はじめに
本記事は(備忘録)TensorFlowを使ってオススメの楽曲名を類推するWebアプリ
【docker-composeで実行環境作り】の続きです。
前回は、docker-composeでTensorFlowとFlask環境作ったので、
今回は、TensorFlow + Kerasを使った機械学習について整理したいと思います。
自分用に作った記事なので、分かりにくい点や情報、技術が古いかもしれませんがご了承ください![]()
また何かしらのWebアプリを独りで作りたい方のご参考になれば嬉しいです。
Webアプリ実物は以下のGIFのようになります。
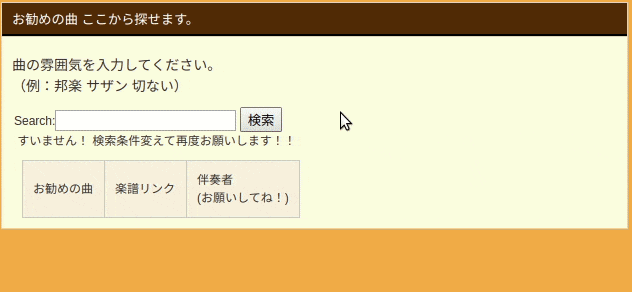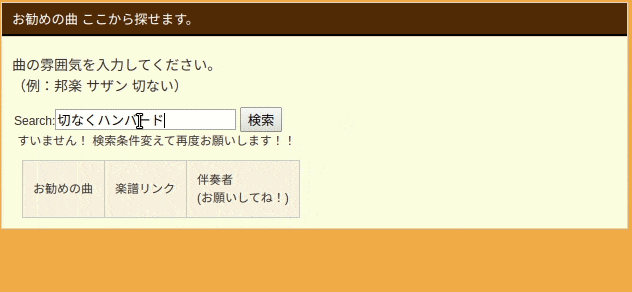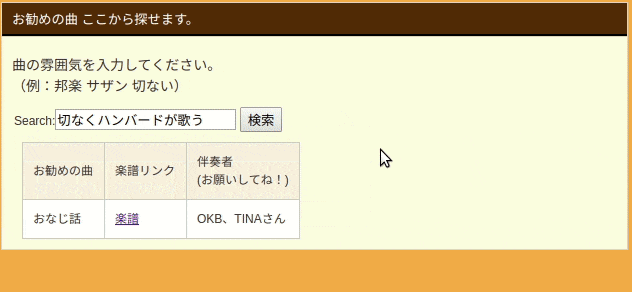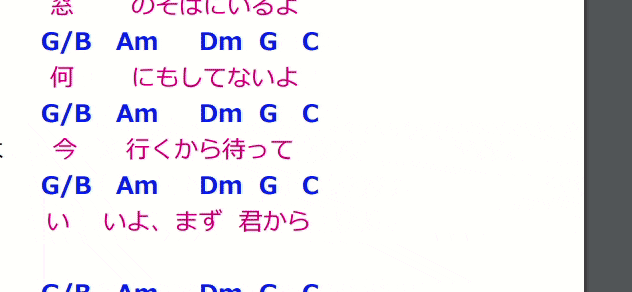
検索ボックスに文章で入力すると、ハンバード・ハンバードさんの「同じ話」と言う回答頂きました![]()
$\tiny{※学習データが少ないため、一部の曲しかヒットしません。。しょぼいです}$![]()
$\tiny{※楽譜リンクをクリックすると楽譜の一部が表示されていますが、記事の対象外です}$![]()
参考文献
この記事を作るにあたって参考にさせて頂きました![]()
- Sequentialモデルのガイド
- 【ニューラルネット】多層パーセプトロン(MLP)の原理・計算式
- Kerasの使い方まとめ【入門者向け】
- 機械学習入門者がKerasでマルチレイヤーパーセプトロンのサンプルを読む
- Denseを調べます
- 【Kerasの引数備忘録】01_kerasの引数はなにを指定しているのか
- TF-IDF
- Kerasの使い方をざっくりと
- すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
TODO マップ
(備忘録)TensorFlowを使ってオススメの楽曲名を類推するWebアプリ
【docker-composeで実行環境作り】の続きで、
今回は機械学習です。
| 章 | 区分 | 状況 | 内容 | 言語、FW、環境等 |
|---|---|---|---|---|
| 序 章 | 共通 | 済 | アプリの概要 | Python TensorFlow Keras Google Colaboratory |
| 第一章 | Web API | 済 | 環境構築(実行環境) | docker-compose Flask Nginx gunicorn |
| 第二章 | Web API | 済 | (今回)機械学習 | Python TensorFlow Keras Flask |
| 第三章 | 画面 | 未着手 | 環境構築 | Python Django Nginx gunicorn PostgreSQL virtualenv |
| 第四章 | 画面 | 未着手 | 表示、Web API呼出し部分 | Python Django |
| 第五章 | AWS | 未着手 | AWS自動デプロイ | Github EC2 CodeDeploy CodePipeline |
※まだ記事は全然整理できていないので時間ある時につくります。
未着手のまま命尽きるかも![]()
またマップは書いてるうちに変わる可能性ありますのでご了承下さい。。
環境
※以下のVerでなくても動くと思いますが、古いのでご注意下さい![]()
OS:Ubuntu 18.04.4 LTS
---------------------- -----------
Flask 1.1.0
gunicorn 19.9.0
Keras 2.3.1
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
matplotlib 3.1.1
mecab-python3 0.996.2
numpy 1.16.4
pandas 0.24.2
Pillow 7.1.2
pip 20.1
Python 3.6.9
requests 2.22.0
scikit-learn 0.21.2
sklearn 0.0
tensorflow 2.2.0
オススメ曲を類推する部分のフロー
まず、ここで作りたいは以下のような機能です。
入力して文章(曲雰囲気等)を与えるとオススメの曲名を返してくれるWeb APIです。
Web APIの実物は以下です。
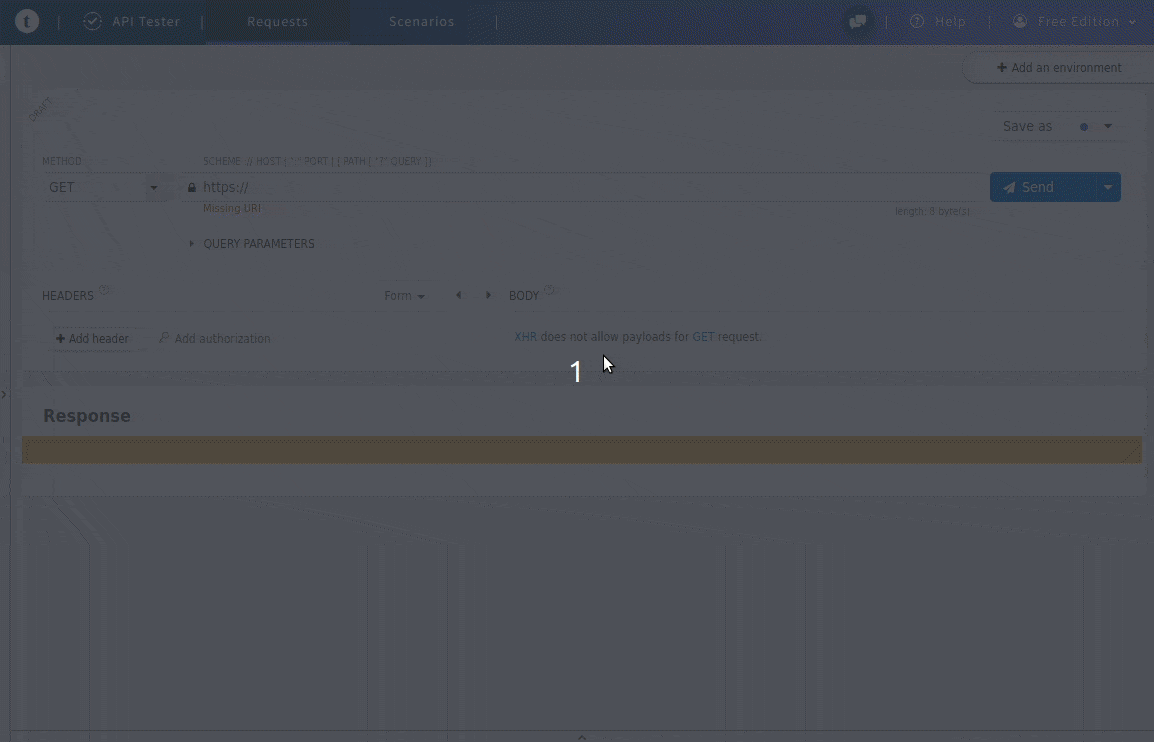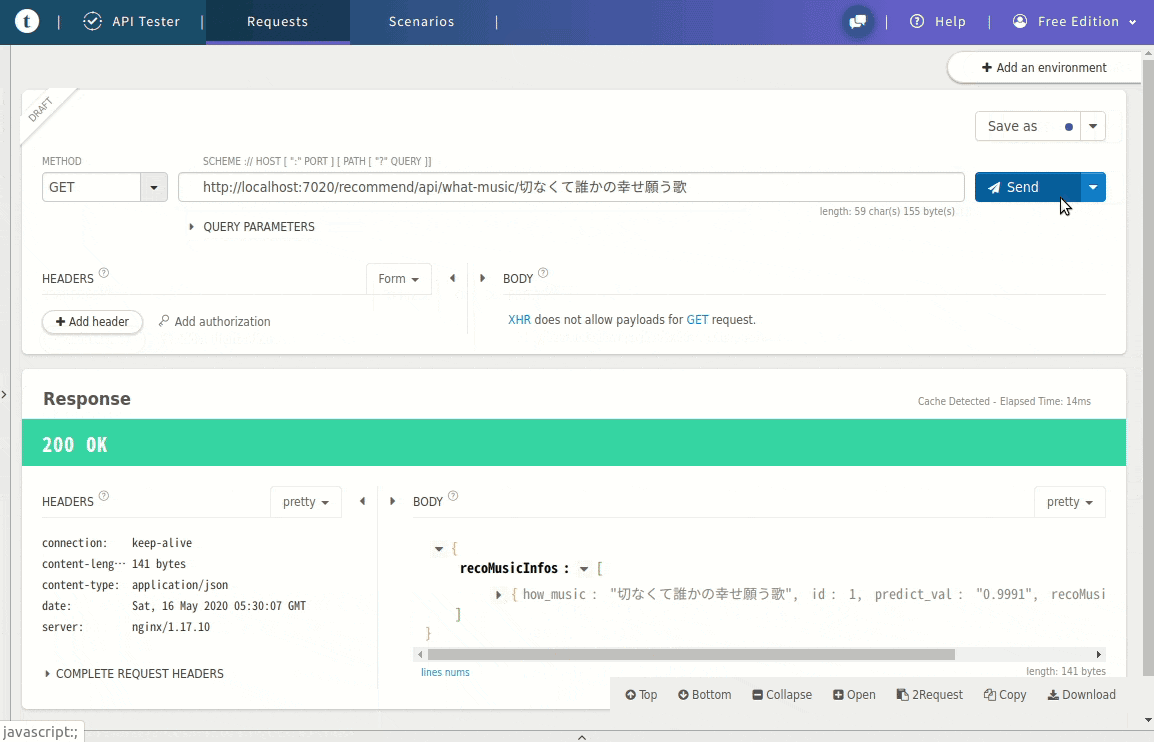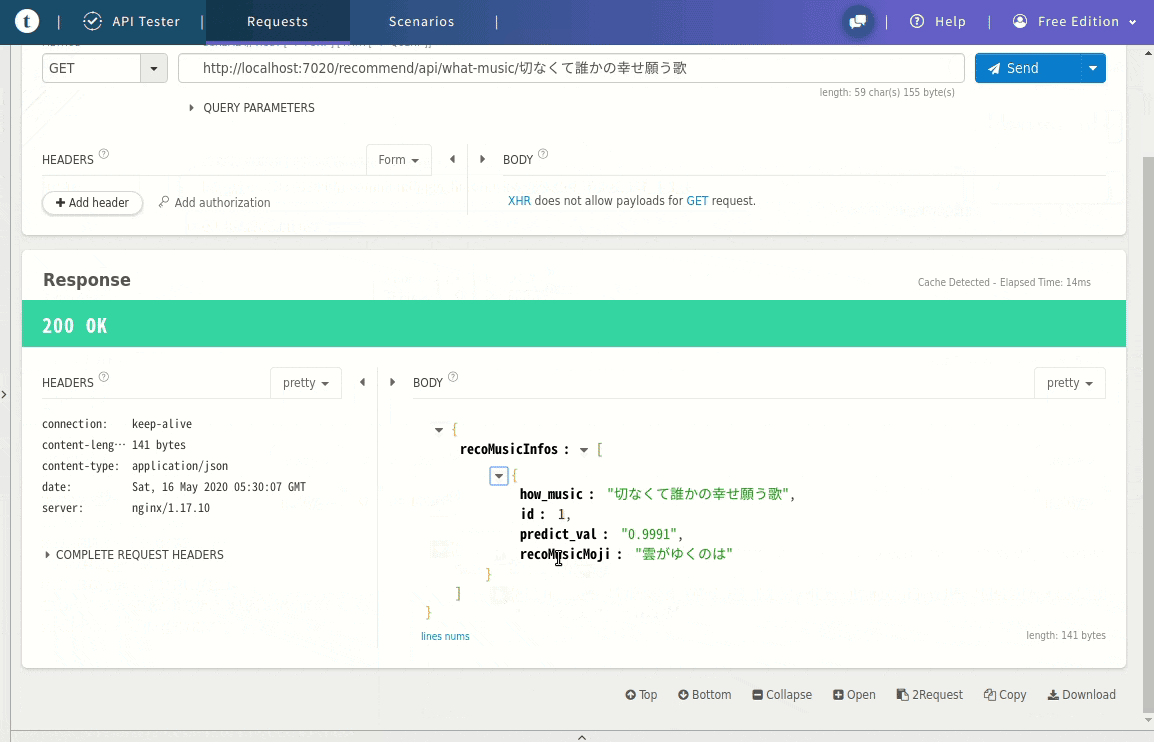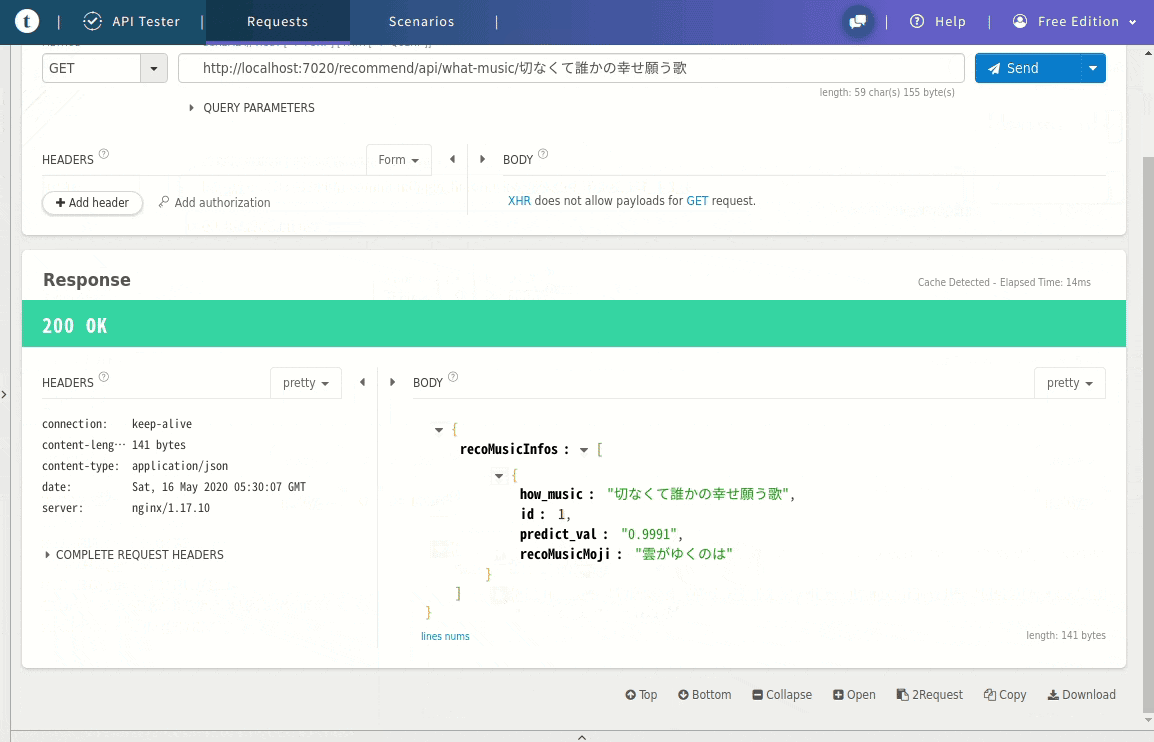
例ではGETメソッドのパラメータとして「切なくて誰かの幸せ願う歌」とし、
JSONで「雲がゆくのは」という曲名が取得できました。
(例)Web APIリンク
このWeb API内部の処理フローは以下となっています。
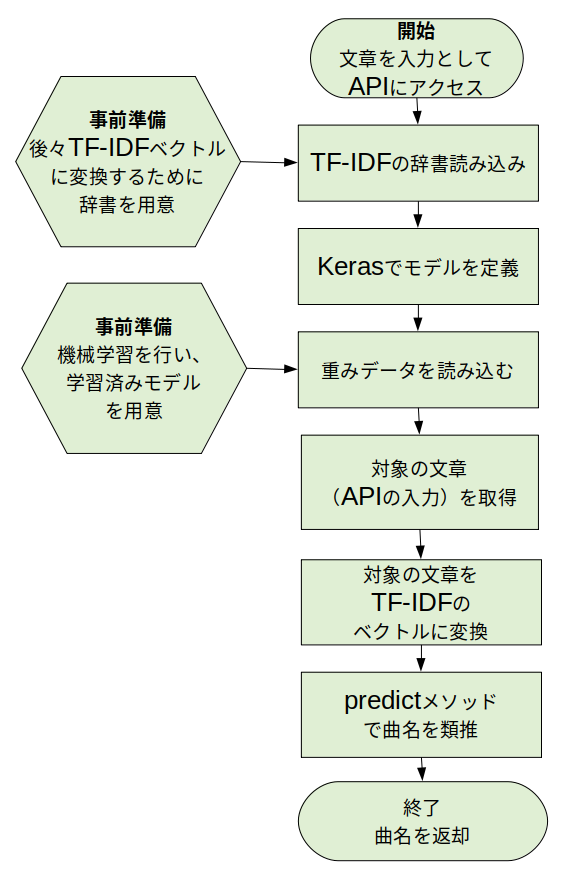
フローのように最後に曲名を返しますが、途中で重みデータを読み込みます。
これは、事前に機械学習によって作成された学習済みモデルの事です。
なので、学習済みモデルを作成する方法について整理します。
機械学習のフロー
以下フローは開発者目線で、機械学習を行うまでの流れとなります。
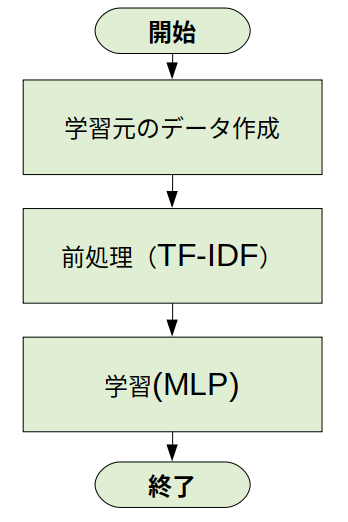
まず、学習元のデータを準備します。こちらは人間が見ても分かるようなテキストで作ります。
次に機械(コンピュータ)に分かってもらうために前処理をします。
今回の例では、TF-IDFと呼ばれる方法で学習元のデータを数値ベクトルに変換します。
最後にMLP(多層パーセプトロン)で機械学習を行います。
各々の詳細は後述します。
学習元データの作成
学習元となるデータは以下のようにカンマ区切り作っています。
機械学習の元データ
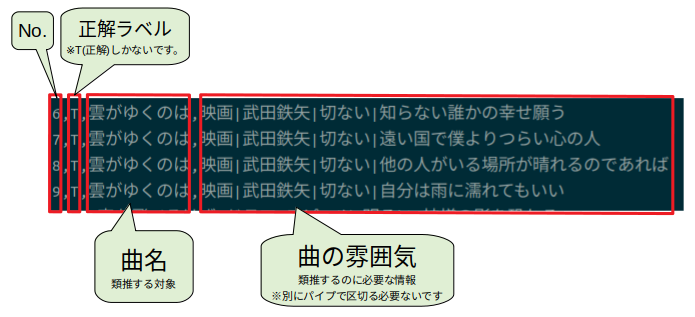
類推対象の曲名に対して曲の情報(雰囲気、アーティスト名等)が入っています。
"|"(パイプ)で区切ってますが、無くても大丈夫です。
前処理(TF-IDF)
TF-IDFで数値ベクトルに変換します。
まず、上記で作成した学習元データを読み込みます。
その後、TF-IDF計算するために文章を単語に分けます(分かち書き)
この処理では形態素解析にMeCabを使っています。
参考までに分かち書きのソースは以下です。
以下は、Google Colaboratoryに貼り付けるコードです。
$\tiny{※凝視したらダメです}$![]()
上から順番に貼り付けて実行してください。。
# 必要なライブラリをインストール
!apt-get install mecab libmecab-dev mecab-ipadic-utf8
!pip3 install mecab-python3
import MeCab
# MeCabの初期化
tagger = MeCab.Tagger()
def tokenize(text):
'''MeCabで形態素解析を行う'''
result = []
word_s = tagger.parse(text)
for n in word_s.split("\n"):
if n == 'EOS' or n == '': continue
p = n.split("\t")[1].split(",")
h, h2, org = (p[0], p[1], p[6])
if not (h in ['名詞', '動詞', '形容詞']): continue
if h == '名詞' and h2 == '数': continue
result.append(org)
return result
# モジュールのテスト
if __name__ == '__main__':
print(tokenize("映画|武田鉄矢|切ない|知らない誰かの幸せ願う"))
実行すると以下のようにコンソールに表示されると思います。
['映画', '*', '武田', '鉄矢', '*', '切ない', '*', '知る', '誰か', '幸せ', '願う']
単語ごとに区切られました。上記例は1文だけですが、
実際のプログラムではこの処理をファイル中の文章(行数)分繰り返しています。
分かち書きできたら、TF-IDFの計算します。
TF-IDFについては、わかり易い説明がありましたので引用させて頂きます。
引用元:TF-IDF
文書の中から、その文書の特徴語を抽出する時に使う値です。
いくつかの文書があったときに、それらに出てくる単語とその頻度(Frequency)から、
ある文書にとって重要な単語はなんなのかというのを数値化します
TF-IDFは以下の式で表されます。
\textrm{TF_IDF}(t) = \textrm{tf}(t,d) × \textrm{idf}(t)
また、$\textrm{tf}(t,d)$と$\textrm{idf}(t)$は以下の式で表されます。
\textrm{tf}(t,d) = \frac{n_{t,d}}{\sum_{s \in d}n_{s,d}} \textrm{ , } \textrm{idf}(t) = \log{\frac{N}{df(t)}} + 1
$n_{t,d}$ : ある単語 $t$ の文書 $d$ 内での出現回数
$\sum_{s \in d}n_{s,d}$ : 文書 $d$ 内のすべての単語の出現回数の和
$N$ : 全文書数
$df(t)$ : ある単語 $t$ が出現する文書の数
上記の式をプログラムに直すと以下になります。
def calc_files():
'''追加したファイルを計算'''
global dt_dic
result = []
doc_count = len(files)
dt_dic = {}
# 単語の出現頻度を数える
for words in files:
used_word = {}
data = np.zeros(word_dic['_id'])
for id in words:
data[id] += 1
used_word[id] = 1
# 単語tが使われていればdt_dicを加算
for id in used_word:
if not(id in dt_dic): dt_dic[id] = 0
dt_dic[id] += 1
# 出現回数を割合に直す --- (*10)
data = data / len(words)
result.append(data)
# TF-IDFを計算
for i, doc in enumerate(result):
for id, v in enumerate(doc):
idf = np.log(doc_count / dt_dic[id]) + 1
doc[id] = min([doc[id] * idf, 1.0])
result[i] = doc
return result
※こちらの文献のサンプルソース1をほぼ流用させて頂いていますが、Githubに今回のソースをあげております。
(ソース)
学習元ファイル読み込みからTF-IDFを計算・出力するソースは以下です。
肝心のTF-IDFを計算するソースは長いのでモジュール化して読み込みます![]()
また、学習元のデータも読み込みます。
以下に格納していますので、アップロードしてください。
tfidfWithIni.py ← TF-IDFを計算するモジュール
ans_studyInput_fork.txt ← 学習元ファイル
TF-IDFベクトル作成手順
以下は、ご参考までにGoogle Colaboratoryに貼り付けるコードです。
$\tiny{※凝視したらダメです}$![]()
上から順番に貼り付けて実行してください。。
# ファイルをアップロード(「tfidfWithIni.py」、「ans_studyInput_fork.txt」)
from google.colab import files
uploaded = files.upload()
# 入力ファイル用のディレクトリ作成
!mkdir text
# 必要なライブラリをインストール
!apt-get install mecab libmecab-dev mecab-ipadic-utf8
!pip3 install mecab-python3==0.996.5 tensorflow==2.5.0
import os, csv, glob, pickle
import tfidfWithIni
import importlib
# モジュール(tfidfWithIni)のリロード
importlib.reload(tfidfWithIni)
# 変数の初期化
y = []
x = []
# ラベルのコード変換用 辞書
labelToCode = {}
# csvファイルを読み込む
def read_file(path):
'''テキストファイルを学習用に追加する''' # --- (*6)
with open(path, "r", encoding="utf-8") as f:
reader = csv.reader(f)
label_id = 0
for row in reader:
# ラベルコード作成
if row[2] not in labelToCode:
labelToCode[row[2]] = label_id
label_id += 1
y.append(labelToCode[row[2]]) # ラベルをセット
tfidfWithIni.add_text(row[3]) # 文章をセット
# print("ラベル: ", row[2], "(", labelToCode[row[2]], ")", " 文章: ", row[3])
# モジュールのテスト --- (*15)
if __name__ == '__main__':
# TF-IDFベクトルを初期化(filesを空にする)
tfidfWithIni.iniForOri()
# ファイル一覧を読む --- (*2)
read_file("ans_studyInput_fork.txt")
# TF-IDFベクトルに変換 --- (*3)
x = tfidfWithIni.calc_files()
# 保存 --- (*4)
pickle.dump([y, x], open('text/genre.pickle', 'wb'))
tfidfWithIni.save_dic('text/genre-tdidf.dic')
pickle.dump(labelToCode, open('text/label_to_code.pickle', 'wb'))
実行すると以下のようにフォルダーとファイルが出来上がります。
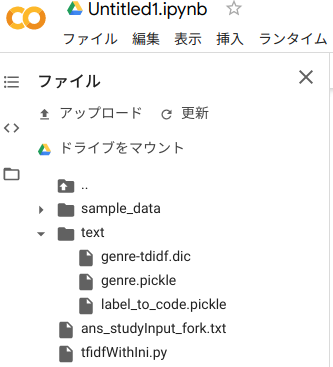
- /content/text/genre.pickle : 単語をTF-IDFでベクトル化したもの
- /content/text/label_to_code.pickle : 学習元ファイルを元に曲名をラベル化した辞書
- /content/text/genre-tdidf.dic : TF-IDF計算用の辞書
TF-IDF計算用の辞書は以下のように計算に使った単語をIDに変換したものです。

機械学習(MLP)
前処理をしたので、機械学習の準備終わりました。
上記までの学習データを元に曲名を正しく判別できるように学習を行います。
学習の手法としてMLP(多層パーセプトロン)を使います。
MLPとは、人の神経を模したニューラルネットワークの一種で、
3つ以上のノードの層からなるものだそうです。
MLPはある手法で学習データ(正解となるデータ)を元に学習を行い、
未知のデータ(この例では曲の雰囲気)がきても正しく判別(この例では曲名)できるようになります。
これを行うために機械学習フレームワークのTensorFlow+Kerasを使います。
そして、今回は以下のような構造のニューラルネットワークを作ります※イメージです![]()
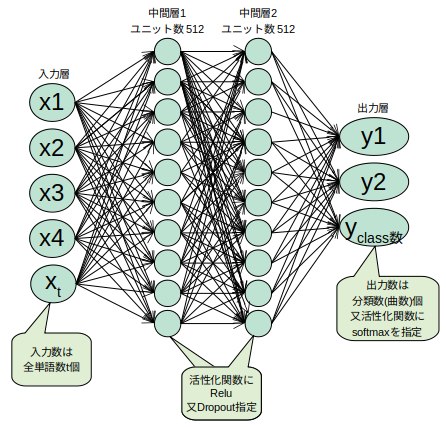
このニューラルネットワーク作るためにTensorFlow+Kerasでモデル化するとこのようになります1。
# MLPモデル構造を定義
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
レイヤーにはKerasのDenseと呼ばれるものを使います。これを使うと各々のパーセプトロンが次のレイヤーの
パーセプトロンに全て繋がるそうです。
また、イメージ図のx1〜xtまでが入力数ですが、これは引数のinput_shapeで定義しており、
全文章を分かち書きしてできた単語の数分です。サンプルの学習ファイルでは144個(次元)になります。
出力はy1〜yclassで学習ファイルの曲名数分あり、引数のnb_classesで指定してます。
サンプルでは10個(曲)です。
次に正しく判別できるようにどのように学習を行うか設定します(コンパイル)。
Keras Documentationのマルチクラス分類問題を元に最適化アルゴリズムとしてRMSprop、
損失関数としてcategorical_crossentropyとします。
※(言葉のイメージ)損失関数:学習のズレを計る指標、最適化アルゴリズム:正解に近づける修正方法
# モデルをコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
最後に学習の実行部分です。
学習はfitメソッドで実行します。入力(曲の雰囲気等)と出力(曲名)
のNumpy配列をsequenceモデルのfitメソッドに与えると学習してくれます。
hist = model.fit(x_train, y_train,
batch_size=16, # 1回に計算するデータ数
epochs=150, # 学習の繰り返し回数みたいなもの
verbose=1,
validation_data=(x_test, y_test))
機械学習の実行
以下は、ご参考までにGoogle Colaboratoryに貼り付けるコードです。
上記TF-IDFベクトル作成手順の手順3まで実行した上で、
以下を実行すると機械学習実行できるはずです。
import pickle
from sklearn.model_selection import train_test_split
import sklearn.metrics as metrics
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import numpy as np
import h5py
# 分類するラベルの数
labelToCode = pickle.load(open("text/label_to_code.pickle", "rb"))
nb_classes = len(labelToCode)
# データベースの読込
data = pickle.load(open("text/genre.pickle", "rb"))
y = data[0] # ラベルコード
x = data[1] # TF-IDF
# ラベルデータをone-hotベクトルに直す
y = keras.utils.np_utils.to_categorical(y, nb_classes)
in_size = x[0].shape[0] # 入力x[0]の要素数
# 学習用とテスト用を分ける
x_train, x_test, y_train, y_test = train_test_split(
np.array(x), np.array(y), test_size=0.2)
# MLPモデル構造を定義
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
# モデルをコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# 学習を実行
hist = model.fit(x_train, y_train,
batch_size=16, # 1回に計算するデータ数
epochs=150, # 学習の繰り返し回数みたいなもの
verbose=1,
validation_data=(x_test, y_test))
# 評価する
score = model.evaluate(x_test, y_test, verbose=1)
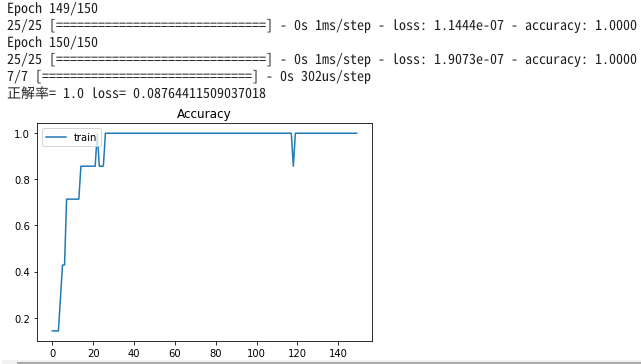
print("正解率=", score[1], 'loss=', score[0])
# 重みデータを保存
model.save_weights('./text/genre-model.hdf5')
# 学習の様子をグラフへ描画
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
実行終わると、以下のようなグラフが表示され、ファイル(/content/text/genre-model.hdf5)が
追加で作成されているはずです。これで機械学習終わりです。
学習済みモデルを使って曲名を類推
類推部分でも機械学習時と同様のモデルを定義します。
学習済みモデル、TF-IDF辞書、結果ラベル用辞書を読み込みます。
そして未知の文書(曲の雰囲気)をTF-IDFベクトルに変換します。
最後にSequencialが持つpredictメソッドにTF-IDFベクトル与えると曲名を類推します。
以下は、ご参考までにGoogle Colaboratoryに貼り付けるコードです。
上記 機械学習の実行の手順4まで実行した上で、
以下を実行すると曲名が類推できるはずです。
import pickle, tfidfWithIni
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.models import model_from_json
import importlib
# モジュール(tfidfWithIni)のリロード
importlib.reload(tfidfWithIni)
def inverse_dict(d):
return {v:k for k,v in d.items()}
# テキストを指定して判定
def getMusicName(text):
# TF-IDFのベクトルに変換
data = tfidfWithIni.calc_text(text)
# MLPで予測
pre = model.predict(np.array([data]))[0]
n = pre.argmax()
print("オススメの楽曲名 : " + label_dic[n], "(", pre[n], ")")
# ラベルの定義
labelToCode = pickle.load(open("text/label_to_code.pickle", "rb"))
nb_classes = len(labelToCode)
label_dic = inverse_dict(labelToCode)
# 辞書から入力 要素数を求める。
in_size_hantei = pickle.load(open("text/genre-tdidf.dic", "rb"))[0]['_id']
# TF-IDFの辞書を読み込む
tfidfWithIni.load_dic("text/genre-tdidf.dic")
# Kerasのモデルを定義して重みデータを読み込む
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size_hantei,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.load_weights('./text/genre-model.hdf5')
if __name__ == '__main__':
requestParam = """
切なくて誰かの幸せ願う歌
"""
getMusicName(requestParam)
学習結果によって変わるかもしれませんが、以下のように表示されると思います。
オススメの楽曲名 : 雲がゆくのは ( 0.99969995 )
Flaskを使ったWeb APIでの曲名類推は前回ちょっとやってますので、割愛したいと思います![]()
tensorflow v2.5.0に書き換え
# Colaboratoryでファイルをアップロード
from google.colab import files
uploaded = files.upload()
import pandas as pd
df_study = pd.read_csv('ans_studyInput_fork.txt', names=['id', 'truth_val', 'ラベル(教師データ)', '入力'])
df_study
# 入力ファイル用のディレクトリ作成
!mkdir text
# 必要なライブラリをインストール
!apt-get install mecab libmecab-dev mecab-ipadic-utf8
!pip3 install mecab-python3==0.996.5 tensorflow==2.5.0
import MeCab
tagger = MeCab.Tagger('-d /etc/alternatives/mecab-dictionary')
def tokenize(text):
'''MeCabで形態素解析を行う''' # --- (*3)
result = []
word_s = tagger.parse(text)
# print(word_s)
for n in word_s.split("\n"):
if n == 'EOS' or n == '': continue
p = n.split("\t")[1].split(",")
h, h2, org = (p[0], p[1], p[6])
if not (h in ['名詞', '動詞', '形容詞']): continue
if h == '名詞' and h2 == '数': continue
if org == '*': org = n.split("\t")[0]
result.append(org)
# return result
return ' '.join(result)
import pickle
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
# csvファイルを読み込む
def main():
df_study = pd.read_csv('ans_studyInput_fork.txt', names=['id', 'truth_val', 'ans', 'que'])
labelToCode = {lbl:idx for idx, lbl in enumerate(df_study.ans.unique())}
y = df_study.ans.apply(lambda x: labelToCode[x]).tolist()
# tfidを計算
df_wakati = df_study["que"].apply(lambda x: tokenize(x))
vectorizer = TfidfVectorizer(max_df=0.9, token_pattern='(?u)\\b\\w+\\b') # tf-idfの計算 1文字でもOK
x = vectorizer.fit_transform(df_wakati).toarray()
# オブジェクト類(tfid等)を保存
pickle.dump(vectorizer, open('text/tfidf_vec.pickle', 'wb'))
pickle.dump([y, x], open('text/genre.pickle', 'wb'))
pickle.dump(labelToCode, open('text/label_to_code.pickle', 'wb'))
print(df_study)
# 実行
if __name__ == '__main__':
main()
import pickle
import tensorflow as tf
# 分類するラベルの数
labelToCode = pickle.load(open("text/label_to_code.pickle", "rb"))
nb_classes = len(labelToCode)
# データベースの読込
data = pickle.load(open("text/genre.pickle", "rb"))
x = data[1] # TF-IDF
# 入力x[0]の要素数(TF-IDF)より入力要素数を求める
in_size = x[0].shape[0]
# MLPモデル構造を定義
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(in_size,)))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(512, activation=tf.nn.relu))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(nb_classes, activation=tf.nn.softmax))
# モデルをコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
input_shape = x.shape
print(input_shape)
model.summary()
# モデルを保存する
model.save('text/hw_model.h5')
print('model seved')
import pickle
from sklearn.model_selection import train_test_split
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import os
# 分類するラベルの数
labelToCode = pickle.load(open("text/label_to_code.pickle", "rb"))
nb_classes = len(labelToCode)
# データベースの読込
data = pickle.load(open("text/genre.pickle", "rb"))
y = data[0] # ラベルコード
x = data[1] # TF-IDF
# ラベルデータをone-hotベクトルに直す
y = tf.keras.utils.to_categorical(y, nb_classes)
in_size = x[0].shape[0] # 入力x[0]の要素数
# 学習用とテスト用を分ける
x_train, x_test, y_train, y_test = train_test_split(
np.array(x), np.array(y), test_size=0.2)
# モデルを読み込む
model = tf.keras.models.load_model('text/hw_model.h5')
# 既に学習済みの重みデータが存在していれば読み込む
# if os.path.exists(ml_dir + 'text/hw_weights.h5'):
# model.load_weights(ml_dir + 'text/hw_weights.h5')
# 学習を実行
hist = model.fit(x_train, y_train,
batch_size=30, # 1回に計算するデータ数
epochs=300, # 学習の繰り返し回数みたいなもの
verbose=1,
validation_data=(x_test, y_test))
# 評価する
score = model.evaluate(x_test, y_test, verbose=1)
print("正解率=", score[1], 'loss=', score[0])
# 重みデータを保存
model.save_weights('text/hw_weights.h5')
# 学習の様子をグラフへ描画
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
import pickle
import tensorflow as tf
# import pandas as pd
def inverse_dict(d):
return {v:k for k,v in d.items()}
# モデルを読み込む
model = tf.keras.models.load_model('text/hw_model.h5')
# 学習済みの重みデータを読み込む
model.load_weights('text/hw_weights.h5')
# tfidオブジェクトをファイルよりロードする
vectorizer_loaded = pickle.load(open("text/tfidf_vec.pickle", "rb"))
# ラベルの定義
labelToCode = pickle.load(open("text/label_to_code.pickle", "rb"))
label_dic = inverse_dict(labelToCode)
# テキストを指定して判定
def predCatego(text):
# TF-IDFのベクトルに変換
data = vectorizer_loaded.transform([tokenize(text)]).toarray()
# MLPで予測
pre = model.predict(data)[0]
sortIndexDesc = pre.argsort()[::-1];
maxInd = sortIndexDesc[0]
ans_sentence = label_dic[maxInd]
predict_val = "{:.4f}".format(pre[maxInd])
print(ans_sentence, predict_val)
print("2番目の答え : " + label_dic[sortIndexDesc[1]], "{:.4f}".format(pre[sortIndexDesc[1]]))
return ans_sentence, predict_val
if __name__ == '__main__':
requestParam = """
切なくて誰かの幸せ願う歌
"""
predCatego(requestParam)
今後について
今回は機械学習まで少し整理できました。
また、時間のある時に少しづつブラッシュアップ、整理できればと思います![]()
未定ですが、次回は画面側の環境構築について整理できればと思います。
| 章 | 区分 | 状況 | 内容 | 言語、FW、環境等 |
|---|---|---|---|---|
| 序 章 | 共通 | 済 | アプリの概要 | Python TensorFlow Keras Google Colaboratory |
| 第一章 | Web API | 済 | 環境構築(実行環境) | docker-compose Flask Nginx gunicorn |
| 第二章 | Web API | 済 | 機械学習 | Python TensorFlow Keras Flask |
| 第三章 | 画面 | 未着手 | (次回)環境構築 | Python Django Nginx gunicorn PostgreSQL virtualenv |
| 第四章 | 画面 | 未着手 | 表示、Web API呼出し部分 | Python Django |
| 第五章 | AWS | 未着手 | AWS自動デプロイ | Github EC2 CodeDeploy CodePipeline |