昨日までのはこちら
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回からは自然言語処理についてです。
自然言語処理とは
英語、日本語のように人間が自然発生的に使って来た言語を自然言語と言います。
これに対しプログラミング言語等の規則に基づく人工言語を形式言語と呼んで区別しています。
自然言語処理とは人間が日常的に使っている自然言語をコンピュータに処理させる
一連の技術のことを言います。
自然言語処理には沢山の技術が内包される形になります。
主な自然言語処理の技術
自然言語処理の中の技術体系は、このようなものがあります。
| 名称 | 内容 |
|---|---|
| 形態素解析 | 形態素に分割し、それぞれの形態素の品詞等を判別する手法 |
| 構文解析 | 形態素に切分けさらにその間の関連や、構文論的な関係を図式化するなどして明確にする手法 |
| 意味解析 | 概念辞書等を用いて文章の意味を解釈する手法 |
| 文脈解析 | 複数の文のつながりをチェックする手法 |
日本語をコンピュータで処理する場合、基本となる技術に形態素解析がありますが
言語は日々刻々と変化し続けているのでコンピューターが対応するのは大変です。
人間は言語情報を完全に処理している訳ではなく、多数の解釈の中から妥当な解釈を行っているため
その妥当性をコンピュータに実装するのが難しいところになります。
意味解析以上のものになるとなかなか難しく、今後の研究が待たれるところです。
形態素解析について
形態素解析は形態素と呼ばれる最小単位の語句に文章を分かち書きし
それぞれの形態素の品詞等を判別する手法のことを言います。
分かち書き
英語のように言葉の区切りに空白を入れる書き方です。
ワタシ ガ ヘンタイ デス ワタシ ハ ド スケベ デス
英語の形態素解析
英語のように単語と単語の間がスペースで区切られる言語においては非常に簡単であり
英語の形態素解析の手順をまとめると以下のようになります。
1.文全体を小文字化し単語の位置により単語が区別されてしまうことを防ぐ
2.it's や don't 等の省略形を分割する(it's → it 's 、 don't → do n't)
3.文末のピリオドを前の単語と切り離す(Mr. などに使われる文末とは関係ないピリオドは切り離さない)
4.スペースで分割する
日本語の形態素解析
日本語は英語の場合と異なり、空白は余りなく、単語の切れ目が分かりません。
そのため専用の辞書を用いて辞書ベースで規則による分割を考える必要があります。
自前で形態素解析を行うのであれば、この分割のルールを自分で定めて実装する必要があります。
日本語の形態素解析に関してはいくつかのライブラリが開発されており
これを用いて形態素解析を行うのが一般的になっています。
代表的なライブラリだとMeCab(めかぶ)と言うものがあります。
Python言語ではjanomeと言うライブラリもあります。
こういったライブラリを用いて実装すれば、比較的簡単に形態素解析を主なうことができます。
ここら辺のライブラリの仕組みはこちらの記事で解説されています。
日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか
基本的な考えとしてはラティスを構築して最適なパスを選択すると言う考え方です。
ラティスとは考えられうる単語分割の解のことです。
下記がわかりやすい例かと思いますので参照させていただきます。
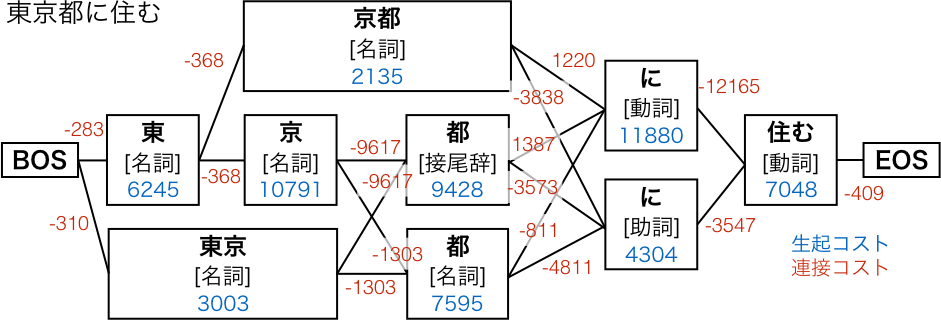
参考:https://techlife.cookpad.com/entry/2016/05/11/170000
これがラティスでこの中からコストを元に最適なパスを選んでいきます。
コストは形態素解析に用いられる辞書によって変わります。
一般的な形態素解析ではNAIST辞書と言うものが使われますが
この中に計算された生起コスト,連接コストの値が記載されており
そこからコーパス用のコスト値が計算されているようです。
このコスト値が一番低いパスを形態素解析の結果としているようです。
当然、この辞書に存在しなければ固有名詞などは通常の単語で分割されていく形になるため
正しく形態素解析を行うためには辞書の整備が不可欠になっています。
新しく作られた言葉のことを未知語と言ったりしますが、形態素解析を行う業務の中では
こう言った未知語への対応や辞書の整備が開発作業の工数の大半を占める形になってきます。
自然言語処理を扱う企業であれば、自前で大量の単語を登録した
データベースを構築して未知語への対応をしています。
構文解析について
構文解析とは係り受け解析とも言い、自然言語処理の技術の中の一種です。
文章を形態素に分けた後に、単語間の修飾関係を解析することになります。
有名なライブラリとしてCaboChaと言うものがあります。
余り長い文章を解析させるのには向いておらず、短めの文章で考えてあげる必要があります。
解析の結果はこんな感じになります。
一郎は二郎が作った穴に、北海道で購入したジャガイモを詰めた
一郎は-------------D
二郎が-D |
作った-D |
穴に、-------D
北海道で-D |
購入した-D |
ジャガイモを-D
詰めた
係り受け解析は文章の意味を解析したいときに使える技術で
文法的な構造を解析して文章の意味を解明していく際に使えるかなと思います。
自然言語処理でよく出てくる言葉
正規表現
いくつかの文字列を一つの形式で表現するための表現方法です。
大量の文章の中から、一定のルールに沿った処理を行う際によく用います。
詳しくはこちら
100日後にエンジニアになるキミ - 46日目 - プログラミング - 正規表現について
N-Gram
任意の文字列や文書を連続したn個の文字で分割するテキスト分割方法のことで
nが1の場合をユニグラム(uni-gram)2の場合をバイグラム(bi-gram)
3の場合をトライグラム(tri-gram)と呼んでいます。
文字ベースだと
# unigram
'今', '日', 'は', 'い', 'い', '天', '気'
# bigram
'今日', '日は', 'はい', 'いい', 'い天', '天気'
# trigram
'今日は', '日はい', 'はいい', 'いい天', 'い天気'
単語ベースだと、形態素解析した単語をn個連結した形になります。
# unigram
'今日', 'は', 'いい', '天気'
# bigram
'今日は', 'はいい', 'いい天気'
# trigram
'今日はいい', 'はいい天気'
単語ベクトル
文章を単語に分割した後に、表の列に単語を割り当ててデータ化したものです。
単語があれば1 , なければ0と言ったようなデータになります。
[1,0,0,0,0,0,1,1,1],
[1,0,0,0,0,0,1,1,0], ...
TF-IDF
tf-idfは文書中の単語に関する重みの一種で、情報検索や文章要約などの分野で利用されます。
単語ベクトルを元に計算が行われ、単語の希少性などを判断するのに使われます。
まとめ
自然言語処理はかなり難しい研究分野の一つですが研究が進んでいない分野は
逆にチャンスの多い分野でもあります。
日本語の研究は特に難しく、意味を解析したりする部分を実装するところは
非常に困難であるのでじっくりと腰を据えて研究に取り組む必要があります。
興味があれば自然言語処理を学んでみましょう。
君がエンジニアになるまであと34日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython