はじめに
株式会社オプティマインドでインフラを担当している山口です。
今回は私の大好きなdatadogについて社内向けに情報をまとめる機会があったので、ついでに記事にしてみました。
datadogとは?
簡単に紹介すると、AWSやGCPなどのクラウドプロバイダ上のリソースをモニタリングできるサービスで、インフラからアプリケーションまで、あらゆるレイヤーをモニタリング出来ます。
対応していないサービスを探す方が難しいくらい、インテグレーション(サービスとの接続)が充実してます。
その他特徴として、メトリクス、APM、ログを統合的にモニタリング可能で、例えば、プログラムのエラーログ発生日時からサーバの負荷状況やプログラムのレスポンス速度などを簡単に分析できます。
なお、オンプレでもエージェントをインストールする事で問題なく利用できます。
特徴
先ほどdatadogはモニタリングサービスだと紹介しましたが、中でもサービスを監視する事に特化しており、例えば
- サーバのCPU使用率が閾値を超えた
- 設定した条件にマッチするログが出力された
- API監視の結果がステータスコードが200以外だった
などの様々なパターンで監視及び通知ができます。
通知のインテグレーションも充実しており、AWSのSNSにメッセージをパブリッシュする、slackの特定のチャンネルにメンションを飛ばすなど大体なんでも出来ます。
弊社では緊急性が低い障害はslackで、高い場合は Datadog -> SNS -> lambda -> AmazonConnect というフローで担当者に電話を掛けるといった使い分けをしております。
良いところ
ここから本題になります。
Terraformに対応している
インフラ管理にinfrastructure as codeを必須としている会社は重要なポイントになると思いますが、datadog内のほぼ全てのサービスがTerraformに対応しています。
もっと言うと、一番最初に設定するクラウドプロバイダとのインテグレーションも管理できるので、開発環境では利用しない、ステージング環境ではこのサービスだけ利用する、本番環境では全て利用するといった設定も全てgitで管理出来ます。
インストールが簡単
Terraformのところでも触れましたが、最初に行うクラウドプロバイダとの連携も、必要最低限のIAMを作成して数クリックするだけで終わってしまうので、とにかく簡単です。
また、kubernetesのメトリクスやログを収集する際はDaemonsetとして動かしますが、昔は手間だったその辺りの設定も数年前からhelmに対応したので、こんな感じにTerraformで管理出来ます。
設定例
# Terraform v0.12.26
data "aws_s3_bucket_object" "datadog_config" {
bucket = "バケット名"
key = "バケットのパス/${terraform.workspace}/values.text"
}
resource "helm_release" "datadog_agent" {
count = var.dd_enabled[terraform.workspace]
name = "datadog-monitoring"
chart = "datadog/datadog"
namespace = "default"
values = [
data.aws_s3_bucket_object.datadog_config.body
]
set {
name = "datadog.apiKey"
value = var.DD_API_KEY
}
set {
name = "datadog.appKey"
value = var.DD_APP_KEY
}
}
ちなみに、弊社では以下のエージェント構成ファイルをs3で管理しており、そちらをapply時に読み込ませるようにしてます。
https://github.com/DataDog/datadog-agent/blob/master/pkg/config/config_template.yaml
強力なログ分析
ログはElasticSearchと同等の操作が可能で、とにかく検索が早いです。
またインデックスの指定もボタン一つ簡単かつ直感的に出来ます。
更に、ログをリスト表示するだけでなく簡単なグラフ化も可能です。

例えば、このようにリストで出すと傾向が掴みづらいログでも、
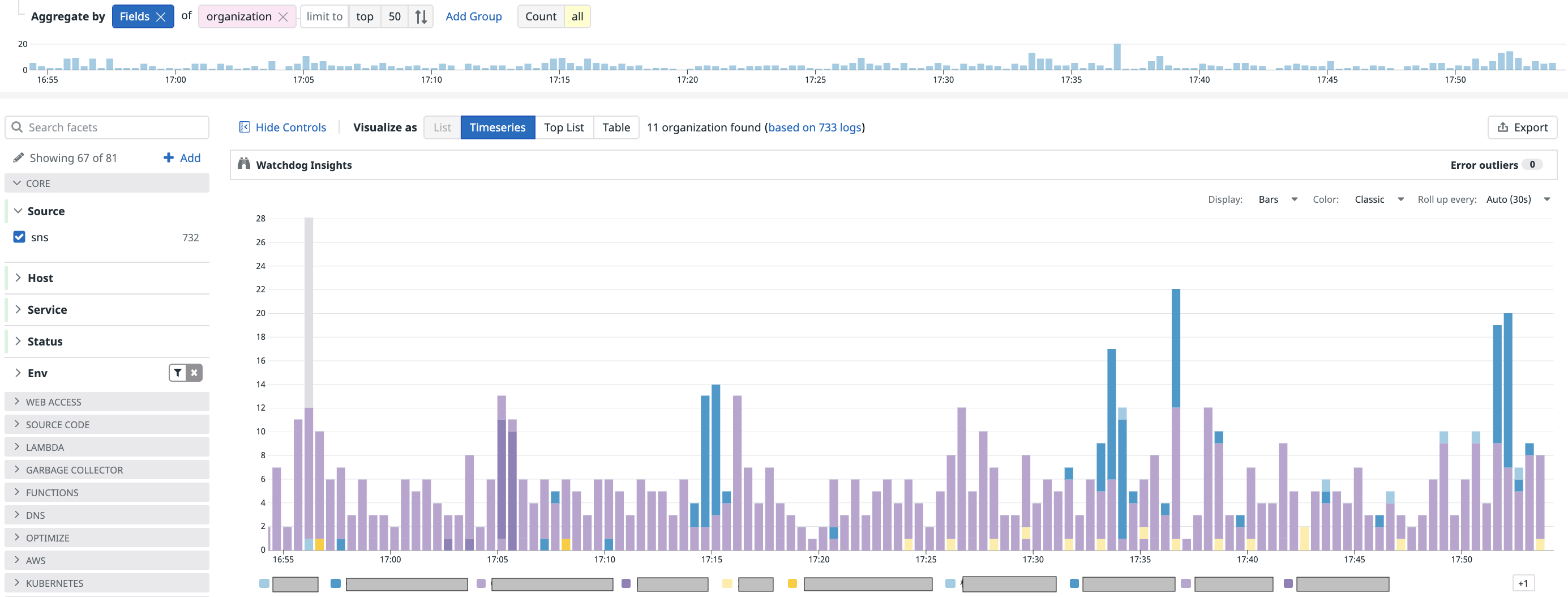
ボタン一つで即座にグラフ化して、様々な角度から分析できます。
また、特定のカラムのテキストを分解して、別のカラムとしてインデックスさせる事もできます。
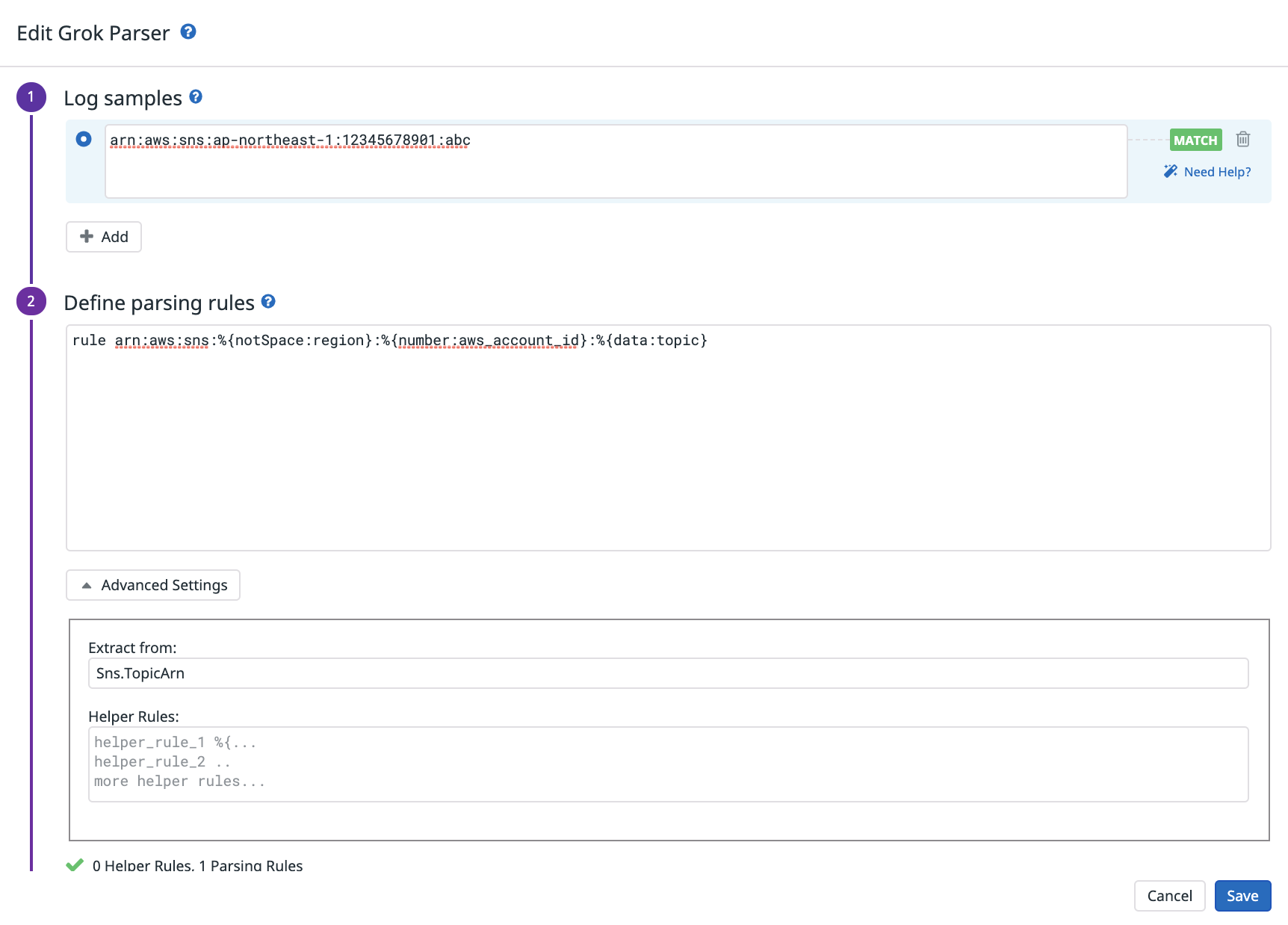
こちらはSNSのARNをリージョン、AWSアカウント、トピック名に分割する例ですが、こちらのGrok Parserのルールを適用するだけで簡単に実現できます。
具体的にparseするための記述方法はこちらに分かりやすくまとまっています。
https://docs.datadoghq.com/ja/logs/processing/parsing/?tab=matcher
これ以外にも優れている機能は沢山ありますが、書ききれないのでこれくらいで。
超柔軟なダッシュボード
いくらメトリクスやログの収集が出来ても、それを表現できるダッシュボードが使いづらいと意味がないです。
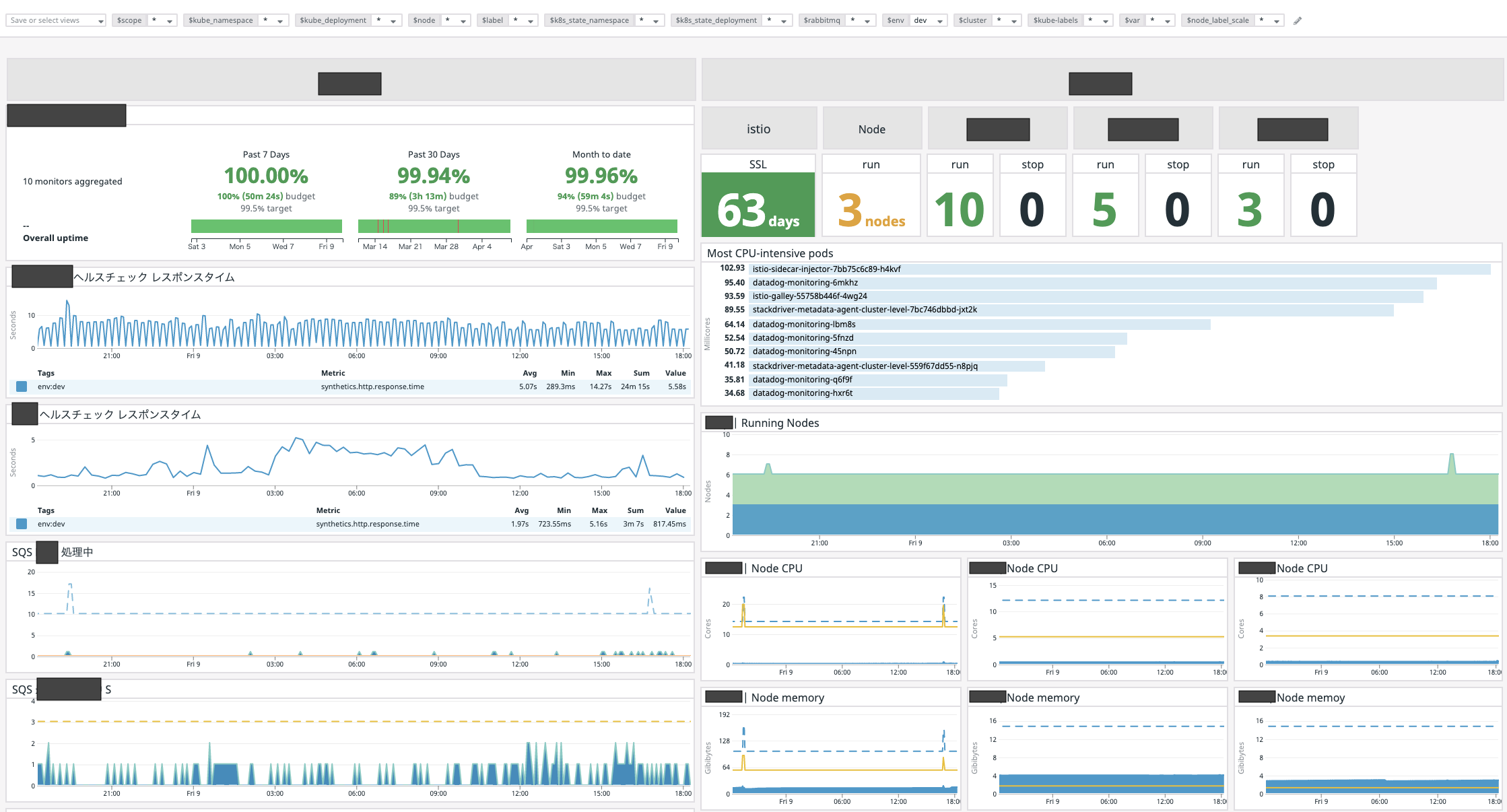
こちらは弊社がメインで使っているダッシュボードですが、これだけみても分かるように、多種多様なウィジェットを配置する事が出来ます。
画面で見えている範囲内だけでも、SLO、ヘルスチェックのレスポンス応答時間、istioのSSL証明書の有効期限、起動しているノード数、SQSのメッセージ数、kubernetes内のPodの起動数及びリソース量を確認する事が出来ます。
弊社のサービスは処理を分散させるために様々なところでキューを使っており、それらの状態を監視するのが運用の肝となりますが、問題なく運用できております。
(ただし標準のSQSインテグレーションだと更新頻度が遅すぎて使えないので、カスタムメトリクスを使用しています)
しかも、これらの全てのデータソースがdatadog内で一元管理できているというお手軽さ。
ダッシュボードはBIツールとしても使えるくらい完成度が高いと思っています。
悪いところ
個人的に思うのは一つだけです。
料金が高い
料金体系はかなり細かいので、詳細は営業さんに確認して頂ければ思いますが、監視するサーバ台数が100台を超えるような規模だと、一ヶ月あたり二桁万円では収まらないのではと思います。
また、弊社はまだAPMを本格導入していないですが、そちらもかなり高額なのでしっかりとしたサイジングが必要になるかと思います。
ただ結局は、金額の高さ=サービスに自信がある だと思っており、実際に利用していてそれだけの価値はあると感じてます。
まとめ
datadogは素晴らしいサービスです。
今後も私がクラウドで新規サービスを立ち上げる際は必ず導入すると思います。
ただし、競合となるNewRelicやElasticSearch (Elastic Stack)も同じようなコンセプトになりつつあると感じております。
そのため、今後は各社サービスの動向をキャッチアップしつつ、それぞれの強みと自社に合ったサービスを選定するのが重要ではと思います。