※お役に立てたらストック、いいねをよろしくお願いします!!
<📝本記事のターゲット層>
- AIサービスの裏側にある技術要素を理解したい人
- エージェント開発やAIアプリ開発を検討する開発者
- 技術選定や標準化動向を追いたい人
🔷生成AIの技術比較:MCP、A2A、Tool Calling、RAG、Computer Useを役割別に整理
生成AIサービスを比較していると、MCP、A2A、Tool Calling、Function Calling、RAG、Computer Useのような技術用語が出てきます。
どれもAIエージェントやAIアプリ開発で重要ですが、名前だけを追うと混乱しやすいです。
大切なのは、「その技術が何を解決するのか」で見ることです。
たとえば、MCPはAIアプリと外部ツール・データソースをつなぐための標準として説明されています。A2Aは、異なるAIエージェント同士が安全にやり取りし、タスクを委譲するためのプロトコルです。Tool CallingやFunction Callingは、モデルが外部処理の必要性を判断し、アプリケーション側が実行するための仕組みです。
この記事では、生成AIを支える技術要素をサービス名ではなく役割別に整理します。
🔹1. AI技術はサービス名ではなく役割で見る
生成AIの技術比較では、製品名から一段下げて「何を解決する技術か」を見ると理解しやすくなります。
この記事で扱う主な技術要素は次の通りです。
| 技術要素 | 主な役割 |
|---|---|
| MCP | AIアプリと外部ツール・データソースを接続する |
| A2A | エージェント同士が通信し、タスクを委譲する |
| Tool Calling | モデルが必要なツール呼び出しを判断し、アプリ側が実行する |
| Function Calling | 関数名と引数を構造化して返し、外部処理につなげる |
| RAG | 外部データを検索し、回答生成に使う |
| Memory | ユーザーや業務の文脈を継続的に活用する |
| Long Context | 長い文書や大量の会話履歴をまとめて扱う |
| Computer Use | AIが画面を見て、UI操作を支援する |
| Deep Research | 検索、調査、推論、引用付きレポート作成を行う |
| Voice / Vision | 音声や画像を入力・出力として扱う |
| Apps / Connectors | ChatGPTなどのアプリから外部サービスへ接続する |
これらは単独で使われることもありますが、実際のAIエージェントや企業向けAIアプリでは組み合わせて使われます。
以下の図は、AIモデルを中心に、外部ツール、データソース、エージェント、ユーザー確認、企業管理がどうつながるかを整理したものです。
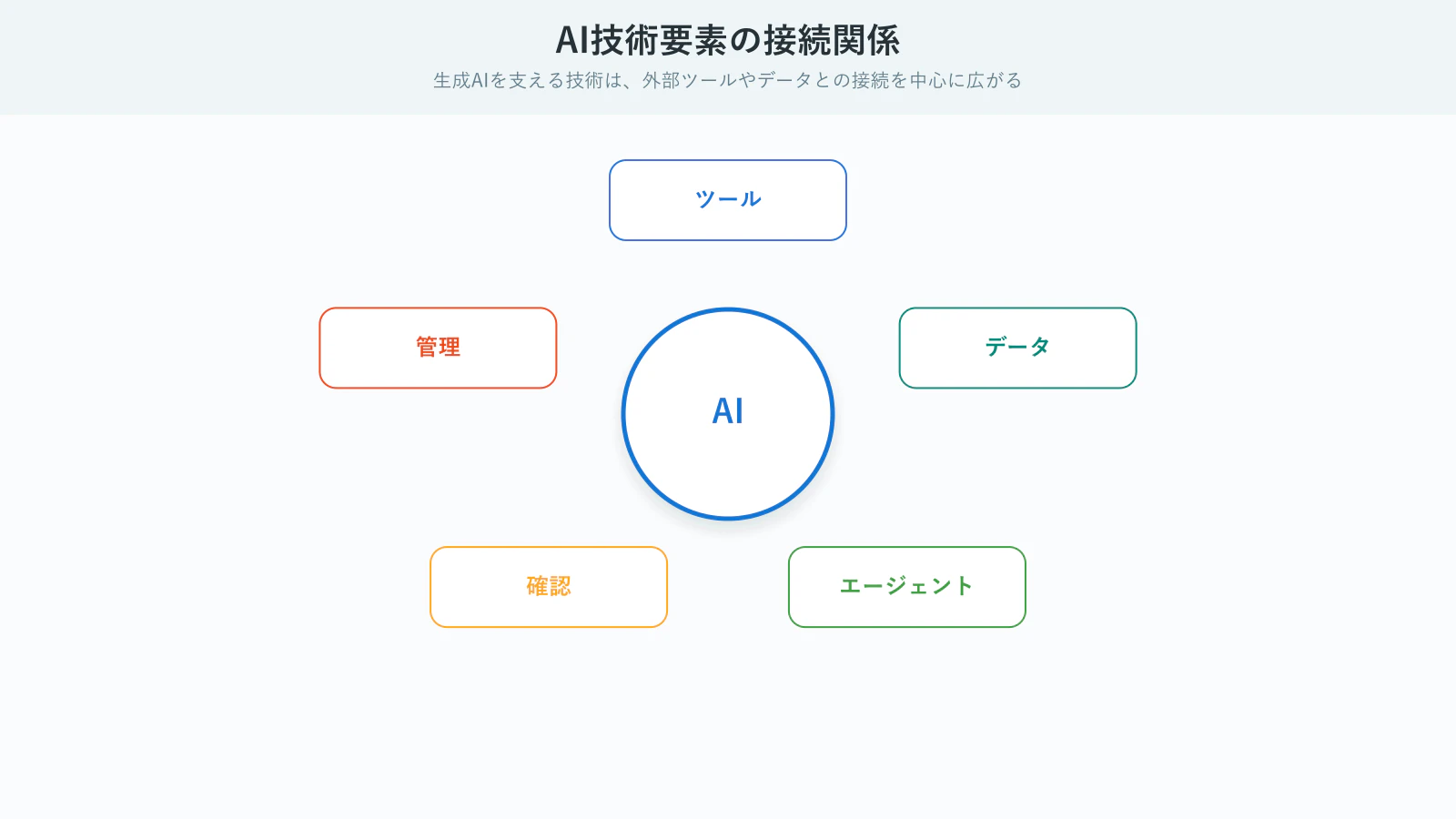
生成AIを支える技術は、外部ツールやデータとの接続を中心に広がる
図の通り、AIモデルだけでは実務の作業は完結しません。
外部ツールを呼ぶ、社内データを検索する、複数エージェントで役割分担する、ユーザー確認を挟む、企業管理で権限や監査を扱う。この周辺技術があることで、AIは単なるチャットから業務や開発に使える仕組みに近づきます。
🔹2. AIと外部ツールをつなぐ技術
まずは、AIと外部ツールをつなぐ技術です。
ここでは、MCP、Tool Calling、Function Calling、Apps / Connectorsを整理します。
▸MCPとは:AIアプリと外部システムをつなぐ標準
MCPとは、Model Context Protocolの略です。
Anthropicの公式ドキュメントでは、MCPはAIアプリケーションを外部システムに接続するためのオープン標準として説明されています。接続先には、ローカルファイル、データベース、検索エンジン、計算ツール、業務ワークフローなどが含まれます。
MCPを使うと、AIアプリは毎回ユーザーが情報を貼り付けなくても、許可されたツールやデータソースから必要な情報を取得し、作業に使えるようになります。
たとえば、Claude CodeはMCPを通じて、issue tracker、監視ダッシュボード、データベース、APIなどへ接続できます。OpenAIやGitHubなどでも、remote MCP serversやMCP連携が文脈として出てきます。
MCPを見るときのポイントは次の通りです。
- どのMCPサーバーに接続できるか
- 認証情報や権限をどう扱うか
- 読み取りだけか、書き込みや実行もできるか
- 操作ログや監査を残せるか
- 企業のネットワークやデータ境界に合うか
💡Tips:MCPは「万能コネクタ」ではなく「接続の作法」として見る
MCPとは何かを理解するときは、「AIと外部システムをつなぐための共通的な作法」と考えると分かりやすいです。
実際に使うときは、MCPサーバーの信頼性、認証、権限、ログ、データの扱いまで確認しましょう。
▸Tool Callingとは:モデルがツール利用を判断する仕組み
Tool Callingとは、モデルが「この処理には外部ツールが必要」と判断し、どのツールをどんな引数で呼ぶべきかを返す仕組みです。
OpenAIの公式ドキュメントでは、Tool Callingはモデルとアプリケーションの間で行われる多段の会話として説明されています。大まかな流れは次の通りです。
- アプリケーションが、利用可能なツール一覧とともにモデルへリクエストする
- モデルが、呼び出すべきツールと引数を返す
- アプリケーション側が実際のコードやAPIを実行する
- 実行結果をモデルへ返す
- モデルが最終回答、または追加のツール呼び出しを返す
重要なのは、モデルが直接すべてを実行するのではなく、アプリケーション側が実行と安全管理を担う点です。
Function Callingは、Tool Callingの中でも、関数名と引数を構造化して返す考え方として理解すると分かりやすいです。現在は各社APIで「tool use」「function calling」「tools」など名称が異なるため、実装時には公式ドキュメントの用語を確認してください。
▸Apps / Connectorsとは:利用者向けAIアプリから外部サービスへつなぐ仕組み
Apps / Connectorsは、ChatGPTなどの利用者向けAIアプリから、外部サービスや社内情報へ接続するための仕組みです。
開発者がAPIでツール呼び出しを実装するのではなく、ユーザーや管理者がアプリ上で連携を設定して使うイメージです。
たとえば、Deep ResearchでGoogle Drive、SharePoint、GitHub、Linear、Teamsなどのコネクタを使う文脈があります。Businessプランでは、GitHub Enterprise、Snowflake、Databricks向けのapp templatesが案内されています。
Apps / Connectorsを見るときは、次の点を確認しましょう。
- どのプランで使えるか
- どの地域で提供されているか
- 管理者設定が必要か
- 読み取り専用か、書き込みや実行も含むか
- 接続先データがモデル学習やログにどう扱われるか
🔹3. エージェント同士・業務システムをつなぐ技術
次に、エージェント同士や業務システムをつなぐ技術です。
ここでは、A2A、マルチエージェント、承認フロー、企業管理を整理します。
▸A2Aとは:エージェント同士の相互運用プロトコル
A2Aとは、Agent2Agentの略です。
GoogleはA2Aを、AIエージェント同士が通信し、情報を安全に交換し、企業アプリケーション上でアクションを調整するためのプロトコルとして発表しました。その後、Linux FoundationのAgent2Agentプロジェクトとして、AWS、Cisco、Google、Microsoft、Salesforce、SAP、ServiceNowなどが参加する形で進められています。
Gemini Enterprise Agent Platformのドキュメントでは、A2A agentをAgent Runtime上で動かし、SDKやHTTPでメッセージ送信、タスク管理、機能参照を行う説明があります。また、Gemini Enterpriseでは、異なるビルダーやプラットフォームで作られたA2A agentを登録し、利用者がGemini Enterprise web appから使えるようにする文脈もあります。
A2Aを見るときのポイントは次の通りです。
- エージェント同士が互いを発見できるか
- タスクの依頼、進捗確認、キャンセルができるか
- 認証済みのagent cardや能力情報を扱えるか
- 企業のID、権限、監査と接続できるか
- どのプラットフォームで実装・運用できるか
▸マルチエージェントは役割分担と管理がセット
マルチエージェントとは、複数のエージェントが役割分担して作業する仕組みです。
たとえば、次のような分担が考えられます。
- 調査エージェント:情報収集と要約を担当する
- 実装エージェント:コード変更を担当する
- レビューエージェント:品質確認やリスク指摘を担当する
- 業務エージェント:社内システムへの申請や更新を担当する
- 管理エージェント:承認、ログ、状態管理を担当する
マルチエージェントでは、ただ複数のAIを動かすだけでは不十分です。
どのエージェントが何を担当するのか、どのデータにアクセスできるのか、どこで人間の承認を挟むのか、失敗時にどう停止・再実行するのかを設計する必要があります。
▸承認フローと企業管理は実務導入の必須要素
AIエージェントが外部ツールを使うほど、承認フローと企業管理が重要になります。
特に注意したいのは、次のような操作です。
- ファイルを書き換える
- コードを変更する
- データベースを更新する
- 顧客情報や社内情報を参照する
- 外部APIを実行する
- メールやチャットを送信する
- 料金が発生する処理を実行する
このような操作では、AIが自律的に進める範囲と、人間の確認を必須にする範囲を分ける必要があります。
企業導入では、ID管理、権限、監査ログ、データ保持、ネットワーク境界、管理者設定まで含めて確認しましょう。
🔹4. AIの入力・記憶・調査能力を広げる技術
ここからは、AIの入力、記憶、調査能力を広げる技術を整理します。
RAG、Memory、Long Context、Computer Use、Deep Research、Voice、Visionは、どれもAIの使い道を広げます。ただし、解決する課題はそれぞれ違います。
| 技術 | 解決する課題 | 代表的な使い方 |
|---|---|---|
| RAG | 外部データを検索して回答に使う | 社内文書検索、FAQ、ナレッジ検索 |
| Memory | 継続的な文脈を覚える | ユーザー設定、好み、過去の作業履歴 |
| Long Context | 長い入力を一度に扱う | 長文PDF、仕様書、議事録、コードベースの一部 |
| Computer Use | 画面を見てUI操作する | ブラウザ操作、業務画面操作、テスト補助 |
| Deep Research | 調査、検索、推論、引用付きレポート作成 | 市場調査、技術調査、競合調査 |
| Voice | 音声入力・音声出力を扱う | 会話型AI、音声アシスタント、議事録 |
| Vision | 画像や画面を理解する | 画像分析、スクリーンショット理解、UI確認 |
以下の図は、生成AI技術を解決する課題ごとに分類したものです。

生成AI技術は解決する課題ごとに分類できる
図の通り、技術名だけを覚えるよりも、「接続」「検索」「記憶」「長文」「操作」「音声」「画像」「調査」のどれを解決するのかで整理すると分かりやすくなります。
▸RAGとLong Contextは似ているが役割が違う
RAGとLong Contextは、どちらも外部情報や長い情報をAIに扱わせる技術として語られますが、役割は違います。
RAGは、必要な情報を検索して取り出し、その情報を回答生成に使う考え方です。社内文書、FAQ、仕様書、チケット、議事録などから関連情報を探す用途に向いています。
Long Contextは、長い入力をモデルにそのまま渡して処理する能力です。長文PDF、長い会話履歴、大きめのコード断片などをまとめて扱う場合に役立ちます。
どちらが良いかは用途次第です。
大量の文書全体から必要な情報を探すならRAGが向いています。限られた長文をまとめて読みたいならLong Contextが向いています。実務では、RAGで候補を絞り、Long Contextで周辺文脈まで読ませるように組み合わせることもあります。
▸Memoryは便利だが、企業利用では境界設計が必要
Memoryは、ユーザーの好み、過去の会話、作業の文脈などを継続的に活用するための技術です。
個人利用では、毎回同じ前提を説明しなくてよくなるため便利です。
ただし企業利用では、何を記憶するのか、誰が見られるのか、削除できるのか、社内データや個人情報が混ざらないかを設計する必要があります。
Memoryを導入する場合は、便利さだけでなく、データ保持、アクセス制御、監査、削除手段を確認しましょう。
▸Computer Useは強力だが安全対策が重要
Computer Useは、AIが画面を見て、マウスやキーボードのようなUI操作を支援する技術です。
OpenAIのComputer Useでは、モデルがスクリーンショットを確認し、UI操作を返す、またはカスタムハーネスを通じて視覚的・プログラム的な操作を組み合わせる説明があります。
AnthropicのComputer Useも、デスクトップ環境を操作するbeta機能として案内されています。また、スクリーンショットに含まれるプロンプトインジェクションを検出した場合、ユーザー確認を促す防御レイヤーについても説明されています。
Computer Useは、従来APIがない画面操作にも使える可能性があります。
一方で、誤クリック、意図しない送信、機密情報の読み取り、外部サイトからの指示混入などのリスクがあります。使う場合は、サンドボックス、権限制限、実行前確認、操作ログ、機密情報のマスキングを検討しましょう。
▸Voice / Vision / Deep Researchは入力と調査の幅を広げる
Voice、Vision、Deep Researchは、AIの入力と調査の幅を広げる技術です。
Voiceは、音声入力や音声出力を扱います。会議、通話、音声アシスタント、ハンズフリー操作などで重要です。
Visionは、画像やスクリーンショットを理解します。UI確認、図表読み取り、画像分析、帳票確認などで役立ちます。
Deep Researchは、検索、推論、情報整理、引用付きレポート作成を組み合わせた調査向けの技術です。OpenAIのDeep Research APIでは、Web検索、code interpreter、remote MCP callsなどの出力項目が含まれる場合があると説明されています。
これらの技術は便利ですが、情報源の信頼性、引用、著作権、個人情報、社内情報の扱いに注意が必要です。
✅5. まとめ:技術比較では「何を解決するか」を先に見る
生成AIの技術比較では、流行語として名前を覚えるよりも、何を解決する技術なのかを先に見ることが大切です。
この記事では、主な技術を次のように整理しました。
- MCP:AIアプリと外部ツール・データソースをつなぐ
- A2A:エージェント同士が通信し、タスクを委譲する
- Tool Calling / Function Calling:モデルが外部処理の必要性を判断し、アプリ側が実行する
- RAG:外部データを検索して回答に使う
- Memory:継続的な文脈を活用する
- Long Context:長い入力をまとめて扱う
- Computer Use:画面を見てUI操作を支援する
- Deep Research:検索、調査、推論、引用付きレポート作成を行う
- Voice / Vision:音声や画像を入力・出力として扱う
- Apps / Connectors:利用者向けAIアプリから外部サービスへつなぐ
技術選定では、次の問いを確認しましょう。
- AIに何をさせたいのか
- 外部ツールや社内データに接続する必要があるか
- 複数エージェントで分担する必要があるか
- 人間の承認をどこで挟むか
- ログ、監査、権限、データ保持をどう扱うか
- その機能はGAか、Previewか、betaか
AIエコシステムの比較では、モデル性能だけでなく、これらの技術要素をどう組み合わせているかが重要になります。
まずは「接続」「検索」「記憶」「長文」「操作」「音声」「画像」「調査」のどれを解決したいのかを決め、そのうえで必要な技術とサービスを選びましょう。
🔹参考URL
本記事では、2026年6月22日時点で確認できる公式情報を参考にしています。各サービスの名称、料金、提供状況、プレビュー表記は変わる可能性があるため、導入前には最新の公式ページを確認してください。
- What is the Model Context Protocol
- MCP connector - Claude API Docs
- Connect Claude Code to tools via MCP
- Google Cloud donates A2A to Linux Foundation
- Announcing the Agent2Agent Protocol
- Use an Agent2Agent agent
- Register and manage A2A agents
- Function calling - OpenAI API
- Using tools - OpenAI API
- Computer use - OpenAI API
- Computer use tool - Claude API Docs
- Deep research - OpenAI API
- Gemini Enterprise Agent Platform overview
- Agent Runtime
- Agents overview - Gemini Enterprise Agent Platform
※お役に立てたらストック、いいねをよろしくお願いします!!