目次へのリンク
概要
ディープラーニングによる点群の分類(PointNet)を行います。
実行には下記のToolboxが必要になります。
- MATLAB R2020a 以降
- Computer Vision Toolbox
- Deep Learning Toolbox
- Parallel Computing Toolbox(NVIDIA GPUでの学習・推論の高速化)
対応ファイル
必要なサポート関数へのパスを追加
code
addpath(fullfile(matlabroot,'\examples\deeplearning_shared\main'));
データのダウンロード
code
datapath = downloadSydneyUrbanObjects;
output
Downloading Sydney Urban Objects data set...
学習用と検証用にデータ分割
code
foldsTrain = 1:3;
foldsVal = 4;
dsTrain = sydneyUrbanObjectsClassificationDatastore(datapath,foldsTrain);
dsVal = sydneyUrbanObjectsClassificationDatastore(datapath,foldsVal);
データの一つを確認
code
data = read(dsTrain);
ptCloud = data{1,1};
label = data{1,2};
figure
pcshow(ptCloud.Location,[0 0 1],"MarkerSize",40,"VerticalAxisDir","down")
xlabel("X");ylabel("Y");zlabel("Z");
title(label)
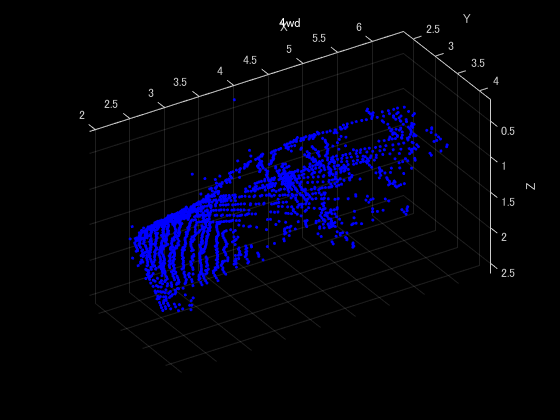
クラス毎のデータ数の分布を確認
code
dsLabelCounts = transform(dsTrain,@(data){data{2} data{1}.Count});
labelCounts = readall(dsLabelCounts);
labels = vertcat(labelCounts{:,1});
counts = vertcat(labelCounts{:,2});
figure
histogram(labels)
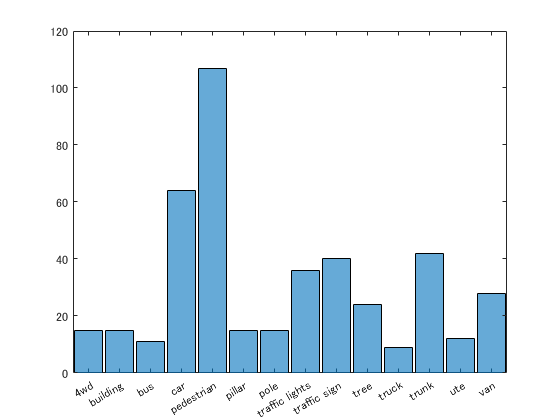
頻度の少ないクラスのデータを複製
code
rng(0)
[G,classes] = findgroups(labels);
numObservations = splitapply(@numel,labels,G);
desiredNumObservationsPerClass = max(numObservations);
files = splitapply(@(x){randReplicateFiles(x,desiredNumObservationsPerClass)},dsTrain.Files,G);
files = vertcat(files{:});
dsTrain.Files = files;
dsTrain.Files = dsTrain.Files(randperm(length(dsTrain.Files)));
ミニバッチサイズを指定
code
dsTrain.MiniBatchSize = 128;
dsVal.MiniBatchSize = 128;
データの水増し(回転・点群の間引き・ノイズ追加)
code
dsTrain = transform(dsTrain,@augmentPointCloud);
前処理
code
% 固定数の点群を抽出
numPoints = 1024; % 1024点の抽出
dsTrain = transform(dsTrain,@(data)selectPoints(data,numPoints));
dsVal = transform(dsVal,@(data)selectPoints(data,numPoints));
% 点群データの正規化
dsTrain = transform(dsTrain,@preprocessPointCloud);
dsVal = transform(dsVal,@preprocessPointCloud);
PointNetモデルの定義(モデルの初期化)
各ネットワークの層を定義し、初期化します。
code
% 1.入力変換モデル
inputChannelSize = 3;
hiddenChannelSize1 = [64,128];
hiddenChannelSize2 = 256;
[parameters.InputTransform, state.InputTransform] = initializeTransform(inputChannelSize,hiddenChannelSize1,hiddenChannelSize2);
% 2.Shared MLPモデル
inputChannelSize = 3;
hiddenChannelSize = [64 64];
[parameters.SharedMLP1,state.SharedMLP1] = initializeSharedMLP(inputChannelSize,hiddenChannelSize);
% 3.特徴変換モデル
inputChannelSize = 64;
hiddenChannelSize1 = [64,128];
hiddenChannelSize2 = 256;
[parameters.FeatureTransform, state.FeatureTransform] = initializeTransform(inputChannelSize,hiddenChannelSize,hiddenChannelSize2);
% 4.Shared MLPモデル
inputChannelSize = 64;
hiddenChannelSize = 64;
[parameters.SharedMLP2,state.SharedMLP2] = initializeSharedMLP(inputChannelSize,hiddenChannelSize);
% 分類モデル
inputChannelSize = 64;
hiddenChannelSize = [512,256];
numClasses = numel(classes);
[parameters.ClassificationMLP, state.ClassificationMLP] = initializeClassificationMLP(inputChannelSize,hiddenChannelSize,numClasses);
学習オプションの設定
code
numEpochs = 40;
learnRate = 0.001;
l2Regularization = 0.01;
learnRateDropPeriod = 15;
learnRateDropFactor = 0.5;
gradientDecayFactor = 0.9;
squaredGradientDecayFactor = 0.999;
学習の実行
カスタム学習ループを使って点群データの学習を行います。
code
avgGradients = [];
avgSquaredGradients = [];
doTraining = false;% true:学習の実行 false:学習後のモデルを使用
if doTraining
% 学習の進捗確認用のプロッター作成
[lossPlotter, trainAccPlotter,valAccPlotter] = initializeTrainingProgressPlot;
numClasses = numel(classes);
iteration = 0;
start = tic;
for epoch = 1:numEpochs
% データセットのリセット
reset(dsTrain);
reset(dsVal);
while hasdata(dsTrain)
iteration = iteration + 1;
% データの読み込み
data = read(dsTrain);
% バッチデータの作成
[XTrain,YTrain] = batchData(data);
% 勾配と損失の計算
[gradients, loss, state, acc] = dlfeval(@modelGradients,XTrain,YTrain,parameters,state);
% L2正則化
gradients = dlupdate(@(g,p) g + l2Regularization*p,gradients,parameters);
% ネットワークの重みを更新
[parameters, avgGradients, avgSquaredGradients] = adamupdate(parameters, gradients, ...
avgGradients, avgSquaredGradients, iteration,...
learnRate,gradientDecayFactor, squaredGradientDecayFactor);
% プロッターを更新
D = duration(0,0,toc(start),"Format","hh:mm:ss");
title(lossPlotter.Parent,"Epoch: " + epoch + ", Elapsed: " + string(D))
addpoints(lossPlotter,iteration,double(gather(extractdata(loss))))
addpoints(trainAccPlotter,iteration,acc);
drawnow
end
% 検証用データでモデルを評価
cmat = sparse(numClasses,numClasses);
while hasdata(dsVal)
% 次のデータを読み込み
data = read(dsVal);
% バッチデータの作成.
[XVal,YVal] = batchData(data);
% クラスの推論
isTraining = false;
YPred = pointnetClassifier(XVal,parameters,state,isTraining);
% スコアが一番高かったクラスを抽出.
[~,YValLabel] = max(YVal,[],1);
[~,YPredLabel] = max(YPred,[],1);
% 混同行列の集計
cmat = aggreateConfusionMetric(cmat,YValLabel,YPredLabel);
end
% 平均の分類精度をプロッターに追加
acc = sum(diag(cmat))./sum(cmat,"all");
addpoints(valAccPlotter,iteration,acc);
% 学習率の更新
if mod(epoch,learnRateDropPeriod) == 0
learnRate = learnRate * learnRateDropFactor;
end
% データセットのリセット
reset(dsTrain);
reset(dsVal);
end
else
% 学習済みモデルのダウンロードと読み込み
pretrainedURL = 'https://www.mathworks.com/supportfiles/vision/data/pretrainedPointNet.mat';
pretrainedNetwork = fullfile(pwd,'pretrainedPointNet.mat');
if ~exist(pretrainedNetwork,'file')
disp('Downloading pretrained network (5 MB)...');
websave(pretrainedNetwork,pretrainedURL);
end
pretrainedResults = load('pretrainedPointNet.mat');
parameters = pretrainedResults.parameters;
state = pretrainedResults.state;
cmat = pretrainedResults.cmat;
% GPUがある場合はgpuArrayに変換
parameters = prepareForPrediction(parameters,@(x)dlarray(toDevice(x,canUseGPU)));
state = prepareForPrediction(state,@(x)toDevice(x,canUseGPU));
end
% 混同行列の表示
figure
chart = confusionchart(cmat,classes);
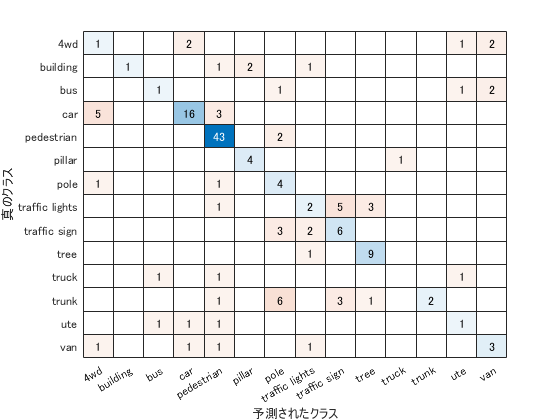
code
acc = sum(diag(cmat))./sum(cmat,"all")
output
acc = 0.6000
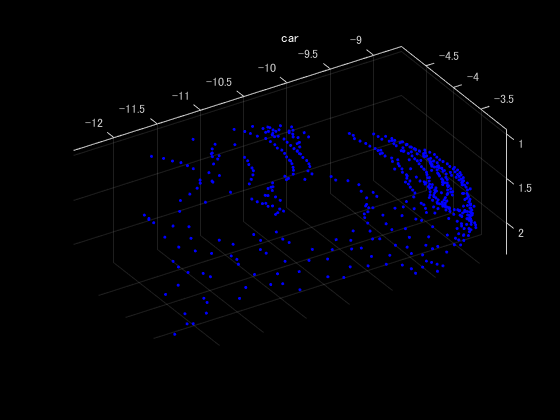
学習したモデルで分類
code
ptCloud = pcread("car.pcd");
X = preprocessPointCloud(ptCloud);
dlX = dlarray(X{1},"SCSB");
YPred = pointnetClassifier(dlX,parameters,state,false);
[~,classIdx] = max(YPred,[],1);
figure
pcshow(ptCloud.Location,[0 0 1],"MarkerSize",40,"VerticalAxisDir","down")
title(classes(classIdx))
まとめ
点群データの分類にディープラーニングを活用した例を紹介しました。
参考
謝辞
本記事は @eigs さんのlivescript2markdownを使わせていただいてます。