「中央集中型クラウドと分散エッジクラウドの共存によるスケーラブルアーキテクチャ」Qiita Conference 2024イベントレポート

2024年4月17日〜19日の3日間にわたり、日本最大級*¹のエンジニアコミュニティ「Qiita」では、オンラインテックカンファレンス「Qiita Conference 2024」を開催しました。
*¹「最大級」は、エンジニアが集うオンラインコミュニティを市場として、IT人材白書(2020年版)と当社登録会員数・UU数の比較をもとに表現しています
当日は、ゲストスピーカーによる基調講演や参加各社のセッションを通じて、技術的な挑戦や積み重ねてきた知見等が共有されました。
本レポートでは、アカマイ・テクノロジーズ合同会社のクラウドソリューションアーキテクトとして活動している伊東 英輝氏によるセッション「中央集中型クラウドと分散エッジクラウドの共存によるスケーラブルアーキテクチャ」の様子をお伝えします。
※本レポートでは、当日のセッション内容の中からポイントとなる部分等を抽出して再編集しています
登壇者プロフィール

クラウドソリューションアーキテクト
エッジとは

伊東:本日は「中央集中型クラウドと分散エッジクラウド共存によるスケーラブルアーキテクチャ」についてお話ししたいと思います。
最初は「エッジとクラウド」ということですが、集中型クラウドと分散エッジをどのように共存させるか、「二択ではなく、必要に応じて選択する」ことが大きなテーマだと考えています。
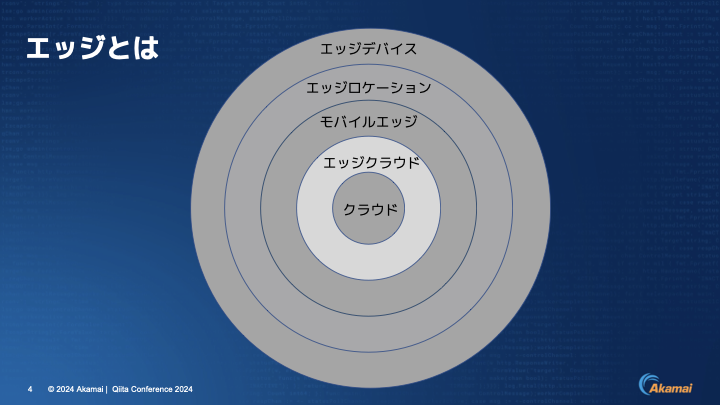
伊東:エッジには、周辺や縁、端などの意味があり、真ん中にクラウドがあって外に向かって様々なエッジが広がっています。
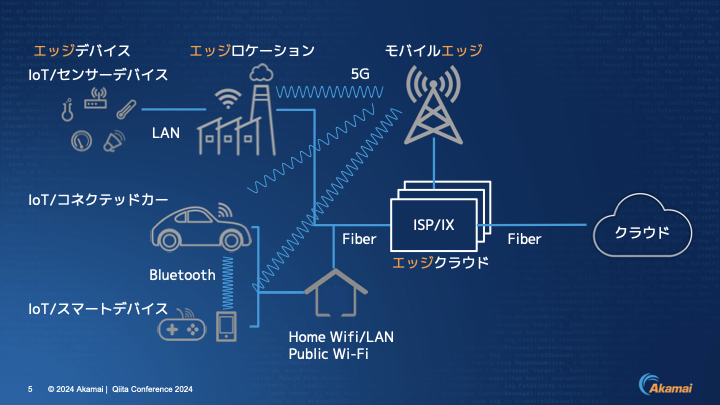
伊東:もう少し詳しくお伝えすると、このような概念図で説明できます。右側にクラウドがあり、その横にエッジクラウドがあります。
世界中のISP(インターネットサービスプロバイダ)もしくはIX(インターネットエクスチェンジ)に配置されているサーバー群です。さらにその奥に行くとモバイルエッジがあり、キャリアさんがMEC(Multi-access Edge Computing)という形でそこにサーバーを置き、より近いところで応答できるようにしています。
工場などにおいて、ファクトリーオートメーション等に代表されるようにエッジサーバーを置くケースについてはエッジロケーションと記載しています。
さらに奥にいくと、人に近いところ、もしくはデバイスそのものになりまして、IoTやセンサーデバイス、コネクテッドカー、スマートデバイスなどがあります。
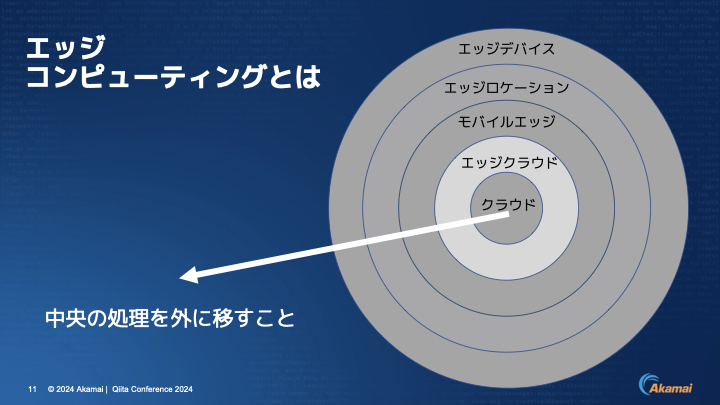
伊東:要するにエッジコンピューティングとは何か?を簡単にお伝えすると、外側にロジックを広げて中央の処理を外に移すことだと言えます。
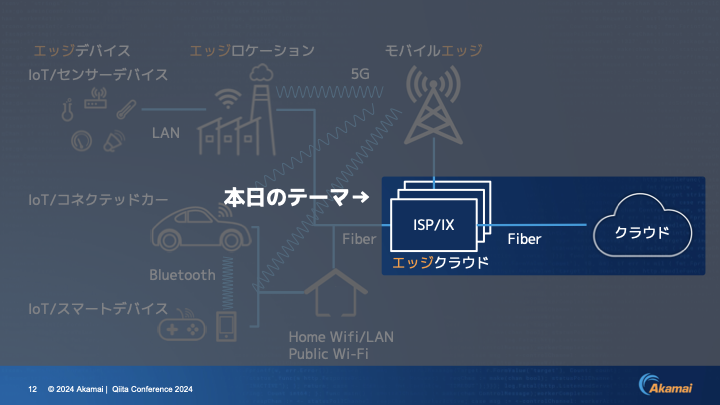
伊東:本日お話しするテーマの1つ目は、クラウドとその横にあるエッジクラウドについて、インターネット上にあるエッジはどう共存していくのか、です。
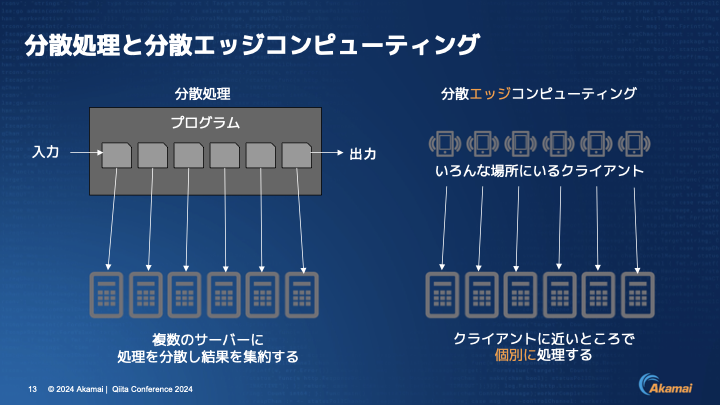
伊東:それから2つ目のテーマが分散と集中ということで、ここでは分散処理と分散エッジコンピューティングの違いについて見ていきます。
まず左側の分散処理ですが、入力と出力の間にある処理を分散して複数のサーバーに依頼し、その集計結果を基にして1つの出力を返すのが分散処理になります。
それに対して今日のテーマになる分散エッジコンピューティングというのは、様々な場所にクライアントがいて、クライアントに近いところで個別に処理し、リアルタイムに応答するということです。
スケーラビリティに貢献するエッジソリューション

伊東:オリジン負荷に対するエッジソリューションというのは様々ありまして、絶えずイノベーションが起きています。

伊東:例えば左側にクライアント、右側にオリジンクラウドサーバーがあったとして、その間にあるエッジのミドルマイルには、地域制御や、セキュリティ、アクセス制御、フロー制御、CDNの特徴であるキャッシュなど、様々な機能があります。1つずつ見ていきましょう。

伊東:地域制御に関しては、そもそもIPアドレスがあるので、それでジオロケーションを判定して地域に分散したり、地域で流量を管理するようなものがあります。

伊東:セキュリティについては、例えばIPアドレスを見て「そのIPは通していい、通してはいけない」という判断を動的に行うようなソリューションや、DDoSのような大規模な攻撃に備えるソリューションなど、その他ここに記載したようなものが出てきました。

伊東:IPのアクセス制御は、そのIPもしくはグルーピングでの制御です。おもしろい機能としては、認証情報は中央のクラウドでやるのですが、毎回コンテンツも含めて中央から返すと無駄なところがあるので、コンテンツがエッジにあればそこから返してしまうような中央検証という機能が挙げられています。またトークン検証や、JWT(JSON Web トークン)のようなものも使えます。

伊東:フロー制御も様々あります。最近ホットだったのは仮想待合室です。コロナ禍にワクチン接種の予約などでサイトが急にダウンしたことに対して、仮想的に待合室をインターネット上で用意してそちらに誘導するようなものが盛んになりました。
スロットリングはオリジンが処理できるキャパシティ以上に流さないようにするものです。
他にも、新しいAPIのリリースがあったときにいきなり流すのではなく、10%だけ新しいバージョンを流して90%は元の古い方のバージョンを流しましょうといったカナリアリリースや、プレミアムユーザーと判断されたものはオリジンに通してそれ以外のユーザーには待ってもらうようなAPIの優先管理などもあります。

伊東:キャッシュは、エッジが一番得意なところです。高度なものになってくるとGraphQL キャッシュや、便利なものとしては毎回エラーをオリジンが返さないようにするようなエラー応答も有効です。キャッシュの高速パージといったことも当然できます。

伊東:最後に便利な機能と付加機能をこちらにまとめています。

伊東:レイテンシーを求めるアプリケーションはもう必要ないから、全部エッジでやる必要はないのではないかという議論もよくあります。まさしくおっしゃるとおりで、結局レイテンシーというものは距離の問題なので、距離とネットワークの帯域がどれくらいあるかという話になります。
日本でいうと、国土が狭く、世界でもトップ10に入るぐらいのインターネット速度を持つ国でもあるため、クラウドは一箇所で良いのではないかという議論も当然あります。

伊東:一方で海外への速度は速くなっておらず、海外へのトラフィックでのレイテンシーも感じます。私自身、先月海外の予約サイトを利用したのですが、CDNが入っておらず、とても遅くてフラストレーションを感じました。
東京、カリフォルニア、ワシントン、パリとあったときに、距離が長くなれば長くなるほど遅くなります。ヨーロッパに関しては300㎳(ミリ秒)以上かかるというのは当たり前の話です。
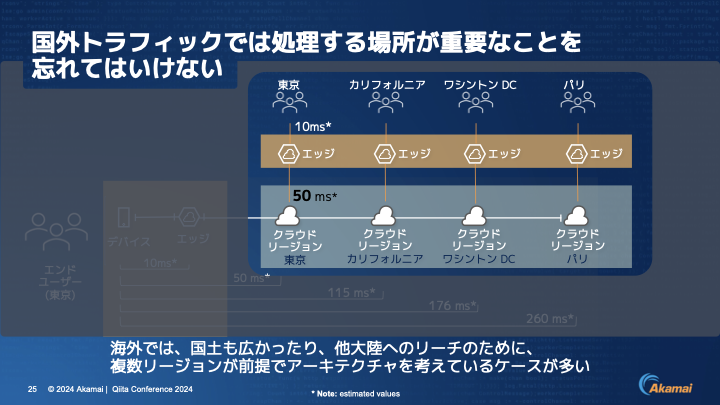
伊東: 国外トラフィックにおいて「処理する場所」が重要なことを忘れてはいけません。
海外では国土も広く、最初からグローバル化を考えているため、複数リージョン前提でアーキテクチャを考えています。東京なら東京、カリフォルニアならカリフォルニアで処理することを前提に、その延長上で様々な国、例えば南米だとかそういうところにリーチしていきます。日本から海外市場を検討するときは、こういうことを考えないといけません。
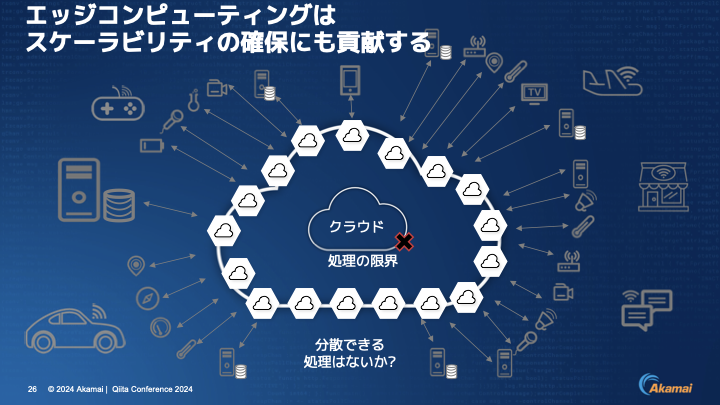
伊東:エッジコンピューティングはスケーラビリティの確保に貢献します。この画像に書いてある通り、クラウドにはどうしても処理の限界というものがあります。その処理の限界を超えるためには、冗長化をしていくわけですが、それにもやはり限界があります。分散できる処理はないか、外に逃がせる処理はないかを考えていく必要があります。
エッジコンピューティングサービスの例
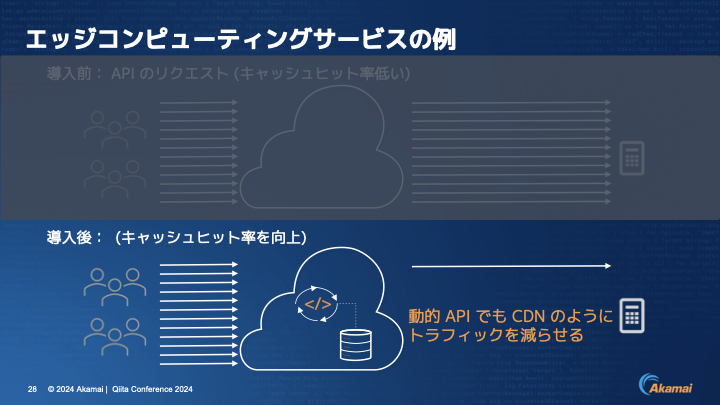
伊東:一般的にAPIはキャッシュできないという思い込みがあると思うのですが、それもあってキャッシュヒット率が非常に低く、結局はエッジを通してほとんど中央に行くケースが多いです。
ですが、エッジコンピューティングを使ったアイデアを少し入れていただければ、動的APIでもCDNのようにトラフィックを減らせるというパターンがあります。これを説明するにあたって、1つ例をご用意しています。

伊東:よくWEBサイトやEコマースサイトで商品クエリサービスがあると思いますが、商品クエリサービスは一般的には誰が見てもいいような情報を返すケースが多いです。こちらの企業さまの場合、商品のA、B、Cなどクエリストリングに商品コードが渡されます。
一般的にCDNのようなものは、クエリストリングを含めたURLでキャッシュのキーを持っているケースが多く、商品コードA、商品コードBとそれぞれ別なキャッシュキーを持っています。お客さまによっては商品点数が何万点もあり、かつロングテール型の商品も多いため、レコメンドエンジンなどによって複数のパターンが生成され、それがエンドユーザーさんからクエリストリングをつけて呼び出されるようになっています。
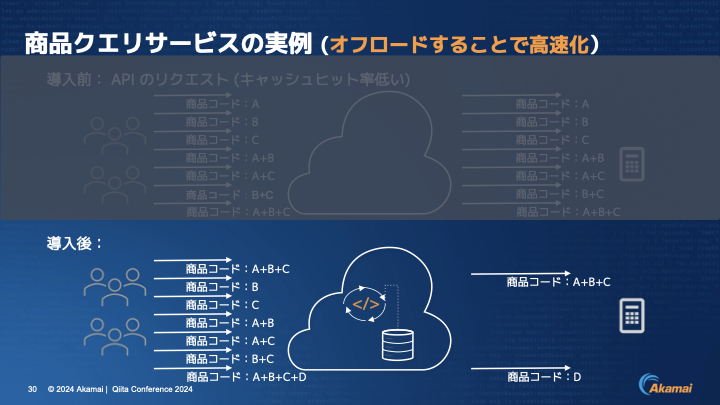
伊東:エッジコンピューティング機能を利用して何を実現したかというのがこちらです。例えば最初にA、B、Cというリクエストがあったときに、当然エッジの方にはデータがないので右側のクラウドの方へ取りに行きます。
そのA、B、Cというコンテンツをきちんと分解し、キーバリュー型データベースにデータを蓄えて、さらにキャッシュします。次にBというリクエストが来たときには、さきほどのクエリストリングのパターンとは違うのですが、Bというコードはすでにエッジに持っているよ、となるので、エッジからコンテンツを返す形になります。
Cも然りです。そのため、A+B、A+C、B+Cという新たなパターンがあっても、一度リクエストを受けたものがエッジにあるのでいずれも返せるということです。
最後に、例えばA+B+C+Dというリクエストがあったときに、新たにDという発見があるので、そのDというコンテンツだけエッジからクラウドの方に取りに行く形で、商品の情報がエッジに溜まっていき、最終的にはオリジンの負荷を減らすということです。このような形で高速化が実現できたと言えます。
すでに一般的な技術となっているスケーラブルアーキテクチャ

伊東:このように、中央集中型のクラウドと分散エッジの共存によるスケーラブルアーキテクチャというのは、既に一般的な技術です。オリジンの負荷に対するエッジソリューションを有効に使えば、今でもスケーラブルなアーキテクチャを実現できます。
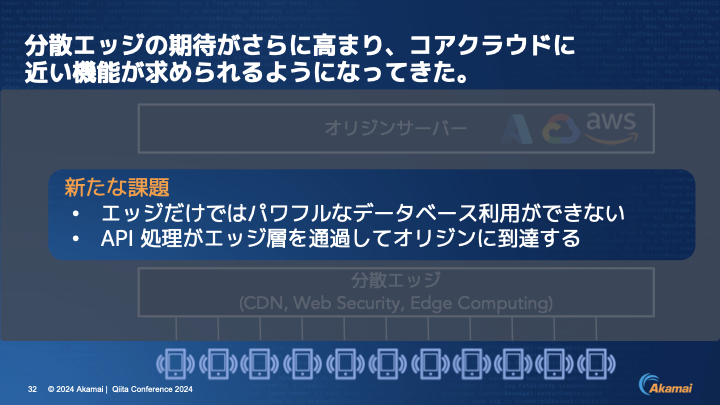
伊東:ただ、皆さまからの要求/要望のレベルが上がってきており、よりコアクラウドに近い機能がエッジに求められているというのが現状になります。とはいえ、エッジのデータベースにはやはりある程度の制約があり、APIの処理がエッジ層を通過してオリジンに到達しているなど、課題はまだあります。
そして最近出てきたのが、分散エッジとクラウドの間に地域クラウドという新たな層を作って、その地域クラウドと融合することでスケーラブル化するというアーキテクチャです。
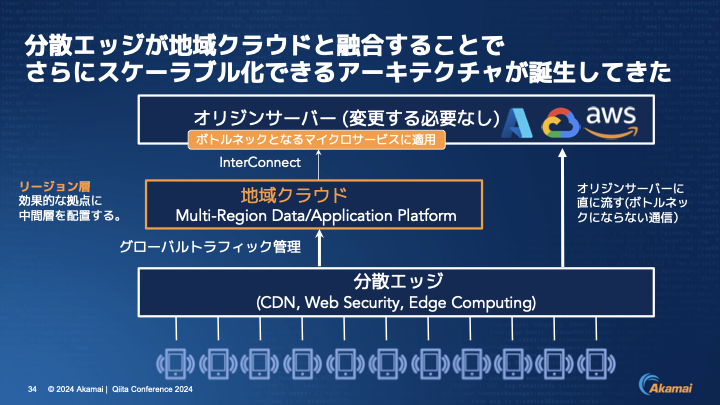
伊東:先ほどと何が違うのかというと、中間層、地域クラウドの層ができています。

伊東:これは、全てのトラフィックをこのようにしようという提案ではなく、ボトルネックになるマイクロサービスに適応しましょうという話です。このAPIリクエストをもう少しオフロードするとパフォーマンスが上がるとか、オリジンの処理が下がってオリジンのコスト削減につながるようなモチベーションがある場合に有効なやり方です。
中央にMulti-Region Data/Application Platformと書いてありますが、1つのクラウドだけでなく、複数のクラウドを使うケースが出てきています。
もちろん1つのクラウドでもいいのですが、複数のクラウドがあった方が分散できて、エンドユーザーから一番近いところが応答できるという面では有利かなと思っています。
分散エッジから地域クラウドのところに関しては、分散エッジが持っているグローバルトラフィック管理機能を使って、一番近いクラウドにナビゲーションしていきます。地域クラウドとオリジンサーバーに対しては、InterConnectという形で帯域の広い高速のネットワークを持っていますので、そこもうまい形でつなぎ込むことができます。
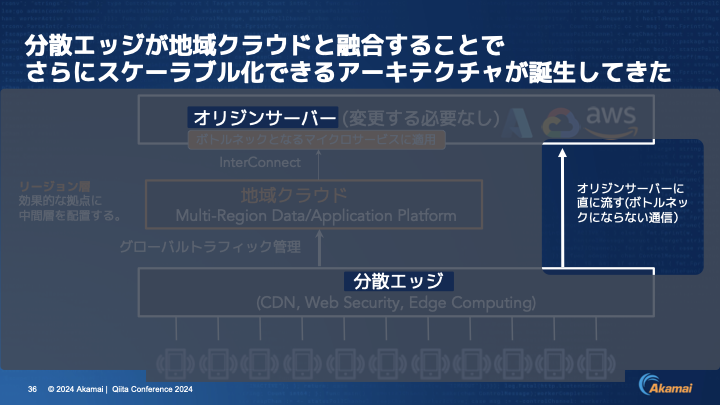
伊東:もう1つのメッセージとしては、ボトルネックにならない通信はこのようなアーキテクチャにする必要ないですよ、ということです。分散エッジの方でルーティング機能を持っていますので、そこでボトルネックになるAPIを特定し、地域クラウドに流すかオリジンへと直に流すかを決めるというところになります。そうすることで、簡単にボトルネックになっているところから始めることができます。
地域クラウドの構成例

伊東:地域クラウドって一体何なの?という話ですが、元になるパーツとしては2つあります。1つは下の方にあるIaaSですね。 Multi-Region Cloud Computingと書かれていますが、要するに、地域に最適なクラウドを選択しましょうということです。
必ずしも1つのクラウドベンダーに固まっているのではなく、シンプルなクラウドを使って、そこで皆さまのアイデアでアプリケーションを構築しましょうという話です。
自分でアプリケーションを構築できない場合は、例えばその上の層で別なミドルウェアを提供したり、Multi-Region Data/Application Platformというミドルウェアを活用できます。
例えばHarperDBとかMacrometaというベンダーさんが提供するソリューションは、単一のプラットフォームでデータベースだけでなく、アプリケーションもしくはメッセージング、キャッシュも扱えるようになっています。1つのプラットフォームで様々な処理ができ、かつ分散データベースのような役割を持っているので、地域をまたがってのデータのレプリケーションもできるわけです。
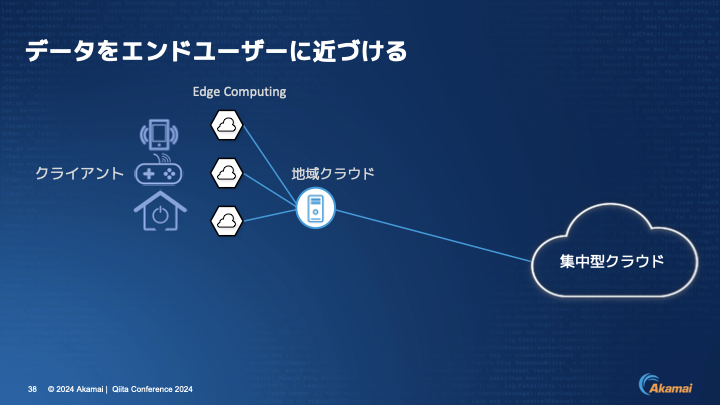
伊東:具体的にデータを持っていく方法ですが、こちらの例では、左側にクライアントがいて右側に集中型のクラウドがあって、その間にエッジコンピューティングになるエッジサーバーと地域クラウドがあります。
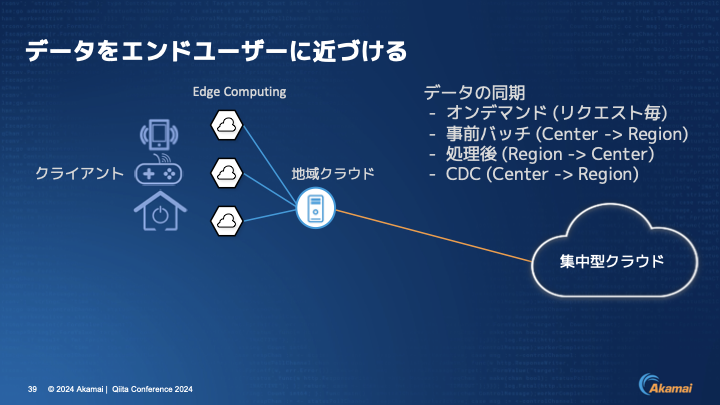
伊東:そこで中央と地域クラウドがどうやってデータを同期するかというと、まずはCDNのようなオンデマンドです。リクエストが来てから、地域クラウドから集中型クラウドへとデータを取りにいくパターンがあります。
もしくは事前バッチです。商品コードなどを中央から地域に事前にバッチで処理するみたいなものです。あとは、例えば地域クラウドでアプリケーションが単独で動いていて、そこにゲームサーバーを配置し、ゲームが終わったらそのゲームのリザルトを集中型クラウドに返すというパターンもあります。
もしくは、中央集中型クラウドにはセントラライズドなデータベースがありますので、そこでチェンジ・データ・キャプチャーのような機能を使って、何か更新があったらリージョンの方に戻すこともできます。
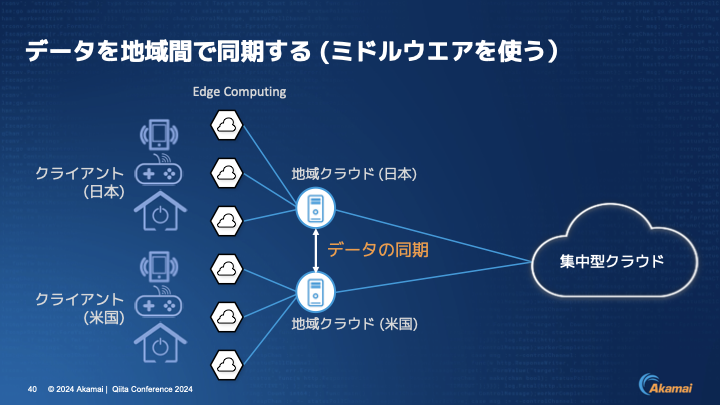
伊東:次に、データを地域間で同期をする部分です。例えば地域クラウドをレプリケーションし、別の地域で動かしたい場合は、先ほどのHarperDBやMacrometaのような機能を使って同期を行います。
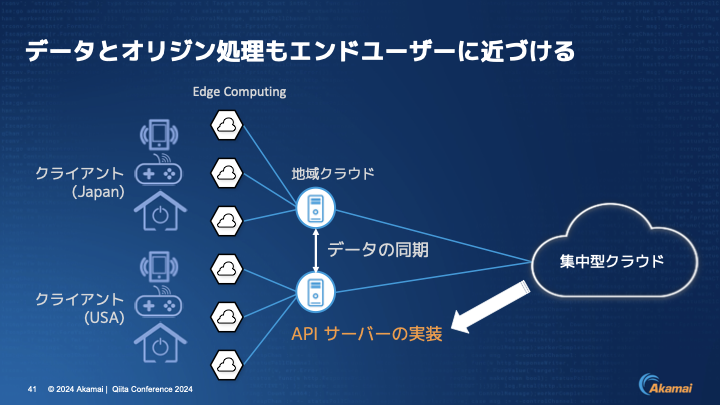
伊東:データが同期できて、そこにあるなら、APIのエンドポイント自身も持ってくることもできます。そうすることで、集中型クラウドの方にデータが行くことはありません。例としては、GraphQLサーバーなどを地域クラウドに持ってきて処理する、というようなアイデアが考えられるでしょう。

伊東:こちらについても具体的なケースをお伝えできればと思います。アメリカのコマースの例ですが、一番上にはオリジンサーバーがあり、特定のAPIの処理が負担になっています。キャッシュ効率が50%のところを90%に向上したい、というのが最初のモチベーションです。
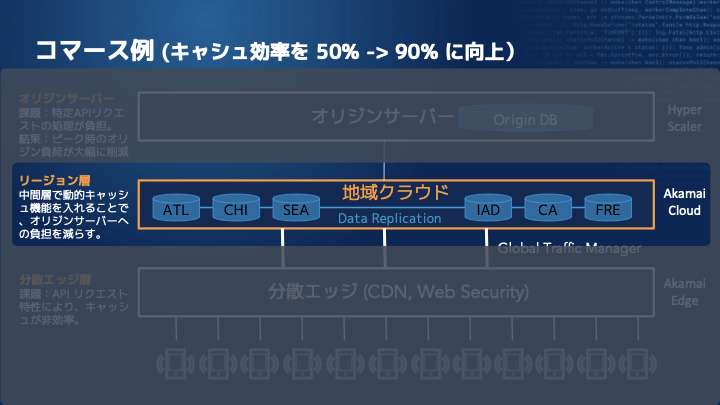
伊東:そこで、地域のクラウドレイヤーを作り、北米で6カ所以上の地域クラウドを展開しています。このようなところでオリジンの負荷を減らすということです。
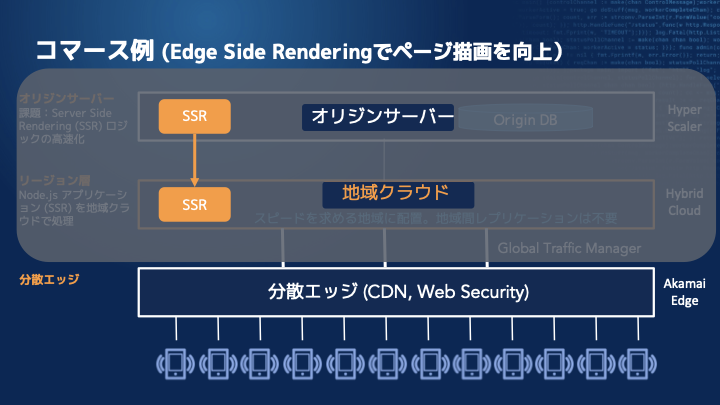
それからもう1つ、サーバーサイドレンダリングの例があります。クライアントの方でクライアントサイドレンダリングをしたものが、段々とサーバーサイドレンダリングになるというような兆候がありました。
伊東:Node.jsが動いているようなアプリケーションがサーバーサイドであった場合に、エッジではなかなかNode.jsが動かないという話になるので、それを地域クラウドの方に持っていき、マルチクラウドで一番適切な場所で該当の処理を動かそうというものになります。
まとめ

伊東:以上、まとめとしてはこちらの通りです。
最後に記載しました通り、地域クラウドのベースというのはシンプルなIaaSです。IaaSを使って、うまい形でアプリケーションを作っていきましょうというところで、実は弊社もIaaSをご提供しています。
デベロッパーフレンドリーかつ手頃な価格でご提供できるということで、非常にご評価いただいていますので、ぜひフリーのアカウントを作成してトライしていただけたらと思います。
伊東:また、弊社もQiitaにページを持っています。ぜひ検索していただき、何かご不明点等ございましたら、気軽にご連絡いただければと思います。ご静聴いただきまして、ありがとうございました!
取材/文:長岡 武司