AWS re:Invent 2016にて、Amazon Athenaという、S3にストアされたデータに対してSQLを投げられるサービスが発表されました。
AWS Blogを読む限り、色々とGoogle BigQueryに似ています。
すでにUS East (Northern Virginia), US West (Oregon)リージョンで利用可能となっています。
BigQueryとの比較
ブログやFAQから得られる情報によれば、AthenaのSpecは、BigQueryと比較して以下のようになっています。
| Athena | BigQuery | |
|---|---|---|
| クエリエンジン | Presto | Dremel |
| ストレージ | S3 | Colossus |
| SQL | ANSI SQL(バージョンは?) | SQL2011(Standard SQLの場合) |
| UDF | × | Javascript, SQL |
| JDBC | ○ | × |
| Web UI | ○ | ○ |
Web UIはこんな感じです
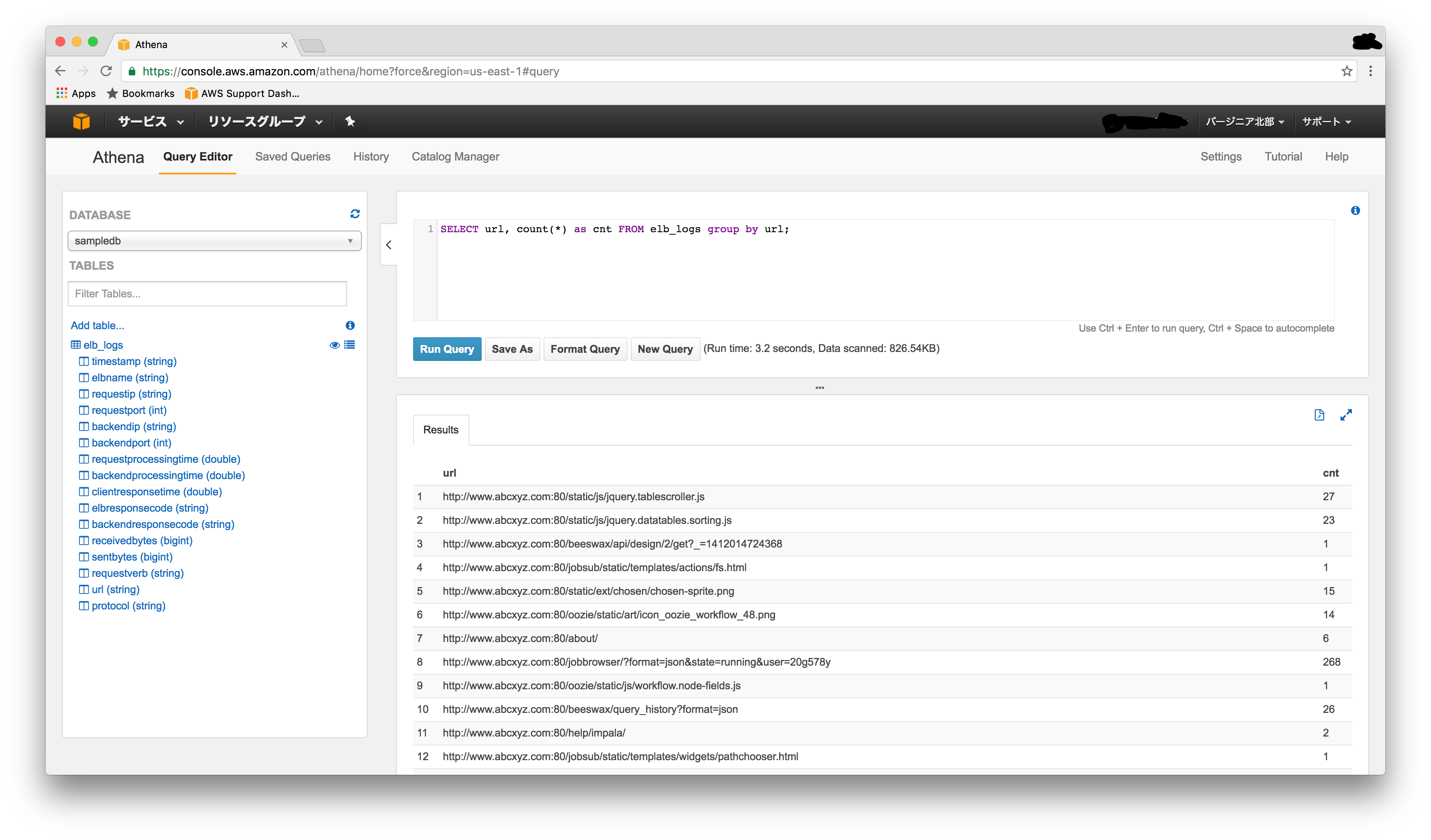
サンプルとしてelb_logsというテーブルが初めから入っています。
料金
Athenaではクエリに対してのみ課金が行われるようです。(とはいえ、ストレージがS3なのでその分のコストは別途かかります)
$5 per TB of data scanned.
とのことで、料金体系もBigQueryと同様です。
ただし、Athenaでは、SELECTする列を絞ってスキャン容量を削減するためには、自前で列指向フォーマットでS3に置いておく必要があるようです。
今の所、BigQueryのBilling Tier的なものは見当たらず、純粋にスキャンした容量によって料金が決まるようです。
感想
- JDBCに対応しているのは嬉しい
- 大きなデータセットで試してみたい
- BigQuery並みの超性能が出るならかなり期待できそうな気がします