前回の記事でMATLABで機械学習を実装する基本について紹介しました。
今回の記事は深層学習の実装について説明します。
おまけにPythonのpytorchによる実装とも比較します。
はじめに
MATLABにはDeep Learning Toolboxというパッケージを持って、これを使うことでPythonのkerasやpytorchみたいに簡単にニューラルネットワークを実装することができます。
書き方としてはkeras風でもpytorch風でもできます。
keras風というのはつまりニューラルネットワークの構造を定義しておくだけで学習は自動で行われるような書き方で、pytorch風は学習ループを自分で書く必要がある書き方です。いずれも私が勝手に読んでいるだけ。
pytorch風ではforループを通じて勾配の計算や最適化アルゴリズムによるパラメータの更新を書くのですが、keras風で書くとMATLABではtrainnetとtrainingOptionsを使って一発のコードで学習を行うのです。
trainnetを使うとkerasみたいに学習は勝手に最初から最後まで行われて便利ですが、その中の過程は色々細かく設定できないし、途中で何かの実行入れることもできなくてなんか不便なところもあって、ブラックボックスって感じもします。trainingOptionsである程度設定できるが、変更できることは意外と少ないですね。kerasの方がまだ色々設定できます。
だからtrainnetを使う方法よりもpytorch風、つまり自分で学習ループを書いて自由に管理する方法の方が好きです。
私は普段pytorchを使っているので、MATLABでもpytorchと似ているような書き方ができて嬉しいです。
この記事で紹介する方法も主にそのpytorch風で書きます。
使うデータセット
手書き数字
まずは使うデータセットの準備から始めます。今回使うのは誰もが知れ渡っているMNISTの手描き数字データセットです。Deep Learning Toolboxをインストールしたらこのデータセットも一緒にダウンロードされているので、すぐ練習などに使えます。
場所はMATLABのルートの中の「toolbox/nnet/nndemos/nndatasets/DigitDataset」フォルダで、MATLABのルートフォルダはバージョンやOSによって違いますが、matlabroot変数で参照できます。
このデータをimageDatastoreで読み込みます。imageDatastoreの使い方については画像処理の基本の記事に少し書いてあります。
機械学習に使う場合は、IncludeSubfolders=trueとLabelSource="foldernames"を指定したらサブフォルダがラベルとして扱われて便利です。
mnist_folder = fullfile(matlabroot,"toolbox/nnet/nndemos/nndatasets/DigitDataset");
imds = imageDatastore( ...
mnist_folder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames")
imds =
ImageDatastore のプロパティ:
Files: {
' .../toolbox/nnet/nndemos/nndatasets/DigitDataset/0/image10000.png';
' .../toolbox/nnet/nndemos/nndatasets/DigitDataset/0/image9001.png';
' .../toolbox/nnet/nndemos/nndatasets/DigitDataset/0/image9002.png'
... and 9997 more
}
Folders: {
' .../MATLAB_R2024a.app/toolbox/nnet/nndemos/nndatasets/DigitDataset'
}
Labels: [0; 0; 0 ... and 9997 more categorical]
AlternateFileSystemRoots: {}
ReadSize: 1
SupportedOutputFormats: ["png" "jpg" "jpeg" "tif" "tiff"]
DefaultOutputFormat: "png"
ReadFcn: @readDatastoreImage
どのラベルがどれくらいあるか調べられます。
imds.countEachLabel
10×2 table
Label Count
_____ _____
0 1000
1 1000
2 1000
3 1000
4 1000
5 1000
6 1000
7 1000
8 1000
9 1000
試しに読み込んでここで一部表示します。
figure
montage(imds.Files(randperm(numel(imds.Files),289)))

訓練データとテストデータの分割
ImageDatastoreを訓練データとテストデータに分けるためにはsplitEachLabelという関数を使うと便利です。
例えば8:2に分けたい場合。
[imds_train,imds_test] = splitEachLabel(imds,0.8,"randomize");
一気に「訓練、検証、テスト」3つに分けることもできます。例えば7:1:2に分けたいならこう書きます。
[imds_train,imds_val,imds_test] = splitEachLabel(imds,0.7,0.1,"randomize");
今回は検証とテストを分けずに、ただ訓練とテスト(=検証)で行きます。
水増し
学習用のデータを増やすために色々ランダムで弄りたい場合imageDataAugmenterを使うと便利です。
imaug = imageDataAugmenter( ...
RandXTranslation=[-8 8], ...
RandYTranslation=[-10 10], ...
RandRotation=[-45,45], ...
RandScale=[0.5 1.2]);
aimds = augmentedImageDatastore([28 28],imds_train,DataAugmentation=imaug);
aimds =
augmentedImageDatastore のプロパティ:
NumObservations: 8000
Files: {8000×1 cell}
AlternateFileSystemRoots: {}
MiniBatchSize: 128
DataAugmentation: [1×1 imageDataAugmenter]
ColorPreprocessing: 'none'
OutputSize: [28 28]
OutputSizeMode: 'resize'
DispatchInBackground: 0
augmentedImageDatastoreオブジェクトはImageDatastoreと同じように使えますが、これを使うと画像が読み込まれる時にランダムで処理されます。
試しにランダムで一部の画像を読み込んでみます。
figure
montage(aimds.readByIndex(randperm(numel(imds_train.Files),289)).input)

どうやら今回は弄りすぎましたね。なんか綺麗なように見えますが、これを実際に学習したらダメそうですね。
実装の全体
では今回の実装でコード全体をここに載せておきます。
% 学習で呼び出されるパラメータ更新を行う関数
function [dlnet,param_ag,param_asg] = fcn_update(dlnet,X,T,param_ag,param_asg,i_iter)
if canUseGPU % GPUが使える場合
X = gpuArray(X);
end
[Y,state] = dlnet.forward(X); % データを入力して最後の層まで走らせる
loss = crossentropy(Y,T); % 結果を実際のラペルと比較して損失を計算する
param_grad = dlgradient(loss,dlnet.Learnables); % 損失から勾配を計算する
dlnet.State = state; % 状態パラメータを更新する
% adamでパラメータを更新する
[dlnet,param_ag,param_asg] = adamupdate(dlnet,param_grad,param_ag,param_asg,i_iter);
end
batch_size = 128; % 各ミニバッチの数
n_epoch = 100; % 最大の繰り返しの回数
mouii = 5; % 正確度が何エポック上がらなければ止まる
% ニューラルネットワークの層の定義
lis_layer = [
imageInputLayer([28 28 1],Normalization="none")
convolution2dLayer([3 3],16,Padding="same",WeightsInitializer="he")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([2 2],Stride=2)
convolution2dLayer([3 3],32,Padding="same",WeightsInitializer="he")
batchNormalizationLayer
reluLayer
dropoutLayer(0.3)
maxPooling2dLayer([2 2],Stride=2)
fullyConnectedLayer(10,WeightsInitializer="he")
softmaxLayer];
dlnet = dlnetwork(lis_layer);
% データを準備する
mnist_folder = fullfile(matlabroot,"toolbox/nnet/nndemos/nndatasets/DigitDataset");
imds = imageDatastore(mnist_folder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames");
% 全部のラベルのリスト
lis_label = unique(imds.Labels);
% データを訓練と検証(=テスト)に分ける
[imds_train,imds_test] = splitEachLabel(imds,0.8,"randomize");
% 訓練のデータをランダムで弄る
imaug = imageDataAugmenter(RandRotation=[-5 5]);
aimds_train = augmentedImageDatastore([28 28],imds_train,DataAugmentation=imaug);
% 検証の時に使うデータを準備しておく
arimg_train = cat(4,imds_train.readall{:});
label_train = imds_train.Labels;
arimg_test = cat(4,imds_test.readall{:});
label_test = imds_test.Labels;
n_train = numel(label_train); % 訓練データの数
n_batch = ceil(n_train/batch_size); % 各エポックでミニバッチが分けられる数
param_ag = []; % adam用の変数
param_asg = []; % adam用の変数
lis_seikaku_train = []; % 各エポックの訓練データの正確度を収める配列
lis_seikaku_test = []; % 各エポックの検証データの正確度を収める配列
lis_sonshitsu_train = []; % 各エポックの訓練データの損失を収める配列
lis_sonshitsu_test = []; % 各エポックの検証データの損失を収める配列
mouiika = 0; % 上がらない回数を数える
i_iter = 1; % 繰り返しの回数を数える
figure(Position=[100 100 700 600]); % グラフを描く準備をする
t0 = datetime("now"); % 開始の時間
% 各エポックで学習を繰り返す
for i_epoch = 1:n_epoch
idx_perm = randperm(n_train); % 訓練データをランダムで並び替える
% 各ミニバッチの学習ループ
for i_batch = 1:n_batch
idx_batch = idx_perm((i_batch-1)*batch_size+1:min(i_batch*batch_size,n_train));
adata = aimds_train.readByIndex(idx_batch); % 水増しを通しされたデータを読み込む
X = dlarray(single(cat(4,adata.input{:})),"SSCB"); % 画像データの準備
T = single(adata.response'==lis_label); % ラベルをワンホットにする
% パラメータの更新
[dlnet,param_ag,param_asg] = dlfeval(@fcn_update,dlnet,X,T,param_ag,param_asg,i_iter);
i_iter = i_iter+1;
end
% エポックが終わったところで全部の訓練データでの損失と正確度を纏める
Y = minibatchpredict(dlnet,arimg_train,MiniBatchSize=batch_size)';
loss = crossentropy(Y,label_train'==lis_label);
label_pred = scores2label(Y,lis_label)';
acc = mean(label_pred==label_train)*100;
lis_sonshitsu_train = cat(1,lis_sonshitsu_train,loss);
lis_seikaku_train = cat(1,lis_seikaku_train,acc);
% テストデータで検証
Y = minibatchpredict(dlnet,arimg_test,MiniBatchSize=batch_size)';
loss = crossentropy(Y,label_test'==lis_label);
label_pred = scores2label(Y,lis_label)';
acc = mean(label_pred==label_test)*100;
lis_sonshitsu_test = cat(1,lis_sonshitsu_test,loss);
lis_seikaku_test = cat(1,lis_seikaku_test,acc);
% グラフを描く
tiledlayout(2,1,Padding="none",TileSpacing="tight");
nexttile
hold on
plot(lis_seikaku_train,LineWidth=2)
plot(lis_seikaku_test,LineWidth=2)
xticklabels([])
ylabel("正確度(%)",FontSize=14)
legend([sprintf("訓練データ(最大 %.3f%%)",max(lis_seikaku_train))
sprintf("検証データ(最大 %.3f%%)",max(lis_seikaku_test))], ...
Location="southeast",FontSize=14)
grid
title(sprintf("%.2f秒経った",seconds(datetime("now")-t0)),FontSize=14)
nexttile
hold on
plot(lis_sonshitsu_train,LineWidth=2)
plot(lis_sonshitsu_test,LineWidth=2)
set(gca,YScale="log")
xlabel("エポック",FontSize=14)
ylabel("損失",FontSize=14)
grid
saveas(gca,"lc.png")
% 検証データの正確度が最大より更に上がったかどうか
if lis_seikaku_test(end) <= max(lis_seikaku_test(1:end-1))
% 上がらなかった場合
mouiika = mouiika+1;
if mouiika >= mouii
break % 数回も上がっていない場合すぐ学習を終了させる
end
else % 上がったらもう一度最初から数える
mouiika = 0;
% 今後使うために、一番いい結果を出す時の学習済みモデルを保存しておく
save("dlnet.mat","dlnet")
end
end
% 最後に混同行列を描いてみる
figure
plotconfusion(label_pred,label_test)
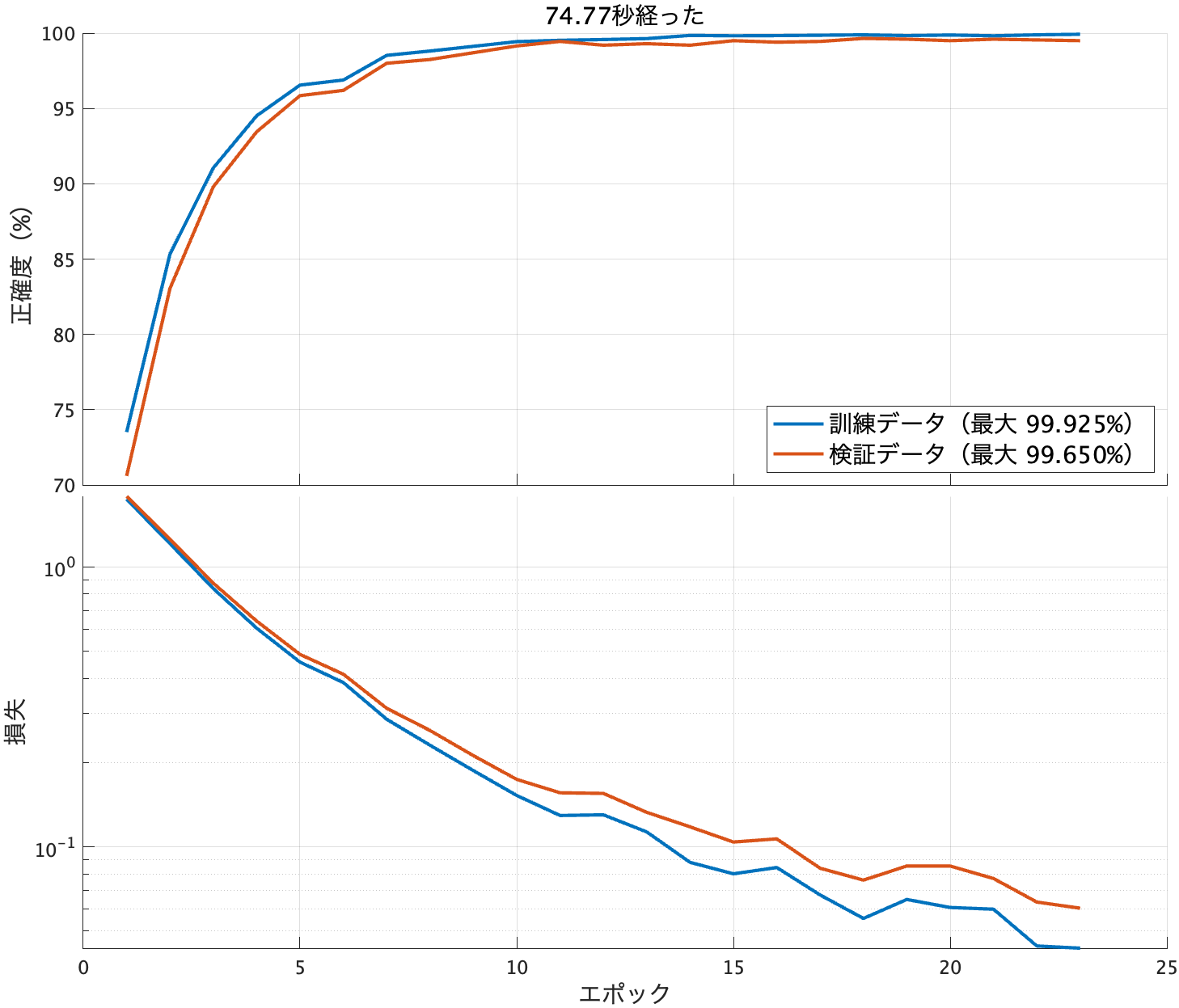
学習の途中で結果はこんな学習曲線ができます。経った時間と最大値も書いてあります。
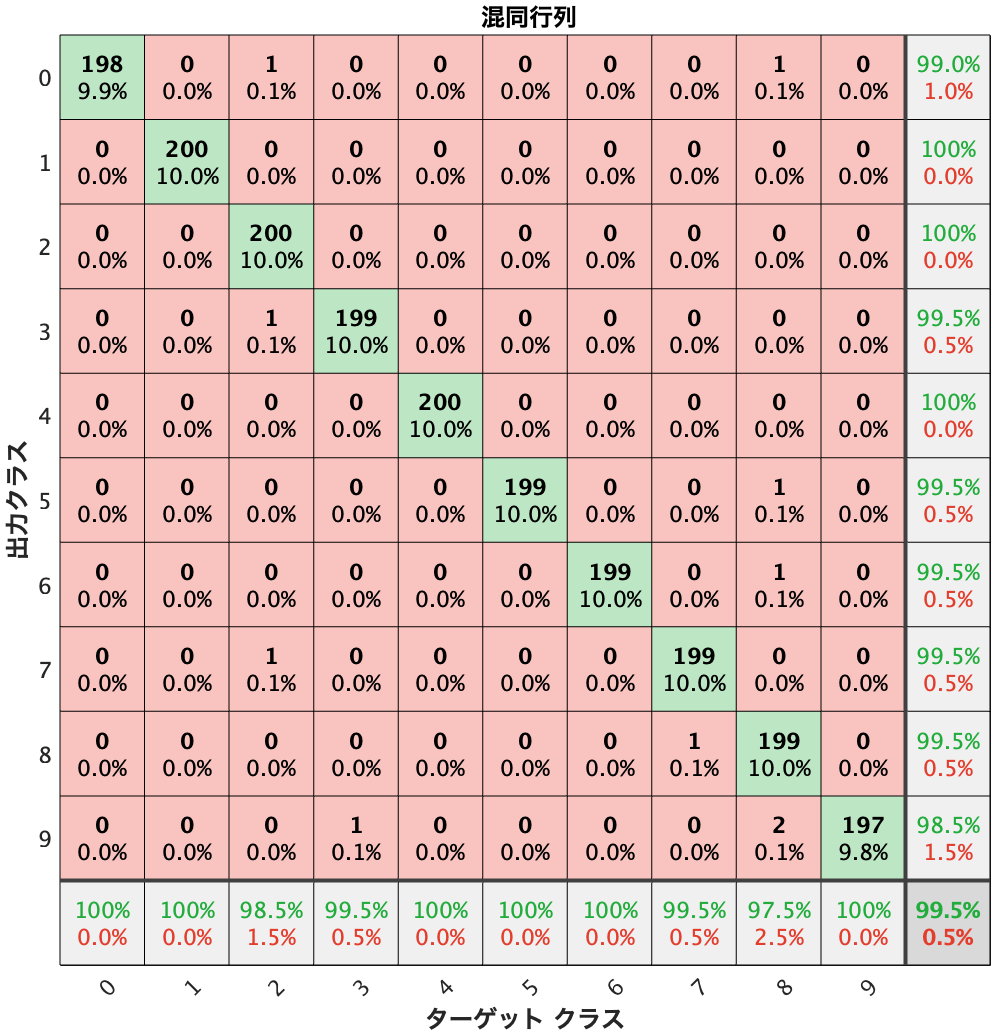
そして最後にこんな混同行列が出てきます。
コードの各部分の説明
次は以上のコードの追加の説明です。
モデルの定義(dlnetwork)
まずモデルの定義はdlnetwork関数でできます。入力するのは重ねた層の配列。
dlnet = dlnetwork(lis_layer);
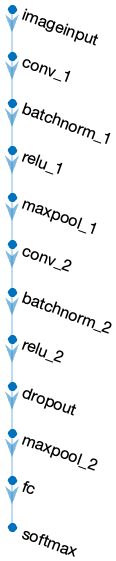
plotメソッドを使ったらネットの構造をグラフで表示することができるので描いてみます。
dlnet.plot
これで作って出てきたdlnetworkのオブジェクトは色んなプロパティを持っています。重要なのは例えば学習に使う重みパラメータが入っているLearnables。
dlnet.Learnables
10×3 table
Layer Parameter Value
_____________ _________ ____________________
"conv_1" "Weights" { 3×3×1×16 dlarray}
"conv_1" "Bias" { 1×1×16 dlarray}
"batchnorm_1" "Offset" { 1×1×16 dlarray}
"batchnorm_1" "Scale" { 1×1×16 dlarray}
"conv_2" "Weights" { 3×3×16×32 dlarray}
"conv_2" "Bias" { 1×1×32 dlarray}
"batchnorm_2" "Offset" { 1×1×32 dlarray}
"batchnorm_2" "Scale" { 1×1×32 dlarray}
"fc" "Weights" {10×1568 dlarray}
"fc" "Bias" {10×1 dlarray}
それと、batchnormなどで学習の間に変わっていく状態パラメータ。
dlnet.State
4×3 table
Layer Parameter Value
_____________ _________________ ________________
"batchnorm_1" "TrainedMean" {1×1×16 dlarray}
"batchnorm_1" "TrainedVariance" {1×1×16 dlarray}
"batchnorm_2" "TrainedMean" {1×1×32 dlarray}
"batchnorm_2" "TrainedVariance" {1×1×32 dlarray}
これらは学習ループの中で使われます。
畳み込み層と全結合層に書いてあるWeightsInitializer="he"は重みパラメータの初期値を何愷明(Hé Kǎimíng)式にするために指定したのです。既定値ではXavier Glorot式ですが、活性化関数をReLUにする場合は何愷明式の方が適切だそうです。まあ、実際にbatchnormを使う時点でどっちもあまり変わらなくて気にしなくてもいいかもしれませんが。
ミニバッチの処理
ここでは毎回のエポックでrandperm関数を使ってシャッフルします。
実はminibatchqueueというミニバッチを作るための関数がありますが、あまり必要ない気がしますので使わないことにします。自分でランダムのところを書いた方がわかりやすいと思います。
GPUの使用(gpuArray)
MATLABではGPUによって高速計算したい場合は配列をgpuArrayオブジェクトに変換します。
今の環境ではGPUが使えるかどうかをチェックするためにはcanUseGPU関数があります。これで条件分岐してCPUとGPUを使い分けすることもできます。
これを使うためにParallel Computing Toolboxパッケージをインストールする必要があります。
ただし実はMATLABの中でもしGPUが使える環境になっていたら特に設定しなくても勝手にGPUを使うことにされる場合が多いです。例えばtrainnet関数で学習する時。
dlarrayオブジェクトに変換
ニューラルネットワークの学習に使う配列はまずdlarrayオブジェクトに変換する必要があります。
ここでSSCBという略称みたいな文字が書いてありますが、これは配列の各軸のデータ形式です。SSCBは「空間、空間、チャネル、バッチ」を示します。
パラメータの更新(dlfeval)
学習ループの中で一番大事なのはdlfeval関数を使うところです。このdlfevalは定義された関数を呼び出してパラメータを更新します。
その関数の中で最適化アルゴリズムも定義します。ここではadamupdateを使います。
入力は主には画像データとラベルですが、その他にもadamupdateに使うパラメータも入れる必要があります。他の最適化アルゴリズムを使ったら入力も違います。
batchnormなど状態パラメータを持つ層を使っている場合はstateの更新が必要となります。もしなければforwardの部分は単にY = dlnet.forward(X)と書いてdlnet.State = stateも不要です。しかしbatchnormを使ったらこれがないとまずいことになるので注意しないといけないです。
訓練とテストデータで検証
各エポックが終わった後検証を行います。訓練データもテストデータもminibatchpredict関数を使って予測させて結果を比べて全体の損失と正確度を計算します。
そして検証データの損失によって次のエポックに入るかどうかを決めます。
minibatchpredictとforwardはどっちもネットワークに画像を入力して最後の層まで通すことですが、forwardは学習用でminibatchpredictは検証と実用だという使い分けがあります。
barchnormやdropout層などは学習の時と実用の時の動きが違うので、これが入るとminibatchpredictとforwardとの違いははっきりわかります。
また、minibatchpredictはGPUが使える環境だと自動的にGPUで計算するということになってくれるので、X = gpuArray(X)を書く必要がなくて手間が省けるのです。更にMiniBatchSizeキーワードにバッチサイズを指定することで分割して計算してくれるから便利です。
混合行列(plotconfusion)
ここではplotconfusion関数で混同行列を作りました。この関数はDeep Learning Toolboxパッケージの中の関数です。
その他にもStatistics and Machine Learning Toolboxパッケージの中のconfusionchartがあります。
confusionchart(label_pred,label_test, ...
RowSummary="row-normalized", ...
ColumnSummary="column-normalized");
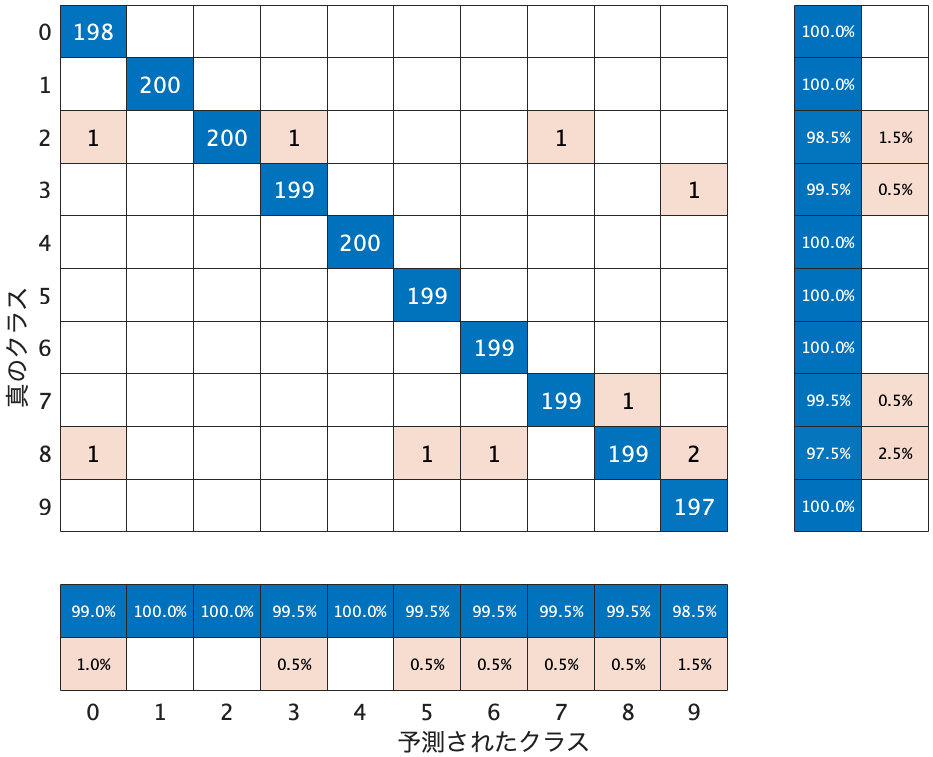
どっちを使ってもいいですが、表示のスタイルはちょっと違います。
複雑なネットワークの定義
以上紹介したニューラルネットワークはただ層を重ねていくだけの簡単なものなのですぐ定義できますが、resnetなどスキップ接続を使う構造の場合はそう簡単にはなりません。部分を分けて定義してconnectLayers関数を使って接続を指定する必要があります。
例えば分岐して後で足し算をするような構造を作ってみます。
lis_layer1 = [
imageInputLayer([28 28 1],Normalization="none")
convolution2dLayer([3 3],16,Padding="same",WeightsInitializer="he",Name="cv1")
batchNormalizationLayer(Name="bn1")
reluLayer(Name="rl1")
maxPooling2dLayer([2 2],Stride=2,Name="mp1")];
lis_layer2 = [
convolution2dLayer([3 3],16,Padding="same",WeightsInitializer="he",Name="cv2")
batchNormalizationLayer(Name="bn2")
reluLayer(Name="rl2")];
lis_layer3 = [
additionLayer(2,Name="add3")
fullyConnectedLayer(10,WeightsInitializer="he",Name="fc3")
softmaxLayer];
dlnet = dlnetwork(lis_layer1);
dlnet = dlnet.addLayers(lis_layer2);
dlnet = dlnet.addLayers(lis_layer3);
dlnet = dlnet.connectLayers("mp1","add3/in1");
dlnet = dlnet.connectLayers("mp1","cv2");
dlnet = dlnet.connectLayers("rl2","add3/in2");
dlnet = dlnet.initialize;
dlnet.plot
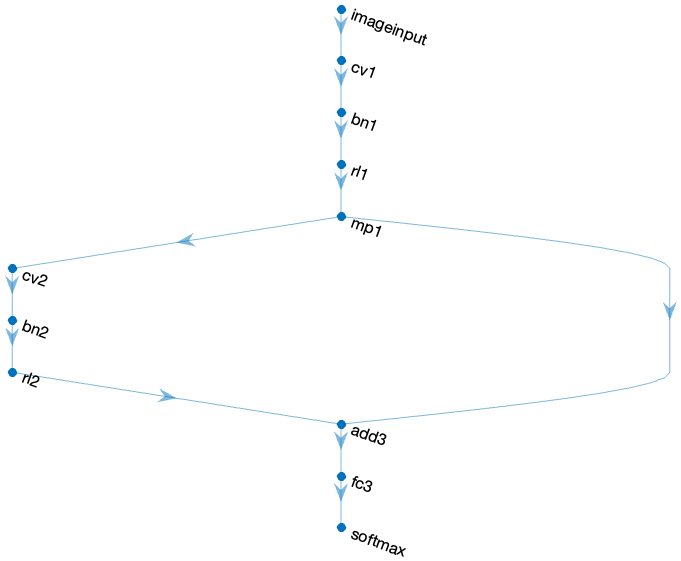
1回のaddLayersで追加される層の間は順番の接続されますが、前に追加された層とは接続されないので、ここでconnectLayersで接続する必要があります。
接続する時に層の名前を指定する必要があります。層の名前は普段自分で付けなくても自動的に命名されるのですが、わかりやすくなるように今回全部自分で名前を付けておきました。
そして最後にinitializeを使って初期化する必要があります。
trainnet関数におけるkeras風の学習
以上わざわざpytorchみたいに学習ループを書いて長いコードになりましたが、実はtrainnetとtrainingOptionskerasみたいに完結な書き方もできますね。この方法は詳しく説明しませんが、一応コード実装のコードを載せて比較します。
lis_layer = [
imageInputLayer([28 28 1],Normalization="none")
convolution2dLayer([3 3],16,Padding="same",WeightsInitializer="he")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([2 2],Stride=2)
convolution2dLayer([3 3],32,Padding="same",WeightsInitializer="he")
batchNormalizationLayer
reluLayer
dropoutLayer(0.3)
maxPooling2dLayer([2 2],Stride=2)
fullyConnectedLayer(10,WeightsInitializer="he")
softmaxLayer];
mnist_folder = fullfile(matlabroot,"toolbox/nnet/nndemos/nndatasets/DigitDataset");
imds = imageDatastore(mnist_folder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames");
[imds_train,imds_test] = splitEachLabel(imds,0.8,"randomize");
opt = trainingOptions("adam", ...
InitialLearnRate=0.001, ...
MaxEpochs=100, ...
Shuffle="every-epoch", ...
MiniBatchSize=128, ...
Metrics="accuracy", ...
ValidationData=imds_test, ...
ValidationFrequency=63,...
ValidationPatience=5, ...
Plots="training-progress");
dlnet = trainnet(imds_train,lis_layer,"crossentropy",opt);
実行したらこのようなGUIウィンドウまで作られます。
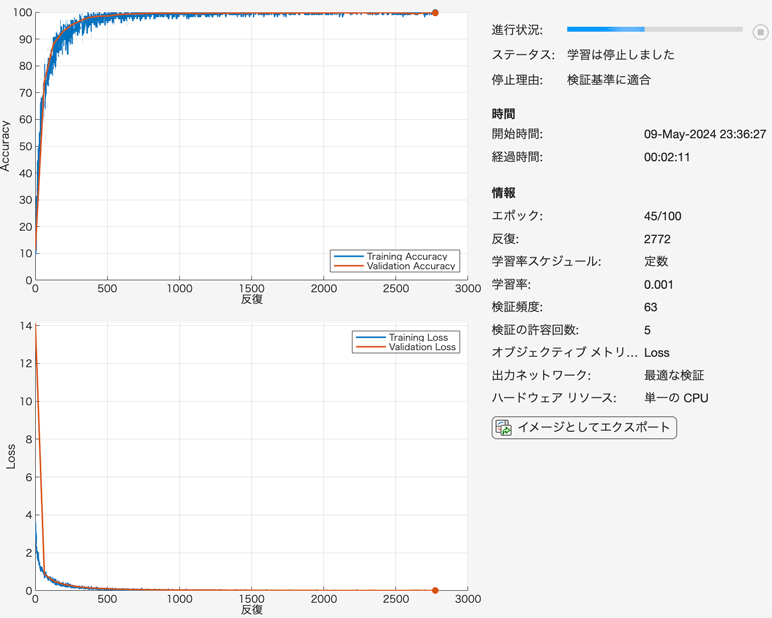
層の定義はpytorch風の時と同じですが、予めdlnetworkオブジェクトを作る必要なく、直接trainnetに入力できます。ただしもしdlnetworkを作っておいたらそれをそのまま使うこともできます。
学習の条件や表示したいことは殆どtrainingOptionsで指定します。設定できることは多くないのですが、あまり気にしないならそのまま使えます。
検証データもtrainingOptionsの中で指定することになっています。
こうやって学習を2行でできてしまうので、初心者にとって便利です。
また、GPUが使える環境である場合は勝手にGPUを使うことになるので、特に指定する必要がありません。
なお、昔から書いたコードを読んだらtrainnetではなくtrainNetwork関数を使うのが一般的ですが、今trainNetworkが非推奨になって、新しく搭載されたtrainnet関数が推奨されています。使い方は大体同じですが、trainnetの方が高速だそうです。
転移学習
MATLABでは学習済みのよく使われているモデルを色々準備されています。これをimagePretrainedNetworkで簡単に作れます。
例えばresnet18を使いたい場合はresnet18の名前を入れればいいです。ただし重みパラメータをダウンロードする必要があります。ダウンロードしておいていない場合このようなエラーメッセージが出てきてダウンロードするように指示されます。
dlnet = imagePretrainedNetwork("resnet18")
次を使用中のエラー: doImagePretrainedNetwork (行 48)
resnet18 には事前学習済みの重みに対する Deep Learning Toolbox Model for ResNet-18 Network サポー
ト パッケージが必要です。このサポート パッケージをインストールするには、アドオン エクスプローラー を使用してく
ださい。未学習の層を取得するには、imagePretrainedNetwork("resnet18",Weights="none") を使用してくだ
さい。これにサポート パッケージは不要です。
重みパラメータを使わずに最初から学習したい場合はWeights="none"を指定して、これでダウンロードしなくてもすぐ使えます。
dlnet = imagePretrainedNetwork("resnet18",Weights="none")
dlnet =
dlnetwork のプロパティ:
Layers: [70×1 nnet.cnn.layer.Layer]
Connections: [77×2 table]
Learnables: [82×3 table]
State: [40×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 0
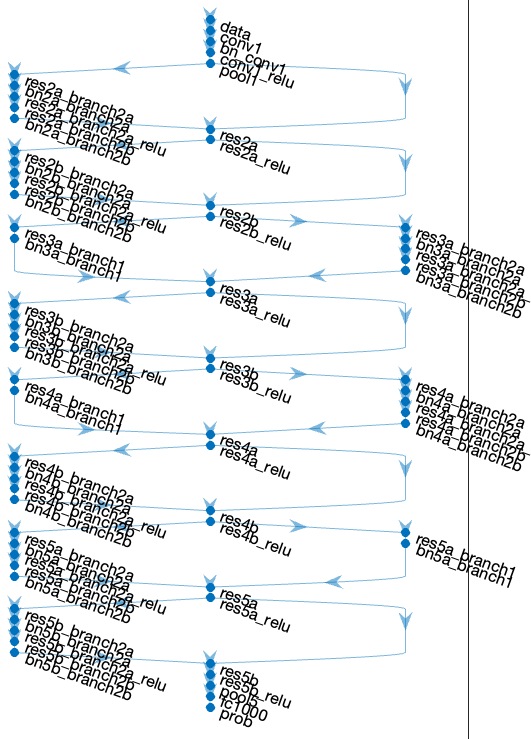
ちょっと作ったネットワークの構造を見てみます。
dlnet.Layers
dlnet.plot
次の層をもつ 70×1 の Layer 配列:
1 'data' イメージの入力 'zscore' 正規化の 224×224×3 イメージ
2 'conv1' 2-D 畳み込み ストライド [2 2] およびパディング [3 3 3 3] の 64 7×7×3 畳み込み
3 'bn_conv1' バッチ正規化 64 チャネルでのバッチ正規化
4 'conv1_relu' ReLU ReLU
5 'pool1' 2-D 最大プーリング ストライド [2 2] およびパディング [1 1 1 1] の 3×3 最大プーリング
6 'res2a_branch2a' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 64 3×3×64 畳み込み
7 'bn2a_branch2a' バッチ正規化 64 チャネルでのバッチ正規化
8 'res2a_branch2a_relu' ReLU ReLU
9 'res2a_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 64 3×3×64 畳み込み
10 'bn2a_branch2b' バッチ正規化 64 チャネルでのバッチ正規化
11 'res2a' 加算 2 入力の要素単位の加算
12 'res2a_relu' ReLU ReLU
13 'res2b_branch2a' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 64 3×3×64 畳み込み
14 'bn2b_branch2a' バッチ正規化 64 チャネルでのバッチ正規化
15 'res2b_branch2a_relu' ReLU ReLU
16 'res2b_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 64 3×3×64 畳み込み
17 'bn2b_branch2b' バッチ正規化 64 チャネルでのバッチ正規化
18 'res2b' 加算 2 入力の要素単位の加算
19 'res2b_relu' ReLU ReLU
20 'res3a_branch1' 2-D 畳み込み ストライド [2 2] およびパディング [0 0 0 0] の 128 1×1×64 畳み込み
21 'bn3a_branch1' バッチ正規化 128 チャネルでのバッチ正規化
22 'res3a_branch2a' 2-D 畳み込み ストライド [2 2] およびパディング [1 1 1 1] の 128 3×3×64 畳み込み
23 'bn3a_branch2a' バッチ正規化 128 チャネルでのバッチ正規化
24 'res3a_branch2a_relu' ReLU ReLU
25 'res3a_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 128 3×3×128 畳み込み
26 'bn3a_branch2b' バッチ正規化 128 チャネルでのバッチ正規化
27 'res3a' 加算 2 入力の要素単位の加算
28 'res3a_relu' ReLU ReLU
29 'res3b_branch2a' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 128 3×3×128 畳み込み
30 'bn3b_branch2a' バッチ正規化 128 チャネルでのバッチ正規化
31 'res3b_branch2a_relu' ReLU ReLU
32 'res3b_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 128 3×3×128 畳み込み
33 'bn3b_branch2b' バッチ正規化 128 チャネルでのバッチ正規化
34 'res3b' 加算 2 入力の要素単位の加算
35 'res3b_relu' ReLU ReLU
36 'res4a_branch1' 2-D 畳み込み ストライド [2 2] およびパディング [0 0 0 0] の 256 1×1×128 畳み込み
37 'bn4a_branch1' バッチ正規化 256 チャネルでのバッチ正規化
38 'res4a_branch2a' 2-D 畳み込み ストライド [2 2] およびパディング [1 1 1 1] の 256 3×3×128 畳み込み
39 'bn4a_branch2a' バッチ正規化 256 チャネルでのバッチ正規化
40 'res4a_branch2a_relu' ReLU ReLU
41 'res4a_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 256 3×3×256 畳み込み
42 'bn4a_branch2b' バッチ正規化 256 チャネルでのバッチ正規化
43 'res4a' 加算 2 入力の要素単位の加算
44 'res4a_relu' ReLU ReLU
45 'res4b_branch2a' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 256 3×3×256 畳み込み
46 'bn4b_branch2a' バッチ正規化 256 チャネルでのバッチ正規化
47 'res4b_branch2a_relu' ReLU ReLU
48 'res4b_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 256 3×3×256 畳み込み
49 'bn4b_branch2b' バッチ正規化 256 チャネルでのバッチ正規化
50 'res4b' 加算 2 入力の要素単位の加算
51 'res4b_relu' ReLU ReLU
52 'res5a_branch2a' 2-D 畳み込み ストライド [2 2] およびパディング [1 1 1 1] の 512 3×3×256 畳み込み
53 'bn5a_branch2a' バッチ正規化 512 チャネルでのバッチ正規化
54 'res5a_branch2a_relu' ReLU ReLU
55 'res5a_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 512 3×3×512 畳み込み
56 'bn5a_branch2b' バッチ正規化 512 チャネルでのバッチ正規化
57 'res5a_branch1' 2-D 畳み込み ストライド [2 2] およびパディング [0 0 0 0] の 512 1×1×256 畳み込み
58 'bn5a_branch1' バッチ正規化 512 チャネルでのバッチ正規化
59 'res5a' 加算 2 入力の要素単位の加算
60 'res5a_relu' ReLU ReLU
61 'res5b_branch2a' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 512 3×3×512 畳み込み
62 'bn5b_branch2a' バッチ正規化 512 チャネルでのバッチ正規化
63 'res5b_branch2a_relu' ReLU ReLU
64 'res5b_branch2b' 2-D 畳み込み ストライド [1 1] およびパディング [1 1 1 1] の 512 3×3×512 畳み込み
65 'bn5b_branch2b' バッチ正規化 512 チャネルでのバッチ正規化
66 'res5b' 加算 2 入力の要素単位の加算
67 'res5b_relu' ReLU ReLU
68 'pool5' 2-D グローバル平均プーリング 2-D グローバル平均プーリング
69 'fc1000' 全結合 1000 全結合層
70 'prob' ソフトマックス ソフトマックス
因みにresnetを考え出したのはHe初期化を提案したのと同じ何愷明です。自然言語処理などでよく使われているマスク自動符号化器もこの人です。
一部改造して使うこともできます。例えば出力層は本来1000クラスの分類に使われているのですが、10クラスだけの分類に書き換えたいなら要らない層を消して、新しい層を作って接続させます。
dlnet = imagePretrainedNetwork("resnet18",Weights="none");
dlnet = dlnet.removeLayers("fc1000");
dlnet = dlnet.addLayers(fullyConnectedLayer(10,Name="fc10"));
dlnet = dlnet.connectLayers("pool5","fc10");
dlnet = dlnet.connectLayers("fc10","prob");
dlnet = dlnet.initialize;
これで使えるようになります。
なお、resnetの入力は224ピクセルで色画像(3チャネル)なのでMNIST手書き数字データセットに使う場合変換する必要があります。読み込む時に呼び出す関数を定義してReadFcnに入れていいです。
imds = imageDatastore(mnist_folder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames", ...
ReadFcn=@(f)repmat(imresize(imread(f),[224 224]),1,1,3));
pytorchでの実装
最後に比較するためにPythonのpytorchで同じようなCNNを実装するコードも載せます。
import time,torch
from torch.utils.data import DataLoader as Dalo
import torchvision.datasets as ds
import torchvision.transforms as tf
import numpy as np
import matplotlib.pyplot as plt
crossentropy = torch.nn.CrossEntropyLoss()
plt.rcParams['font.family'] = 'Hiragino Sans'
batch_size = 128
n_epoch = 100
mouii = 5
dlnet = torch.nn.Sequential(
torch.nn.Conv2d(1,16,3,1,'same'),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(16,32,5,1,'same'),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(),
torch.nn.Dropout(0.3),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(7*7*32,10)
)
for i in [0,4,10]:
torch.nn.init.kaiming_normal_(dlnet[i].weight)
mnist_folder = '/Applications/MATLAB_R2024a.app/toolbox/nnet/nndemos/nndatasets/DigitDataset'
imds = ds.ImageFolder(root=mnist_folder,transform=tf.Compose([tf.Grayscale(),tf.ToTensor()]))
n_train = 8000
n_test = 2000
imds_train,imds_test = torch.utils.data.random_split(imds,[n_train,n_test])
if(torch.cuda.is_available()):
dlnet.cuda()
imaug = tf.RandomRotation((-5,5))
opt = torch.optim.Adam(dlnet.parameters())
lis_acc_train = []
lis_acc_test = []
lis_loss_train = []
lis_loss_test = []
mouiika = 0
t_roem = time.time()
for i_epoch in range(n_epoch):
dlnet.train()
for X,T in Dalo(imds_train,batch_size,shuffle=True):
X = imaug(X)
if(torch.cuda.is_available()):
X = X.cuda()
T = T.cuda()
Y = dlnet(X)
crossentropy(Y,T).backward()
opt.step()
opt.zero_grad()
dlnet.eval()
lis_loss_i = [];
lis_acc_i = [];
for X,T in Dalo(imds_train,batch_size,shuffle=False):
X = imaug(X)
if(torch.cuda.is_available()):
X = X.cuda()
T = T.cuda()
Y = dlnet(X)
label_pred = Y.argmax(1)
lis_loss_i.append(crossloss(Y,T).item())
lis_acc_i.append((label_pred==T).cpu().numpy().mean()*100)
lis_loss_train.append(np.mean(lis_loss_i))
lis_acc_train.append(np.mean(lis_acc_i))
lis_loss_i = [];
lis_acc_i = [];
for X,T in Dalo(imds_test,batch_size,shuffle=False):
X = imaug(X)
if(torch.cuda.is_available()):
X = X.cuda()
T = T.cuda()
Y = dlnet(X)
label_pred = Y.argmax(1)
lis_loss_i.append(crossloss(Y,T).item())
lis_acc_i.append((label_pred==T).cpu().numpy().mean()*100)
lis_loss_test.append(np.mean(lis_loss_i))
lis_acc_test.append(np.mean(lis_acc_i))
plt.figure(figsize=[6,5],dpi=100)
plt.subplot(211)
plt.title('%.2f秒経った'%(time.time()-t_roem))
plt.plot(lis_acc_train)
plt.plot(lis_acc_test)
plt.legend(['訓練データ(最大 %.3f%%)'%max(lis_acc_train),'検証データ(最大 %.3f%%)'%max(lis_acc_test)])
plt.grid()
plt.subplot(212)
plt.plot(lis_loss_train)
plt.plot(lis_loss_test)
plt.grid()
plt.tight_layout()
plt.savefig('lc.png')
plt.close()
if(i_epoch>0 and lis_acc_test[-1]<=max(lis_acc_test[:-1])):
mouiika = mouiika+1
if mouiika >= mouii:
break
else:
mouiika = 0
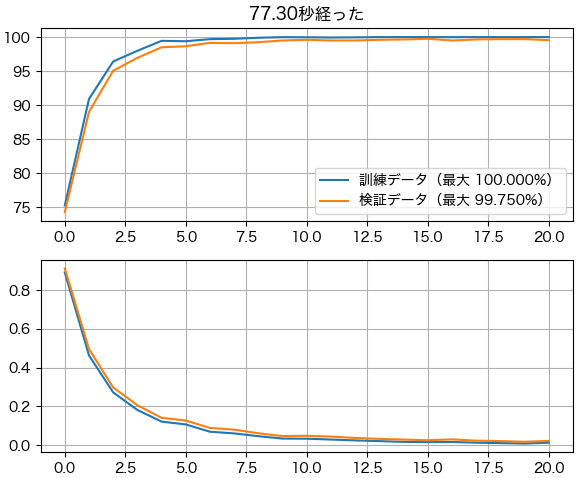
以上紹介したMATLABでの実装する書き方はpytorchと似ていますが、色々違いがあります。
例えば各層を定義する時に入力サイズを指定する必要がなく、自動的に前の層から決められるので少し楽になりますね。
それに最初から日本語が対応で特に設定する必要がなくて楽です。これはpytorchの問題よりmatplotlibの問題ですね。日本語に対するサポートがいいのもMATLABの長所の一つです。
参考&もっと読む
他にもMATLABによる深層学習関連の記事がqiitaには沢山あるのでここにリンクを貼っておきます。
- 言語処理100本ノックで MATLAB 入門!第8章: ニューラルネットワーク
- 5.6.2.1 ディープラーニング:畳み込みニューラルネットによる分類
- 5.6.2.7ディープラーニング:SSDによる物体検出
- 5.6.6 ディープラーニング:点群データのサポート
- MATLABで入力画像サイズを合わせずに分類CNNを使う
- 分類CNNをいじってニセCAM、ニセ検出器にする
- 事前学習済みモデルを使った学習ゼロの異常検知【MATLAB実装】
- MATLAB×深層学習×顕微赤外分光法
- MATLAB 最速最短でディープラーニングを使う
- MATLABでCNN
- スマホで撮った写真をディープラーニングで判定してみる (学習編)
- スマホで撮った写真をディープラーニングで判定してみる (デプロイ編)