昨日までのはこちら
100日後にエンジニアになるキミ - 76日目 - プログラミング - 機械学習について
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回は機械学習についてのお話の続きです。
分類モデルについて
初回で機械学習でできることについて解説していますが、機械学習でできることは
基本的には3つです。
・回帰
・分類
・クラスタリング
大まかに言うと予測になりますが何を予測するかと言う部分が変わります。
・回帰:数値を予測する
・分類:カテゴリを予測する
・クラスタリング:いい感じにする
分類モデルはカテゴリ値を予測しにいきます。
今回使用するデータはscikit-learnに付属しているiris(あやめ)のデータを用います。
| sepal length (cm) | がく片の長さ |
|---|---|
| sepal width (cm) | がく片の幅 |
| petal length (cm) | 花弁の長さ |
| petal width (cm) | 花弁の幅 |
setosa, versicolor, virginicaという 3 種類の品種のアヤメです。
データの可視化
データを読み込みしてデータを眺めてみましょう。
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# iris データの読み込み
iris = load_iris()
# データフレームに変換する
df = pd.DataFrame(np.concatenate((iris.data, iris.target.reshape(-1,1)), axis=1),columns=iris.feature_names + ['type'])
df.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | type | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5 | 3.6 | 1.4 | 0.2 | 0 |
3種類のあやめ(剛力ではない)のデータになり、4列分の数値データを150行分持っています。
最後の列typeはあやめの品種になります。
今回用いるデータは3種類なので0,1,2という数値で入っています。
どのような特徴として現れるのかを可視化してみます。
import matplotlib.pyplot as plt
%matplotlib inline
# 可視化用のデータを変数に格納する
x1 = df['petal length (cm)']
x2 = df['petal width (cm)']
y = df['type']
x = df[['petal length (cm)','petal width (cm)']]
# データを描画する
for i in range(3):
plt.scatter(x1[y==i],x2[y==i],marker="x",label=i)
plt.legend()
plt.grid()
plt.show()

3種類のあやめがかなりきれいに分かれてしかも纏めっているように見えます。
ここで機械学習のデータの加工方法の一つである正規化と標準化を試してみましょう。
正規化(min-max normalization)
正規化は最小値を0 , 最大値を1のスケールで変換する手法です。
ただし、最小値・最大値を使った方法では最大値・最小値に強く影響を受けてしまうと言われています。
正規化値 = (値 - 最小値) / (最大値 - 最小値)
標準化(z-score normalization)
標準化は数値のデータの範囲を平均0、分散1になるように変更します。
こうすることで正規化よりも外れ値に強いと言われています。
標準化値 = (値 - 平均) / 標準偏差
標準化を行うと、データのスケールを小さくして、学習速度を上げることができます。
各説明変数間のスケールが大きく異なる場合(身長、体重など)
スケールの大きい変数が学習に影響を与えてしまうため、標準化を用いてこれを是正できます。
正規化の方法
正規化、標準化は以下のようなコードで行うことが出来ます。
ライブラリとしてはMinMaxScalerとStandardScalerを用います。
データの分割
まずは訓練用とテスト用にデータを分割します。今回は7:3で分割を行います。
# データを分割する
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=3)
正規化を行う
# 正規化を行う
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
# 訓練用のデータを正規化する
x_train_norm = mms.fit_transform(x_train)
# 訓練用データを基準にテストデータも正規化
x_test_norm = mms.transform(x_test)
print('訓練データの最大値 : ' , x_train_norm.max())
print('訓練データの最小値 : ' , x_train_norm.min())
# テスト用は訓練用データを元にしているため多少前後する
print('テストデータの最大値 : ' , x_test_norm.max())
print('テストデータの最小値 : ' , x_test_norm.min())
訓練データの最大値 : 1.0
訓練データの最小値 : 0.0
テストデータの最大値 : 1.0357142857142858
テストデータの最小値 : -0.017857142857142877
標準化を行う
# 標準化を行う
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
x_train_std = ss.fit_transform(x_train)
x_test_std = ss.transform(x_test)
print('訓練データの平均値 : ' , x_train_std.mean())
print('訓練データの標準偏差 : ' , x_train_std.std())
# テスト用は訓練用データを元にしているため多少前後する
print('テストデータの平均値 : ' , x_test_std.mean())
print('テストデータの標準偏差 : ' , x_test_std.std())
訓練データの平均値 : 3.425831047414769e-16
訓練データの標準偏差 : 1.0000000000000002
テストデータの平均値 : -0.1110109621182351
テストデータの標準偏差 : 1.040586519459273
標準化した場合は平均は0に近い数値になります。
正規化、標準化の結果と元のデータの違いを見てみましょう。
# 正規化、標準化したでーたと元のデータを可視化する
x_norm = mms.transform(x)
x_std = ss.transform(x)
plt.axis('equal')
plt.scatter(x.iloc[:,0],x.iloc[:,1], marker="x", label="org" ,c='blue')
plt.scatter(x_std[:,0] ,x_std[:,1] , marker="x", label="std" ,c='red')
plt.scatter(x_norm[:,0],x_norm[:,1], marker="x", label="norm",c='green')
plt.legend()
plt.grid()
plt.show()
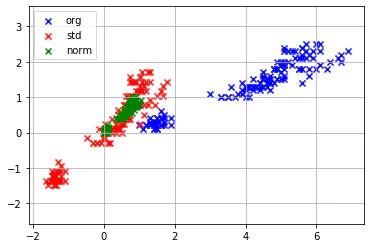
青がオリジナルの数値、赤色が標準化、緑色が正規化した際のデータです。
取りうる分布がかなり変わっているのがわかります。
予測モデルの作成
正規化、標準化データと元のデータの機械学習の結果の違いを見てみましょう。
下記はロジスティック回帰を用いて分類を行った結果を出力しています。
スコア値が高い方が精度が良くなっています。
# ロジスティック回帰モデルを読み込みする
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='liblinear', multi_class='auto')
lr_norm = LogisticRegression(solver='liblinear', multi_class='auto')
lr_std = LogisticRegression(solver='liblinear', multi_class='auto')
lr.fit(x_train,y_train)
print('元データのスコア :',lr.score(x_train,y_train))
lr_norm.fit(x_train_norm,y_train)
print('正規化したデータのスコア :',lr_norm.score(x_train_norm,y_train))
lr_std.fit(x_train_std,y_train)
print('標準化したデータのスコア :',lr_std.score(x_train_std,y_train))
元データのスコア : 0.8666666666666667
正規化したデータのスコア : 0.8095238095238095
標準化したデータのスコア : 0.9523809523809523
標準化したデータの方は精度が格段に上がっています。
判別モデルは最終的には目的変数の予測値を出力します。
この場合はカテゴリ値として0,1,2いづれかの数値を出力し、その結果がテストデータと合うかどうかをみて
精度を測っています。
精度検証の仕方などは前日の講義機械学習について5で行った際のやり方と同様です。
分類モデルの種類
他に分類モデルにはどのようなものがあるかを紹介します。
決定木

参考:wikipedia
分類するといえばこれかなという感じで良く用いられる手法です。
学習の過程で変数の値によって枝分かれしていき、最終的には樹木のような形状で可視化することができるモデルです。
ランダムフォレスト
決定木を弱学習器とするアンサンブル学習アルゴリズムです。
元々は決定木ですが、決定木をランダムに複数作り、それを並列に並べて結果の多数決を行います。
勾配ブースティング木(Gradient Boosting Decision Tree)
GBDT(Gradient Boosting Decision Tree)と略されます。
これも決定木を元に学習をさせ、結果をから誤差を少なくするように学習を繰り返し行います。
そうすることで最終的な結論を導き出す手法です。学習を繰り返すほど、精度が良くなる仕組みです。
現在の主流なのはこのブースティングと呼ばれる手法になっています。
いずれも、scikit-learnライブラリには入っているので色々と試してみることができます。
まとめ
本日は分類のモデルの仕組みを説明しました。
分類モデルは他にもたくさん存在します。
まずは、分類とは何、と言うことから初めて、モデル作り方と検証の仕方を抑えておきましょう。
君がエンジニアになるまであと18日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython