リスクテイクしてこそ研究者だ。音響と画像認識で成果を出し続ける日立研究員のマインド

ここ数年で機運が高まり続けている企業のデジタルトランスフォーメーション。AIをはじめとする技術への社会的注目度は格段に上がってきており、日立製作所でも社会課題解決を支援する様々なコア技術の研究と、それらを社会実装したソリューションを、日々発表しています。
今回はその中でも、音響領域と画像認識領域における最新の取り組みについて。
同社では、最も古い映像認識コンペティションのひとつであるTRECVID(TREC Video Retrieval Evaluation)に2015年から参加しており、また音響領域の国際コンペティションであるDCASEに至っては2020年から主催側として活動しています。
その背景にあるマインドは「リスクテイク」。グローバルレベルで技術競争が激しくなっているからこそ、研究者はリスクを負ってでも積極的にチャレンジをするべきだ!本記事では、そんな強烈なマインドをもった2人の技術研究者にお話を伺いました。
目次
プロフィール

研究開発グループ 人工知能イノベーションセンタ メディア知能処理研究部

研究開発グループ ルマーダデータサイエンスラボラトリ
世の中にある様々な事象のデジタル化を技術支援

――まずはおふたりの現在のお仕事と、これまでのご経歴について教えてください。
川口:2007年に日立に新卒で入社して、中央研究所に配属され、そのまま現在に至るまでここにいます。
入社時は携帯電話やビデオ会議システムを担当していて、その後は水中ソナーや爆発物検知、最近だと2020年9月に販売開始されたDNAシーケンサーのアルゴリズムの開発と、本当に様々なテーマをやってきました。
現在は音響や振動、水中音響、化学信号などを対象とする信号処理と機械学習の研究開発を行うチームのチームリーダーをやっています。
岡崎:私は2020年3月に日立に中途入社しまして、映像解析チームの中でも監視ソリューションを研究する部署にいます。
その前は、セキュリティ関連企業の研究所に新卒で入りまして、そこでも機械学習を用いて映像解析の研究をやっていました。
――ありがとうございます。コンペの話に入る前に、先におふたりが取り組まれている研究内容について教えてください。
川口:日立は今、世の中にある様々な事象をデジタル化して、効率化していこうという事業をメインに展開しています。
それに対して私たちは、デジタル化を推進するためのコア技術として信号処理と、そのための機械学習に関する研究開発を行っています。信号処理とは要するに、センサーから獲得したデータに対して情報を抽出して返すことです。しかし、センサーデータには、ノイズがあったり変動があったり、データが少なかったりするので情報を抽出するのは結構難しいものです。
このような、整理されていない限られたデータから情報を抽出するということに取り組んでいるわけですが、その中で私たちのチームが特にフォーカスしているのが、音響認識の技術になります。
――音響認識はあまり馴染みがない領域なのですが、具体的にはどんな内容でしょうか?
川口:音声認識という技術は、ご存じの方が多いと思います。音声認識はヒトの声を自動的に文字に書き起こす技術です。
それに対し、音響認識は、ヒトの音声ではなく環境で発せられる様々な音から、いまどのような状況なのか、何が起きているのか、を自動的に判断する技術であり、「DCASE(Detection and Classification of Acoustic Scenes and Events)」と呼ばれている現在急成長している分野です。
さらに音響シーン識別と音響イベント検出に大別されますが、こちらの図がイメージしやすいでしょう。
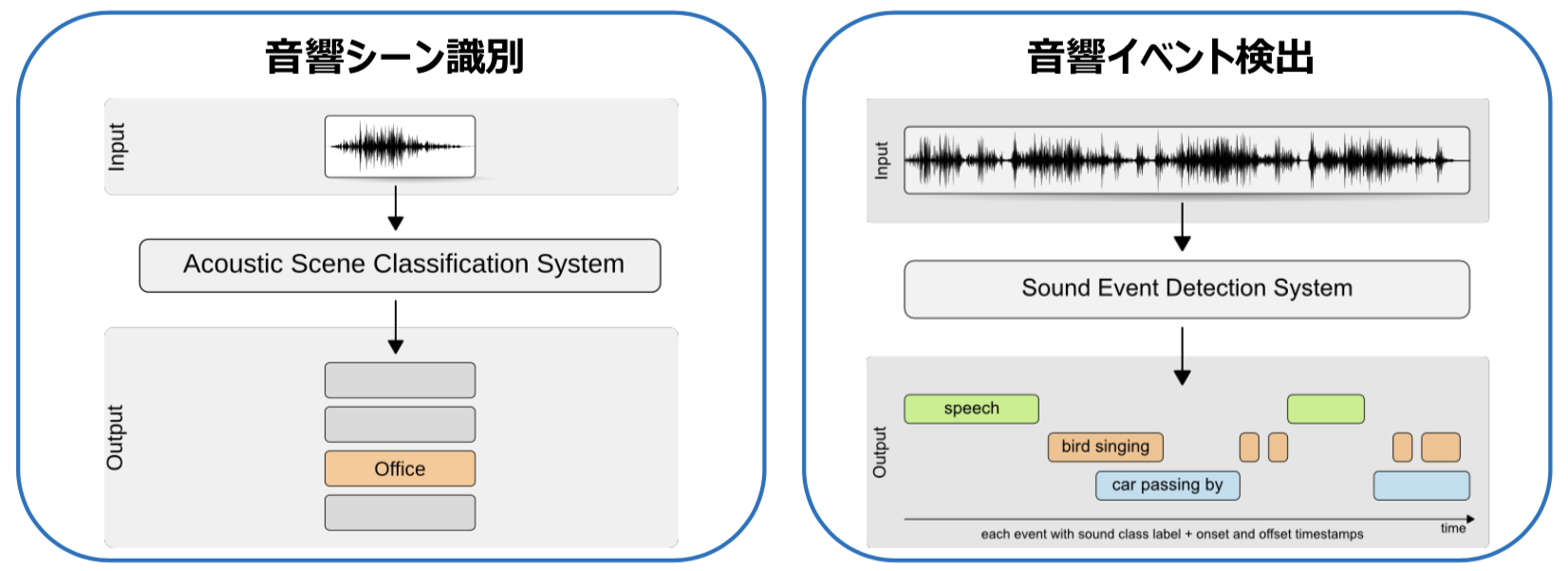
川口:この技術を応用することで、例えば工場内の点検業務や製品検査、設備の保守保全など、今まで熟練技術をもった方々がやっていたことを、自動化して効率化する自動化するための技術を開発しています。
――なるほど、面白いですね。ありがとうございます。岡崎さんはいかがでしょうか?
岡崎:私たちが取り組んでいるのは画像認識領域です。一言でお伝えすると、デジタルセキュリティを中心とした映像解析技術を用いたサービスやソリューションの研究開発です。
日立では、人やオブジェクトの映像認識、高速画像検索や、古いものだと2008年に数百台のカメラを用いた次世代ネットワーク型大規模監視システムなどを提供してきました。
――10年以上前から、そのようなソリューションを提供されてきたんですね。
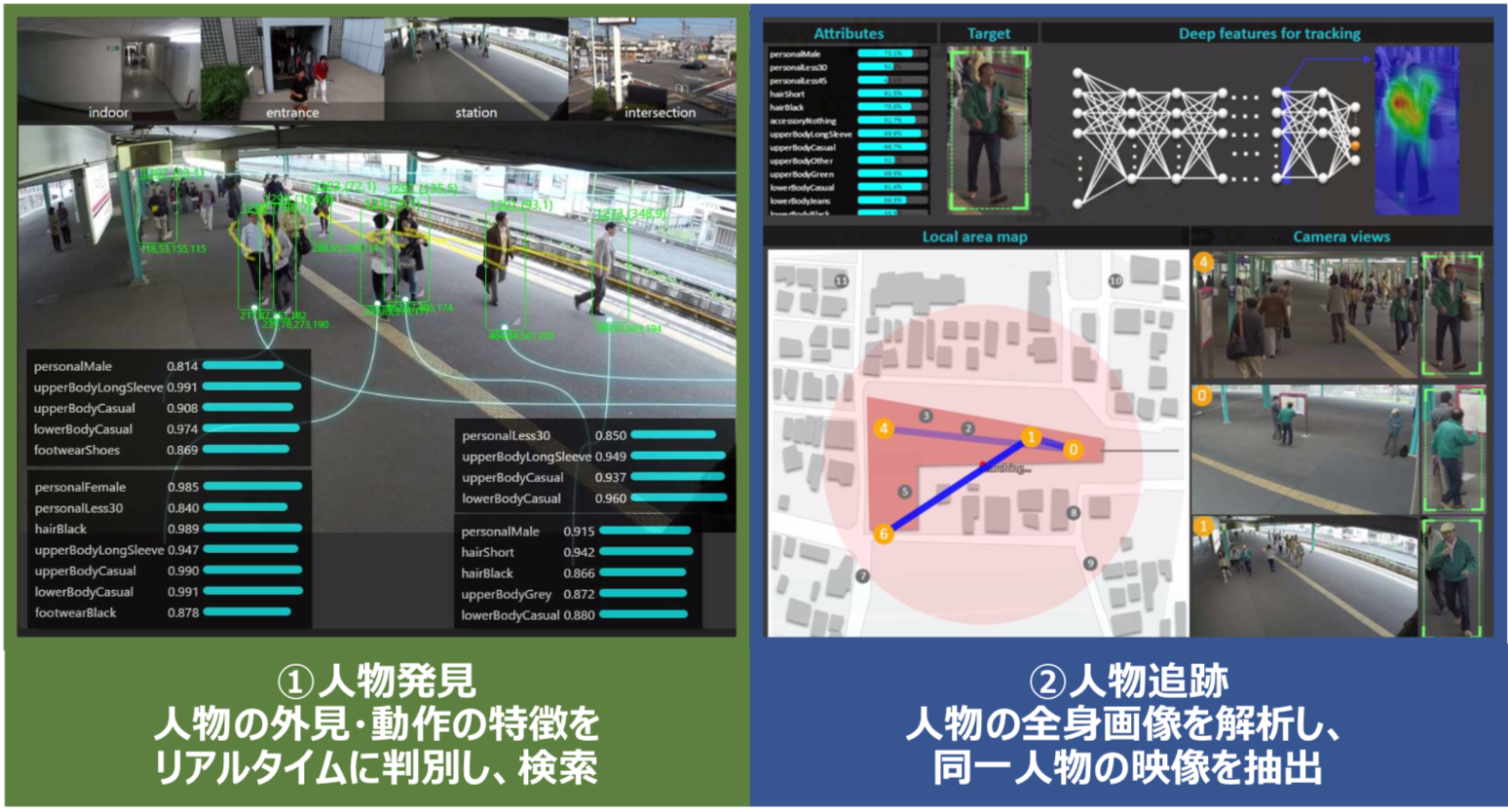
岡崎:そうですね。2014年には大規模重要施設のセキュリティサービスの強化に向けた本人認証・危険物検知・不審者追跡技術(MPS:Multi-Perspective Search)を開発しており、それが現在の、ディープラーニングを活用した映像解析によるリアルタイムな人物発見・追跡技術(MPS-AI)へと進化していきました。
100項目以上の属性をリアルタイムに識別して、人物の全身特徴を抽出することで数万人を1秒で追跡するということを可能にしています。
DCASE 2018 Challenge Task 5にて1位タイを獲得

――川口さんはDCASE、岡崎さんはTRECVIDと、それぞれ国際的なコンペに参加されて成果を出されていると伺っています。まずは、それらコンペの世界的な潮流から教えていただけますか?
川口:音声や音楽関係だと、2002年から話者ダイアライゼーションのDARPA EARSというのがあり、その後、2005年から音楽情報処理のMIREX、2007年から音源分離のSiSEC、2011年から音声認識のCHiMEといったコンペが開催されてきていました。
その成功を受け、ヒトの音声や音楽だけでなく環境音から何が起こっているかを対象とするDCASE Challengeというコンペが2013年から始まりました。
以降、年々進化しています。
――どんな形で進化しているのでしょう?
川口:開催当初は単純なタスクが多かったのですが、例えば訓練データとテストデータの間で録音する機器が違ったり、録音場所が違ったり、訓練データのラベルの情報に欠損があったりと、よりリアリティがあるタスクへと進化していってますね。
また、オーディオキャプショニングと呼ばれる、文章での説明を出力するような難易度の高いタスクも出てきていて、かなり進化しています。
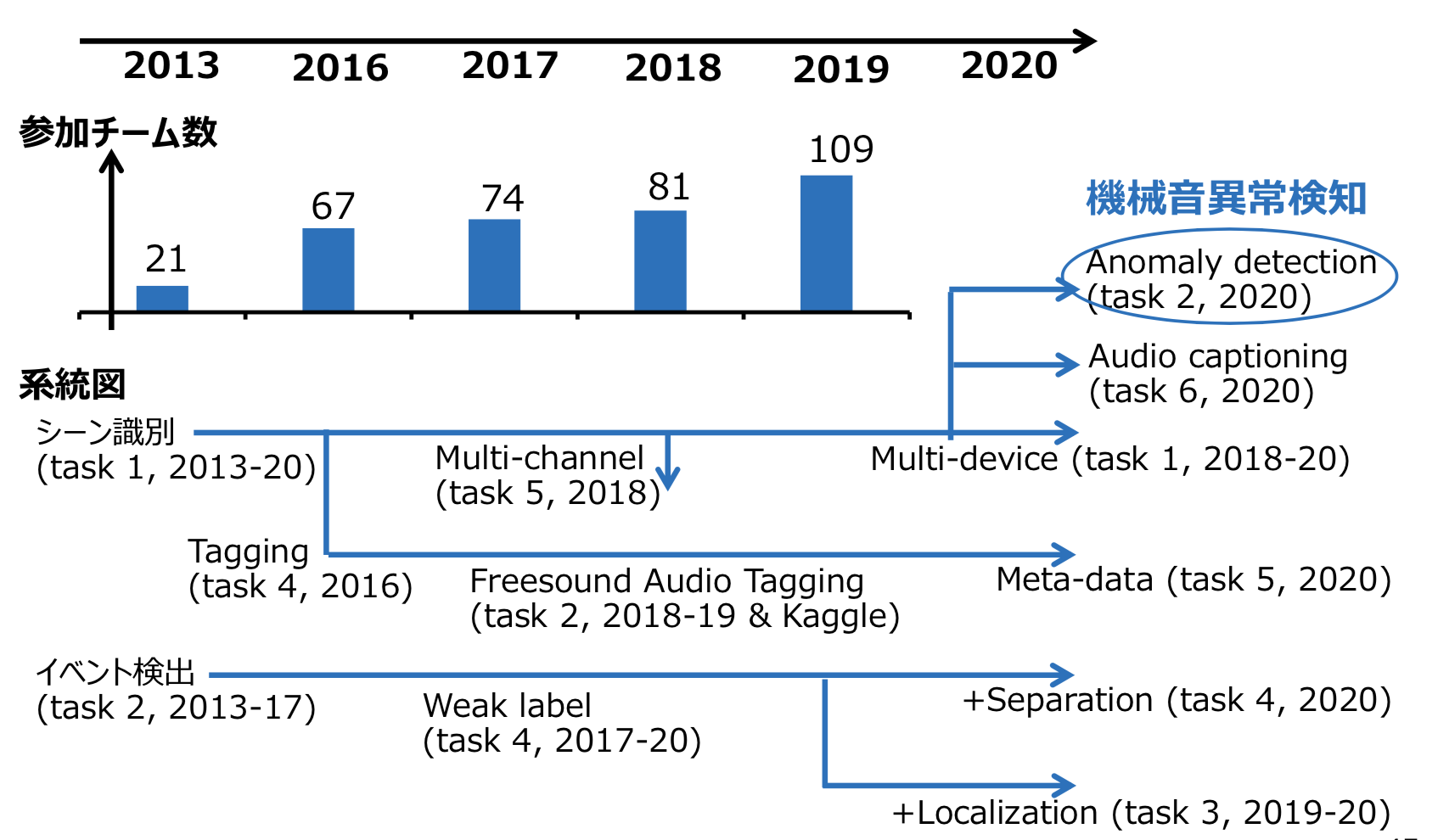
DCASEコミュニティの公開データを基に川口氏が作成
川口:私たちはその中で、2018年の複数チャンネル向けシーン識別である「DCASE 2018 Challenge Task 5」に参加し、結論としては、そこに投稿したシステムの最終評価として12チーム34投稿中1位タイを獲得しました。
研究者は、もっとリスクテイクするべき

――国際的なコンペで1位を獲るのは、すごいことだと思います。そもそもですが、どのような経緯で2018年のDCASEに参加されることになったのでしょうか?
川口:DCASEとは違う騒音環境下での音声認識のコンペ「CHiME(チャイム)」というものがあるのですが、それの2015年度開催のCHiME3に日立チームとして参加しました。主担当は藤田さんをはじめとする音声関連のメンバで、リーダは当時日立にいらっしゃった戸上さんという方で。
その時に、そういう国際コンペに参加するとみんなのレベルや意識が上がるな、ということを体験し、音声認識以外でもコンペに出したいなと思ったのがそもそものきっかけでした。ちなみにその後、私は関わっていませんが、CHiME5では日立チームが2位を獲得しています。
その後2016年には、当時NECにいた小松さんという方がDCASEで1位をとったというニュースを知り、その時はDCASEというものを知らなかったので、これはいいなと思いました。当時、異常音検知のコンペ自体は存在しなかったのですが、このタスクも本質的な課題は共通なので、1位を獲得すればメリットは十分にあるなと。
――なるほど。別コンペへのご参加がひとつの刺激になったんですね。
川口:そうなんです。翌年の2017年(DCASE 2017 Challenge)には出したいなと思ってはいたのですが、その時はリソースがなく、チェックだけしました。
翌年に向けて必勝法を探していき、「多種のフロントエンドとバックエンドを執拗にアンサンブルする」という必勝パターンが見えた気がしたので、それと合わせて2018年時点にKaggleなどで効果が報告されていた画像認識向けpre-trainedモデルの利用などの方法を採用して、参加した次第です。
ここでいうフロントエンドとは、残響除去や音源分離などの信号を入力として信号を出力する処理のことを意味し、バックエンドとは特徴量抽出と最終層を組み合わせて、入力信号に対してラベルやスコアを出力する処理のことを意味しています。最終的には356個のサブシステムを形成して、多数決をとって(Late fusion)アウトプットしました。
多種のフロントエンドを使ったtest time augmentationを含むdata augmentationは行いましたが、当時流行り始めていたMixupなどはコンペには間に合いませんでした。
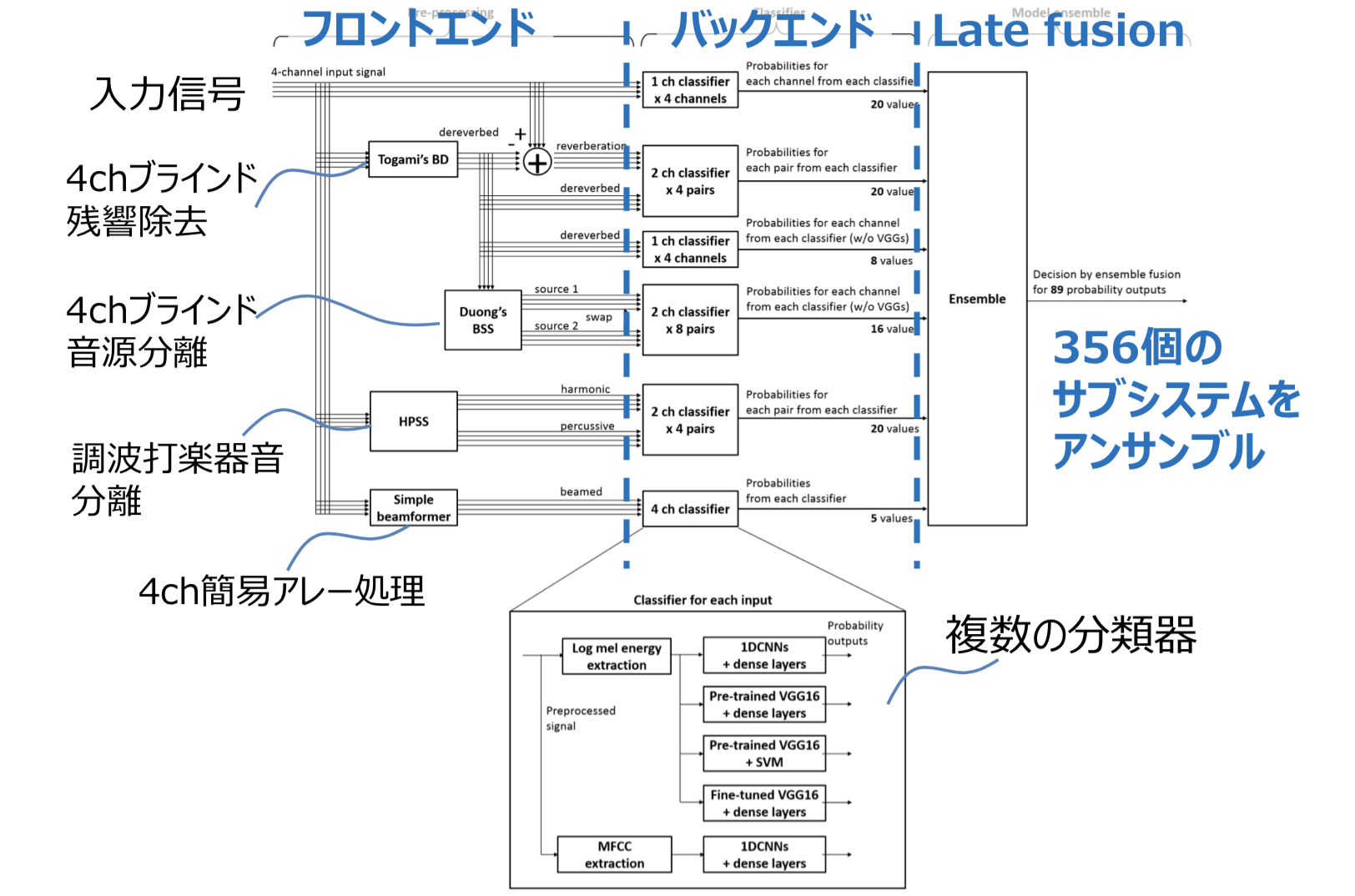
DCASE 2018 Challenge Task 5で投稿されたシステムの概要
――実際にコンペに参加されて、成果として1位を獲得された感想はいかがですか?
川口:まず、このコンペで主担当だった田邊さんはじめ、当時のチームメンバに感謝と敬意を表したいです。前回のインタビューで話していたフォンさんも。
また、目的達成の上でも満足しています。研究所の目的としては、ベースライン+αによる技術力向上や製品開発や受注の後押しがありましたが、それと並行して、個人的にはリスクテイクの文化を研究所に根付かせることをもうひとつのミッションに据えていました。
私たち研究所のメンバーは、基本的にはリスクテイクする機会というものがありません。本来、目標設定は、リターンの大きさと目標達成確率の両方を勘案して行うべきですが、実際には目標達成確率に高いウエイトが置かれた目標設定がされる傾向がありました。
一方で、本来の研究開発というものは、ハイリスク・ハイリターンでボラティリティが高いものです。成功することしかやらない研究開発は、高ボラティリティを期待しているはずの様々な投資者の期待には応えられませんので、もっとリスクテイクするべきだと考えています。
――素晴らしい視座ですね。
川口:チャレンジした目標を設定して、背水の陣で臨む。それくらいのヒリヒリした覚悟でやるのが良いんじゃないか、という気持ちがあったわけです。
そうしたら、人って本気を出すんですよ。しかも、宣伝にもなるし、製品開発の後押しにもなるなど、多くのメリットもある。チーム自体も底上げされることになります。
結論としては、製品化の後押しもできたし、リスクテイクとしては成功したのかなと思っています。
様々な災害画像を精度高く認識するためのマルチラベルマルチクラス学習技術
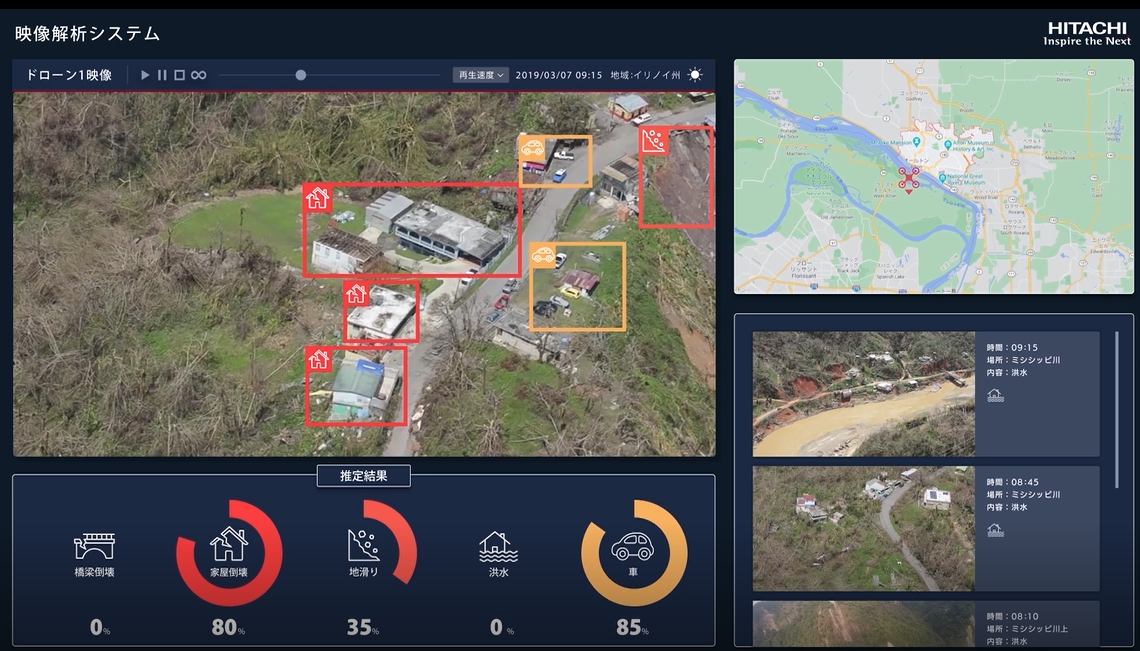
――岡崎さんは昨年3月に日立へと転職されたわけですが、はじめにどんなミッションを受けたのでしょうか?
岡崎:日立では2015年から毎年TRECVIDのコンペに参加していまして、今年は誰が取り組むのかとなった際に、これまでのKaggleなどに参加してきた経験を踏まえて、私がやることになりました。
目標順位は1位と設定されていたのですが、そもそもコンペ自体がどういう難易度か分からなかったので、個人的には結果は気にせずに取り組んでいました。
――TRECVIDは、歴史の長いコンペティションなんですよね。
岡崎:そうですね。2001年からアメリカ国立標準技術研究所(NIST)が毎年開催している大規模映像の意味理解や検索技術関連のワークショップで、私たちはその中でも、災害映像解析コンペティションである「TRECVID 2020 DSDI Task」に参加しました。
日立がこれまで培ってきた映像解析技術の知見も活かして、自然災害画像を高精度に認識できる災害画像解析技術を開発し、トップレベル精度及び目標順位を達成するに至りました。
――着任早々素晴らしいですね。災害画像解析技術は、具体的にはどんな内容なのでしょうか?
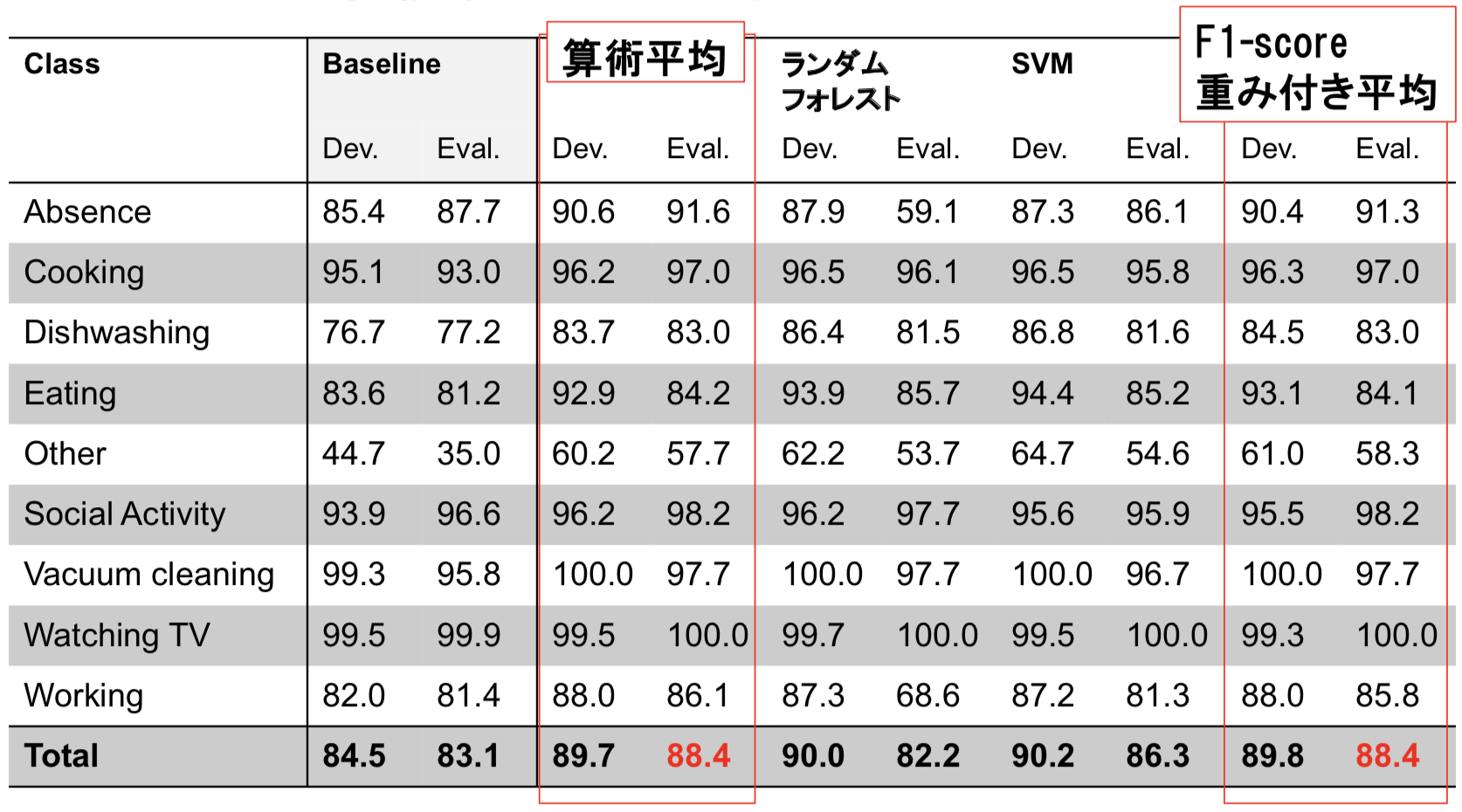
岡崎:今回のコンペでは、航空画像や空撮画像から、その画像に映っている複数の災害属性を高精度に把握するという技術を競いました。
空撮した画像は高解像度の大きなデータだったので、洪水や土砂崩れ、森や道路など、様々な属性が写り込んでいます。
よくある機械学習としてはシングルラベルのマルチクラス問題になるのですが、今回はひとつの画像内の全ての属性に対して、あるかないかを予測していくというタスクだったので、複数の災害属性を同時に精度良く認識できる「マルチラベルマルチクラス学習技術」を開発し、様々な災害画像を精度高く認識できるようにしました。
――技術的に最も難易度が高かったポイントは何でしょうか?
岡崎:大きくは3つありますね。
まずはマルチラベルに関連して、設定された属性は32クラスあるのですが、これら全ての属性が均等に用意されているわけではなく、例えば洪水だと1万枚あるのに対して、土砂崩れは100枚しかないなど、クラスごとのデータ数にばらつきがあります。つまり、普通に学習すると大量の洪水データに引っ張られてしまうことになります。
そこのアンバランスに対応するアプローチとして、特性の異なる3種のネットワークを利用してクラス間のバランス制御処理を導入したのが、ひとつのポイントだと思います。
また、空撮画像という特性上、例えば小さな車が写っていたとしたら、それを正確に認識する必要があったので、その点も難易度が高かったと感じます。
あとは、32クラスの属性全てについて1枚の画像をラベルづけするマルチラベルのアノテーションは、そもそも難易度が高いものです。ノイズがたくさんあるアノテーションラベルを使って、どのようにうまく学習させていくのかを考えるのも、難しいポイントでした。
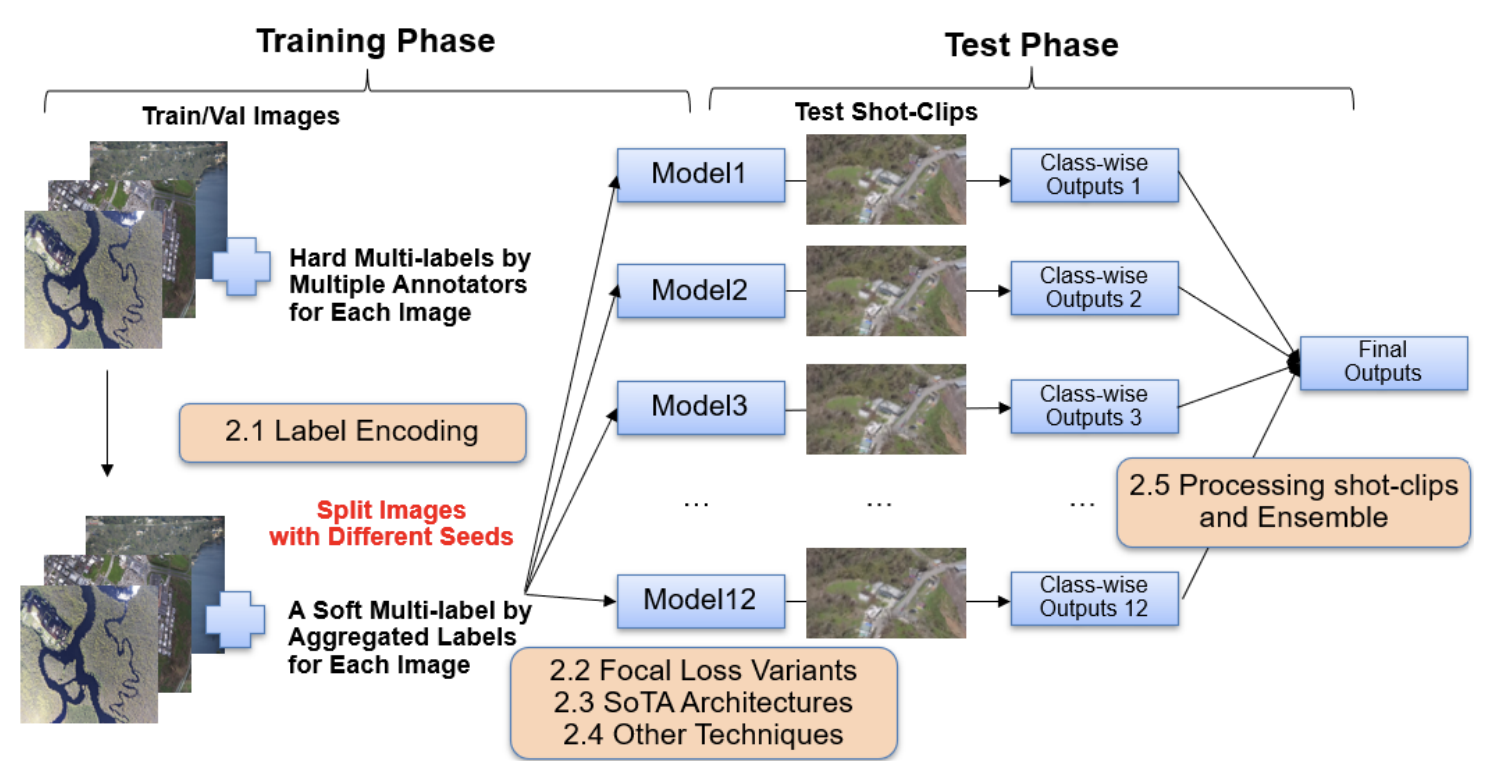
――なるほど。先ほどの川口さんの「リスクテイク」のお話を受けて、岡崎さんとしては転職組としてどう感じられましたか?
岡崎:前職も色々やらせていただいてとても良い研究環境だったのですが、やはりセキュリティの会社ということもあって論文を外に出したり、技術を公開するといったことが中々厳しいという難点がありました。
その点に関しては、日立は論文を出すのが推奨されていて、結果をアウトプットするのが求められているので、そういう文化が積極的に作られているのはとても良いと感じています。
タスクをどうやって作っていくか、はすごく難しい問題

――先ほどお話いただいた技術的なポイント以外に、コンペで成果を出すためのアクションって、どんなことがありますか?
岡崎:データセットの課題を最初に精査したのが、良い結果に繋がったのかなと感じています。統計分野で「EDA(Exploratory Data Analysis:探索的データ分析)」という概念があるのですが、それを今回はやりきれたかなと思います。
モデルを作る際も、正解率やランキングスコアなど様々なメトリックがあるのですが、コンペで指定されたメトリック以外にも、モデルの挙動を見るために様々なメトリックを導入していまして、そういう複数のメトリックでモデルがどういう感じで学習しているかをモニタリングできたというのが、継続的なモデルの改善に繋がったのかなと。そこをしっかりできたのがよかったかなと思っています。
川口:EDAをやられた点について、オーバーフィッティングはどうでしたか?
岡崎:そこは確かに問題で、学習データをtrainとvalidationに分けて、複数のメトリックでオーバーフィッティングしていないかを常に確認していました。
今回のコンペは特殊で、リーダーボードはないし、学習データは画像なのですがテストデータは映像なんですよね。映像をエンコードして画像に直して、1枚1枚に対する結果を統合してシステムに提出するという形で進めたのですが、どういう形で統合したら良いのか、例えばある属性が一瞬でもその映像に映ったらその属性はあるとしていいのかなど、その辺りの結果に関わる点がコンペの主催者から示されなかったので、そこは雰囲気を見ながら進めていきました。
川口:それは辛いですね(笑)オーバーフィッティングはどこまで追い込むか、きつい問題があるじゃないですか。追い込みすぎると良くないし。そこのさじ加減は、どうされてましたか?
岡崎:正直、勘ですね(笑)
今までいくつかのKaggleのコンペティションに参加してきて、Kaggleだとオーバーフィッティングしていると最終スコアでガラッと落ちるんですが、そこで落ちないための工夫をするといった経験があったので、今回もオーバーフィッティングをある程度避けることができたのかなと思います。

川口:なるほど。この辺は、データセットによるところもありますよね。ドメインシフトがどこまで起こっているのかなど、どこまで信頼できるかがポイントだと思うのですが、その辺りはどうでしょう?
岡崎:テストデータは見てはいけないことになっていて、ドメインシフトが起こっているのかいないのか、判断ができないという状況でした。
システムの最終提出にいくつかモデルの結果を投げれるんですが、その際に、ドメインシフトへの対応処理を入れたモデルの結果と、対応処理は入れてない、手持ちのデータで最も良いモデルの結果をそれぞれ投げて、どっちかが当たればいいかなくらいの感じでやりました。
今回は、ドメインシフトへの対応処理を入れたモデルの方が最終スコアが悪かったですね。
川口:なるほど。そういうことってありますよね。
岡崎:もともとドメイン適応の研究をしていたので、そういったアプローチもなんとなく知っているつもりでやったのですが、やはり論文とコンペとだと、なかなかギャップがあるなと感じます。
川口:コンペで与えられるデータセットが神様かというと、すごく難しい問題があって、たとえば、そのデータセットで起こるドメインシフトや分布の偏りが本当にリアルなドメインシフトや分布の偏りなのか難しいところがありますよね。
リアルには起こらないようなドメインシフトや分布の偏りが、もしかしたら起こっているかもしれなくて、そうだとするとそこに対して1位をとってもあまり意味がない。
タスクをどうやって作っていくかという観点でも、すごく難しいなと思います。
2020年のDCASE Workshop (DCASE Challengeと関連して開催される国際会議) には私もGeneral Co-Chairとして開催に携わったのですが、そこでNII(国立情報研究所)の佐藤真一先生にキーノートスピーチをしていただきまして、そのときもコンペのあり方についてお話をされていました。興味深い話として、TRECVIDのデータセットの分布は、あの有名なImageNetとは違うところがあると。
ImageNetでは各クラスのサンプル数が同程度なのですが、TRECVIDのデータセットでは各クラスの出現頻度が自然に出現する頻度 (Zipf則) に従っていて、サンプル数が大きく偏っているそうです。TRECVIDのように偏りの大きい分布がいわば自然なわけです。
しかし、無邪気に自然が良いというわけでもなくて、良し悪しがありますし、データの偏りはAIによる差別・偏見の原因でもあるので、AI倫理の問題とも強く関わっています。いずれにせよ、データセットの分布の偏りは作成者のスタンスに大きく依存するので、それで良い精度を出したとしても、本当に意味のあるものなのかが結構難しいなと思いました。
コミュニティをリードしたくて、DCASE参加側から主催側にシフト

――今、DCASE Workshopを開催されたというお話がありましたが、その意図についても教えてください。
川口:日本を含めてアジアは、この分野の研究者人口が多いのにも関わらず、これまでDCASE Workshopを開催していませんでした。アジア初開催で盛り上げることを狙って、日本の研究者で協力して誘致し、誘致案が採択され、開催することができました。
COVID-19の影響でオンライン開催となりましたが、参加者数はこれまでで最も多く、音響認識分野を盛り上げられたと思います。
また、これと並行して、2020年のDCASE 2020 Challenge Task 2において、機械の異常音を検知するというコンペティションを開催しました。
――そうなんですね。コンペティションはどのような意図で開催されたのでしょうか?
川口:何点かあるのですが、一番は主体性をもってコミュニティをリードしたいと感じたからです。いつまでもお客さんだとフリーライドし続けてしまう。それではダメだなと。コミュニティに対しても申し訳ないし、待ってるだけだとできることが限られてしまいます。
そもそも私たちが現在メインで取り扱っている機械の異常音検知は、教師なし・半教師あり・教師ありの全てのシナリオにおいて高い精度で動作するようにしたいし、騒音が大きくても間違えないようにしたいなど、様々な課題があるのですが、それらを全て解くにはコミュニティ自体が小さいという課題がありました。
だからこそ、コミュニティを拡大するために、まずは日立から無料でデータセットを公開することにしました。
それが、機械音データセット「Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection」いわゆる「MIMII Dataset」です。4種類の機械(バルブ、ポンプ、ファン、スライドレール)と、機械の種類ごとにメーカーの異なる7型式の製品からなるデータセットでして、正常音を収録したものは計26,092ファイル、異常音は計6,065ファイルを用意しました。
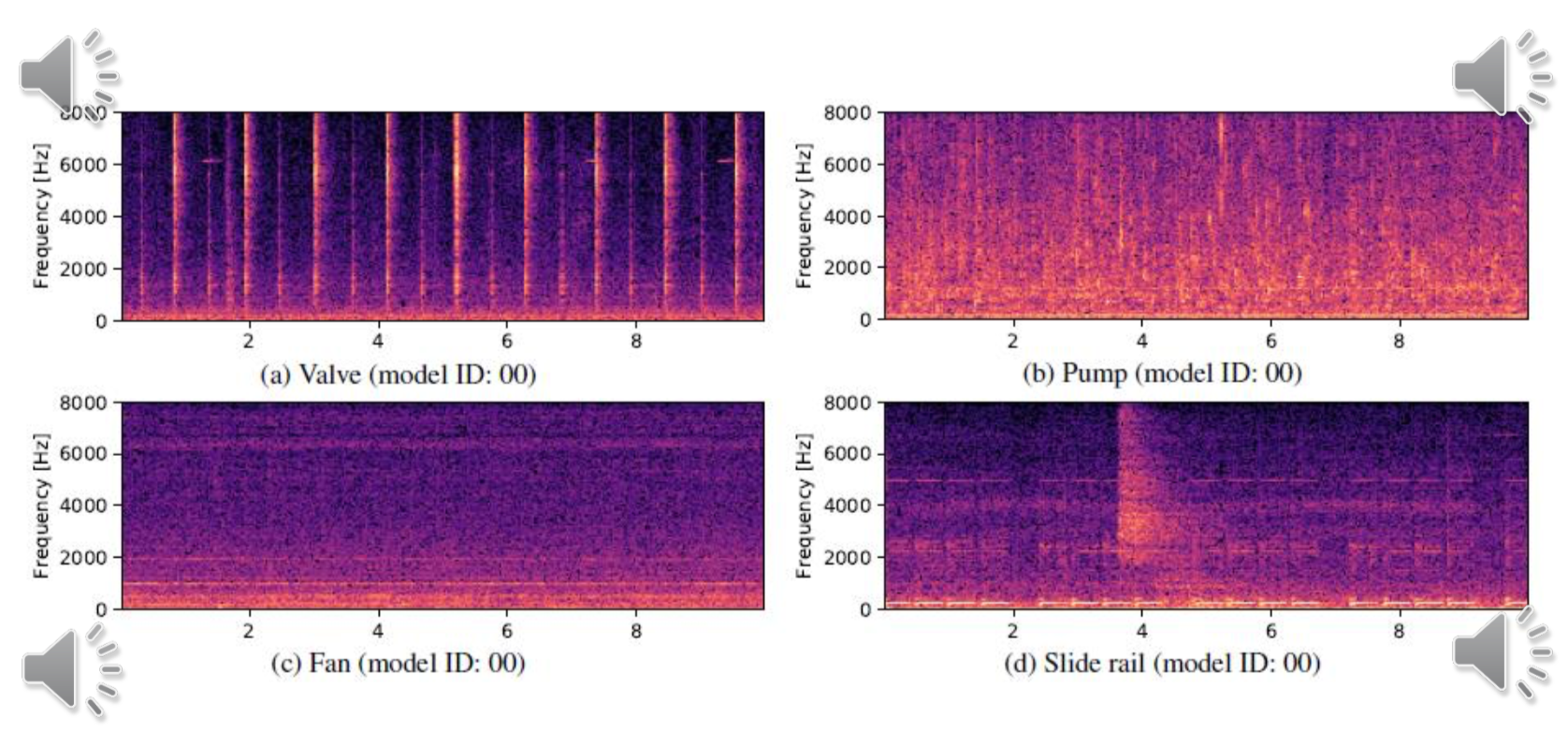
それぞれの音の特徴が全く異なる4種の機械を選定している
――競合他社に無償でデータを提供して、大丈夫なのでしょうか?
川口:日立の社内で収録した機械音のみを日立が公開する限りは、デメリットはほとんど無いと考えています。日立では幸いにして公開できるもの以外にも公開できないものを含めてデータはたくさん手に入ります。ですから、自社内で収録した機械音だけであれば、 公開したところで問題になることはないんです。
実際に2019年9月にリリースして、2020年11時点で累計ダウンロード数が46000件以上になるなど、想定以上に反響をいただきました。
――そんなにダウンロードされたんですね!
川口:ちなみにNTTさんからも、2019年におもちゃの機械音データセットである「ToyADMOS(トイアドモス)」がリリースされていて、MIMII Datasetと合わせて使うことで、様々な機械に対する異常検知の性能を同時に評価できるようになりました。
そんな流れから、2020年のDCASE Challengeとして教師なし異常音検知のタ スクをNTTおよび同志社大学の先生と共同で提案し、無事に採択されてTask 2として開催することになりました。
――なるほど。開催結果としてはいかがでしたでしょうか?
川口:単独タスクとしては過去最多の40チームが117システムを投稿して大いに盛り上がりました。機運を盛り上げて異常音検知コミュニティを形成することに成功したと自負しています。
日立の「頑張ったら報われる」という文化がすごく好き

――すごく面白いお話でした。今後についても、社会実装のイメージなど可能な範囲で教えてください。
川口:まずは近いところとして、DCASE Challengeでは2021年も引き続き、我々が主催するタスク(DCASE 2021 Challenge Task 2)を開催します。テーマとしては昨年と同じく「機械音の異常検知」でして、今回は「ドメインシフトがあっても異常検知できますか?」という問題設定で3月からスタートします。
その先の技術の社会実装としては、まだ公にお伝えできないことが多いのですが、2020年10月に製品を出したことで、引き続き研究所としては事業部と連携してお客様の異常音検知の課題解決を支援していきたいと考えています。
中長期的には、グローバルな市場を見据えた展開を想定しているという感じですね。
岡崎:今回は災害検知タスクということで、空撮画像からどういった災害が起きているかを予測するタスクでしたので、例えば設備管理への応用を考えています。例えばドローンや人工衛星からとった映像を自動で判別にかけて、危険の予兆を見極めるのに使えたらなと。
あとは、コンペの延長として現在着手しているのが、金融事業部のリモート査定についてです。つまり、人工衛星から撮った画像で家の壊れ具合を機械学習で推定して、被害に応じた迅速かつ最適な調査員の派遣を行ったり、明らかに壊れている家に関しては調査員を派遣せずに遠隔で補償金を支払う、といった応用ケースを考えています。
――ありがとうございました!最後に、それぞれ読者の方にメッセージをお願いします。
岡崎:私が所属する部署としては、セキュリティを機械学習で良くしていこうというミッションを持っているので、コンペ技術を通じて社会を良くしていけたらと思っています。
あとは先ほどもお伝えした通り、日立はコンペや論文など、自分の研究内容をアウトプットできる場が豊富で、今回みたいな取材やニュースリリースといった形でも結果を対外的に働きかけてくれるので、頑張った分評価してもらえるといった環境はありがたいなと思いますね。
川口:私としては先ほどお伝えした通り、計画的にリスクテイクすることの重要性をお伝えできたらと思っています。
組織としてのメリットもありますし、自分自身の幸せのためでもあると思います。
あと、DCASE2021 Challenge Task 2、ぜひ参加してください!
編集後記
コミュニティにしっかりと貢献し、積極的にリスクテイクしてでもチャレンジとしての研究テーマを進めていく。非常に熱く、それでいて企業と個人と社会の三方にとっても非常に良い。そんな、非常にポジティブなマインドに触れることができた素敵なインタビューでした。
無難な目標設定を行って、スロースピードで研究していく。そんな、一般的な日本の大企業が抱える研究所にもたれるイメージとは裏腹の、刺激的なフィールドだと感じた次第です。自身の研究領域に関するアウトプット文化が少ない等で悩まれている方は、日立製作所は良い環境なのではないでしょうか。
取材/文:長岡 武司
撮影:平舘 平
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立の異音検知ソリューションが「第29回 日本音響学会技術開発賞」を受賞!
詳細はこちら
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所経験者採用実施中!
音声認識、音響認識、または時系列信号処理に関する研究開発
募集職種詳細はこちら
映像解析技術の研究開発
募集職種詳細はこちら
日立製作所の人とキャリアに関するコンテンツを発信中!
デジタルで社会の課題を解決する日立製作所の人とキャリアを知ることができます
Hitachi’s Digital Careersはこちら