アドベントカレンダー21日目です
昨日は@marusannの映画.comから人気映画をスクレイピングでした✨
背景
Pythonで高速化したい!と思って調べていた並列処理、並行処理などなど
「なんとなくわかったつもり」でいる自分に喝を入れ、頭を整理するために、備忘録がてらこの記事を使わせていただきます
間違っている箇所などあれば、ご指摘お願いします!
🙂調べながら頭の中を整理🙂
並列処理と並行処理ってなんぞや
並列処理
コンピュータに複数の処理装置を内蔵し、複数の命令の流れを同時に実行すること
引用:並列処理(パラレルプロセッシング)とは - IT用語辞典 e-Words
複数のレジにそれぞれの列ができるイメージ
本当に同時の複数の処理を実行して、全体の処理時間を短くする

並行処理
コンピュータの単一の処理装置を複数の命令の流れで共有し、同時に実行状態に置くこと
引用:並列処理(パラレルプロセッシング)とは - IT用語辞典 e-Words
1人の店員さんが同時に複数のお客さんを受け持つイメージ
「前の人かごの中いっぱいじゃん、私飲み物1本だけですぐ終わるのに、、」
って思ってたら、気を利かした店員さんが
「前の人途中だけど、会計先にしたげるわ」
って言ってくれて、待ち時間が減ったみたいな

1人で2人の会計を受け持ってて、同時にやっているように見えるけど、総時間は変わらない
複数の処理を受け持って、同時に実行しているように見せかけるけど、全体では速くならないのが並行処理
マルチプロセスとマルチスレッドってなんぞや
どっちも複数の処理を実行する、並列処理、並行処理のためのもの
違いは、処理単位!
プロセス
OSからメモリ領域などの割り当てを受けて処理を実行しているプログラムのことを言う。OSの機能の一部を実行するシステムプロセスと、利用者の指示で実行されるユーザープロセスがある。必要に応じて別のプロセスを起動することができ、起動した側を親プロセス、された側を子プロセスという。
引用:プロセスとは - IT用語辞典 e-Words
- 実行してるプログラムのこと
- OS上で独立した処理単位
- 独立のメモリ空間を保有している
スレッド
並行処理に対応したマイクロプロセッサ(CPU/MPU)およびオペレーティングシステム(OS)におけるプログラムの最小の実行単位をスレッドという。連続して実行される一本の命令の並び、処理の流れのことで、並行処理を行わない場合は一つの実行プログラム(プロセス)は一つのスレッド(シングルスレッド)で命令を順に実行していく。
引用:スレッドとは - IT用語辞典 e-Words
- プロセスよりも小さな処理の単位がスレッド
- プログラムの処理の中の実行単位
- 1つのプロセスの中で、複数起動できる処理単位
- 同じメモリ空間を共有する
マルチプロセス
マルチプロセスとは、複数のタスクを並行して実行する機能のこと。CPUは複数の処理を完全に同時実行できないため、OSが強制的に管理して切り替える。
引用:マルチプロセスとは-意味・解説|フィデリ IT用語辞典
python hello.pyとpython aloha.pyを同時に実行できるイメージ
数学の課題しながら国語の音読するみたいな
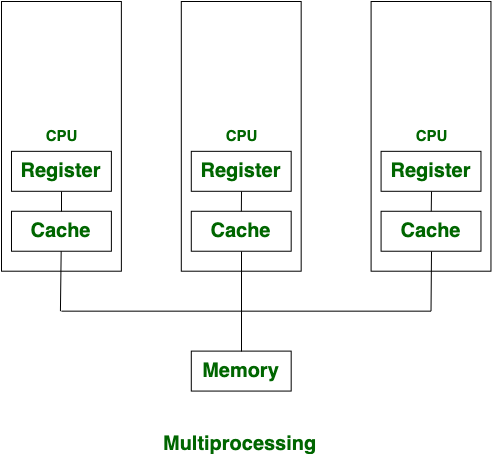
引用画像:Difference between Multiprocessing and Multithreading
マルチスレッド
一つのコンピュータプログラムを実行する際に、複数の処理の流れを並行して進めること。また、そのような複数の処理の流れ。
引用:マルチスレッドとは - IT用語辞典 e-Words
1.ファイルを読み込む
2.縦棒グラフで可視化画像を作成する
3.横棒グラフで可視化画像を作成する
4.画像を出力する
みたいな処理のがあった時、2と3を同時にするのがマルチスレッドのイメージ
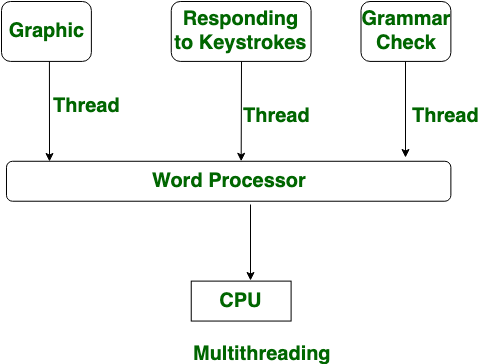
引用画像:Difference between Multiprocessing and Multithreading
負荷の種類
I / Oバウンド
I / Oバウンドとは、計算の完了に要する時間が主に入出力操作の完了を待機するのに費やされた時間によって決定される状態を指します。これは、CPUバウンドであるタスクの反対です。
引用:I/O bound - Wikipedia
- プログラムのディスクとの入出力(Input/Output、I / O)による負担のこと
- ファイルの読み書き、DBへの接続、ネットワーク通信で発生することが多い
- 処理よりもデータの読み書きに多くの時間を費やす場合
青い箱はプログラムが作業を行っている時間を示し、赤い箱はI/O操作が完了するまでの待ち時間を示す
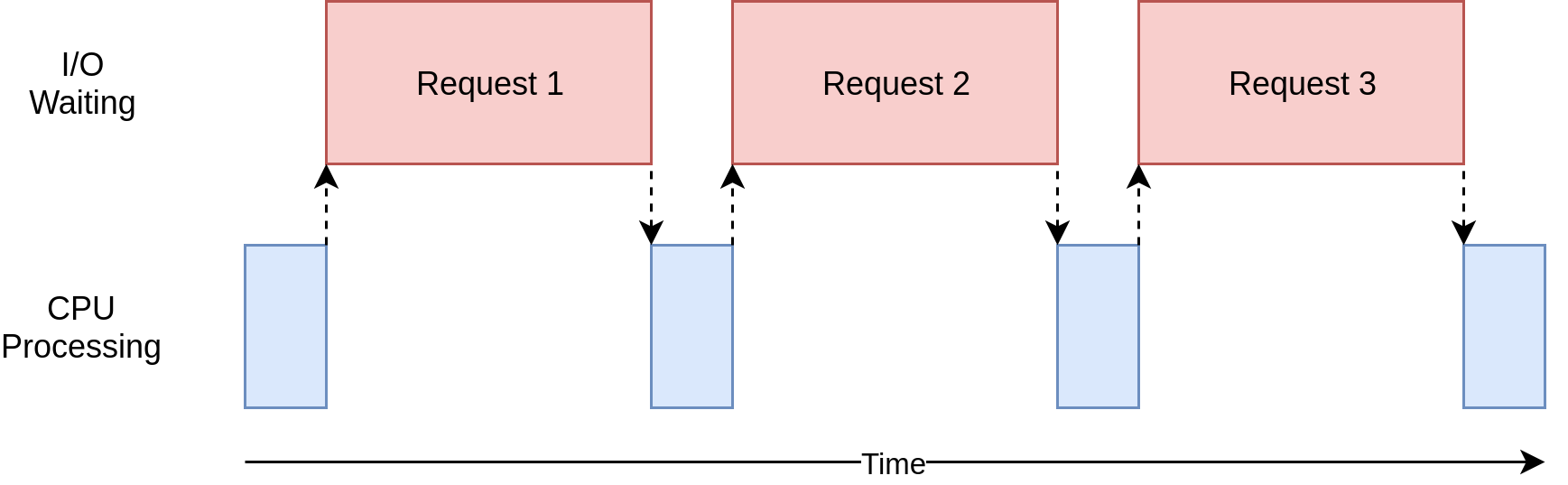
画像引用:Speed Up Your Python Program With Concurrency
CPUバウンド
たとえば、大規模な科学計算を行うプログラムがあったとして、そのプログラムはディスクとの入出力(Input/Output、I/O)は行わないが、処理が完了するまでに相当の時間を要するとします。「計算をする」ということからも想像がつくとおり、このプログラムの処理速度はCPUの計算速度に依存しています。これがCPUに負荷をかけるプログラムです。「CPUバウンドなプログラム」とも呼ばれます。
引用:CPUバウンドとI/Oバウンド - ablog
- プログラムが原因で、CPUにかかる負荷のこと
- 処理速度がCPUに制約される
- 外部リソースからの入出力は行わないが、処理が完了するまでに相当の時間を要する場合
- 数値計算のようにCPUを使い続けるような処理とかで発生することが多い
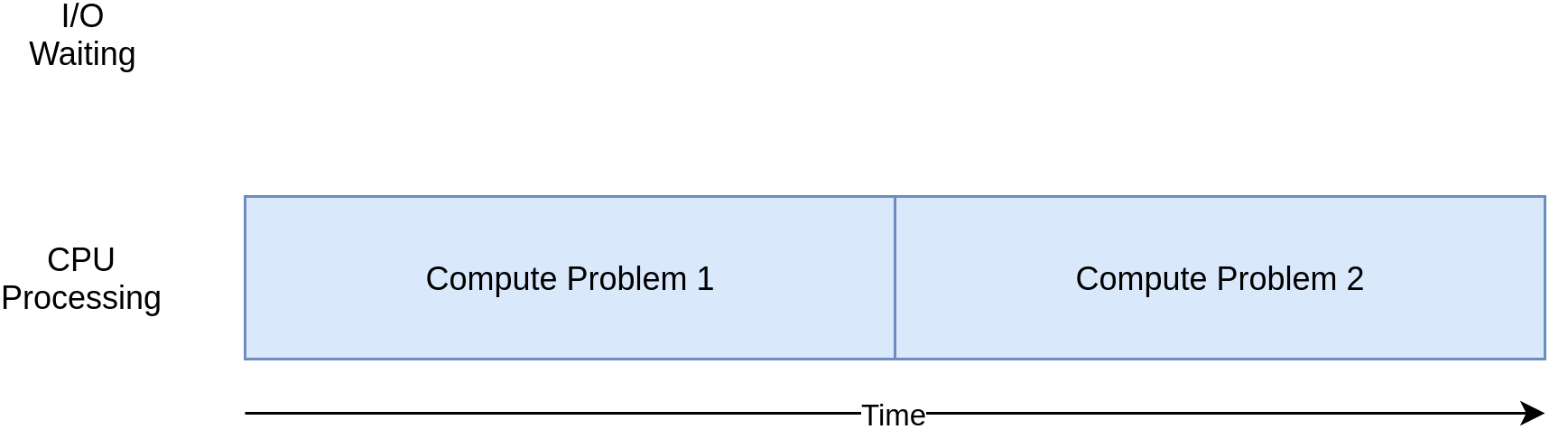
画像引用:Speed Up Your Python Program With Concurrency
🙂Pythonで実践🙂
ハードウェアの実行環境は以下のとおりです
- MacBook Pro
- プロセッサ:1.4 GHz Quad-Core Intel Core i5
- メモリ:16 GB
で、Python 3.7.4で実行します
ライブラリ
標準ライブラリが充実していす
マルチスレッドのライブラリたち
など
マルチプロセスのライブラリたち
【標準ライブラリ】
【外部ライブラリ】
など
GILの制約
PythonにはGILの制約があるので、マルチスレッドで実行しても、同時に実行されるスレッドが1つに制限されてしまいます
ただ、I/O関数を呼び出す時には解放されるそうです
今回使用するconcurrent.futures
- Python3.2 から追加された並行・並列処理用のライブラリ
- マルチスレッドを扱う ThreadPoolExecuterとマルチプロセスを扱う ProcessPoolExecuterの2つのクラスがある
マルチプロセスお試し
まず、GILの制約がないマルチプロセスを、concurrent.futuresで試します
素数判定の問題を使います
まずは普通に
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
startTime = time.time()
for number, prime in zip(PRIMES, map(is_prime, PRIMES)):
print(f'{number} is prime: {prime}')
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Time:3.000836133956909[sec]
約3秒で実行できました
ProcessPoolExecutorでマルチプロセスに
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
startTime = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print(f'{number} is prime: {prime}')
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Time:0.8680341243743896[sec]
1/3以下に...!
マルチスレッドお試し
GILの制約があるマルチスレッドですが、I / Oは制約が解除されます
ということで、I / Oの例を用いて、concurrent.futuresで試します
まずは普通に
シングルスレッドで実行
import urllib.request
import time
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def get_detail():
# Start the load operations and mark each future with its URL
for url in URLS:
try:
data = load_url(url,60)
except Exception as exc:
print(f'{url} generated an exception: {exc}')
else:
print(f'{url} page is len(data) bytes')
def main():
startTime = time.time()
get_detail()
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()
http://www.foxnews.com/ page is len(data) bytes
http://www.cnn.com/ page is len(data) bytes
http://europe.wsj.com/ generated an exception: HTTP Error 403: Forbidden
http://www.bbc.co.uk/ page is len(data) bytes
http://some-made-up-domain.com/ page is len(data) bytes
Time:14.911992073059082[sec]
約15秒かかりました
ThreadPoolExecutorでマルチスレッドに
import concurrent.futures
import urllib.request
import time
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
def get_detail():
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print(f'{url} generated an exception: {exc}')
else:
print(f'{url} page is len(data) bytes')
def main():
startTime = time.time()
get_detail()
endTime = time.time()
runTime = endTime - startTime
print (f'Time:{runTime}[sec]')
if __name__ == '__main__':
main()
http://www.foxnews.com/ page is len(data) bytes
http://europe.wsj.com/ generated an exception: HTTP Error 403: Forbidden
http://some-made-up-domain.com/ page is len(data) bytes
http://www.cnn.com/ page is len(data) bytes
http://www.bbc.co.uk/ page is len(data) bytes
Time:4.659713983535767[sec]
こちらも1/3以下に👏
おわり
並列処理、並行処理が常に必要であるとは限らず、必要でない時に使用してもその恩恵を受けることはできません
スレッドとプロセスの動作とか、並行処理と並列処理への理解が、コードのボトルネックの発見だったり、ソフトウェアの実装なんかに役立つそうです
私は「なんとなくわかったつもり」で放置することが本当に多いので、シリーズ化できるかも...😀