はじめに
機械学習モデルを解釈する際には「特徴量重要度」がキーワードになってきます。「特徴量重要度」には様々な指標があり、目的が違います。
①feature importance、②permutation importance、③SHAP の3つについて説明していきます。
結論から言うと
3つの特徴量重要度を調べて、個人的に感じた結論を以下に書きます。
-
①feature importance:予測モデルを組む際に 「モデル」が重要視する因子が分かる 。例えば決定木を考えた際にどの因子がノードの分割に寄与するのかを評価するイメージ。
-
②permutation importance:各特徴量が予測にどう寄与するかが分かる。モデルの「予測精度」に影響する因子が分かる。
-
③SHAP: 「予測結果」に対する各特徴量の寄与が分かる 。それぞれのデータの予測にインパクトを与える因子が分かる。
①feature importance
ある特徴量で分割することでどれくらいジニ不純度を下げられるのかに基づいて計算される。
その特徴量の分割がターゲットの分類にどれくらい寄与しているかを測る指標。
tree系で使えるが、学習データに対する評価しかできない。モデルを作成する際の寄与度を評価するが、特徴量が予測精度にどれだけ貢献しているかは分からない。
②permutation importance(PFI:permutation feature importance)
元のデータと、ある特徴量の値を完全にシャッフルしたデータで、それぞれの正解データと予測データの誤差を比較してその差を特徴量の重要度とする。
特徴量をシャッフルしたことで誤差が大きくなる特徴量はモデルのパフォーマンスへの寄与が大きく、重要と見なされる。
Permutation Importanceはモデルの予測精度向上に効いている特徴量を見つける方法としては有効ですが、SHAPのように「予測がどのように成されたか?」を解釈する手法として用いることはできません。
③SHAP(SHapley Additive exPlanations Value)
各特徴量が個別のデータの予測にどの程度貢献しているかを示し、モデルの予測に対する全体的な理解を深めることができます。
SHAP Importanceの値は特定の特徴量の値が結果にどのように影響するかを理解するために使用できます。
データの読み込み
今回はこちらのページで紹介した"df.csv"というデータを用いていきます。csvファイルはGitHunにも保存しております。
# ライブラリーのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データセットの読み込み
df = pd.read_csv("df.csv", encoding="shift_jis")
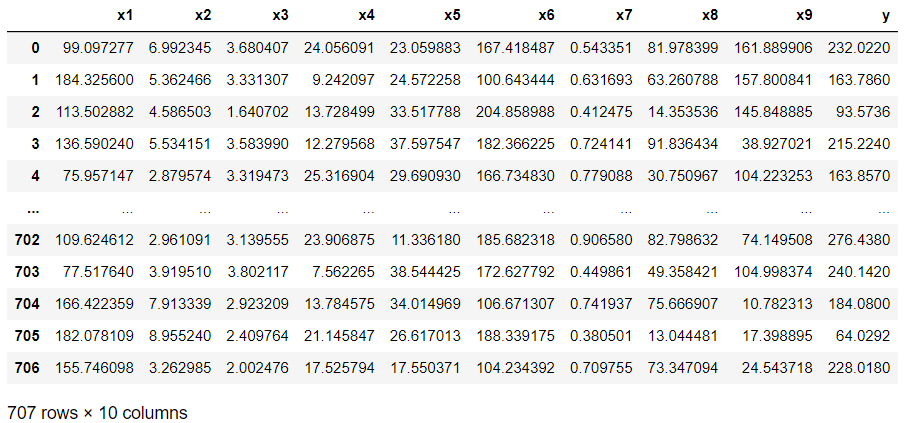
df
# データの分割
from sklearn.model_selection import train_test_split
# 説明変数の定義
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
# 学習データとテストデータへの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# 学習データのサイズを確認
X_train.shape
(494, 9)
ランダムフォレスト回帰の実行
feature importanceはtree系にしか使えないので、今回はランダムフォレスト回帰でデータセットを分析していきます。
# ランダムフォレスト回帰のインスタンスの作成
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators = 100,
max_features = 5,
random_state = 123,
n_jobs = -1)
# 学習データに対する精度
rf.fit(X_train, y_train)
rf.score(X_train, y_train)
0.9897505176839843
# テストデータに対する精度
rf.score(X_test, y_test)
0.9136504687426884
①feature importanceの計算
# feature importanceの計算
importances = rf.feature_importances_
# 計算結果をデータフレームに格納
df_feature_importance = pd.DataFrame(zip(X_train.columns, importances),columns=["Features","Importance"])
df_feature_importance
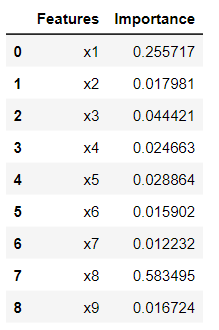
このサイトにあるように、LightGBMやXGBoostでは特徴量の重要度の計算方法を頻度(初期値)もしくはゲインから指定する必要があるので注意です。
plt.figure(figsize=(10,5))
sns.barplot(x="Importance", y="Features",data = df_feature_importance, ci=None)
plt.title("Permutation Importance")
plt.tight_layout()
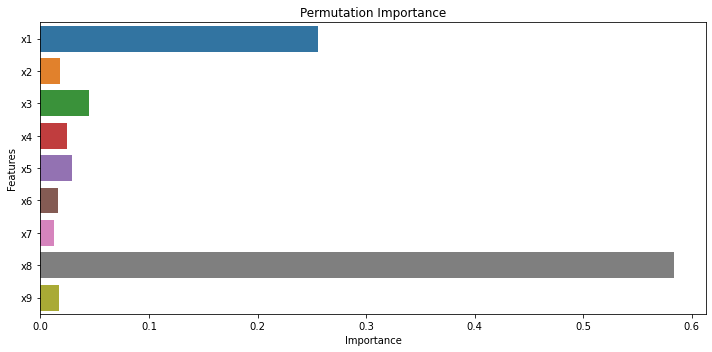
②permutation importanceの計算
from sklearn.inspection import permutation_importance
result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=123)
df_importance = pd.DataFrame(zip(X_train.columns, result["importances"].mean(axis=1)),columns=["Features","Importance"])
df_importance ```

```python
plt.figure(figsize=(10,5))
sns.barplot(x="Importance", y="Features",data=df_importance,ci=None)
plt.title("Permutation Importance")
plt.tight_layout()
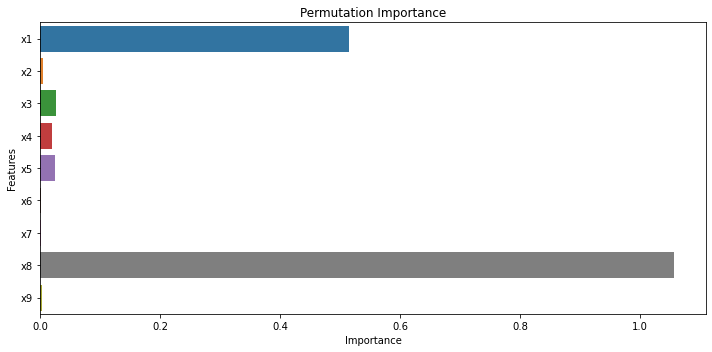
①feature importanceと②permutation importanceを比較すると、x8が最重要でその次はx1である点は共通しています。それ以外の説明変数の重要度は両者で多少異なりますが、全体的な傾向としては共通していると言えます。
③SHAPの計算
# SHAPの計算
import shap
shap.initjs() # いくつかの可視化で必要
explainer = shap.TreeExplainer(rf, X_test)
shap_values = explainer.shap_values(X_test)
# SHAP値の確認
shap_values.shape
(213, 9)
SHAP値は全てのデータに対して算出されます。試しに1つデータを選んで確認してみます。
i = 2
shap.force_plot(explainer.expected_value, shap_values[i,:], X_test.iloc[i,:])

以下のコードで全体に対してのSHAPの結果を可視化できます。
shap.summary_plot(shap_values, X_test)
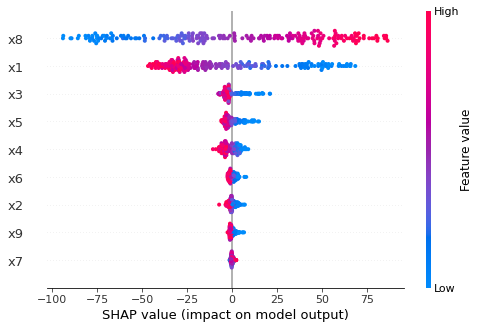
③SHAPの結果を見ても、x8が最重要でx1がその次に重要であることが分かります。また①feature importanceや②permutation importanceと比較すると説明変数が目的変数に正の寄与をするのか負の寄与をするのか分かる点が大きな違いです。また各データの予測に対して説明変数がどのように寄与しているのか把握することが出来ます。