はじめに
SRCNNで超解像をやってみた(TensorFlow)の続きになります。
コチラの記事に超解像分野のモデルの変遷がまとまっています。

この中のFSRCNNモデルを公式論文を参考にTensorFlow(keras)で実装してみました。
データや環境は前回の記事と同じです。
FSRCNNとは
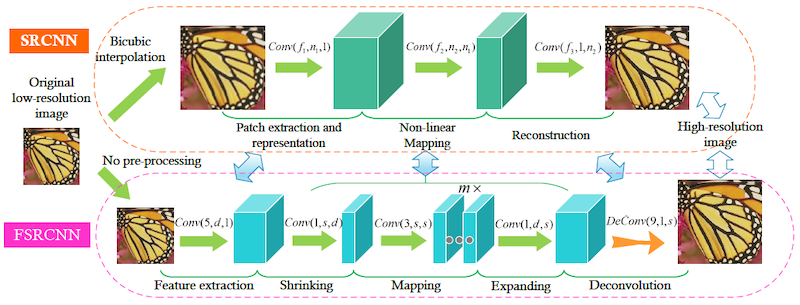
上図は公式論文より。
SRCNNモデルでは入力画像として、高画質の画像を縮小・拡大して画質を落とした画像を与えていたので計算量が多くなることが課題だった。(高画質の画像と同じサイズの画像を用意する必要があった)
そのため入力画像は小さいサイズの画像のままで扱い、最後の層でDeconvolutionを行うことで拡大する、という構造にすることでパラメータ数を減らすことに成功している。
実装
活性化関数にPReluを使います。ただkerasのPReluだと入力サイズを指定しないといけないため、どんな入力サイズでも対応できるように自作のPReluクラスを実装します。コチラを参考にしました。
import tensorflow.keras.backend as K
class MyPReLU(tf.keras.layers.Layer):
def __init__(self,
alpha_initializer = 'zeros',
alpha_regularizer = None,
alpha_constraint = None,
shared_axes = None,
**kwargs):
super(MyPReLU, self).__init__(**kwargs)
self.alpha_initializer = tf.keras.initializers.get('zeros')
self.alpha_regularizer = tf.keras.regularizers.get(None)
self.alpha_constraint = tf.keras.constraints.get(None)
def build(self, input_shape):
param_shape = tuple(1 for i in range(len(input_shape) - 1)) + input_shape[-1:]
self.alpha = self.add_weight(shape = param_shape,
name = 'alpha',
initializer = self.alpha_initializer,
regularizer = self.alpha_regularizer,
constraint = self.alpha_constraint)
self.built = True
def call(self, inputs, mask=None):
pos = K.relu(inputs)
neg = -self.alpha * K.relu(-inputs)
return pos + neg
def compute_output_shape(self, input_shape):
return input_shape
def get_config(self):
config = {
'alpha_initializer': tf.keras.initializers.serialize(self.alpha_initializer),
'alpha_regularizer': tf.keras.regularizers.serialize(self.alpha_regularizer),
'alpha_constraint': tf.keras.constraints.serialize(self.alpha_constraint),
}
base_config = super(MyPReLU, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
PReluに関しては公式論文が詳しいです。
モデル部分も公式論文の数値を参考に実装しました。
def build_My_FSRCNN(d=4):
conv_initializer = tf.keras.initializers.he_normal(seed=46)
deconv_initializer = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.001, seed=46)
#prelu_initializer = tf.keras.initializers.Constant(value=0.25)
prelu_initializer = tf.keras.initializers.Zeros()
model = Sequential()
model.add(Conv2D(56, 5, padding='same', kernel_initializer=conv_initializer, input_shape=(None, None, 3)))
model.add(MyPReLU(alpha_initializer=prelu_initializer, shared_axes=[1, 2]))
model.add(Conv2D(12, 1, padding='same', kernel_initializer=conv_initializer))
model.add(MyPReLU(alpha_initializer=prelu_initializer, shared_axes=[1, 2]))
for _ in range(d):
model.add(Conv2D(12, 3, padding='same', kernel_initializer=conv_initializer))
model.add(MyPReLU(alpha_initializer=prelu_initializer, shared_axes=[1, 2]))
model.add(Conv2D(56, 1, padding='same', kernel_initializer=conv_initializer))
model.add(MyPReLU(alpha_initializer=prelu_initializer, shared_axes=[1, 2]))
model.add(Conv2DTranspose(3, 9, 4, padding='same', kernel_initializer=deconv_initializer))
return model
公式論文だとPReluの初期値パラメータ$α$を0.25にしているようですが、自分が学習させた感じ途中で発散してしまったので結局ゼロにしてます。
評価指標や損失関数を定義してコンパイルします。
def psnr(low, high):
return tf.image.psnr(low, high, max_val=1.0)
def ssim(low, high):
return tf.image.ssim(low, high, max_val=1.0)
optimizers = [
tf.keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8),
tf.keras.optimizers.Adam(learning_rate=0.0001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)
]
loss = tf.keras.losses.MeanSquaredError()
metrics = [psnr, ssim]
optimizers_and_layers = [(optimizers[0], model.layers[:-1]), (optimizers[1], model.layers[-1])]
optimizer = tfa.optimizers.MultiOptimizer(optimizers_and_layers)
model.compile(optimizer = optimizer,
loss = loss,
metrics = metrics)
損失関数はAdamで最後の転置畳み込み層とそれ以外で学習率を変更してます。
これで600エポックくらい回してみました。
Epoch 600/600
16/16 [==============================] - 20s 1s/step - loss: 0.0028 - psnr: 26.5561 - ssim: 0.7826
結果
前回に続いて推しメン画像で試してみる



元画像、次にbicubic法で補完した超解像画像、学習済みFSRCNNモデルで補完した超解像画像です
微妙ですね、、、
PSNRやSSIMの数値もbicubic補完の数値の方が高かったです。
まとめ
GANと同じく学習がすごい難しいと思いました。
ただ最新の超解像モデルでは頻繁に使われているgeometric ensembleというTTA(Test Time Augmentation: 推論時も水増しをする手法)を使うと劇的にPSNRやSSIMの数値が変わったので、これも別記事で紹介しようと思います。
またほとんど論文を見て実装したので、論文実装に対する抵抗感は無くなったのは大きい。英語は嫌いですが、最新手法や効果的なパラメータ情報にアプローチするためには止む無しといったところですね。