はじめに
ことの発端は競馬AIの製作のためにスクレイピングを学ぼうとしていて、その学習課題を探していました。
どうせならばデータ取得→前処理→学習→推論の一連の流れができるものがいいと思い
我が推しメン大場花菜のツイート内容からいいねの数を推定する
を学習課題とすることにしました。
今回は簡素な流れでまずは動き始めることを目的にしており、精度云々は今後詰めていこうと思います。
※間違い等ありましたらご指摘ください
データ収集
データの収集はTwitter APIを使用します。
登録方法は↓の記事を参考にしました。
TwitterAPI登録を記入時間30分で超簡単にパスする裏技(日本語訳付き)
まぁまぁ理由とか考えて書くのめんどくさいので覚悟してください。
僕はここで一日潰れました。(日本語が不自由なもので…)
登録が終わったらTweetが取得できるので取得プログラムを書いていきます。
通常Twitter APIは200件までしかTweetを取得できないようで、これも以下の記事を参考に「@hana_obaのツイートを全件取得する」が実現できるコードを書いていきます。なお、ほとんどが参考記事のプログラムの丸コピとなるので自身で書いた部分だけをここでは載せておきます。
TwitterAPI でツイートを大量に取得。サーバー側エラーも考慮(pythonで)
# ユーザーを指定して取得 (screen_name)
getter = TweetsGetter.byUser('hana_oba')
df = pd.DataFrame(columns = ['week_day','have_photo','have_video','tweet_time','text_len','favorite_count','retweet_count'])
cnt = 0
for tweet in getter.collect(total = 10000):
cnt += 1
week_day = tweet['created_at'].split()[0]
tweet_time = tweet['created_at'].split()[3][:2]
# Eoncodeしたい列をリストで指定。もちろん複数指定可能。
list_cols = ['week_day']
# OneHotEncodeしたい列を指定。Nullや不明の場合の補完方法も指定。
ce_ohe = ce.OneHotEncoder(cols=list_cols,handle_unknown='impute')
photo = 0
video = 0
if 'media' in tweet['entities']:
if 'photo' in tweet['entities']['media'][0]['expanded_url']:
photo = 1
else:
video = 1
df = df.append(pd.Series([week_day, photo, video, int(tweet_time), len(tweet['text']),tweet['favorite_count'],tweet['retweet_count']], index=df.columns),ignore_index=True)
df_session_ce_onehot = ce_ohe.fit_transform(df)
df_session_ce_onehot.to_csv('oba_hana_data.csv',index=False)
特に工夫したことはありませんが、Twitter APIの仕様を理解しないとデータをうまく扱うことは難しいのでググったり試行錯誤でほしいデータを取得していきましょう。
今回のデータセットは
- 曜日
- 画像の有無
- 動画の有無
- ツイート時間
- ツイートの文字数
だけとします。
曜日はone-hot Encodingを用いて七曜ごとに分けています。
これだけの情報だけで今回は学習をしていきます。
前処理、学習
ここまでは自身のPC上でプログラムを動かしていましたが大したことはしないとはいえ今後の展開を踏まえマシンスペックが足りていないのでここからはGoogleColaboratory上で実施していきます。
まずは先ほどのプログラムで出力したデータを読込します。
import pandas as pd
datapath = '/content/drive/My Drive/data_science/'
df = pd.read_csv(datapath + 'oba_hana_data.csv')
データの総数は
df.shape
2992件でした。
(2992, 13)
全体の7割と学習データとし、残り3割を検証データとしようと思います。
データは時系列順に並んでおり単純に前から7割、とするとその時のフォロワー数などの条件が異なるのでランダムに7割を取得したいです。
ややアナログ要素を含んでますが今回は全体の約7割である2400件を学習データとし、残りを検証データとします。
df_train = df.sample(n=2400)
df_test = df.drop(df_train.index)
x_train = df_train.iloc[:,:11]
t_train = df_train['favorite_count']
x_test = df_test.iloc[:,:11]
t_test = df_test['favorite_count']
一度このデータでランダムフォレストで学習してみます。
# モデルの宣言
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=2000, max_depth=10,
min_samples_leaf=4, max_features=0.2, random_state=0)
# モデルの学習
model.fit(x_train, t_train)
スコアを見てみます
# モデルの検証
print(model.score(x_train, t_train))
print(model.score(x_test, t_test))
0.5032870524389081
0.3102920436689621
スコアは何を表しているかというと、今回は回帰問題なので決定係数です。
0から1の値を取り1に近づけば近づくほど精度が高い、ということになります。
今回のスコアを見るとまぁ精度はよくないですよね。
では、精度を上げるべく前処理を実施していきましょう。
まずはそれぞれのパラメータの寄与度をみてみようと思います。
# 特徴量の寄与度が高い順に変数格納
feat_names = x_train.columns.values
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10, 10))
plt.title('Feature importances')
plt.barh(range(len(indices)), importances[indices])
plt.yticks(range(len(indices)), feat_names[indices], rotation='horizontal')
plt.show();
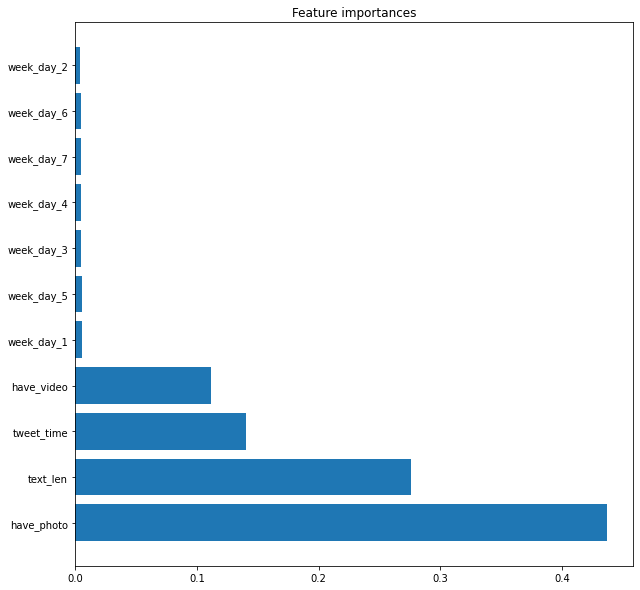
寄与度とは推定をするのに何を重要視しているか、と思っていただければと思います。
一番寄与度が高いのはhave_photo、つまり写真の有無が大きいようですね。
動画がそこまで重要でないように見えるのですが動画は全体の3%と数も多くないのでしょうがないでしょう。
曜日はほぼ関係がないようですね。これはデータから削除しても構わないでしょう。
また、外れ値についても見ていきます。
# グラフで可視化
plt.figure(figsize=(8, 6))
plt.scatter(range(x_train.shape[0]), np.sort(t_train.values))
plt.xlabel('index', fontsize=12)
plt.ylabel('y', fontsize=12)
plt.show()
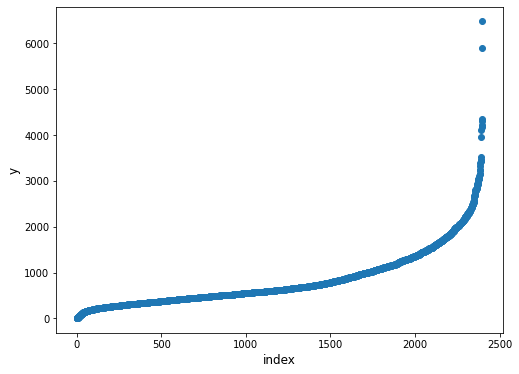
学習データのうち、明らかに外れてる値があるのがわかるかと思います。これらに引きずられて学習してしまうかもしれないのでこういったデータは外していきます。
# 解説順とは逆だがこの順番でやらないと外れ値除去された状態でsplitできない
# 外れ値除去
df_train = df_train[df_train['favorite_count'] < 4500]
df_train.shape
# 曜日を削除
x_train = df_train.iloc[:,7:11]
t_train = df_train['favorite_count']
x_test = df_test.iloc[:,7:11]
t_test = df_test['favorite_count']
これでもう一度学習をしてスコアを見てみましょう。
# モデルの検証
print(model.score(x_train, t_train))
print(model.score(x_test, t_test))
0.5175871090277164
0.34112337762190204
先ほどよりはよくなりましたね。
最後に実際のいいねの数と推定したいいねの数の分布をヒストグラムで見てみます。
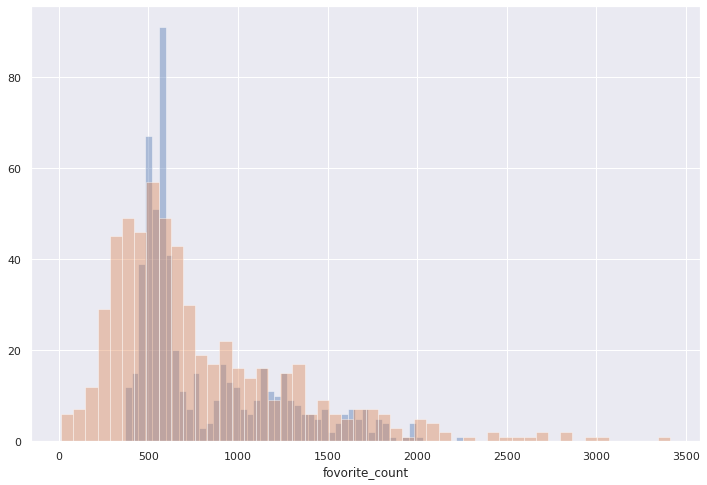
青が推定、オレンジが実際のいいね数になります。
ズレは確かに存在しますが、大きく外してはなさそう、それぞれを見てないから何とも言えないけど。
精度の向上はまた、次にでも。
参考
- Twitter APIの登録方法について
TwitterAPI登録を記入時間30分で超簡単にパスする裏技(日本語訳付き)
- Twitter APIを用いたデータ取得