はじめに
かめはめ波を撃ちたくなったので作ってみました。

推定の線は非表示にすることもできます。

OpenPoseを用いて関節の座標を取得、そこから角度を算出して、そのポーズがそれっぽいかを判定しています。
OpenPoseについて
セットアップ方法
OpenPoseのTensorflow版であるtf pose estimationを使用しました。
私の環境はWindows10、GTX1070といったものだったので、セットアップに関しては下記のページを参考にしました。
Windowsで姿勢推定(tf pose estimation)
はまったので注意書き
・長い、深いパスは避けた方が無難です。(swigが正しく動かないことがあるようです。)
実行方法
下記コマンドで、自前のWebカメラを使って動作させることができます。
python run_webcam.py
Escで終了します。
関節の座標取得
各関節には下記のような番号が割り振られています。
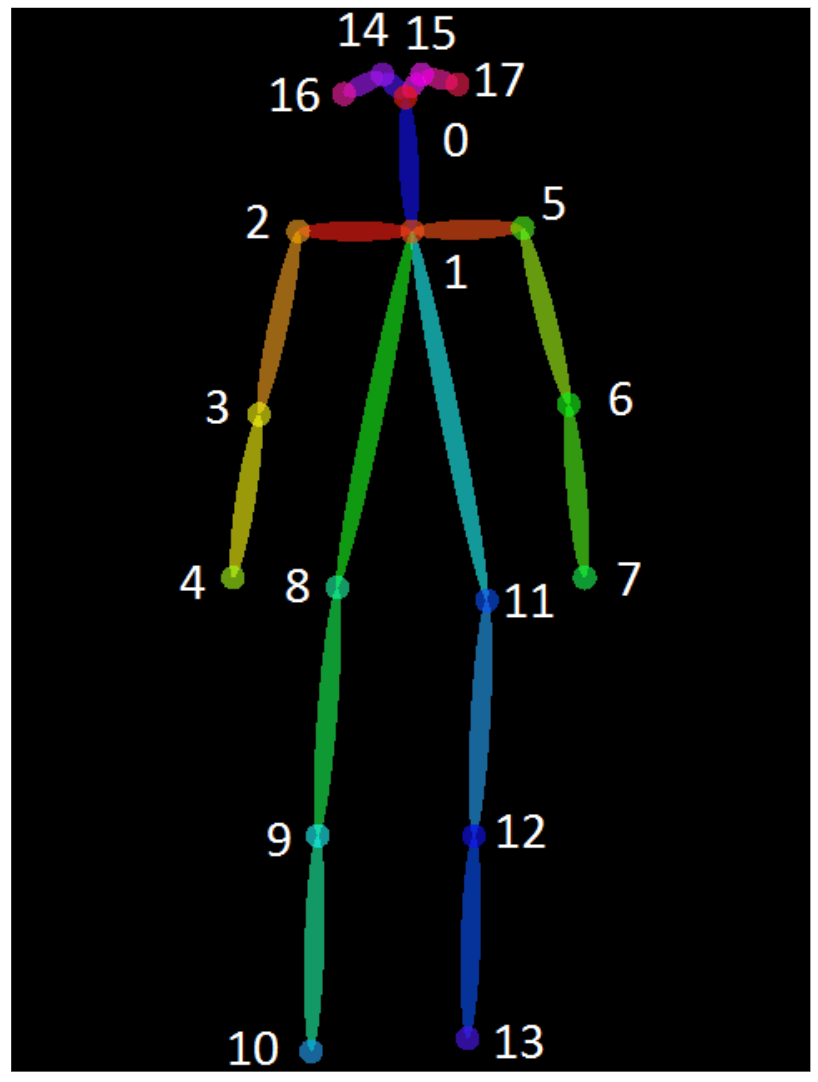
例えば、右肩(2)を取得したい場合はこうなります。
複数人の取得もありうるため、humansをforで回しています。
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
height,width = image.shape[0],image.shape[1]
for human in humans:
body_part = human.body_parts[2]
x = int(body_part.x * width + 0.5)
y = int(body_part.y * height + 0.5)
debug_info = 'x:' + str(x) + ' y:' + str(y)
実際のコード
実際のコードです。
kamehameha.pyとして保存し、run_webcam.py と同じフォルダに保存してください。
import argparse
import logging
import time
from pprint import pprint
import cv2
import numpy as np
import sys
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
import math
logger = logging.getLogger('TfPoseEstimator-WebCam')
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
fps_time = 0
def find_point(pose, p):
for point in pose:
try:
body_part = point.body_parts[p]
return (int(body_part.x * width + 0.5), int(body_part.y * height + 0.5))
except:
return (0,0)
return (0,0)
def euclidian( point1, point2):
return math.sqrt((point1[0]-point2[0])**2 + (point1[1]-point2[1])**2 )
def angle_calc(p0, p1, p2 ):
'''
p1 is center point from where we measured angle between p0 and
'''
try:
a = (p1[0]-p0[0])**2 + (p1[1]-p0[1])**2
b = (p1[0]-p2[0])**2 + (p1[1]-p2[1])**2
c = (p2[0]-p0[0])**2 + (p2[1]-p0[1])**2
angle = math.acos( (a+b-c) / math.sqrt(4*a*b) ) * 180/math.pi
except:
return 0
return int(angle)
def accumulate_pose( a, b, c, d):
'''
a and b are angle between neck, left shoulder and left wrist
c and d are angle between neck, right shoulder and right wrist
'''
if a in range(70,105) and b in range(100,140) and c in range(70,110) and d in range(120,180):
return True
return False
def release_pose( a, b, c, d):
'''
a and b are angle between neck, left shoulder and left wrist
c and d are angle between neck, right shoulder and right wrist
'''
if a in range(140,200) and b in range(80,150) and c in range(0,40) and d in range(160,200):
return True
return False
def draw_str(dst, xxx_todo_changeme, s, color, scale):
(x, y) = xxx_todo_changeme
if (color[0]+color[1]+color[2]==255*3):
cv2.putText(dst, s, (x+1, y+1), cv2.FONT_HERSHEY_PLAIN, scale, (0, 0, 0), thickness = 4, lineType=10)
else:
cv2.putText(dst, s, (x+1, y+1), cv2.FONT_HERSHEY_PLAIN, scale, color, thickness = 4, lineType=10)
#cv2.line
cv2.putText(dst, s, (x, y), cv2.FONT_HERSHEY_PLAIN, scale, (255, 255, 255), lineType=11)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='tf-pose-estimation realtime webcam')
parser.add_argument('--camera', type=str, default=0)
parser.add_argument('--resize', type=str, default='432x368',
help='if provided, resize images before they are processed. default=432x368, Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resize heatmaps before they are post-processed. default=1.0')
parser.add_argument('--model', type=str, default='cmu', help='cmu / mobilenet_thin')
parser.add_argument('--show-process', type=bool, default=False,
help='for debug purpose, if enabled, speed for inference is dropped.')
args = parser.parse_args()
print("mode 0: Normal Mode \nmode 1: Debug Mode")
mode = int(input("Enter a mode : "))
logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model)))
w, h = model_wh(args.resize)
if w > 0 and h > 0:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
else:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
logger.debug('cam read+')
cam = cv2.VideoCapture(args.camera)
ret_val, image = cam.read()
logger.info('cam image=%dx%d' % (image.shape[1], image.shape[0]))
count = 0
i = 0
frm = 0
y1 = [0,0]
global height,width
orange_color = (0,140,255)
while True:
ret_val, image = cam.read()
i =1
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
pose = humans
if mode == 1:
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
height,width = image.shape[0],image.shape[1]
debug_info = ''
if len(pose) > 0:
# angle calcucations
angle_l1 = angle_calc(find_point(pose, 6), find_point(pose, 5), find_point(pose, 1))
angle_l2 = angle_calc(find_point(pose, 7), find_point(pose, 6), find_point(pose, 5))
angle_r1 = angle_calc(find_point(pose, 3), find_point(pose, 2), find_point(pose, 1))
angle_r2 = angle_calc(find_point(pose, 4), find_point(pose, 3), find_point(pose, 2))
debug_info = str(angle_l1) + ',' + str(angle_l2) + ' : ' + str(angle_r1) + ',' + str(angle_r2)
if accumulate_pose(angle_l1, angle_l2, angle_r1, angle_r2):
logger.debug("*** accumulate Pose ***")
# (1) create a copy of the original:
overlay = image.copy()
# (2) draw shapes:
cv2.circle(overlay, (find_point(pose, 4)[0] - 40, find_point(pose, 4)[1] + 40), 40, (255, 241, 0), -1)
# (3) blend with the original:
opacity = 0.4
cv2.addWeighted(overlay, opacity, image, 1 - opacity, 0, image)
elif release_pose(angle_l1, angle_l2, angle_r1, angle_r2):
logger.debug("*** release Pose ***")
# (1) create a copy of the original:
overlay = image.copy()
# (2) draw shapes:
cv2.circle(overlay, (find_point(pose, 7)[0] + 80 ,find_point(pose, 7)[1] - 40), 80, (255, 241, 0), -1)
cv2.rectangle(overlay,
(find_point(pose, 7)[0] + 80, find_point(pose, 7)[1] - 70),
(image.shape[1], find_point(pose, 7)[1] - 10),
(255, 241, 0), -1)
# (3) blend with the original:
opacity = 0.4
cv2.addWeighted(overlay, opacity, image, 1 - opacity, 0, image)
image= cv2.flip(image, 1)
if mode == 1:
draw_str(image, (20, 50), debug_info, orange_color, 2)
cv2.putText(image,
"FPS: %f" % (1.0 / (time.time() - fps_time)),
(10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
#image = cv2.resize(image, (720,720))
if(frm==0):
out = cv2.VideoWriter('outpy.avi',cv2.VideoWriter_fourcc('M','J','P','G'), 30, (image.shape[1],image.shape[0]))
print("Initializing")
frm+=1
cv2.imshow('tf-pose-estimation result', image)
if i != 0:
out.write(image)
fps_time = time.time()
if cv2.waitKey(1) == 27:
break
cv2.destroyAllWindows()
実行・終了のさせ方
下記コマンドで実行させます。
python kamehameha.py
メニューがでてきます。「Debug Mode」を指定すると、推定の線や角度情報が表示されます。

初期処理が終わると、かめはめ波が撃てるようになります。
Escで終了します。
注意事項
- 姿勢検知はおおざっぱなものです。カメラの位置・カメラに対してどう体を向けているかなどの条件によって正しく検知できないことがあります。
- 画面右から左に向けてしか放てません。
- OpenPoseの仕様の部分となりますが、背景と人物のコントラストがあった方が検知がよさそうです。(Debug Modeを併用して確認してください。)
姿勢検知の条件
「Debug Mode」の画面左上には、右肩、右ひじ、左肩、左ひじの角度が並んでいます。

それぞれの角度が条件に当てはまっている場合、その姿勢をしていると判断します。
| 「かめはめ」 | 「波~」 | |
|---|---|---|
| 右肩 | 70 ~ 105 | 140 ~ 200 |
| 右ひじ | 100 ~ 140 | 80 ~ 150 |
| 左肩 | 70 ~ 110 | 0 ~ 40 |
| 左ひじ | 120 ~ 180 | 160 ~ 200 |
うまく反応しないようなときは、コードのaccumulate_pose関数、release_pose関数の判定の数値をいじっていただければと思います。
終わりに
OpenPoseを使ってなにかしたいと考えていたため、今回それができてよかったです。
筋トレが正しい姿勢で行えているかといったパーソナルトレーナー的役割とか、子供が喜ぶギミックめいたものなんかが作れそうですね。