はじめに
姿勢推定アルゴリズムOpenPoseのTensorflow版としてtf pose estimationが公開されています。
これをWindows+Anaconda仮想環境で動かしてみました。
Windowsではすんなり動かなかったため備忘録として残しておきます。
初心者のため説明などふわふわしてますがご了承ください。
環境
Windows 10
conda 4.7.11
CUDA 10.1
cudnn 7.3.1
GeForce RTX 2080
本記事ではAnacondaやCUDA等のインストールには触れません。
Anacondaで仮想環境を作るとこから入ります。
環境を作る前に
tf pose estimation のダウンロード
まず下記Githubからファイルをダウンロードして好きなところに解凍して置いておきます。
https://github.com/ildoonet/tf-pose-estimation
Windows Subsystem for Linux をインストール
本記事の手順ではbashを使いますので、作業に入る前に使えるようにしときます。
手順は下記とかをご参考に。
https://qiita.com/Aruneko/items/c79810b0b015bebf30bb
環境構築
仮想環境の作成
Anaconda (powersell) promptで下記コマンドでpython3.6の仮想環境を作ります。
Anaconda Navigatorからも簡単に作れますが、たまに壊れるときがあるのでコマンドから作っています。
conda create -n myenv python=3.6
python3.7でもデモを動かす分には大丈夫でした。
作った仮想環境をactvateして作業していきます。
conda activate myenv
ライブラリインストール
必要なライブラリを仮想環境にインストールします。
tf pose estimationが必要とするものはrequirements.txtに記載してあるのですが、その前に以下のライブラリをインストールしておくとスムーズです。
バージョンは動作確認したものを記載。
- cython 0.29.13
- numpy 1.16.4
- git 2.20.1
- swig 3.0.12
- opencv 3.3.1
- tensorflow-gpu 1.14.0 (GPU無い場合は tensorflow )
全部conda install で入れました。
次に、ダウンロードしたtf-pose-estimation-masterに移動して、requirements.txtをインストールする、んですが。
その中のpycocotoolのインストールがうまくいきません。
ので、先に下記コマンドで別にpycocotoolを入れておくかrequirements.txtを書き換えておくかしないといけません。
pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"
できたらrequirements.txtに記載の必要なライブラリをまとめてインストールします。
pip install -r requirements.txt
必要なライブラリが揃いました。
あとは手順通りにやっていきます。
C++ライブラリのビルド
cd tf_pose\pafprocess
swig -python -c++ pafprocess.i && python setup.py build_ext --inplace
パッケージインストール
cd ..\..\
python setup.py install
modelのダウンロード
cd models\graph\cmu
bash download.sh
環境構築はこれでOKのはず。
Run
tensorRTのコメントアウト
環境構築ができたので早速動かせるかと思いきや、run.pyしてみたらtensorRTが無いとerrorが出ました。
tensorRT は windows の python にはまだ対応していない為使えないみたいです。
なのでコード内で使っているところをコメントアウトします。
(最適化して速度を早くするものらしく、動かす分には無くても問題ないようです)
tf_pose/estimator.py
- 14行目 import文
- 315行目~328行目 if文
動かしてみる
とりあえず何も考えずカメラで試す。
python run_webcam.py
Escで終了。
モデルは4種類用意されており、指定しない場合cmuモデルが使われます。
- cmu (trained in 656x368)
- mobilenet_thin (trained in 432x368)
- mobilenet_v2_large (trained in 432x368)
- mobilenet_v2_small (trained in 432x368)
速度はmobilenetの方が早く、精度はcmuが良い印象?
モデルを指定するときは、上記コマンドの後ろに--model=モデル名 を付けて指定できます。
静止画
python run.py --model=mobilenet_thin --image=./images/p1.jpg
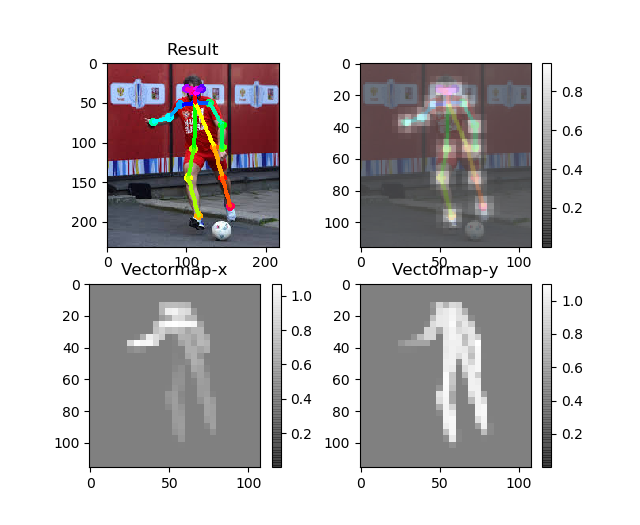
静止画はデフォルトではこんな感じにpyplotで出力されます。
推定関節のヒートマップと、関節をつなぐために求められたクトルマップです。
Result画像を保存したい場合、run.py 54行目imageがデータですのでcv2.imwrite(出力名.jpg, image)で保存できます。
静止画とカメラは問題なく動きますが、動画用のファイルにはバグがあるみたいで推定してくれません。
下記コードで動きました。
(拝借したコードなのですが、どこから持ってきたかわからなくなったのでソースを見つけたら貼り付けます。)
こちらで解決してくれたものです。
ついでに推定骨格を描画した動画を保存するコード入れています。
保存する場合は4行あるコメントアウトを全て外してください。
import argparse
import logging
import time
import cv2
import numpy as np
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
logger = logging.getLogger('TfPoseEstimator-Video')
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
fps_time = 0
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='tf-pose-estimation Video')
parser.add_argument('--video', type=str, default='')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resize images before they are processed. default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resize heatmaps before they are post-processed. default=1.0')
parser.add_argument('--model', type=str, default='mobilenet_thin', help='cmu / mobilenet_thin')
parser.add_argument('--show-process', type=bool, default=False,
help='for debug purpose, if enabled, speed for inference is dropped.')
parser.add_argument('--showBG', type=bool, default=True, help='False to show skeleton only.')
args = parser.parse_args()
logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model)))
w, h = model_wh(args.resize)
if w > 0 and h > 0:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
else:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
cap = cv2.VideoCapture(args.video)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
if cap.isOpened() is False:
print("Error opening video stream or file")
# fourcc = cv2.VideoWriter_fourcc(*'DIVX')
# writer = cv2.VideoWriter('./video/output.mp4', fourcc, fps, (width, height))
while cap.isOpened():
ret_val, image = cap.read()
logger.debug('image process+')
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
if not args.showBG:
image = np.zeros(image.shape)
logger.debug('postprocess+')
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
logger.debug('show+')
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
# writer.write(image)
if cv2.waitKey(1) == 27:
break
cv2.destroyAllWindows()
# writer.release()
cap.release()
logger.debug('finished+')
動かすときは同様に
python run_video.py --video=./video.mp4
相変わらずエラー文出ますね、、時間があれば見直します。
結果
-
さっきのやつ

-
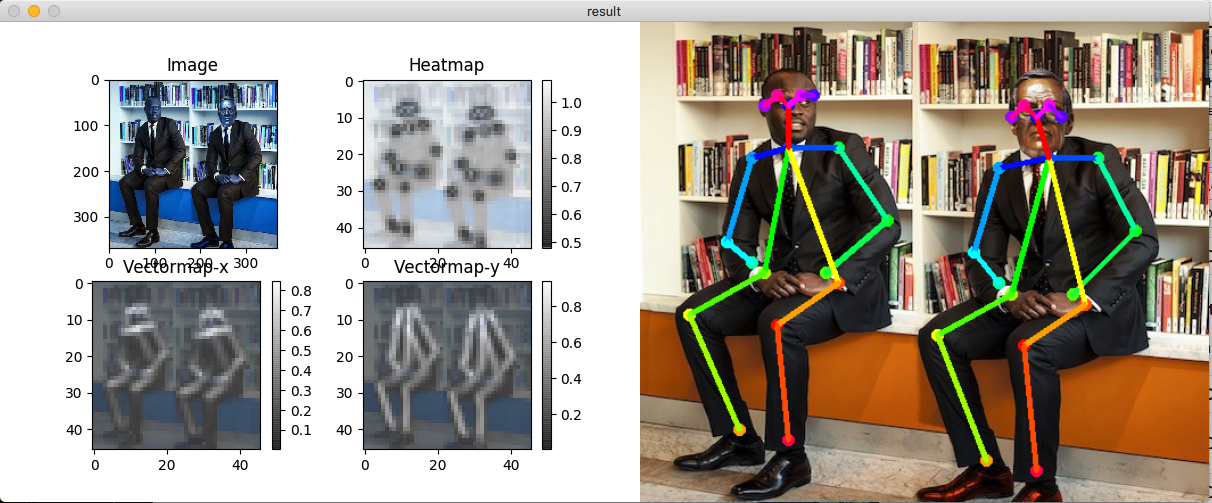
借りてきたふちこさんズ

逆さまは以外はぱっと見認識できてるように見えますが…。
よく見ると関節の位置がちらほらずれてます。変な体勢は難しいみたいです。
これはウェブカメラのキャプチャーですが、FPSは画像のとおりcmuモデルでFPS24、mobilenet_thinモデルだとFPS30くらい出ていました。CPUだとその1/10くらい遅くなります。
ちなみに13体のふちこさんを貸していただいたのですが、全員載せられませんでした。ごめんなさい。 -
サイゼにいる天使

カメラでも試しましたが、上半身だけはOKで肩以上がフレームアウトしていると認識してくれない感じでした。
たまに背景に居ないはずの人間を認識します。これ見ると肩が入っていることが重要なんでしょうか。
微妙な結果ばかり載せてすみません。
助けてくださった先輩方、ありがとうございます。
以上!