世界中のダークデータを抽出せよ。日立製作所 × スタンフォード大学の北米戦略について聞いてみた

「データは21世紀における石油」という表現がなされるほど、データドリブンな社会への期待値が高まっている昨今ですが、企業内の情報資産には、まだまだデジタルデータ化がなされていないものが多く存在します。
日々の伝票や請求書類からオペレーションに付随するメモまで、オフィスにはこれまで蓄積されてきた紙に記された膨大な情報が眠っています。創業数年以内のベンチャー企業ならともかく、数十年の歴史を有する企業にとっては、データ化そのものが大きな負担になっていると言えるでしょう。
この状況に対して、株式会社日立製作所が2021年6月に発表したのが「データ抽出ソリューション」です。これは、企業の中で日々収集・蓄積されていくデータのうち、活用されていない、もしくは活用されているが手間がかかって活用効率が悪いデータ、いわゆる「ダークデータ」を抽出し、デジタル資産として有効活用するというもの。
米国スタンフォード大学の企業参画プログラムで開発されたAIを中核としたエンジンを活用し、非定型ドキュメントであっても必要な文字情報等を抽出してデジタルデータ化し、経営戦略に活かすソリューションとなっています。
具体的にどのような技術を用いており、また中長期的にどのような事業構想を描いているのか。今回は、日立製作所・日立アメリカ・日立ヴァンタラの3社にてデータ抽出ソリューションの企画・開発に携わっている3名に、それぞれお話を伺いました。
目次
プロフィール

金融デジタルイノベーション本部 主任技師

Researcher

Manager
日々収集・蓄積されるダークデータをもっと有効活用させる

――今回の「データ抽出ソリューション」はスタンフォード大学の企業参画プログラムから生まれたものということで、まずは取り組みのきっかけや概要を教えてください。
宮田 : 日立では優れた自社技術を活用したDX(デジタルトランスフォーメーション)の推進をミッションとしていまして、その流れの一貫で世界各国の様々な最先端技術をリサーチしています。
スタンフォード大学の企業参画プログラムについても、もともとシリコンバレー発の技術をビジネス化のタネとして使えないものかという模索から始まっていまして、2016年から、工学系研究科が主催するデータサイエンス分野におけるプログラム「Stanford Data Science Initiative」に参画しています。そこで、ダークデータの効率的な活用に向けた研究や、その成果を元にしたオープンソース開発に参画してきました。
――「ダークデータ」という表現を初めて聞いたのですが、これはどういうものなのでしょうか?
宮田 : 企業の中で日々収集・蓄積されていくデータのうち、活用されていない、もしくは活用されているが手間がかかって活用効率が悪いデータのこと指します。
スタンフォード大学との取り組みを3名の教授と進めているのですが、その中の1名と進めているのが、このダークデータに着目したソリューションとなります。
――ダークデータが溜まることの弊害にはどんなものがあるのでしょうか?
宮田 : そもそも、情報をデータ化する大きな目的は「分析」にあります。
しかし、多くの企業では様々なリポジトリに格納されるデータ量が急速に増えてはいるものの、それらがどのような属性をもち、またどこに存在するのか適切なタグ付がなされていないので、そのままでは使えません。
データアナリストやビジネスアナリストはデータの準備に8割方の時間を割いており、実際のインサイト分析には2割ほどしか使えていないという調査結果もあるくらいです。
日立としてもこのような課題を解決すべく、随分と前から構造/非構造データの研究を行っていて、データサイエンティストのトップ人財が集まる「Lumada Data Science Lab.」でも、ダークデータに関する専任の研究開発チームを設置しています。
最終的に目指すところは、「分析して価値へと変えていく」ところ

――今回は3名とも、それぞれ別の企業からご参加されていますが、日々どのようなコミュニケーションをされているのでしょうか?
南 : 研究所と事業部の打ち合わせとして、定期的にオンラインで顔を合わせています。「依頼研(依頼研究)」といって、事業部が研究所に対して研究依頼を出すことがあるのですが、宮田さんとはそのような形でよく話をしています。
お客さまの実際のドキュメントを見ると、往々にして既存のものにさらにプラスした技術要素を加えてソリューション化する必要があるので、より複雑なドキュメントに対応できるようフィードバックを行っていたりします。
また今回のデータ抽出ソリューションは北米市場にも展開していきたく、日立ヴァンタラの山田さんやその上司の方、我々事業部の人間、そして宮田さんをはじめとする研究所メンバーで、どう広げていくかの戦略会議を定期的に行っています。
――日立さんでは、今回のデータ抽出ソリューション以外にも、AI-OCR技術の研究開発を行っていることを取材しました。こちらのチームとは何かやりとりはされているのでしょうか?
参考:研究開発寄りのプロダクト開発は面白い!日立グループを実験場にAI-OCRを活用した「帳票認識サービス」の担当技術者が語るやりがい
南 : 帳票認識サービスのチームとは、週に1回くらいのペースでミーティングしています。帳票認識サービスでは「非構造データ」が未だ適用困難な領域とされていますが、データ抽出ソリューションではこの部分も含めてデジタルデータ化していくことを狙っています。
もちろん、連携を前提に話し合っていますが、具体的な部分はまだこれからというところです。
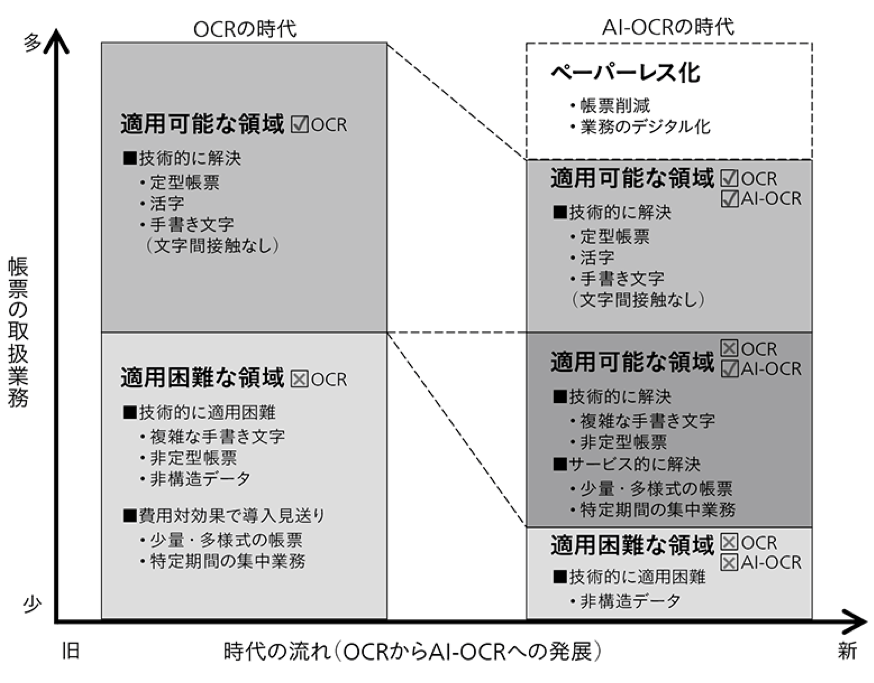
――この図の適用困難な領域部分を全てカバーすることが目的ということですね。
南 : もちろん、カバー率を100%に近づけることは大前提となりますが、お客さまが本来的に求めていることは、先ほど宮田さんからもお話があった「分析」の部分です。データ抽出ソリューションも、最終的に目指すところは「分析して価値へと変えていく」ところでして、帳票認識サービスや分析系AIと組み合わせたトータル分析ソリューションにしていきたいと考えています。
情報表現構造解析技術と弱教師学習技術を駆使したエンジン
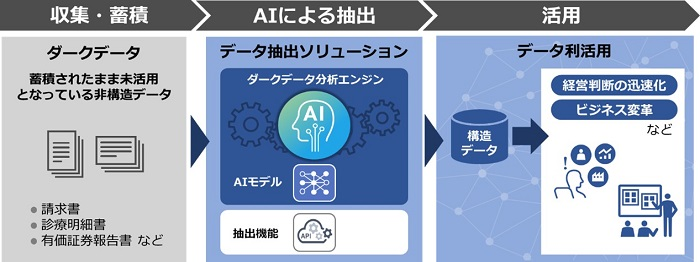
――ここで改めて、ダークデータに対するデータ抽出ソリューションの技術概要を教えてください。
宮田 : 大きくは2つの特徴があります。
まず、従来のAI-OCR技術は帳票上のXY座標についてディープラーニングさせるのが一般的でしたが、これだと絶対的な位置関係についての学習しかなされないので、例えば同じ行に複数の日付があるパターン、ないパターンなどについての相対的な判断が難しい状況でした。
これに対してデータ抽出ソリューションでは、表や図、テキスト間の相対座標といったドキュメント内の様々な特徴から文書の構造全体を解析し、非定型の多種多様なドキュメントのデータ抽出に対応することが1つの特徴です。
具体的には、「情報表現構造解析技術」での解析結果を使ってラベリングファンクションという情報へのタグ付けプログラムを記述し学習させるということをやっていまして、一言でお伝えすると、座標ではなく「ルール自体」を覚えさせるようにしています。
――要するに、人が紙文書を目で見て判断するような流れにしている、ということでしょうか。
宮田 : そうですね。人が何か紙文書を読むときは、テキストはもちろん、全体のレイアウトや単語の出現位置など視覚的な情報から文書を捉えていると思いますが、それと理屈は同じです。
例えば、日付の表記に「発行日」「診察日」「受診日」などの表記ゆれがあったとしても、ルールを理解しているので、文書の構造から同じ意味をさす単語として認識できるようになります。
また、1つの区分に対して複数の項目が紐づく1:Nの関係についても正しく認識するため、複雑な表のデータ抽出にも適しています。もちろん、抽出対象が複数ページにまたがるドキュメントであっても、対象となる項目を正しく抽出することができるようになります。
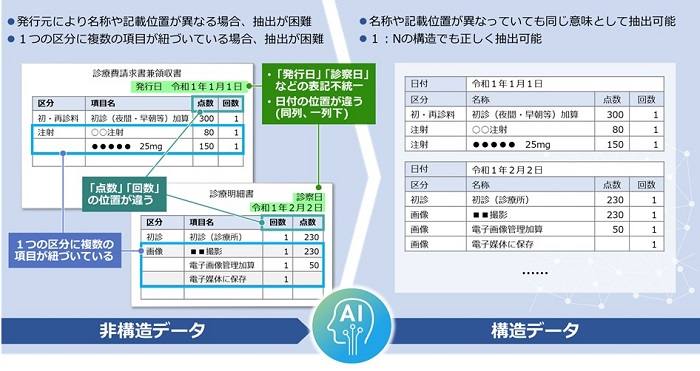
診療明細書を使ったデータ抽出のイメージ
――抽出後のデータ処理時間が大きく削減できそうですね。
宮田 : あともう1つは、少ない教師データからAIモデルを構築できる「弱教師学習技術」を使っていることも大きな特徴です。従来のディープラーニングではモデル構築にあたって沢山の教師データを学習させる必要があったのですが、帳票のような紙文書については、必ずしも大量の教師データが用意できるものばかりとは限りません。
また、教師データの準備では人手でデータラベリングを行うことが必要であるため、モデル構築や精度の維持・運用に多大なコストと時間が必要でした。
弱教師学習技術を使うことで、データラベリングの作業を自動化してモデル構築のコストが削減されますし、追加学習や再学習といったモデルの継続的な改善にも柔軟に対応できるようになります。
――なるほど。データの抽出率としてはいかがでしょうか?
南 : ここについては、お客さまデータの非構造具合を見てみないと分からないのが、正直なところです。
データを拝見して100%を目指したいところですが、AIの世界ではまだまだ100%というのは難しいものです。
データ抽出ソリューションでは、認識結果の「確からしさ」を示す「確信度」というものを活用しており、業務内容によってOK/NGを設計できるようにしています。ここは、帳票認識サービスと同様です。
北米含め、ダークデータ活用は世界共通の悩み

――いわゆるAI-OCRは様々な企業が提供していると思いますが、その中でこのデータ抽出ソリューションの強みは何になるのでしょうか?
山田 : 今宮田さんからお話があった通り、相対的な構造情報を使いながら表現できるのが1つの強みだと思います。従来のAI-OCR抽出だと座標情報を覚えさせるのが肝になるのですが、非構造データはそもそものバリエーションが多岐にわたることになるので、実業務への適用や運用を考えると現実的ではありませんでした。座標情報からルールへ、というのがブレイクスルーだと思います。
宮田 : ルールと一言で言っても、それをしっかりとロジックに落とし込むには、業務そのものをよく分かっていないといけません。だからこそ、あらゆる産業の業務知識が豊富な日立の強みが発揮しやすいと感じています。
もちろん、業務知識をロジック化してプログラムへと落とし込む部分が最も難しいので、そこができるのも大きな強みでしょう。
――ルールについては、毎回構築されていくのでしょうか?
山田 : ルールには、汎用的に使えるものと業務ロジックがガッツリと入ったものの2パターンがありまして、前者は一度作れば汎用的に使えますが、後者についてはお客さまにヒアリングしながら毎回作っていくことになりますね。
――なるほど。山田さんは北米市場の展開の窓口だと思うのですが、日本と北米とで、導入の難易度など違いは何かあるのでしょうか?
山田 : お客さまが困っている箇所や難易度に大きな違いはないと感じます。北米や欧州でも、手作業で帳票からのデータ化作業は多くの企業で残っていまして、そこは日本と変わりません。世界共通の悩みだと言えます。
南 : 一方で個人的に感じることは、お客さまのデリバリーに対するスピード感ですね。2ヶ月くらいですぐ完成させてよ、という話をよく聞きます。日本ではスピード以上に信頼性を重視されることもよくあるので、ここのスピード感はかなり違うのかなと思います。
山田 : 確かに、そこは日本と北米の文化で大きく異なる点かなと感じますね。
――そのような中で、日立はスタンフォード大学のような教育機関との協創を通じて、海外市場でどのように事業展開されていく予定なのでしょうか?
山田 : 北米のお客さまの課題を解決できるよう、現地にブランチをもつ日本の金融機関や保険会社、そして北米現地のローカル企業のお客さまに対してもソリューションをご提供していきます。
南 : 日立は日本でこそある程度の知名度がありますが、海外に出たらまだまだ無名の企業です。さらにはGAFAの主戦場の1つで戦わねばならないので、自分たちの尖っているところを磨き上げることはもちろん、他企業とのパートナリングをしっかり使っていくことも大事だと捉えています。
今年7月には、米グローバルロジック社(GlobalLogic)の買収が完了し、今後は彼らの持つチャネルを十分に活かしていきたいと考えています。
常日頃から「考えるマインド」をもっていないと厳しい環境
――少し皆さまのことについても伺いたいのですが、日立で働くことの楽しさや魅力を教えてください。
山田 : 私は基本的には企画の仕事をしているのですが、日立では毎回全然違うプロジェクトに立ち会えるのが楽しいです。
今回の北米での取り組みは、それこそスタンフォード大学の最新研究にも触れられるので、お客さまの旬なペインポイントに寄り添いながら、最新技術をどうやったら課題解決に活かせるのかを考えていきます。個人的にはここが一番面白いですね。
宮田 : 研究者としては、最先端のところで戦わせてくれるのが非常にありがたいです。私自身、もともとはダークデータとは違うことをやっていたわけですが、異なる分野であっても、最先端の環境で研究をさせてもらっています。
これができるのも、優秀な前任者の研究や事業部のバックアップがあるからでして、自分ひとりの力では到底出来ないところにチャレンジできる。それが、面白いところかなと思います。
南 : 完全に個人的な話なのですが、2009年に取引所を担当していた頃に、携わっていた売買システムが本番稼働を迎えて午前9:00にオープンしました。
そのときに、当時のクライアントのCIOなどがトレーディングフロアに出てきて拍手したりして、その感動が自分の中では良い成功体験になっています。
やはり、携わったものが日の目を見る瞬間はとても良い時間ですね。
――働きやすさの観点ではいかがでしょう?
宮田 : 研究では様々なリソースを使うことになり、以前はそれらの申請が大変でハードルが高かったのですが、今はより気軽にできるようになったのでずいぶんと楽になりました。ちょっと試したいことが、ハードル低くできるようになったと思います。
山田 : 制度面では、人事が様々な施策を進めて、会社を変えていこうとしてるんだなということを感じています。
あとは、ボトムアップで提案できるのも魅力だと思います。私がもともとやっていた音声認識や今回のダークデータのソリューションは、フロント部隊で知見がある人がほとんどいない領域だったからこそ、手を挙げることで積極的に牽引する立場になることができました。
新人であっても、ロジックがしっかりと通っていれば採用されるのは、とてもいい文化だなと思います。
南 : 皆さんがおっしゃる通り、働きやすくなったのは間違いないのかなと思います。一方で私のように管理職にいると、メンバーのベクトルの合わせ方が難しいのも確かです。
以前は上司が答えを知っていてみんなに伝えれば良かったのですが、今は管理職も手探りでマーケットを探している状況なので、山田さんが言ったようにボトムアップが求められています。働き方が自由になってきた分、責任も強くなっているからこそ、常日頃から「考えるマインド」をもっていないと厳しい環境でもあるなと感じます。
求む、グローバルで挑戦できる人

――どういう人が日立の研究者に向いているのでしょうか?
宮田 : 個人的には「バランスが取れる人」でしょうか。もちろん研究者なので「こだわり」は当然必要なのですが、こだわりすぎると次のステージに行けないこともあるので、広い視野をもって目移りしながら、期間を決めてしっかりとこだわってやってみるというバランスが大事だと思います。
南 : 日立が対峙するお客さまの課題は、当然ですが1人では解決できません。日立グループ内外の様々なメンバーとシームレスに連携して価値を届けることが必要になります。そうやって進めれたときに、私の場合は、先ほどの2009年の嬉しかった記憶が蘇ります。
宮田さんがおっしゃっていたバランスもそうですし、メンバーを巻き込んで何回もチャレンジして試行錯誤する姿勢が、特に求められると思います。
――ありがとうございます。それでは最後に、読者の皆さまに向けて一言ずつメッセージをお願いします!
南 : ドメインエキスパートがデジタル技術を駆使し、お客さまの要望にすぐに答えるという時代が、もうすぐそこまできていると感じます。その中で、今の研究とは違うことが往々にして出てくることがあるので、これから入社する人とはオープンマインドで一緒にトライでできたらいいなと思います。
宮田 : とにかく、新しい技術に興味ある人と一緒に仕事をしたいなと。インプットをするからこそアウトプットがあるわけなので、何事にも興味をもって、新しい技術をしっかりと習得していく意欲のある人と仕事したいと思います。
山田 : 私からは企画者目線のメッセージを。何か専門性をもつのも大事ですが、同時に新しいことにチャレンジし、研究者に食らいついて技術を獲得するなど、好奇心をもって様々な分野に手を広げるのが、企画者としては重要なポイントだと思います。
あと、これからはますます、グローバルで挑戦できる人も重要になってくるので、そんな志向がある方はぜひ一緒に働きましょう!
編集後記
米調査会社のIDC社が2019年6月に発表した調査レポートによると、世界のあらゆるデータのうち、分析されてしっかりと有効活用できているのはわずか2.5%だと言います。つまり、残りの97.5%のデータの価値は、少なくともデータ分析のテーブルには乗っていないことになります。
今回お話を伺ったデータ抽出ソリューションは、ここにメスを入れるものとして非常に期待値が高いと感じます。海外の最先端技術を取り入れた研究開発に興味のある方にとっては、最高の職場環境だと言えるでしょう。
取材/文:長岡武司
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所経験者採用実施中!
様々な文書からのナレッジ抽出、ナレッジの機械学習での活用に関する研究開発
募集職種詳細はこちら
日立製作所の人とキャリアに関するコンテンツを発信中!
デジタルで社会の課題を解決する日立製作所の人とキャリアを知ることができます
Hitachi’s Digital Careersはこちら