EMNLP2023に採択された論文を眺めていたところ、ある論文が目に止まりました。
「Discovering Universal Geometry in Embeddings with ICA」という論文です。
これは京大下平研の山際さんの論文で、ざっくりとサマると「Word EmbeddingなどのEmbeddingを独立成分分析(ICA)で次元削減することで、人間にとって解釈性の高い成分を取り出すことができる」という論文です。
Vision TransformerやBERTを用いた実験から、モーダルや言語に関わらず解釈性の高い表現が得られたという結果を得ています。
論文内では、文を対象としたEmbeddingであるText Embeddingには触れられていないですが、おそらくうまく動くだろうという見込みがあったため、本手法をText Embeddingに対して実行してみました、というのが本記事の内容です。
データセット
利用したデータは「景気ウォッチャー調査」です。
景気ウォッチャーとは、内閣府が毎月実施している「街角の景況感を判断するためのアンケート調査」を公開したデータで、下記のページで公開されています。
この調査結果は街角景気とも言われ、様々な業種の経営者や労働者にインタビューをして、3ヶ月前と比較した景気の現状や先行きについて評価をしてもらったというものです。
評価は「良い」「やや良い」「変わらない」「やや悪い」「悪い」の5段階評価に加え、その判断理由を表すテキストからなります。
そのため、このデータは客観的な指標ではなく日本で働く皆さんの「実感」に基づいた景気が反映されていると考えられます。
景気ウォッチャー調査は、以前にも要約された統計データを地図にマッピングする記事を書きましたが、今回は景気に対する主観的評価に対する判断理由のテキストを使います。
今回は2022年1月から2022年11月までのデータを集めて使いました。
データ例
景気の現状判断: ✗, ▲, □, ○, ◎
| 景気の現状判断 | 追加説明及び具体的状況の説明 |
|---|---|
| ▲ | 今シーズンに入り来店客の減少、客単価の減少が顕著となり、アパレルを筆頭に冬物商材の動きが鈍く、ほとんどのテナントが前年実績未達成の状況である。 |
| × | 新聞へ出稿する求人広告が一段と減少した。広告会社も新聞媒体は売れないといっている。 |
| □ | フルタイム希望の求職者は依然、僅少な傾向である。50代女性で週末就業のダブルワーク希望者は比較的多い。 |
| □ | 企業からの依頼が例年より少ない。相変わらず、求職者の申込みは少ない。 |
| ○ | 相変わらず、企業の求人数は増えており、年末年始の求人広告件数にも反映している。 |
| ▲ | 前年に比べ年末商戦は悪いとの報告が多い。 |
| □ | 以前と同じ報告になるが、人手不足というフレーズが全ての社長の共通テーマになっている。受注を増やすことはできるが、それをこなすことができないという形で、製造業と建設業の売上の伸び代が、人手不足のせいで落ちているという状況である。 |
| □ | 同業者に聞くところ、受注量が動いているという業者が半分ぐらいのため、変わらないと判断する。 |
| □ | 月間の求人数はほぼ同じである。 |
| □ | 小売業の取引先からは年末商戦もおおむね好調との報告が多い。一方、メーカーは資材価格の上昇と人件費の上昇がコストを押し上げ、利益率に影響を与えている事例が増えている。不動産は市の中心部であれば、相変わらず高値で引き合いがある。業界によってまだら模様の感がある。 |
OpenAIのAPIでテキストをEmbeddingに変換
今回は直近で公開されたOpenAIの「text-embedding-3-small」を使いました。
他にも性能の高い日本語Text Embeddingモデルはあります(名大武田・笹野研の塚越さんが公開しているTechnical Reportが詳しい)が、APIを叩くだけで楽に利用できる点と平均的に性能が高い点からOpenAIのEmbeddingを使いました。
サンプルコード
client = OpenAI() # 環境変数や引数などでAPI_KEYはセット
embeds_chunks = []
for i in tqdm(range(0, len(df), 1000)):
results = client.embeddings.create(
input=sents[i:i+1000],
model="text-embedding-3-small"
)
partial_embeds = [np.array(data.embedding, dtype=float) for data in results.data]
embeds_chunks.extend(partial_embeds)
embeds = np.stack(embeds_chunks)
del embeds_chunks
FastICAを使って独立成分を取り出す
# パラメータは論文内で指定されているものを参考にICAが収束したものを選択
ica = FastICA(n_components=n_components, random_state=42, max_iter=10000, tol=1e-3)
embeds_ica = ica.fit_transform(embeds)
df_ica = pd.DataFrame(embeds_ica)
skewness = skew(df_ica)
# 今回は正方向の独立成分を扱うため、歪度の大きい向きを正方向にしたい
# そこで、論文に従って歪度が負の軸を反転させている
df_ica *= np.sign(skewness)
df_ica.shape
>> (14818, 30)
df_icaの中身を最初から10件の文だけ選び、その最初から5つの次元を取り出したものが次の表です。
カラム名は成分の番号で、その値は独立成分スコアとなっています。
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| -0.124224 | 0.0685887 | -0.184686 | -0.195462 | -0.820685 |
| 0.925121 | -0.360944 | -0.602754 | -0.474337 | -0.19128 |
| -0.184668 | -0.246243 | -0.514242 | -1.37613 | -1.25874 |
| 0.111601 | 0.69712 | -0.395694 | -1.05832 | -0.153647 |
| -0.779398 | -0.75955 | -0.132822 | 2.10606 | -0.000313469 |
| -0.411627 | -0.231666 | -1.23247 | -0.705456 | 0.44361 |
| -0.446516 | -0.405586 | -1.3468 | 0.98856 | -0.215902 |
| -0.287723 | 0.650714 | -1.18879 | -0.213838 | 2.24953 |
| 0.0341046 | -2.17743 | -0.795595 | -1.084 | -1.14249 |
| 2.91212 | -0.774048 | 1.69052 | 2.94867 | 0.20269 |
しかし、これではわかりにくいのでplotlyを使ってstripplotしちゃいましょう。
df_ica_ = pd.melt(df_ica, var_name="Component", value_name="Value", ignore_index=False).reset_index()
df_ica_["sentence"] = df_ica_["index"].apply(lambda i: sents[i])
px.strip(df_ica_, x="Component", y="Value", color="Component", title="ICA components of the sentences", hover_data=["sentence"])
実際にstripplotすると以下のような図が表示されます。
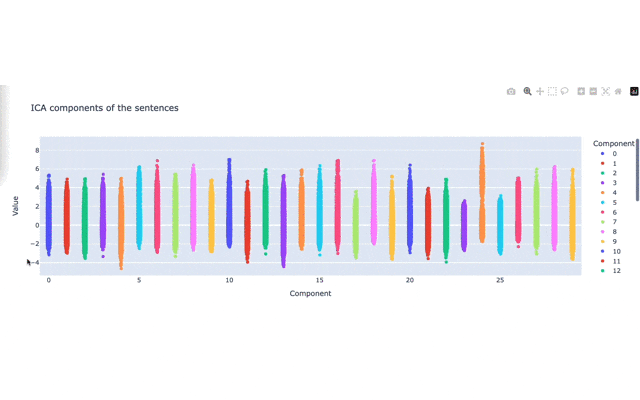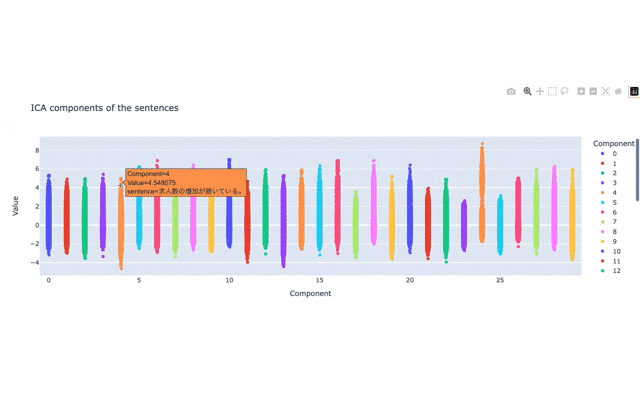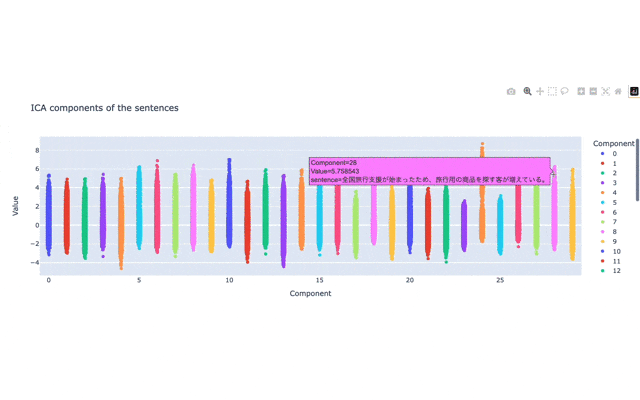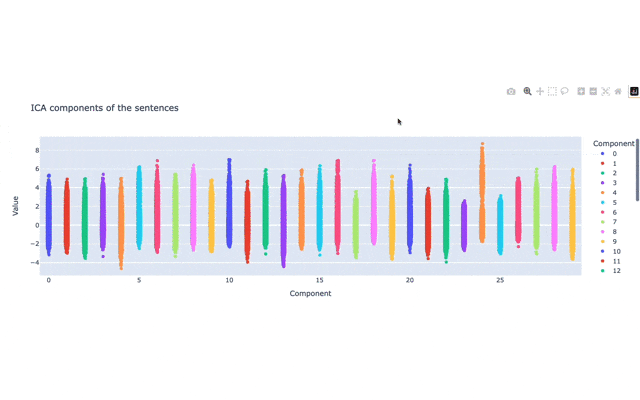
(gif動画で小さい画像になっていてすみません...。ちなみに結構重たいです。)
plotされた縦長の点の集合それぞれがICAの軸になっています。
基本的にはこの縦長の点の集合の両端(上と下の端)に位置している言葉が、それぞれの軸の意味を強く表現しているテキストとなります。
例えば、1つ目の次元では物価上昇に関する表現がスコアの上位に多かったです。
他にも25番目の次元で高いスコアになっているのはウクライナ侵攻による影響についてのコメントのようです。
stripplotを見るだけでも様々な示唆が得られると思いますが、これを応用してみましょう。
ここからは3月に開催するNLP2024で私が発表する論文の内容と近いので、興味がある方はぜひ見に来てください...!
独立成分のカテゴリデータ化
このように探索的な分析をする場合、「独立成分が表現している意味にマッチした文がどれくらいあるか」を成分ごとにカウント・集計し、それらを比較できると非常に便利そうです。
そこで、得られた独立成分をカテゴリ変数に変換するということを考えます。
前節でプロットされている独立成分スコアは、それぞれの成分毎に全文章へ割り当てられています。
そして、独立成分スコアはスコアの絶対値が大きいほど、その成分が表現しているであろう意味に近い文章となっています。
例えば、次の図は今回の実験の中で0番目の独立成分を取り出してスコア順にソートしたものですが、独立成分の高いものは「消費意欲減退」に関するトピックを持った文が集まっています。
一方で、0に近いほどそのトピックが表現している意味から遠い様々な文章が集まっています。
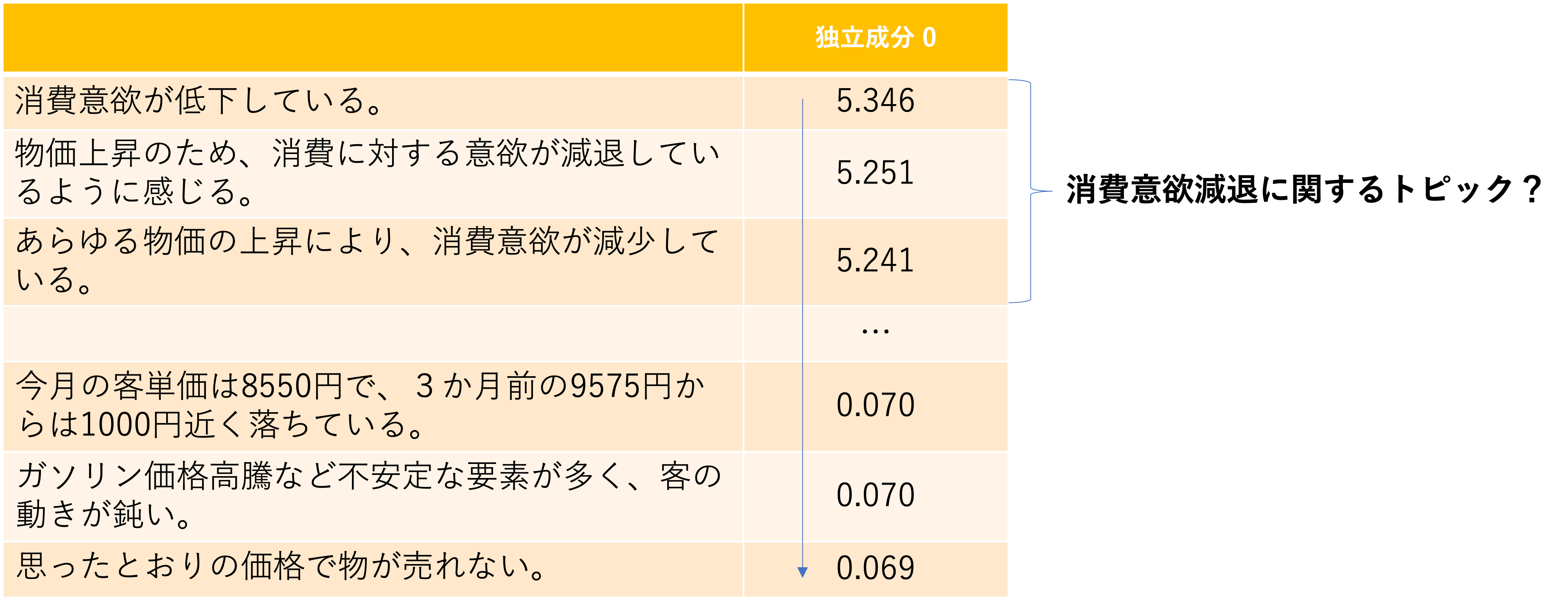
この性質を利用してスコアの高い文をその成分が表現している意味を持っているとして「1」、そうでない文章に「0」を割り当てることで、その成分をカテゴリ変数に変換できるのではないかと考えました。
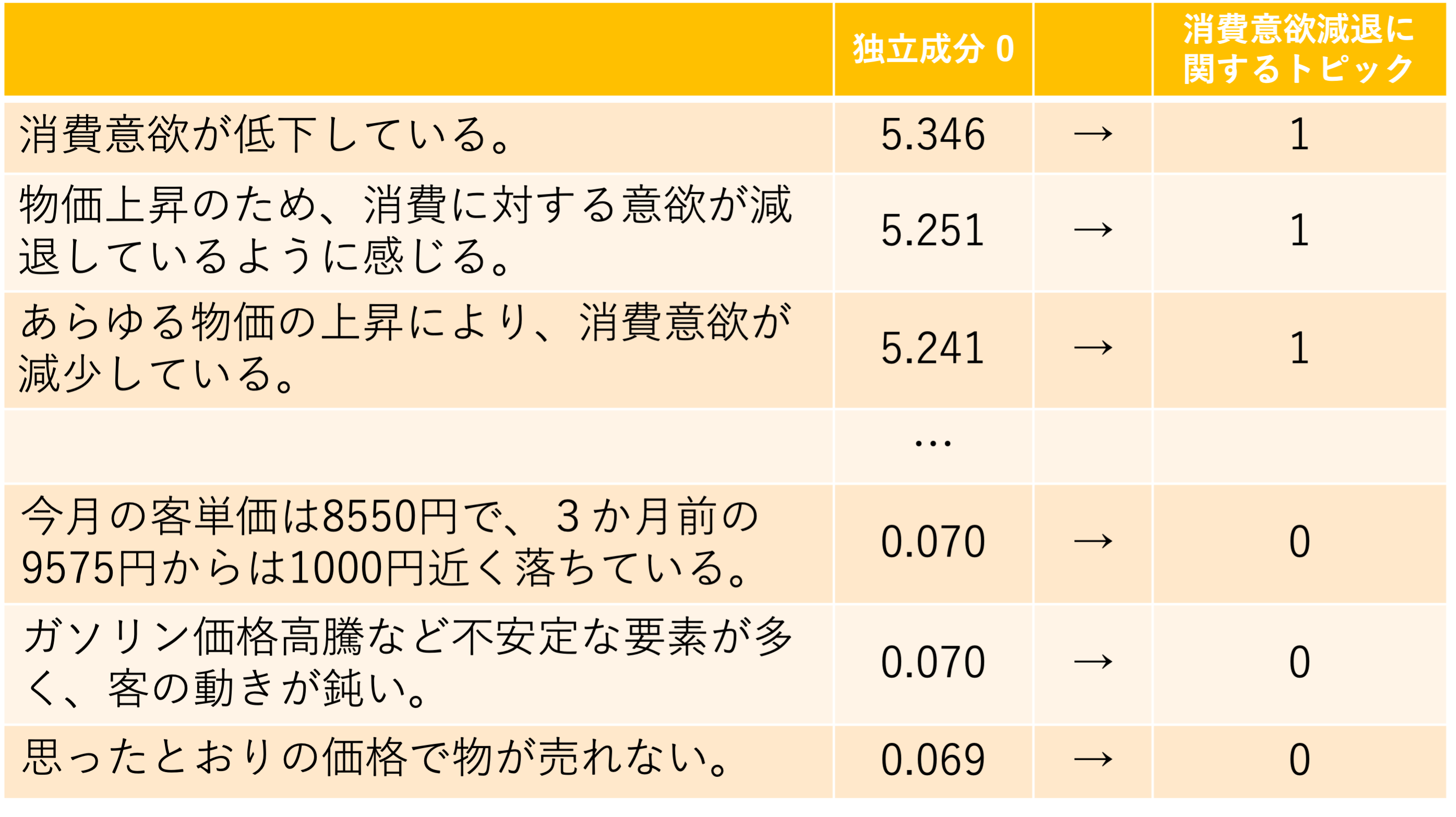
そして、独立成分ごとにがスコアが2.0以上のものをカテゴリに割り当てると考えたときの図が以下です。
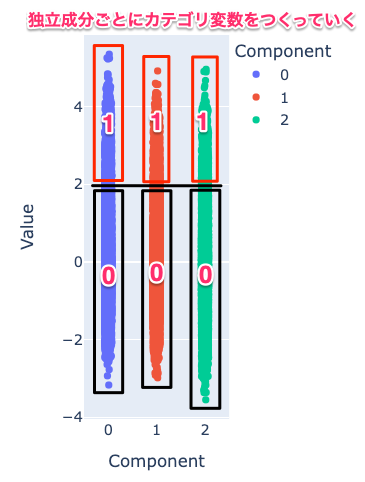
簡単のため山際さんの論文に従って負側の成分は無視しています。
(負側を無視するにあたって、分布の歪度を計算して負側に偏ってる独立成分を反転させることで、正方向に独立成分が大きくなるようにしています。)
この手法の問題点は、独立成分スコアを2.0という決め打ちの閾値でカテゴリ変数に変換してしまうため、個々の独立成分のスコア分布を考慮できなかったり、Embeddingがたまたま近くなってしまって含まれているが人間の解釈上では邪魔なノイズが含まれていたりします。
そこで、GPT-3.5のAPIを使って、以下のプロンプトとコードによってカテゴリ化される文章をクリーニングしてしまいます。
処理の内容はざっと説明すると、「独立スコアが最も高い10件の文を正解例としたときに、残りの文はその正解に当てはまるのか?を分類させた」というものです。
import re
import json
from tenacity import retry, stop_after_attempt, wait_random_exponential
# 与えられた正解例から分類基準を推測させて、入力文がそれに当てはまるかを推測させる
# バッチで文を処理できるように出力はJSON形式で返すようにする
prompt = """Please, assign a classification label to each sentence by inferring the classification criteria from the following sample of sentences.
Be sure to return the result in a single JSON format.
If the sentence fits the classification criteria, the label is 1; if not, it is 0.
Model Answer Sentences:
{pos_sents}
Please, discover the classification criteria for the sample sentences and assign labels to each sentence..
Answer Sample:
{{
"criteria": "[分類基準の簡潔な要約(トピック名); MUST BRIEFLY JAPANESE TOPIC NAME]",
"results": [{{"id": 1, "label": 0}},{{"id": 2, "label": 1}}, ...]
}}
Input Sentences::
{input_sents}"""
def generate_prompt(ps_sents, input_sents, input_idxes):
return prompt.format(pos_sents="\n".join(ps_sents), input_sents="\n".join([f"{i}. {sent}" for i, sent in zip(input_idxes, input_sents)]))
@retry(stop=stop_after_attempt(7), wait=wait_random_exponential(multiplier=1, max=60))
def completion_with_retry(prompt, criteria):
if criteria:
assistant_message = f'{{\n "criteria": "{criteria}",\n'
else:
assistant_message = "{\n "
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": prompt
},
{
"role": "assistant",
"content": assistant_message
}
],
temperature=0.0, # 出力結果をぶらさないためにはここが重要
model='gpt-3.5-turbo' # 4のほうがよいが微妙に高くつく
)
return assistant_message + chat_completion.choices[0].message.content
def classify_sentences(ps_sents, input_sents, input_idxes, criteria):
prompt = generate_prompt(ps_sents, input_sents, input_idxes)
message = completion_with_retry(prompt, criteria)
# JSON形式で返させてるので結果をパースする
pattern = re.compile(r"^```json\n(\{.+\})\n```$", re.DOTALL)
match = re.search(pattern, message)
if match is not None:
json_str = match.groups()[0]
else:
json_str = message
return json.loads(json_str)
N_START_SENTS = 10 # 正解例の数
N_ITER_SENTS = 15
component2labels = {}
for i in range(n_components):
print(f"Processing Component {i}")
# スコアが高い順に並べ替えてindexを取得する
ps_indexes = df_ica.sort_values(by=i, ascending=False).index[:len(df_ica[(df_ica >= 2.0)[0]])]
ps_sents = sents[ps_indexes[:N_START_SENTS]]
component2labels[i] = {"criteria": None, "results": []}
criteria = None
for j in range(N_START_SENTS, len(ps_indexes), N_ITER_SENTS):
input_sents = sents[ps_indexes[j:j+N_ITER_SENTS]]
input_idxes = ps_indexes[j:j+N_ITER_SENTS]
results = classify_sentences(ps_sents, input_sents, input_idxes, criteria)
criteria = results["criteria"]
if component2labels[i]["criteria"] is None:
component2labels[i]["criteria"] = criteria
component2labels[i]["results"].extend(results["results"])
# APIの実行回数を減らすために、入力文の半分より大きい数がラベルに当てはまらなくなったら打ち切り
labels = [r["label"] for r in results["results"]]
if (sum(labels) / len(labels)) < 0.5:
break
その結果、得られたカテゴリ名とそのカテゴリに属する文数が以下となりました。
| 分類基準(カテゴリ名) | 文数 |
|---|---|
| 物価上昇による消費意欲の影響 | 150 |
| 来客数の減少に関する要素 | 611 |
| 街の人出の増減と活気の回復 | 41 |
| 原材料価格や燃料価格の高騰によるコスト増 | 539 |
| 状況の厳しさ | 35 |
| 建築資材価格の高騰と納期の遅延に関する影響 | 115 |
| イベントの復活と関連する要素 | 92 |
| 半導体不足による生産影響 | 245 |
| 新車の納期遅延に関する情報 | 146 |
| 年末年始/夏休み/ゴールデンウィーク/お盆期間の人の動き | 111 |
| 変化の有無 | 70 |
| 公共工事の受注状況 | 11 |
| 売上の増減 | 33 |
| 新型コロナウイルスオミクロン株の感染拡大の影響 | 436 |
| 景気の良くなる話が出てこない | 13 |
| 人の動きの変化に関する分類基準 | 34 |
| 受注量の増減に関する情報 | 17 |
| 来客数の回復 | 89 |
| まん延防止等重点措置の影響に関する分類 | 191 |
| 新型コロナウイルス感染拡大の影響に関する分類 | 29 |
| 売上や求人数の変化に関する比較 | 28 |
| コロナ禍からの回復の状況 | 518 |
| 来客数の増加 | 430 |
| 新型コロナウイルス感染症の影響による受注量の変化 | 14 |
| ウクライナ情勢による影響の有無 | 402 |
| 売上の動きに関する分類 | 12 |
| 求人数と求職者数の動向に基づく分類 | 26 |
| 飲食店の客足の戻り具合 | 16 |
| 全国旅行支援の効果に関する情報 | 231 |
| 顧客の来店や購買意欲の低下 | 63 |
文数は初期値の10件を足しています。
そのため、文数が11件程度の「公共工事の受注状況」は初期値以外に1つしか当てはまらなかったということを示しています。これは、最初の10件とそれ以降の傾向が若干違っていたため、細かい単位で抽象化されてしまったという可能性がありそうです。
逆に539件の「原材料価格や燃料価格の高騰によるコスト増」は、スコアを2.0を閾値にしてフィルタしたときに得られた多くの文章が当てはまっていたと言えます。
また、「状況の厳しさ」や「変化の有無」といった抽象的すぎてなにも言ってないような気がするトピック名もあったりしました...。
これはプロンプトをいじったり正解例の数を調整したりすれば解決されるかもしれませんね。
集計データを活用する
以上の集計データからも、ある程度の示唆は得られると思われますが、これを使ってさらなる分析をしてみます。
ここでいきなり新情報が入ってくるのですが、景気ウォッチャー調査には回答が収集された地域、あるいは回答者の業種や職種が含まれています。
そこで、このような属性データを使って前述のデータを地域ごとに集計をしてみましょう。
ちょっと長くなってしまいますが、集計結果がこちらです。
| criteria | 北海道 | 東北 | 南関東 | 北関東 | 東海 | 甲信越 | 北陸 | 近畿 | 中国 | 四国 | 九州 | 沖縄 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| まん延防止等重点措置の影響に関する分類 | 10 | 1 | 35 | 8 | 27 | 4 | 6 | 23 | 32 | 14 | 15 | 6 |
| イベントの復活と関連する要素 | 2 | 8 | 22 | 6 | 6 | 6 | 2 | 7 | 6 | 3 | 12 | 2 |
| ウクライナ情勢による影響の有無 | 23 | 36 | 54 | 21 | 52 | 15 | 22 | 60 | 33 | 25 | 47 | 4 |
| コロナ禍からの回復の状況 | 13 | 46 | 90 | 25 | 46 | 11 | 29 | 78 | 65 | 31 | 60 | 14 |
| 人の動きの変化に関する分類基準 | 2 | 3 | 1 | 2 | 5 | 0 | 0 | 7 | 3 | 0 | 1 | 0 |
| 全国旅行支援の効果に関する情報 | 22 | 26 | 15 | 15 | 29 | 16 | 15 | 24 | 18 | 11 | 25 | 5 |
| 公共工事の受注状況 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 半導体不足による生産影響 | 3 | 9 | 43 | 15 | 47 | 11 | 9 | 40 | 29 | 10 | 19 | 0 |
| 原材料価格や燃料価格の高騰によるコスト増 | 27 | 52 | 91 | 32 | 80 | 23 | 32 | 77 | 35 | 28 | 48 | 4 |
| 受注量の増減に関する情報 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 1 | 0 |
| 売上の動きに関する分類 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 |
| 売上の増減 | 0 | 1 | 3 | 1 | 2 | 2 | 4 | 4 | 0 | 1 | 2 | 3 |
| 売上や求人数の変化に関する比較 | 0 | 1 | 1 | 1 | 5 | 1 | 1 | 3 | 2 | 0 | 3 | 0 |
| 変化の有無 | 3 | 6 | 11 | 4 | 9 | 0 | 11 | 3 | 5 | 5 | 3 | 0 |
| 年末年始/夏休み/ゴールデンウィーク/お盆期間の人の動き | 5 | 9 | 20 | 3 | 13 | 2 | 5 | 13 | 8 | 9 | 12 | 2 |
| 建築資材価格の高騰と納期の遅延に関する影響 | 7 | 9 | 8 | 4 | 19 | 3 | 5 | 19 | 18 | 2 | 5 | 6 |
| 新型コロナウイルスオミクロン株の感染拡大の影響 | 17 | 35 | 80 | 27 | 51 | 24 | 26 | 62 | 28 | 18 | 52 | 6 |
| 新型コロナウイルス感染拡大の影響に関する分類 | 1 | 2 | 5 | 1 | 4 | 1 | 0 | 2 | 0 | 2 | 0 | 1 |
| 新型コロナウイルス感染症の影響による受注量の変化 | 0 | 0 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 新車の納期遅延に関する情報 | 15 | 8 | 28 | 6 | 26 | 15 | 7 | 6 | 4 | 8 | 13 | 0 |
| 景気の良くなる話が出てこない | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 |
| 来客数の回復 | 2 | 10 | 4 | 3 | 8 | 2 | 6 | 13 | 11 | 6 | 13 | 1 |
| 来客数の増加 | 18 | 41 | 68 | 23 | 37 | 25 | 13 | 56 | 47 | 28 | 42 | 22 |
| 来客数の減少に関する要素 | 14 | 53 | 97 | 18 | 76 | 27 | 34 | 66 | 100 | 39 | 65 | 12 |
| 求人数と求職者数の動向に基づく分類 | 2 | 0 | 3 | 0 | 5 | 0 | 0 | 1 | 1 | 0 | 3 | 1 |
| 物価上昇による消費意欲の影響 | 7 | 17 | 26 | 4 | 13 | 0 | 13 | 28 | 13 | 5 | 9 | 5 |
| 状況の厳しさ | 2 | 1 | 3 | 1 | 5 | 3 | 0 | 3 | 4 | 2 | 0 | 1 |
| 街の人出の増減と活気の回復 | 3 | 2 | 1 | 1 | 2 | 0 | 2 | 3 | 4 | 6 | 5 | 2 |
| 顧客の来店や購買意欲の低下 | 1 | 2 | 11 | 2 | 13 | 2 | 4 | 8 | 8 | 1 | 1 | 0 |
| 飲食店の客足の戻り具合 | 1 | 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
このようなカウントデータに変換できれば、地図にプロットしてみるということもできそうです。
さらに、これらのデータを使って因子分析や対応分析を実行してみる、といったことができそうです。
試しに因子分析をやってみましょう。
因子分析はある多変量のデータの間でN個の共通要因があると仮定して、その共通因子はなんのかを数値化するという分析手法です。
Factorの数はスクリープロットによってFactorの分散の大きさを考慮して2を選択しました。
つまり、上記の集計結果の中に共通因子が2つあるとしたら、それぞれはどんなもの?ということを分析してみました。
Factorが2つあるため、これをそれぞれX軸・Y軸にプロットしてみます。
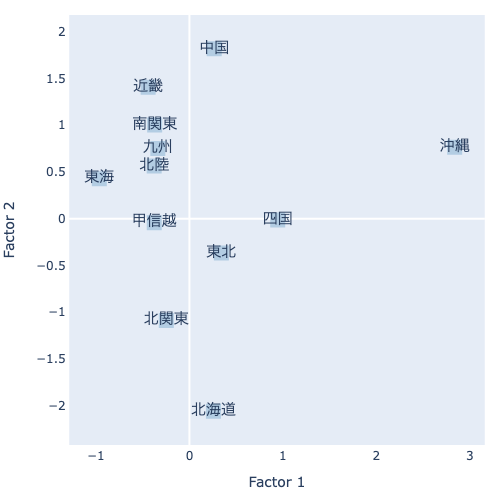
この結果を読み取ると、Factor 1(X軸)では、正方向に沖縄が来ています。一方で、負方向には東海があり、それに続いて南関東や近畿などの他の地方が負側にくるようです。
一方で、Factor 2(Y軸)では、北海道と沖縄・近畿が対局の位置にあります。一部を除けば、なぜか東日本と西日本に分かれているような傾向を感じます。
それでは、それぞれの軸の意味を調べてみましょう。
因子分析では、そのFactorはどの変数の影響が強いのかを因子負荷量によって表現でき、これによってFactorがどのようなものなのかを解釈することができます。
Factor 1の因子負荷量はこちらです。
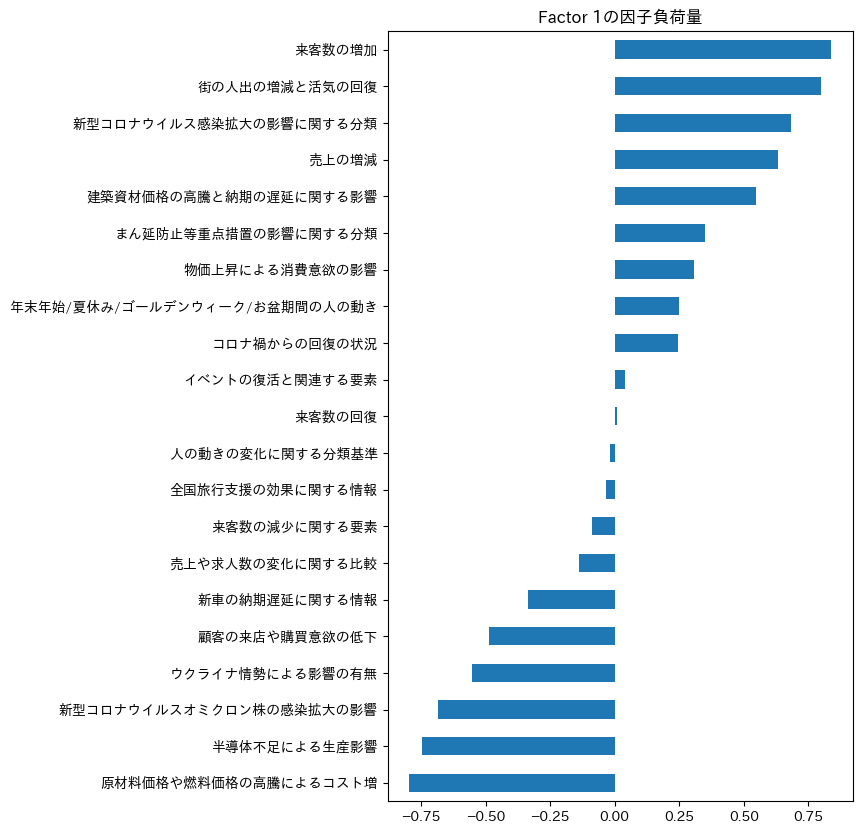
Factor 1をなんとか読み取ると、正方向にはサービス業に関するトピックが集まっているように見えます。一方で、負方向には製造業に関するトピックが強く出ていそうに見えます。
つまり、この軸はサービス業の強い地域なのか、製造業の強い地域なのかを表している軸になっているのかもしれません
また、Factor 2の因子負荷量はこちらです。
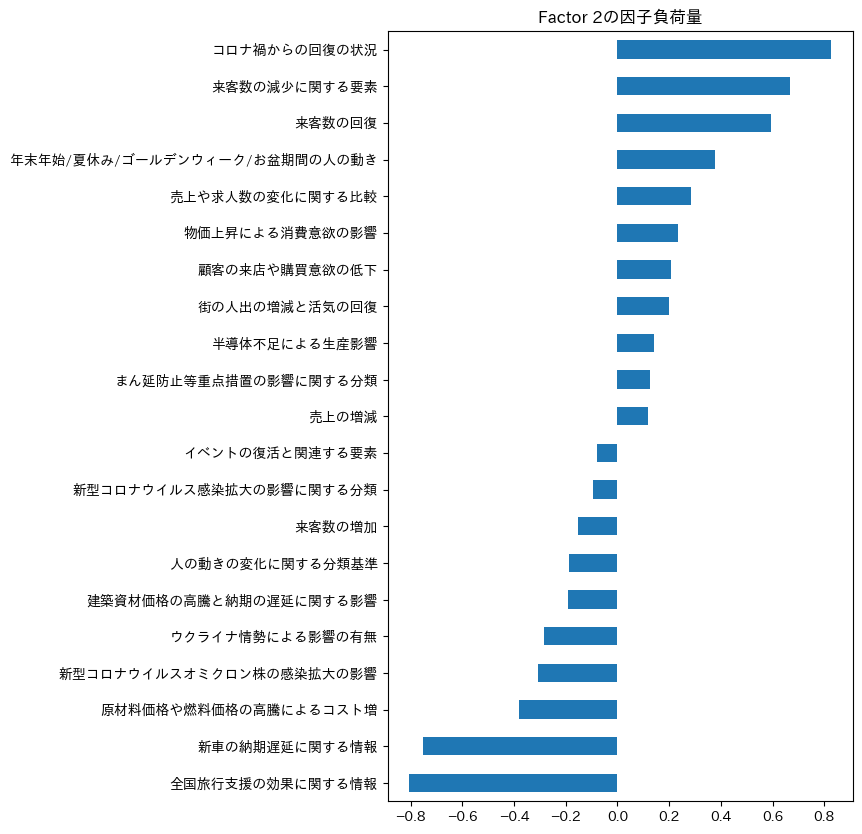
Factor 2は解釈が難しい結果になっているように見えます。
類似しているトピックが両側に集まっており、業種で分かれているわけではなさそうです。
東西の違いやあるいは人口分布などの何らかの地域的な特徴があるのかもしれません。
ICAに対する入力文を絞り込んだり、対象とするトピックを絞ったり、あるいは因子分析のパラメータを調整したりすることで人間の感覚でより解釈しやすい軸が取れるかもしれません。
以上が本手法の実用例でした。
ちなみに、NLP2024の論文では対応分析を試してみています。
気になる方はNLP2024の3/12(火) 11:15-12:45のセッションで、Pb会場: 504+505 (5F)にてポスター発表をするので来てください!

↓大会プログラムはこちら
https://www.anlp.jp/proceedings/annual_meeting/2024/
終わりに
いかがでしたでしょうか。
本手法はアンケート分析において、自由解答欄を「コード化」する流れを自動的にやってしまおうということも意図しており、様々なテキスト解析に対して応用できるものとなっていると思います。
特にアンケート分析やインタビュー結果をコード化していく作業には多大な労力がかかることも多いと思います。
そのようなテキストでは、自由回答の話題も似通っている傾向があることから、今回の分析結果よりも解釈しやすいものとなる可能性が高そうです。
アンケート結果に紐づく属性データや顧客セグメントの情報を用いることで、より顧客の解像度を上げるのに応用していただけたらと思います。