はじめに
何番煎じか分かりませんが、TensorFlow+Kerasを使ってオススメの楽曲名を類推するWebアプリ
を作ったときの話です。
2019年後半頃に趣味で作り、放置状態になってました。勿体ないので自分用に整理した記事です(備忘録)。
自分用に作った記事なので、分かりにくい点や情報、技術が古いかもしれませんがご了承ください![]()
また何かしらのWebアプリを独りで作りたい方のご参考になれば嬉しいです。
実装苦労しましたがfw、libのお陰でなんとか動きました。。。動くだけです![]()
TensorFlow、Kerasについては、@Suguru_Toyohara さんの記事が分かり易いのでご存知ない方は
こちらをお読み頂ければと思います。$\tiny{※参考にさせて頂きました。ありがとうございました}$![]()
Re:ゼロから始めるTensorFlow2.0
以下引用です。
TensorFlow:GoogleがDeepLearning用に開発していたフレームワークをOpen Source化した
機械学習全般をカバーするフレームワーク
Keras:難しかったTensorFlowでのモデル作成を簡単なものにするフレームワーク
実物は以下のGIFのようになります。
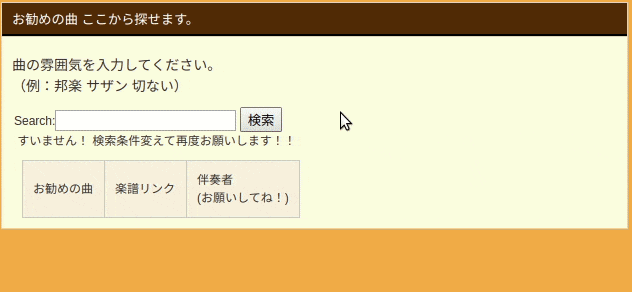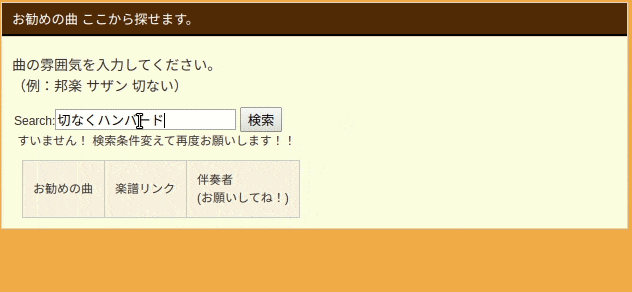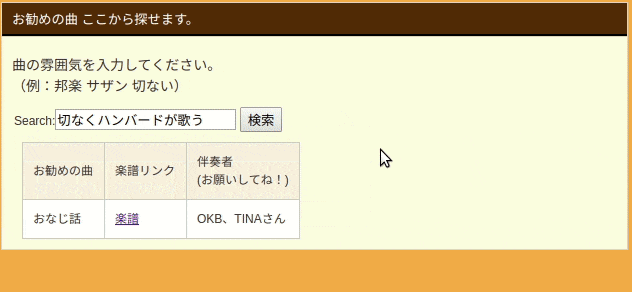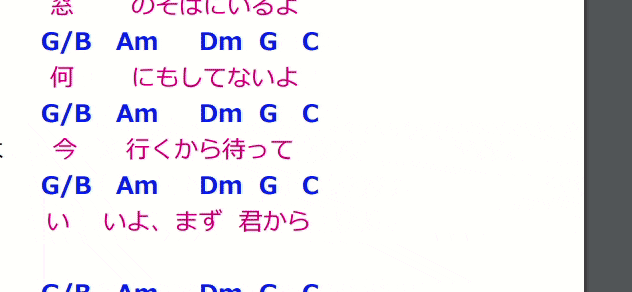
検索ボックスに文章で入力すると、ハンバード・ハンバードさんの「同じ話」と言う回答頂きました![]()
$\tiny{※学習データが少ないため、一部の曲しかヒットしません。。しょぼいです}$![]()
$\tiny{※楽譜リンクをクリックすると楽譜の一部が表示されていますが、記事の対象外です}$![]()
TODO マップ
今回はアプリの概要です。
| 章 | 区分 | 状況 | 内容 | 言語、FW、環境等 |
|---|---|---|---|---|
| 序 章 | 共通 | 済 | (今回)アプリの概要 | Python TensorFlow Keras Google Colaboratory |
| 第一章 | Web API | 済 | 環境構築(実行環境) | docker-compose Flask Nginx gunicorn |
| 第二章 | Web API | 済 | 機械学習 | Python TensorFlow Keras Flask |
| 第三章 | 画面 | 未着手 | 環境構築 | Python Django Nginx gunicorn PostgreSQL virtualenv |
| 第四章 | 画面 | 未着手 | 表示、Web API呼出し部分 | Python Django |
| 第五章 | AWS | 未着手 | AWS自動デプロイ | Github EC2 CodeDeploy CodePipeline |
| ※まだ記事は全然整理できていないので時間ある時につくります。 | ||||
| 未着手のまま命尽きるかも |
||||
| またマップは書いてるうちに変わる可能性ありますのでご了承下さい。。 |
このテーマのゴール(目的?)
- ミニマム:アプリ作成時の手順、詰まった箇所をアウトライン化する。
- フル:現状のアプリに何かしら新しめの技術を取り入れて改善する(まだ決まっていません
 )。
)。
長くなってしまいそうなので今回は環境までです。。。
対象読者:
- 機械学習には興味はあるが、どんな事に応用できるのか参考にしたい人
- 何らかの言語でWEBアプリをなんとなく作ったこと又は知見がある人
- ネットや書籍を参考に環境作ったり、コードをなんとなくでも読める人
アプリの概要
上記のGIFのように検索ボックスに曲の雰囲気、アーティスト名等の情報を入力します。
オススメの曲が表示されます。$\tiny{※現状は一曲のみです}$
画面側の処理フロー
ユーザが曲の雰囲気等入力するとオススメ曲を画面に表示します。表示するまでの流れは以下となります。
赤枠部分がメインのところで、TensorFlowで実装した自作のWeb API呼出しています。
**このAPIの中でオススメ曲を類推してます。**次でWeb APIの処理フローについて説明します。
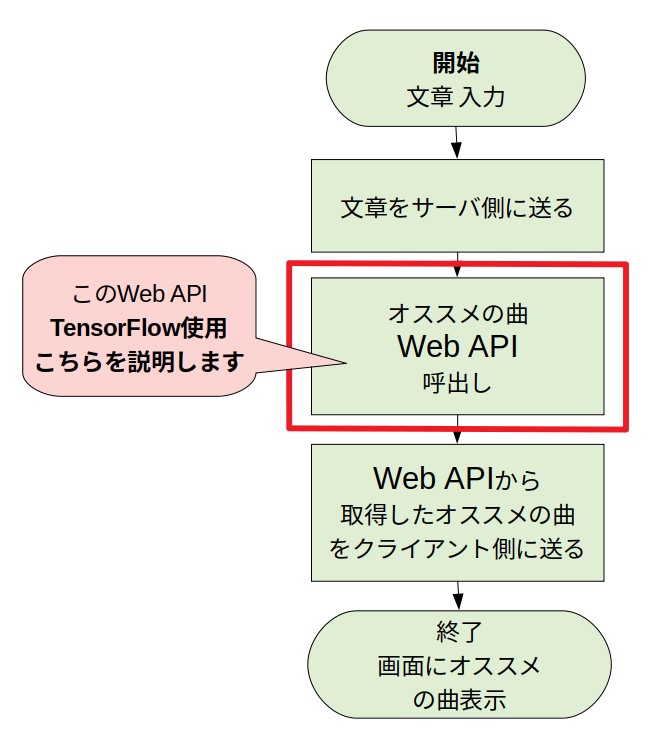
オススメ曲類推 Web APIの処理フロー
画面よりユーザが入力した文章(曲雰囲気等)をWeb APIのGETメソッドのパラメータしてアクセスします。
Web APIの実物は以下です。
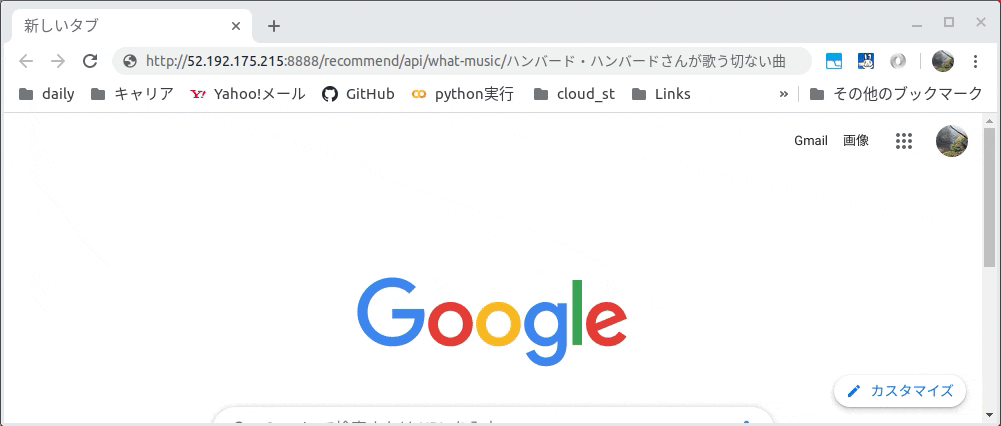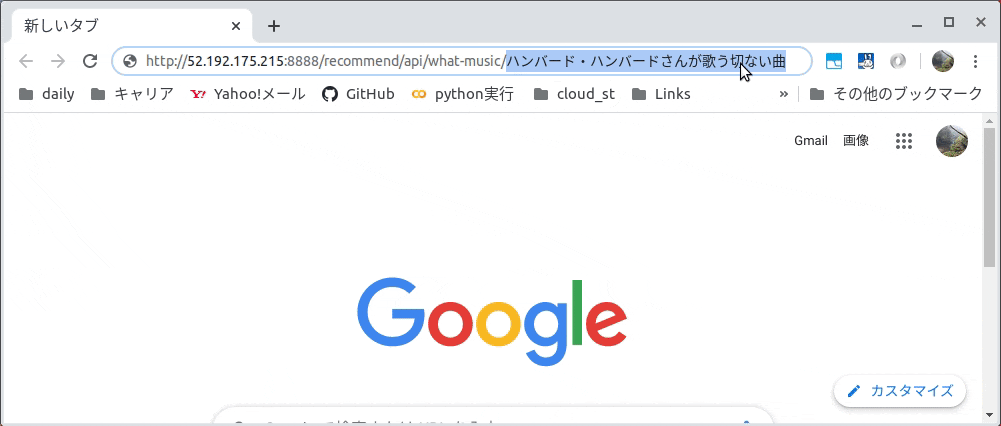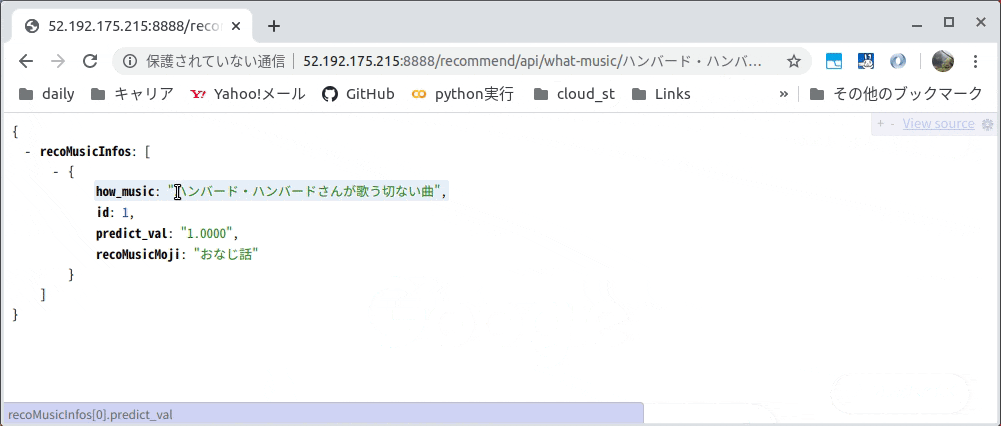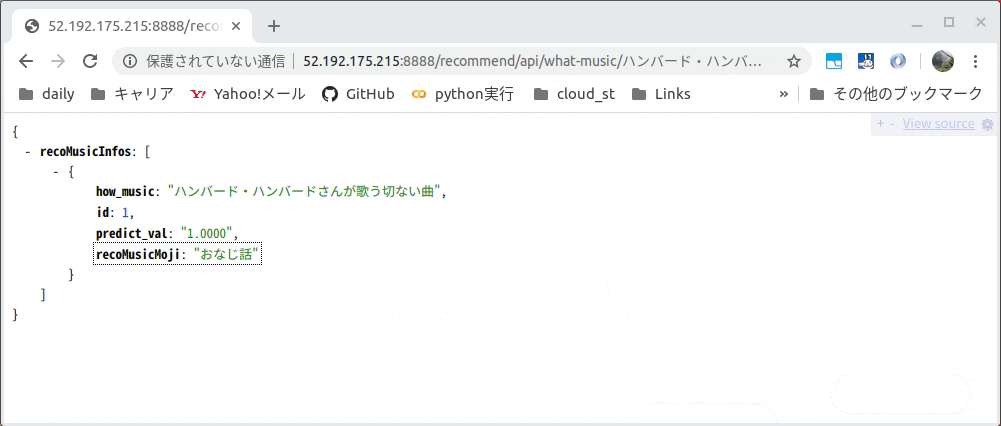
例ではGETメソッドのパラメータとして「ハンバード・ハンバードさんが歌う切ない曲」とし、
JSONで「同じ話」という曲名が取得できました。
(例)Web APIリンク
API内部の処理フローは以下となっています。
先程の例のようにユーザの文章を入力パラメータとし、APIにアクセスします。
その後、TF-IDFの辞書を読み込みます。ここでいきなり「TF-IDF」という単語が出てきますが、
わかり易い説明がありましたので引用させて頂きます。
引用元:TF-IDF
文書の中から、その文書の特徴語を抽出する時に使う値です。
いくつかの文書があったときに、それらに出てくる単語とその頻度(Frequency)から、
ある文書にとって重要な単語はなんなのかというのを数値化します
ざっくりですが、コンピュータに直接文章解析してとお願いしても、
曖昧すぎてどう解析したら良いか分かりません。数値を明確に与えて、
解析を行う準備の一つの手段みたいなものだと思ってます。
辞書とは下記のようにTF-IDFの計算に使った文章(機械学習を行った全文書)の単語等が入っているものです。
機械学習関連はこちらの文献をほぼ流用させて頂きました。とても分かりやすくためになりました![]()
流用/参考:すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方

次にKerasのSequentialでモデル定義します。このモデル定義は機械学習時のモデル定義そのままです。
$\tiny{※機械学習の方法は次回以降に書きたいと思います}$![]()
そして機械学習済みのモデルを読み込み、文書をTF-IDFベクトルに変換します。
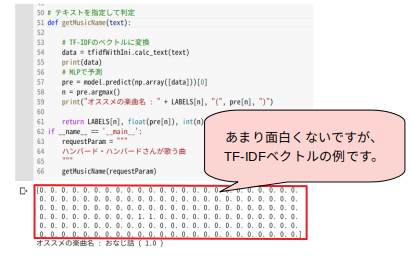
あとは、SequentialのpredictメソッドにTF-IDFベクトルを渡して、楽曲名を類推します。
ご参考までにオンライン実行環境のGoogle Colaboratory(使い方)でコンソールに類推結果を
表示する方法です。必要なファイルは以下です。
「genre-model.hdf5」、「genre-tdidf.dic」は機械学習が終わらないとできないファイルなので、
以下においておきます。また、TF-IDFの計算は別モジュール「tfidfWithIni.py」のため、読み込みが必要です。
後述の手順で必要なファイルなので3つダウンロードしておいてください。
genre-model.hdf5
genre-tdidf.dic
tfidfWithIni.py ※注1
以下は、Google Colaboratoryに貼り付けるコードです。
$\tiny{※凝視したらダメです}$![]()
上から順番に貼り付けて実行してください。。
# ファイルをアップロード(「genre-model.hdf5」、「genre-tdidf.dic」、tfidfWithIni.py)
from google.colab import files
uploaded = files.upload()
# 必要なライブラリをインストール
!apt-get install mecab libmecab-dev mecab-ipadic-utf8
!pip3 install mecab-python3
import pickle, tfidfWithIni
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.models import model_from_json
import importlib
# モジュール(tfidfWithIni)のリロード
importlib.reload(tfidfWithIni)
# ラベルの定義
LABELS = ["TSUNAMI", "雲がゆくのは", "空も飛べるはず", "糸", "おなじ話"
, "今宵の月のように","贈る言葉", "サボテンの花", "民衆の歌"
, "いつも何度でも"]
# 辞書から入力 要素数を求める。
in_size_hantei = pickle.load(open("genre-tdidf.dic", "rb"))[0]['_id']
# TF-IDFの辞書を読み込む
tfidfWithIni.load_dic("genre-tdidf.dic")
# Kerasのモデルを定義して重みデータを読み込む
nb_classes = len(LABELS)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size_hantei,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.load_weights('genre-model.hdf5')
# テキストを指定して判定
def getMusicName(text):
# TF-IDFのベクトルに変換
data = tfidfWithIni.calc_text(text)
# MLPで予測
pre = model.predict(np.array([data]))[0]
n = pre.argmax()
print("オススメの楽曲名 : " + LABELS[n], "(", pre[n], ")")
if __name__ == '__main__':
requestParam = """
ハンバード・ハンバードさんが歌う曲
"""
getMusicName(requestParam)
手順3まで実行すると以下のようにコンソールに表示されると思います。
オススメの楽曲名 : おなじ話 ( 1.0 )
手順3の47〜49行目でリクエストパラメータ(曲の雰囲気)をセットしていますが、
ためしに以下のようにしてみて下さい。
requestParam = """
人との出会いをテーマにした曲でみゆきさんが歌ってる
"""
書き換えて実行すると以下のようにコンソールに表示されると思います。
オススメの楽曲名 : 糸 ( 0.99971527 )
中島みゆきさんの「糸」という曲が表示されたと思います。
上記コードに使っている重みデータは以下の学習データを元にしています。
機械学習の元データ
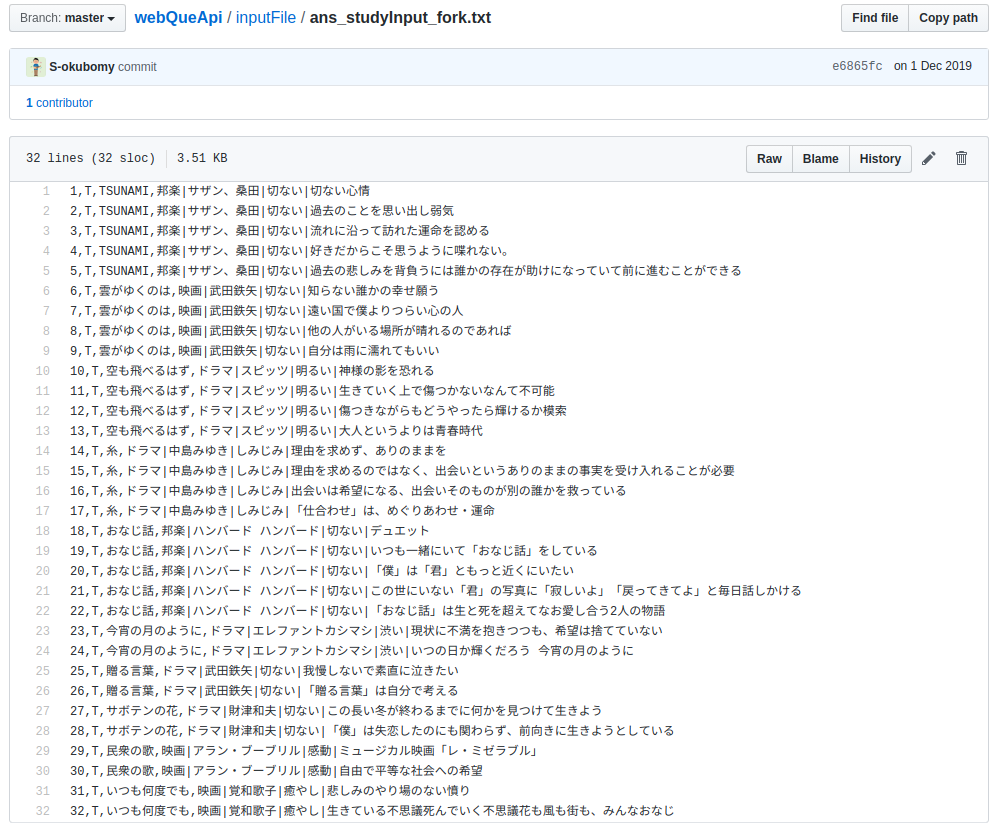
後々、機械学習の方法も整理できたらと思いますが、学習データは少なくこの中にある曲しか類推できないです。
学習データ作るのが大変なのでスクレイピングとか何かいい方法あればと思ってます![]()
環境 ※以下のVerでなくても動くと思いますが、古いのでご注意下さい
- 開発環境
- OS:Ubuntu 18.04.4 LTS
- 言語:Python 3.7、HTML、CSS、JavaScript
- フレームワーク:Django 2.2.4、Flask 1.1.0、
Tensorflow 2.1.0、Keras 2.3.1、Bootstrap - ソースコード管理:Github
- IDE:VS code 1.44
- サーバ環境
- デプロイ:AWS
- Apサーバ:Gunicorn
- Webサーバ:Nginx
- デプロイ方法:CodePipeline 自動デプロイ
今後について
今回は環境まで少し整理できました。
また、時間のある時に少しづつブラッシュアップ整理できればと思います![]()
次の**環境構築**(実行環境)はこちらです。
| 章 | 区分 | 状況 | 内容 | 言語、FW、環境等 |
|---|---|---|---|---|
| 序 章 | 共通 | 済 | アプリの概要 | Python TensorFlow Keras Google Colaboratory |
| 第一章 | Web API | 済 | (次回)環境構築(実行環境) | docker-compose Flask Nginx gunicorn |
| 第二章 | Web API | 済 | 機械学習 | Python TensorFlow Keras Flask |
| 第三章 | 画面 | 未着手 | 環境構築 | Python Django Nginx gunicorn PostgreSQL virtualenv |
| 第四章 | 画面 | 未着手 | 表示、Web API呼出し部分 | Python Django |
| 第五章 | AWS | 未着手 | AWS自動デプロイ | Github EC2 CodeDeploy CodePipeline |
参考文献
この記事を作るにあたって参考にさせて頂きました![]()
- Re:ゼロから始めるTensorFlow2.0
- TF-IDF
- Kerasの使い方をざっくりと
- すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
- Google Colaboratory概要と使用手順(TensorFlowもGPUも使える)