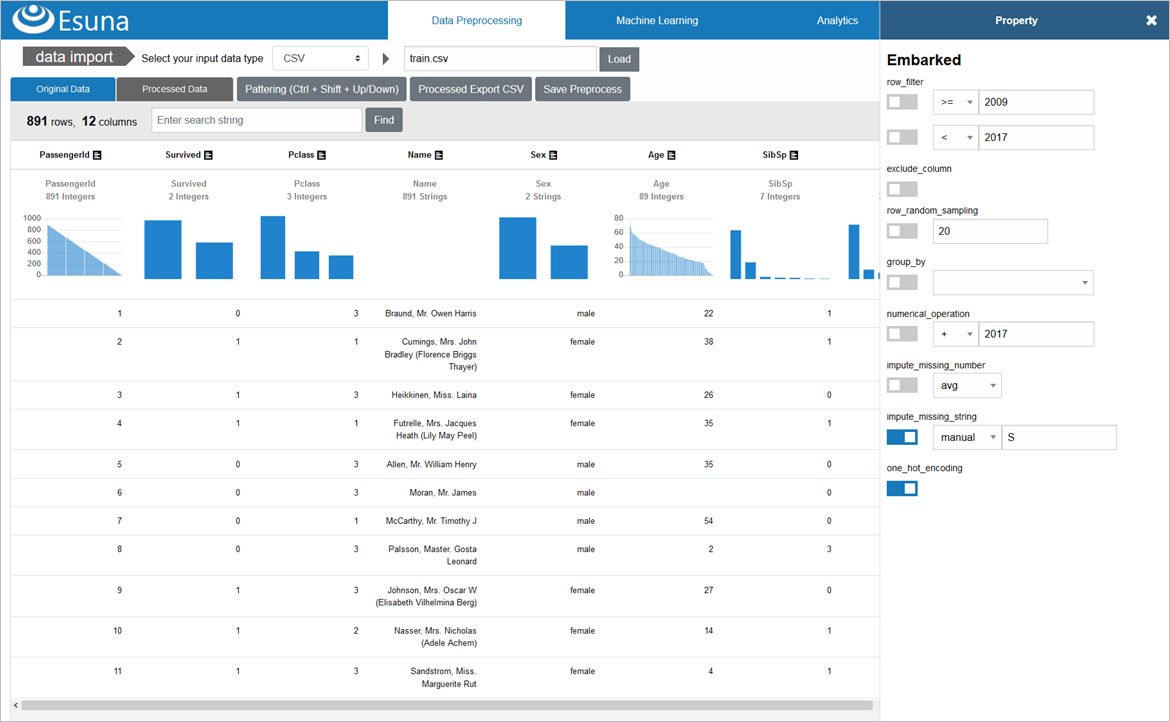
「Data Processing」メニューからCSVをインポート
Esunaは、画面上部の「Data Preprocessing」メニューをクリックすると出てくる画面で、前処理を設定していきますが、最初にやることは、画面上部の「data import」からデータをインポートすることです
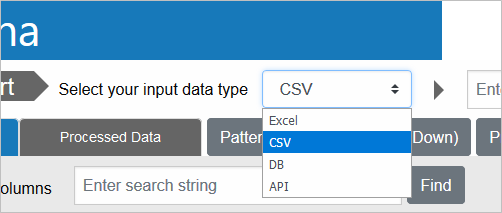
Excel/CSV/DB/APIといった、様々なデータタイプが指定できますが、今回は「CSV」を選択した後、「Load」ボタンをクリックして、先ほど入手したtrain.csvを選択します
選択したファイルが、Esuna側にアップロードされ、画面にCSV内容が表示されます
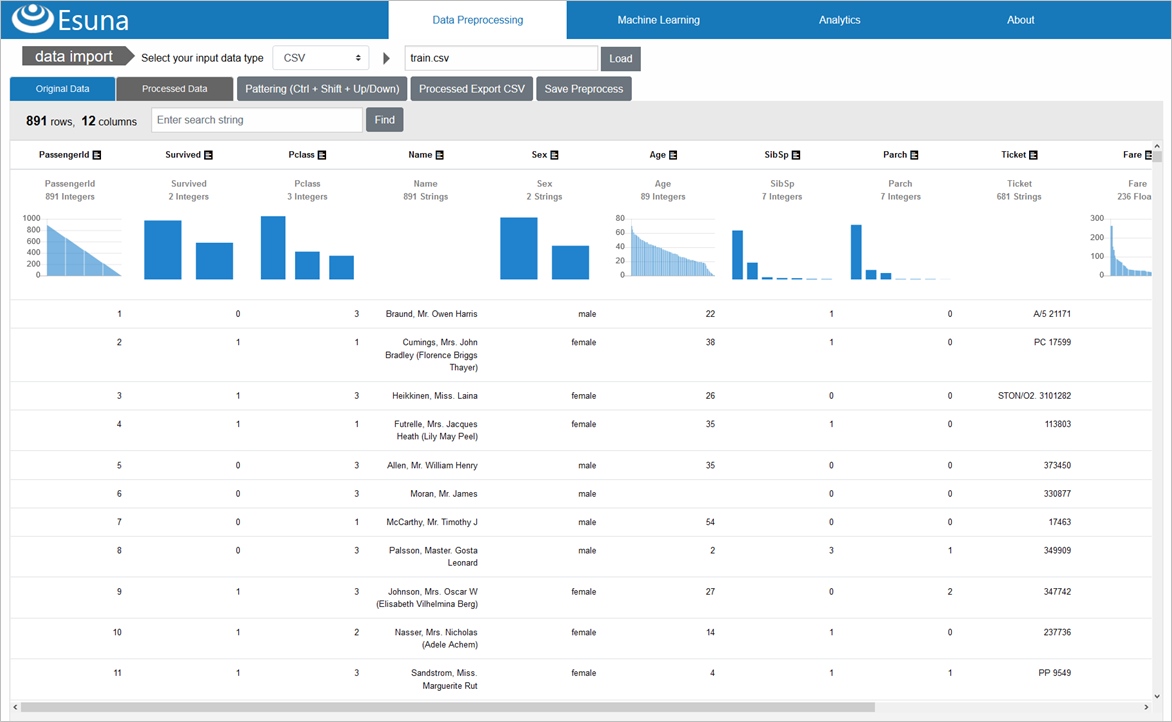
CSVデータが読み込まれた上部には、データの統計情報(型、バリエーション数、分布グラフ)が表示されるので、どんなデータ傾向かは、一目で分かります
たとえば、乗客の階級を示す「Pclass」は、3種類の整数で構成されていることがEsunaで自動判別されていて、実際にデータを見ると、1(金持ち上層クラス)~3(労働階級下層クラス)の整数のみ存在するデータであることが確認できます
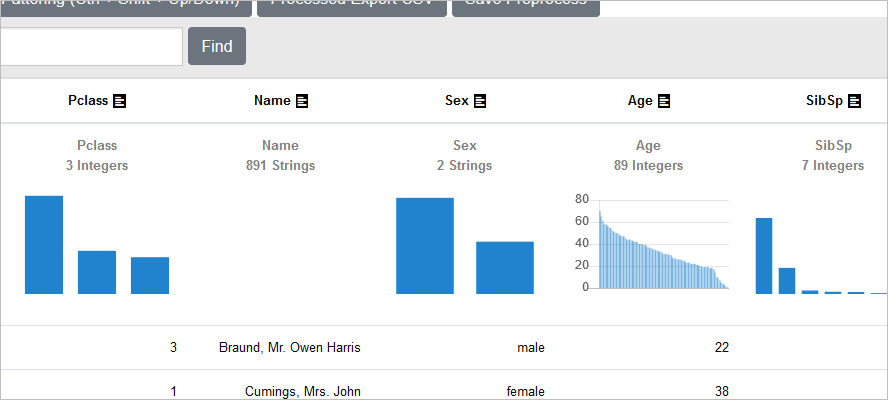
前処理①:特徴量にならない情報(列)を削除
前処理の基本は、まず、「特徴量(≒列のこと)となり得ない情報を削除」することが、最も肝心です
AI・MLのリテラシーがあまり無いと、あるあるなネタですが、「データが沢山あれば、望んだ予測ができるだろう」という誤っているけど、何故か盲信されている「幻想」があります
実際は、予測に貢献する特徴量は、ごく限られていることが多く、PCA(主成分分析)やImpurity(不純度)、NMF(非負値行列因子分解)で見ていくと、支配的な特徴量と、そうでないものの差が大きく出ます
ひらたく言えば、「大半の予測は、重要度の高い少量のデータだけで決められる」ということであり、そのためには、あまり貢献しない特徴量を削減(≒次元削減と言います)することが非常に大事です(データが減れば、学習や予測にかかる計算負荷も下がるので、一石二鳥です)
さて、タイタニック予測においては、以下の列が、各理由から削減対象と捉えます
- チケット番号「Ticket」
- チケット番号そのものは、生存率に直接関与しないため
- 近い番号の方が、生存率の高い/低い部屋番号にまとまって配置された可能性は考えられるが、仮説の域を出ないので、いったん削除
- 乗客名「Name」
- 乗客名は、全員が異なるため、特徴量になり得ない
- 名字が同じで、チケット番号が近い or 部屋が近い等であれば、家族乗船の可能性があり、家族全員がボートに乗れるまで待ったとき生存率が低くなる、といった仮説は考えられるが、トリッキーな処理が必要なため、他の手段を先に試す
- 部屋番号「Cabin」
- 部屋番号は、生存率にとても高い相関性を持っているはずですが、Cabinは891件中、687件と大量のデータが欠損しているため、使い物にならないと判断し、削除
なお、訓練データ/テストデータのどちらにも存在する、乗客をユニークに識別するID「PassengerId」は、特徴量としては不要ですが、予測データには必要なため、前処理段階では削除しません
また、訓練データのみに存在する、生存/死亡を表す正解データ「Survived」についても、特徴量としては不要ですが、モデル構築の際に使うため、前処理段階では削除しません
それでは、Esunaで、この3列の削除を行います
「Ticket」の見出しをクリックすると、前処理用のプロパティウインドウが開きます
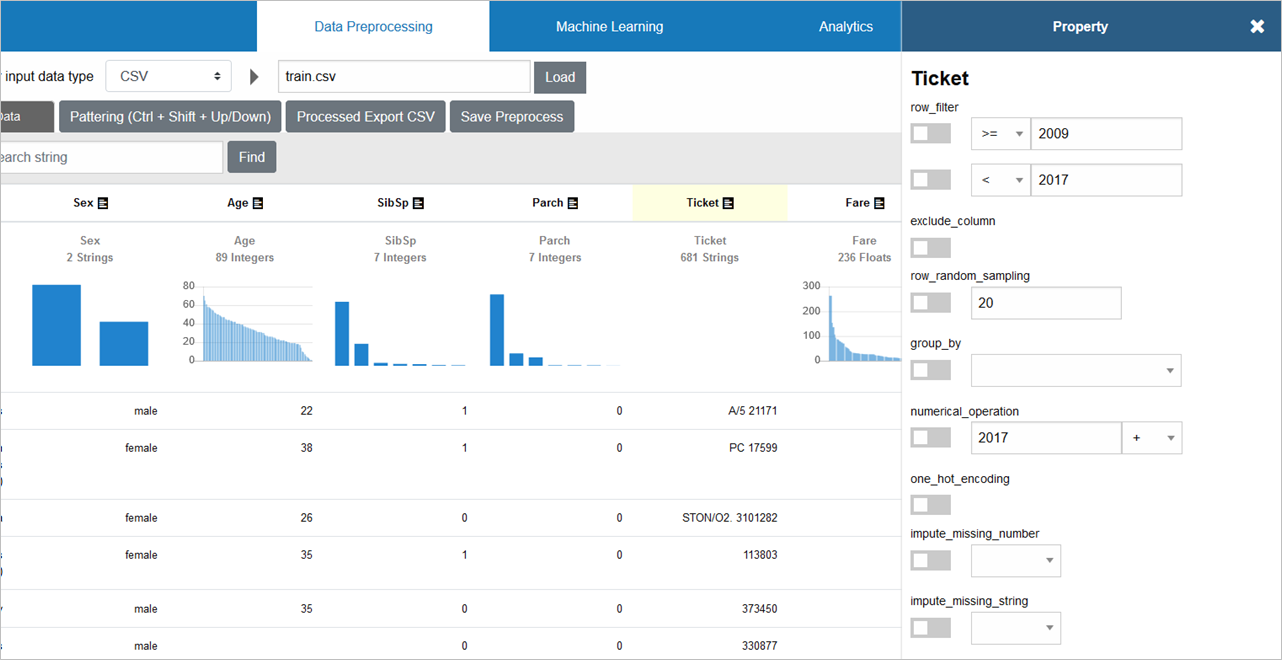
列削除するには、「exclude_column」にチェックを入れます
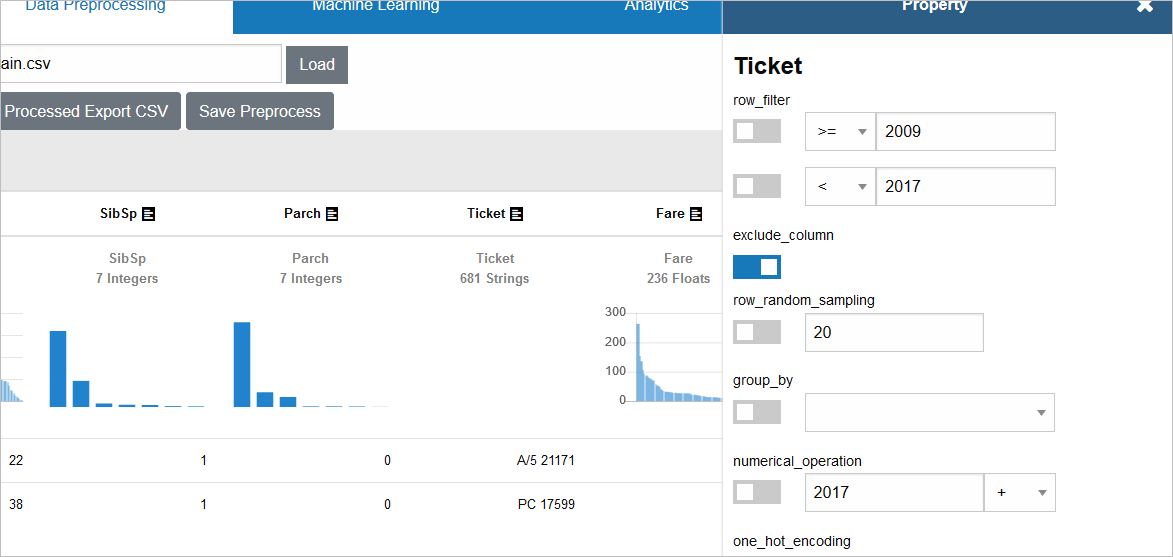
同じ要領で、「Name」「Cabin」の「exclude_column」にもチェックを入れていきます
画面上部少し下にある「Processed Data」タブをクリックすると、3列が削除されていることを確認できます
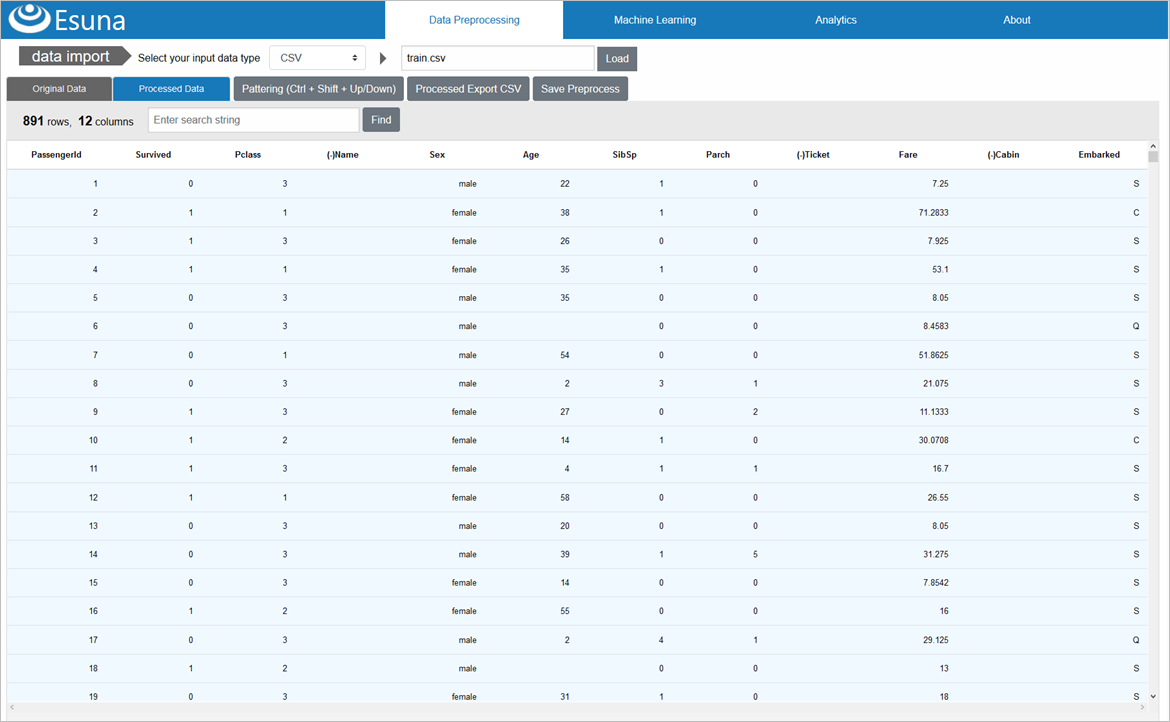
前処理②:欠損値を補完
次は、少量の欠損値(≒空欄の値)がある以下2列の欠損値補完を行います
- 年齢「Age」
- 空欄は、空欄以外の平均値で補完することとします
- 今回のデータでは、891件中、177件と20%近くを占めるため、平均値に偏ることが予想されます
- 欠損がある行自体を削除した方が良いかも知れませんが、いったん補完することとします
- 乗船した港「Embarked」
- S=Southampton(サウサンプトン):イギリス南部の都市
- Q=Queenstown(クィーンズタウン):ニュージーランド南西部の町
- C=(シェルブール・オクトヴィル):フランス北西部の都市
- この3つのうち、最も多い「S」で補完します(対象データ2件なので影響は極小)
それでは、補完していきましょう
Ageの補完には、数値補完を行う「impute_missing_number」を使い、欠損していない全員の年齢の平均値(avg)での補完を設定します
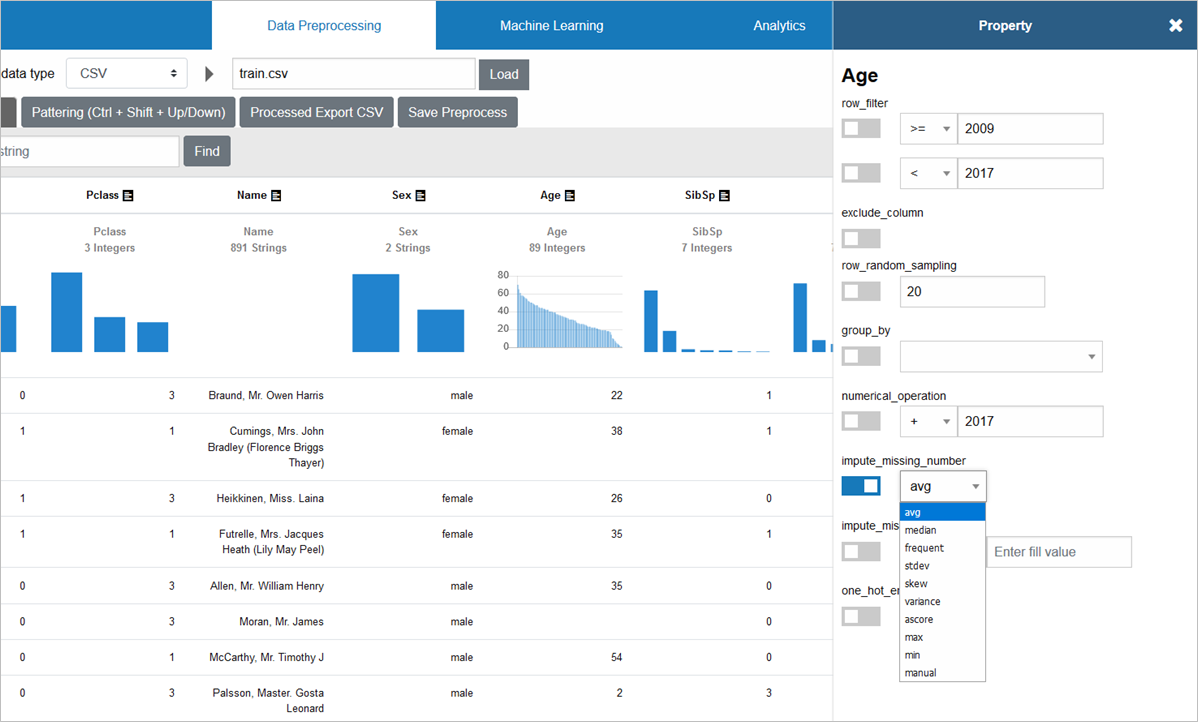
Ageが、平均値29.7歳で補完されていることが確認できます
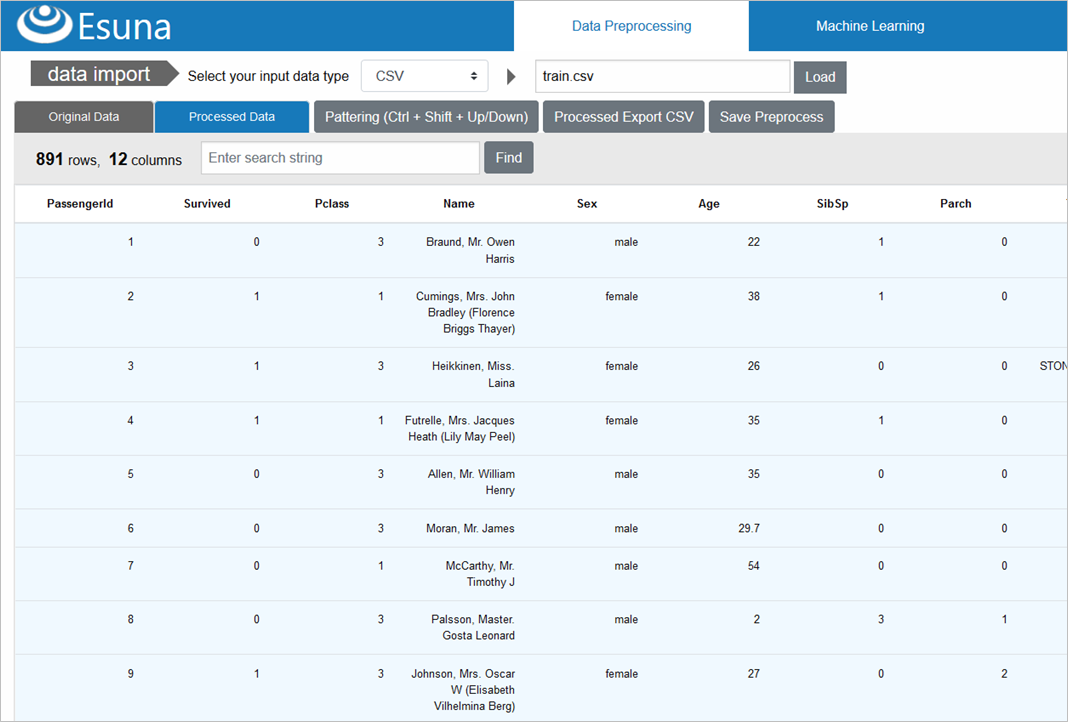
Embarkedの補完には、文字列補完を行う「impute_missing_string」を使い、手入力で「S」での補完を設定します
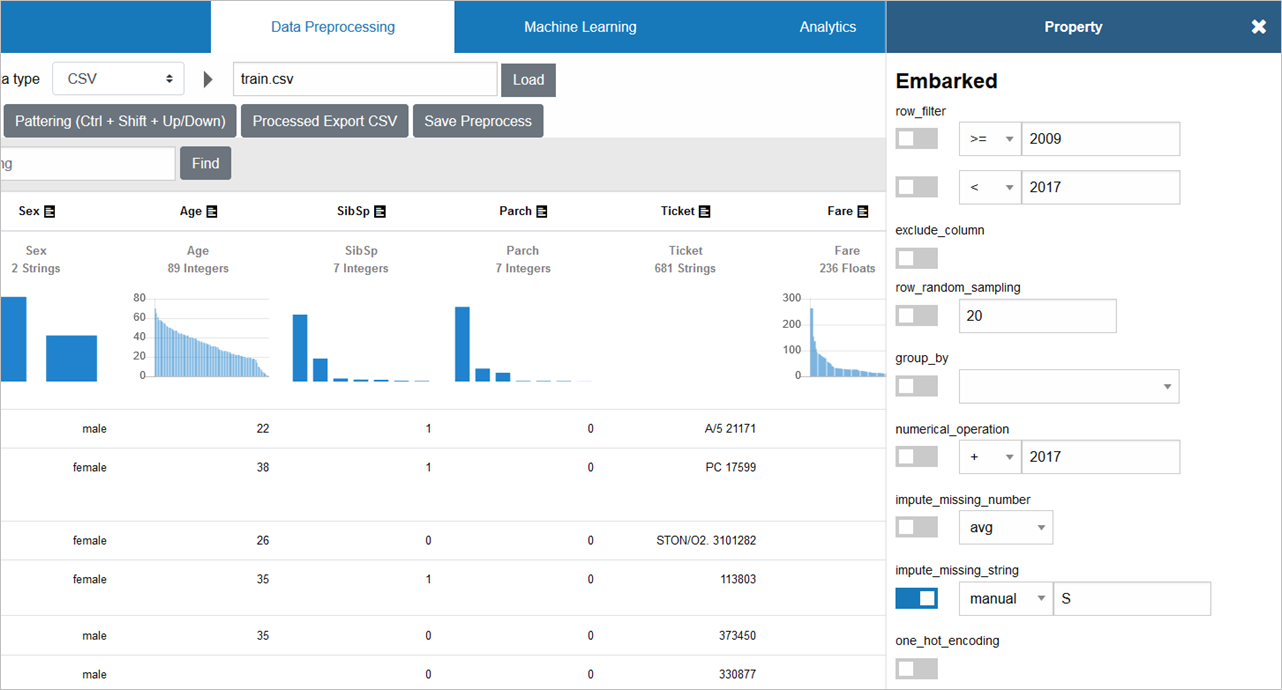
PassengerId=62等のEmbarkedは、「S」で補完されたことが確認できます
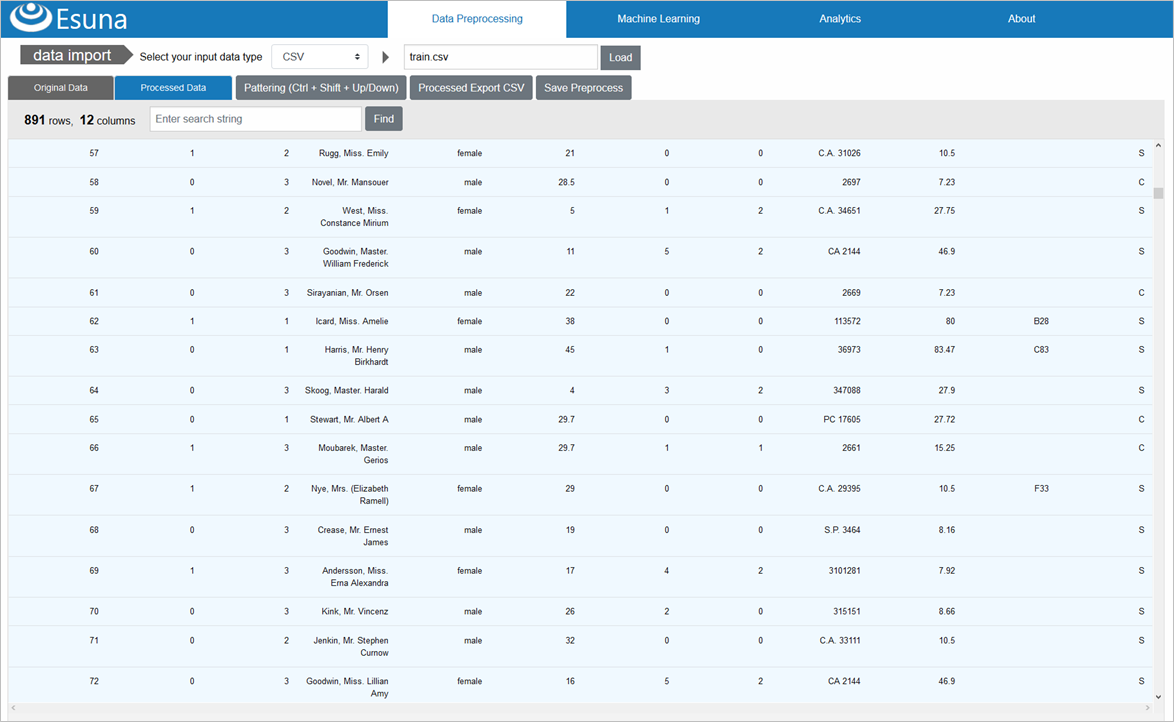
前処理③:カテゴリ値を数値に変換
機械学習/ディープラーニングに入力するデータは、基本的に、数値以外は受け付けないため、以下のような、幾つかの文字列バリエーション、つまり「カテゴリ値」で表される列は、数値への変換が必要です
- 性別「Sex」
- 乗船した港「Embarked」
カテゴリ値の数値変換には、「one_hot_encoding」を使います
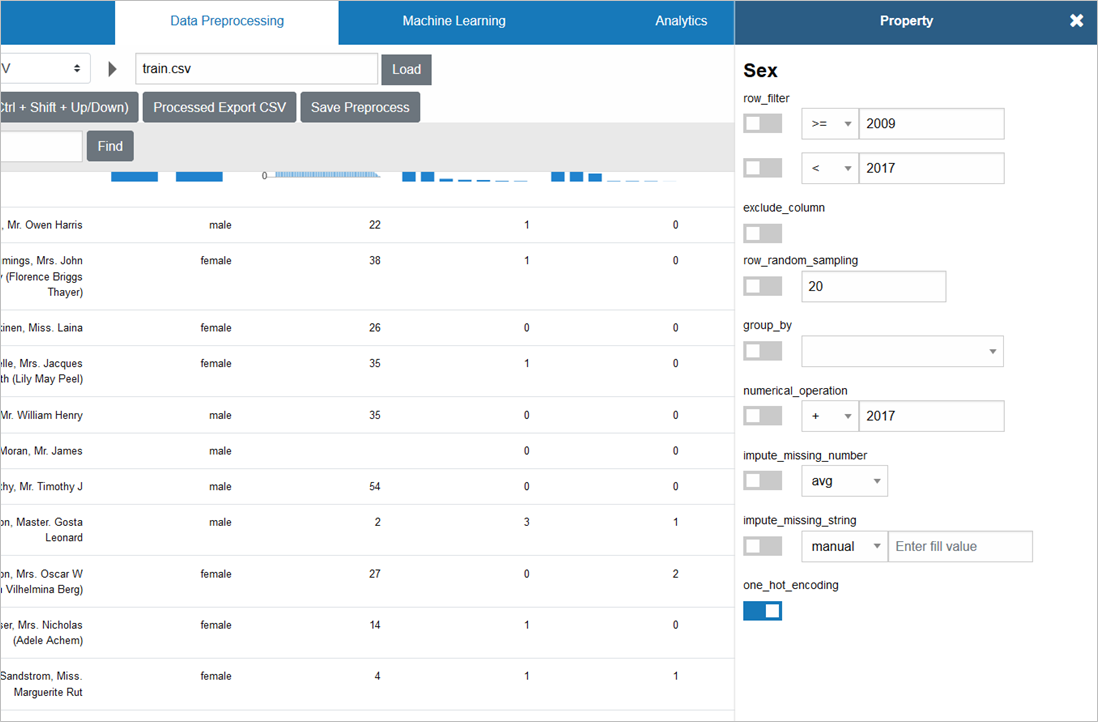
「male」「female」の2つのカテゴリ値だった「Sex」は、この変換により、「0」「1」という数値に変わります
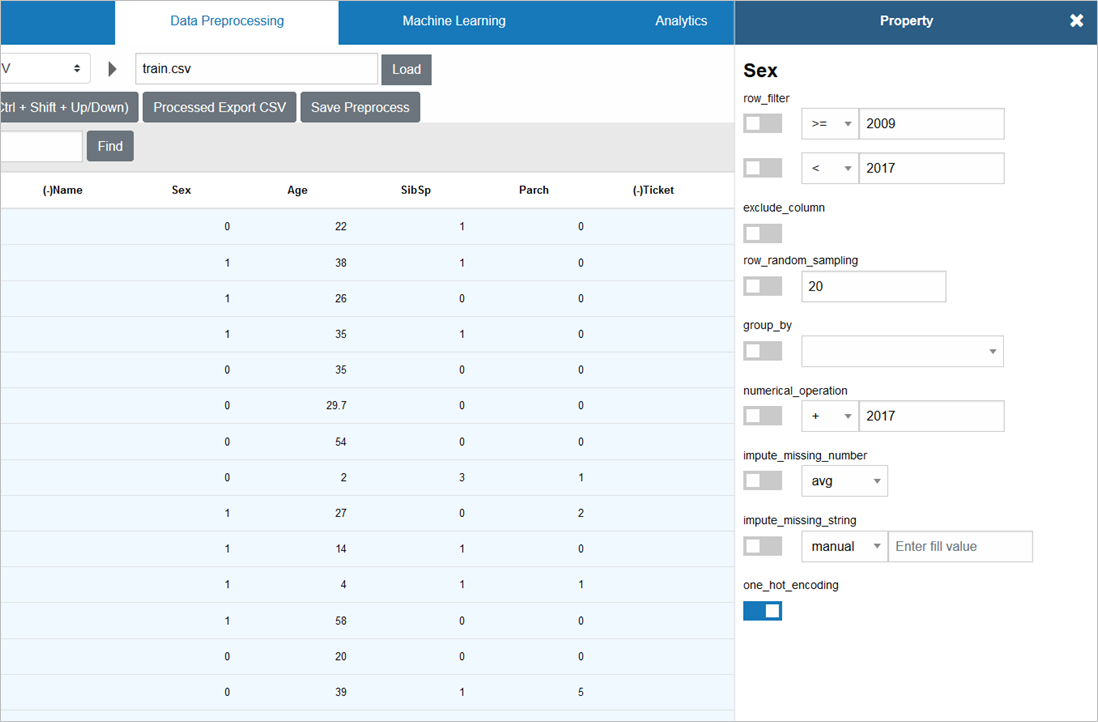
Embarkedも同様に、「one_hot_encoding」します
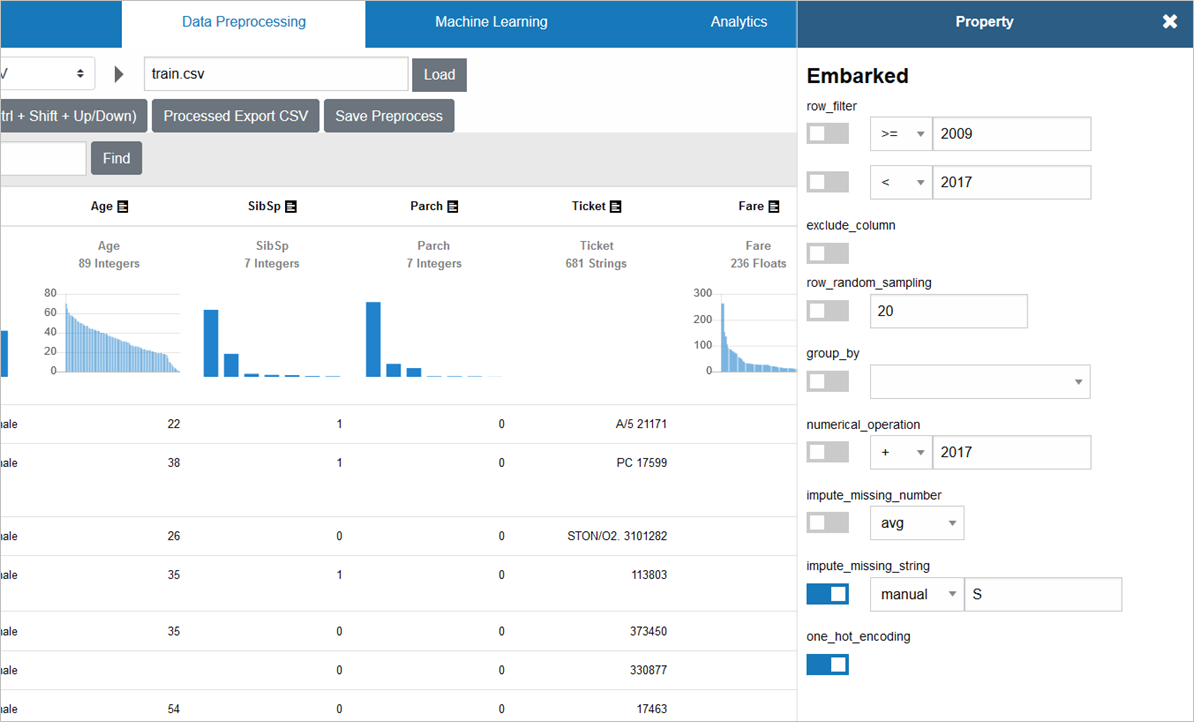
「S」「C」「Q」が、「0」「1」「2」へと変換されました
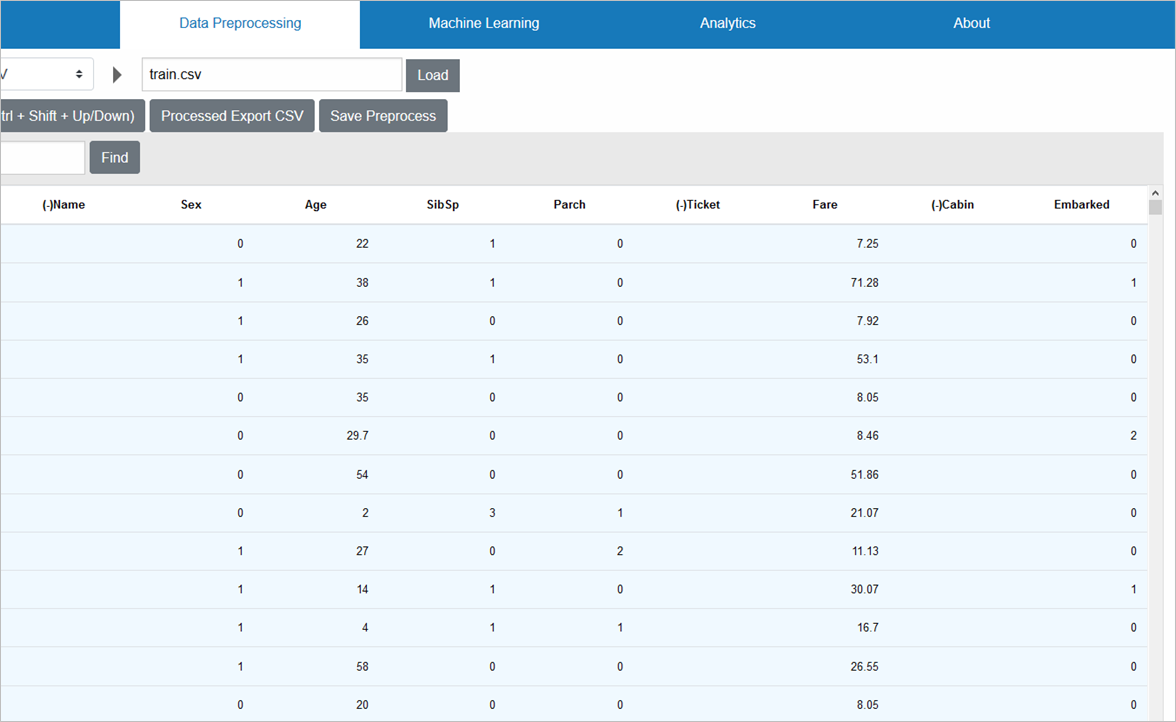
前処理済みデータのCSVエクスポート
ここまでの操作で、特徴量になり得ない3列が削除され、残り9列についても、欠損値が無くなり、数値のみのデータとなったので、前処理済みの訓練データとして、CSVエクスポートします
「Processed Export CSV」をクリックすると、train_processed.csvというファイルが作成されます
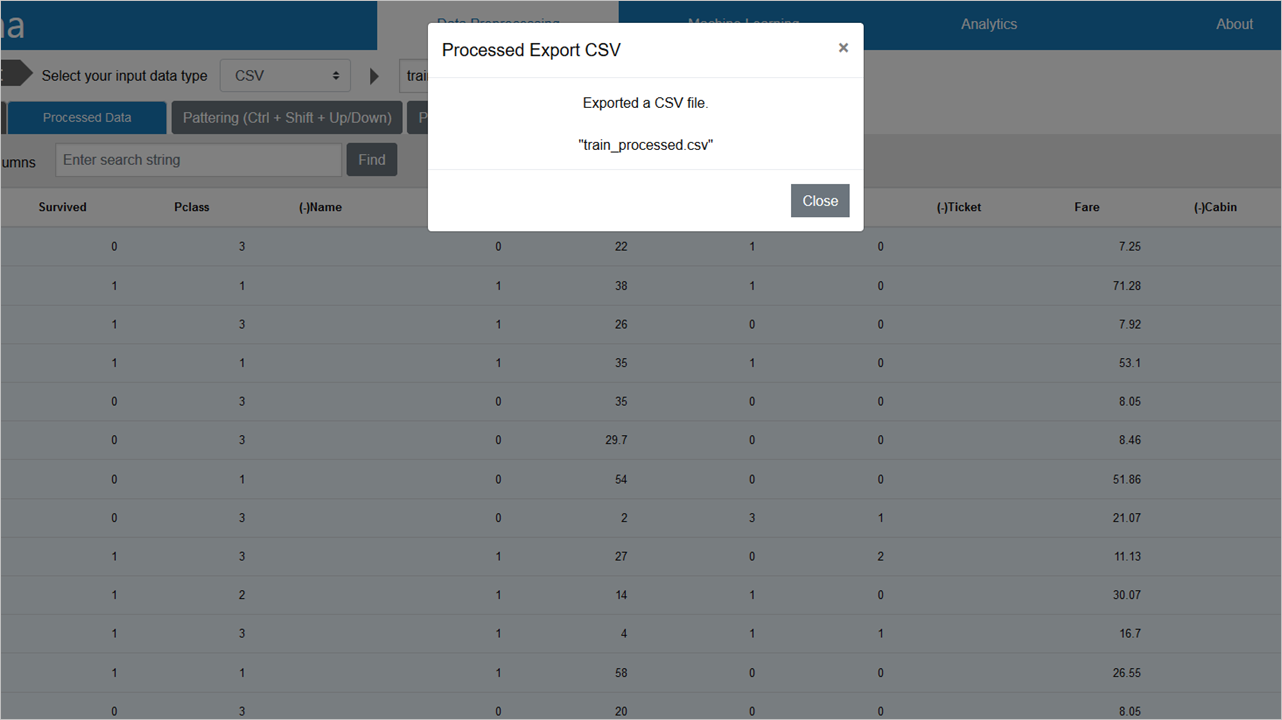
これで、train.csvの前処理は完了です
同じ前処理を、test.csvに対しても実施したい(≒前処理が訓練データとテストデータで異なると、モデルがうまく動作しないため)ので、画面上部の「data import」からtest.csvをインポートし、「Processed Export CSV」を行い、test_processed.csvというファイルも作成します
前処理は、Esunaが生成したElixirコードで実行される
先ほどまで見てきた、前処理後データは、実は裏でEsunaが動的に生成するElixirコードによって、実現されています
ここで生成された、前処理Elixirコードを見てみましょう
defmodule Preprocessor do
def rows( csv_file_path ) do
csv_file_path
|> Importer.csv_load_map
|> Enum.map( &( Map.drop( &1, [ "Cabin", "Name", "Ticket" ] ) ) )
|> MapList.imputer( [ "Age" ], "", "avg" )
|> MapList.fill( [ "Embarked" ], "S", "" )
|> MapList.get_dummies( [ "Embarked", "Sex" ] )
end
def columns( csv_file_path ) do
csv_file_path
|> Importer.csv_load
|> List.first
end
end
ImporterモジュールによるCSVファイルのロード/変換や、MapListモジュールによるリストマップの複数列操作と、Elixirのパイプにより、かなり直観的なコードになっています
また、Pythonでpandasによるデータ操作をやったことがあれば、それと似たような操作が、Esunaでは可能なことが分かります
なお、このEsunaで使っているモジュール群は、別途切り出し、scikit-learnやpandasに相当するようなツールキットとして、そのうちOSS公開予定です
終わり
第一部は、以上となります
Kaggleのタイタニック予測にて、データサイエンスプラットフォーム「Esuna」を使い、前処理の解説を行いましたが、Esunaでの前処理は、非常にカンタンなUIから操作できることが、実感できたのでは無いかなぁ、と思います
まもなく、OSSとして公開されるEsunaを、楽しみにお待ちください ![]()
→ Kaggleに参戦した結果も含む、第二部以降は、コチラからご覧になれます
p.s.「いいね」よろしくお願いします
ページ左上の  や
や  のクリックを、どうぞよろしくお願いします
のクリックを、どうぞよろしくお願いします![]()
ここの数字が増えると、書き手としては「ウケている」という感覚が得られ、連載を更に進化させていくモチベーションになりますので、もっとElixirネタを見たいというあなた、私達と一緒に盛り上げてください!![]()