最近Pythonでオーケストレーション層(BFF)のアプリケーションを書く機会がありました。
Python3.4からはasyncioが導入され、I/Oバウンドな処理はシングルスレッドでも効率的に捌けるようになったものの、依然としてCPUバウンドな処理はGILが存在することで、シングルプロセス下では並列処理が制限されます。
このことから言語特性として、CPUバウンドよりもI/Oバウンドな処理を複数捌くことに適していると見ることができます。言語選択の意思決定をする際に重要なファクターとなりますが、そのためにはGILの仕組みを改めて知る必要があると思い、調べてみました。
GIL(グローバルインタプリタロック)とは
そもそもGILとは何のことでしょうか。
正式にはGlobal Interpreter Lock(グローバルインタプリタロック)といい、PythonやRuby等の言語に見られる排他ロックの仕組みです。この2つの言語だけを見ると動的型付け言語に特徴的と思われるかもしれませんが、そうではなく、むしろC言語との協調に関わっています。
PythonはC言語で実装されたCPythonが広く使われている
GILの説明に入る前に、「PythonにはGILが存在する」と説明してしまうと語弊があるので、もう少し丁寧に拾っていきましょう。
そもそもPythonという言語には複数の実装が存在します。最も広く使われているのがC言語で実装されたCPythonで、おそらくPythonの言語特性が説明されているときには、暗黙的にこのCPythonを指しているはずです。
その他代表的なものとしてJavaで実装されたJythonや、.Net Frameworkで動作するIronPythonがありますが、これらにはGILが存在しません。それだけを聞くとなぜCPythonが利用されているのか?と思うかもしれませんが、NumPyのような主要ライブラリはC言語で実装されていることが多く、言語実装のアップデート頻度からもCPythonが使われることが多くなっています。
これらを踏まえて、以降GILについてはCPythonの仕様をもとに説明していきます。
GILの排他ロックについて
では本題に戻ってGILの説明に入りますが、大まかに言うと「複数スレッド下でもロックを持つ単一スレッドでしかバイトコードが実行できず、その他のスレッドは待機状態になる」ことです。ロックは定間隔で開放され、新たにロックを獲得した別スレッドがプログラムを実行します。
ロックの仕組みについては後述しますが、ひとまずCPUバウンドな処理は一スレッドでしか実行できず、処理の並列化が制限されると認識しておけば良いでしょう。
では実際にGILの影響をコードで見ていきましょう。まずは大きな数を数えるシンプルなプログラムを実行します。
def countdown():
n = 10000000
while n > 0:
n -= 1
if __name__ == '__main__':
start = datetime.now()
t1 = Thread(target=countdown)
t2 = Thread(target=countdown)
t1.start()
t2.start()
t1.join()
t2.join()
end = datetime.now()
print(f"Time: {end - start}")
2スレッドで1000万のカウントダウンをするプログラムですが、私の環境下で実行時間は約1.1秒でした。では1スレッドで実行するとどうでしょうか?
if __name__ == '__main__':
start = datetime.now()
countdown()
end = datetime.now()
print(f"Time: {end - start}")
こちらは約0.53秒で終了しました。2スレッド時の約半分ということは、各スレッドが並行して実行されていないことが分かります。CPUバウンドな処理は、一つのスレッドでしか実行できないからです。
ではCPUバウンドではない処理はどうでしょうか?先ほどカウントダウンした箇所をsleepに置き換えて、2スレッドで実行してみます。
def sleep():
time.sleep(2.0)
このときは約2秒間で処理が終了しています。CPUバウンドであれば2×2秒で4秒かかるところでしたが、スリープならば半分の2秒で終わっています。これはスリープ実行時にロックを開放し、待機中のスレッドが直後にスリープ状態に入ることで、実質的に並行して処理されたためです。
ちなみにロックが発生するのはPythonのバイトコードを実行するときで、必ずしもCPUを使っている時だけではありません。
なぜGILが存在するのか
ではそもそもなぜ並列処理に制約をもたらすGILが存在するのでしょうか。これは私自身、CPythonのコードを読み解いて導き出した解ではありませんが、以下のことが主要因なようです。
- メモリ管理やC連携といった低レベルの仕組みをシンプルにするため。
- CPythonはC言語で実装されたライブラリと連携が容易であるが、それらは通常スレッドセーフではないため。
上記の理由からCPythonを実行させるために、一つのスレッドのみがバイトコードを動作可能である必要があり、それを実現するべくGILという仕組みが存在します。
ただしこれはPythonという言語自身の特性ではなく、C言語で実装されたCPythonに付随するものです。例えばJavaで実装されたJythonは、JVMによるスレッド管理のおかげでマルチスレッド下でも競合が発生しないため、GILが存在しません。
もっともGILを回避できるメリットよりも、C言語の資産を活用できることやアップデートが活発であるといったメリットが大きいと判断されているためか、CPythonが多く利用されているのでしょう。
GILの開放と獲得
(この項目の説明はUnderstanding the Python GILを元にしています)
CPythonのGILの仕組みはバージョン3.2によって変更され、gil_drop_requestというロック開放リクエストが起点となりました。
例えばスレッドが一つしかない場合、単一のスレッドが処理終了となるまで実行を続けます。これはロック開放リクエストがどこからも届いていないためです。
一方でスレッドが複数ある場合は異なります。サスペンドされたスレッドはデフォルトで5ms待機し、その後gil_drop_requestを'1'にセットします。すると実行中のスレッドはロックを開放し、それを知らせるシグナルを発します。
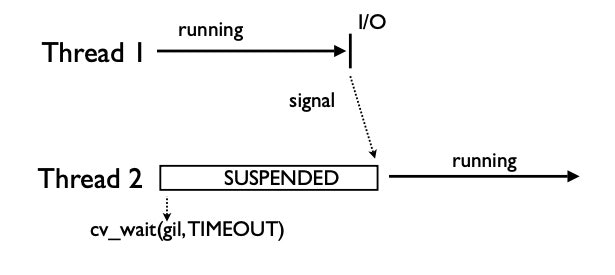
ロック待ちのスレッドはそのシグナルを受け取ると、ロックを獲得しますが、その際に獲得したことを知らせるシグナルを発します。先ほどロックを開放したスレッドはそのシグナルを受け取ることで、中断状態に入ります。
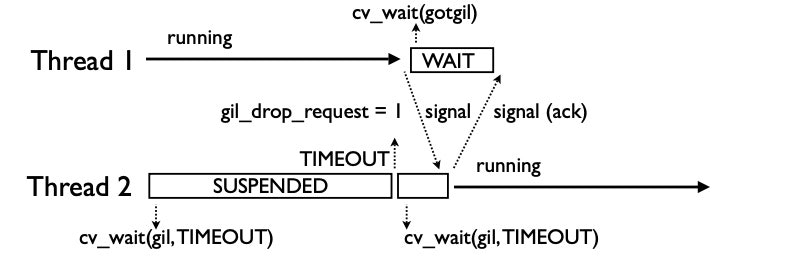
(※画像はいずれもUnderstanding the Python GILより引用)
タイムアウト後は先ほどと同様に、gil_drop_requestをセットすることで再びロック獲得を試みる…といった流れで複数のスレッドがロックの獲得と開放と繰り返すことになります。
タイムアウト時間は変更できる
ロック待ちのスレッドはデフォルトで5ms待機しますが、これはsys.getcheckinterval()というPythonのコードから時間を参照できます。
またsys.setcheckinterval(time)によってインターバルの時間を変更することもできます。
なぜロック開放リクエストを送る方式になったのか
Python3.2からgil_drop_requestによるロック開放方式となりましたが、それ以前はtickと呼ばれる実行単位あたりでロックが開放されていました。
ちなみにこれはsys.getcheckinterval()によって参照できますが、ロック方式の変更で利用されなくなったので、以下のような警告文が表示されます。
DeprecationWarning: sys.getcheckinterval() and sys.setcheckinterval() are deprecated. Use sys.getswitchinterval() instead.
ではなぜロック開放方式が変更されたのでしょうか。
先ほど紹介したように、現在は待機中のスレッドがロック開放のリクエストを送りますが、以前は実行中のスレッドがデフォルトで100tickの実行単位が経過したらロックを開放していました。しかしこれはマルチコアの状況下ではある問題を孕んでいます。
まずシングルコアのケースで見ていきます。実行中のスレッドがロックを開放すると、待機中のスレッドの一つにそれを知らせるシグナルを送ります。シグナルを受けたスレッドは実行待ちのキューに入りますが、ロックを開放したばかりのスレッドと、シグナルを受けたスレッドのどちらが次に実行されるのかは、OSのスケジューラが優先度をもとに選択します。
(同じスレッドが続けてロックを獲得することがありますが、コンテキストスイッチによるオーバーヘッドを考えるとそれが望ましいこともあります)
しかしマルチコアの場合、実行可能なスレッドが複数あるためどちらもロックを獲得しようとし、いずれかがロックの獲得に失敗します。不要にロックを獲得しようとすること自体もオーバーヘッドになりますし、厄介なことに待機中のスレッドはほとんどロックを獲得できません。
待機中のスレッドは再開するまでにタイムラグがあるので、ロックを獲得しようとしたときには既に、先ほど開放したばかりのスレッドがロックを獲得していることが多いのです。長い処理では片方のスレッドが数十分以上もロックを持ち続けることがあるそうです。
またOSがバッファリングしていることで直ちに終わるI/O処理が頻繁に起こるケースでは、I/O待ちになるたびに次々とロックの開放と取得が行われるために負荷が高まるというデメリットもあります。
上記の問題から考えれば、待機中のスレッドがリクエストを送る現在の方式が優れています。
現行GILのデメリット
では現行のGILに問題がないかといえば、そうではありません。Understanding the Python GILの資料では2つのデメリットが紹介されています。
1. フェアではないロック獲得が起きることがある
まずスレッドが3つ以上存在する場合、ロック開放を要求したスレッドがロックを獲得できず、遅れてきたスレッドに取られてしまうことがあります。
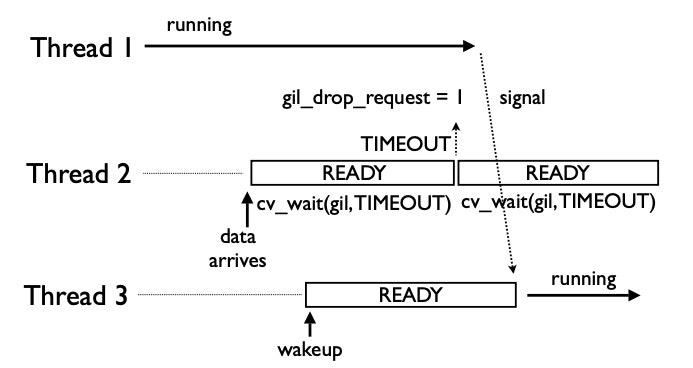
(※Understanding the Python GILより引用)
上記の画像ではスレッド2がタイムアウト後にロック開放を要求し、スレッド1がロックを開放と共にシグナルを送っています。本来ならスレッド2がロックを獲得するはずが、その間にスレッド3が後からキューに入ったことで優先的にロックを獲得しています。
このようにタイミング次第では特定スレッドにロック獲得が偏り、並列処理が非効率になる可能性があります。
2. Convoy Effectによる非効率が発生することがある
またCPUバウンドなスレッドと、I/Oバウンドなスレッドが同時に走っている場合、Convoy Effectという非効率な状態が発生することがあります。
処理全体の観点で考えれば、I/Oバウンドなスレッドに優先してロックを持たせ、I/O待ちになったらCPUバウンドなスレッドに移り、I/Oが終了したら再び優先的にロックを持たせることが効率的です。反対にCPUバウンドなスレッドばかりがロックを持てば、I/Oバウンドな処理が残り、I/O待ちの待機時間の分だけ実行時間が長引くことを考えれば分かりやすいでしょう。
しかしスレッドは優先度を持たないため、どのスレッドが優先的にロックを獲得するかを制御できません。2つのスレッドが待機中の場合、CPUバウンドなスレッドが先にロックを獲得するかもしれません。
またI/Oが直ちに終了する場合でもタイムアウトまで待機する必要があります。もしI/O待ちが大量に発生する場合、逐次タイムアウトを待っている間にCPUバウンドな処理が終了し、I/O待ちばかり残ってしまうことがあります。
これを「Convoy Effect」といいますが、タイムアウトして始めてロック開放を要求するため、全体最適の観点から非効率になるケースが発生しうるのです。
マルチプロセスで並列処理を行う
多くの方がご存知だと思いますが、マルチプロセスにすることでCPUバウンドな処理を並列実行することができます。これは各プロセスがインタプリタを保持し、GILはインタプリタ単位で存在するためです。
試しに先ほどマルチスレッドで処理を行った部分を、マルチプロセスで実行してみましょう。
def countdown():
n = 10000000
while n > 0:
n -= 1
if __name__ == '__main__':
start = datetime.now()
t1 = Process(target=countdown)
t2 = Process(target=countdown)
t1.start()
t2.start()
t1.join()
t2.join()
end = datetime.now()
print(f"Time: {end - start}")
マルチプロセス下では約1.1秒かかった処理が、マルチプロセス下では約0.65秒となりました。CPUバウンドでも並列実行できていることがわかります。
スレッドと比べてオーバーヘッドが大きいものの、プロセス間でも値を共有できますし、CPUバウンドな処理を並列実行するときには有用です。
Python 3.8で導入されたサブインタプリタ
この記事を書いている時点ではリリースされたばかりのPython 3.8でサブインタプリタが暫定的に実装されました。サブインタプリタはPEP 554で提案されていますが、まだマージはされていません。
先ほど述べたように、GILはインタプリタ単位で存在しますが、サブインタプリタによって同一プロセス内で複数のインタプリタを保持することができます。
将来的に可能性を秘めたアイデアですが、CPythonはRuntimeでステートを持っているため、インタプリタでステートを保持するためには依然多くの問題を抱えているようです。
実際にPython 3.8に上げて、_xxsubinterpretersをimportすれば利用できますが、まだプロダクションレベルで活用するには難しいかもしれません。
asyncioによるイベントループを活用する
GILの説明という本筋から外れ、方法論的な話になりますが、現行のPythonではI/O待ちが複数発生するケースでは、asyncioによるイベントループを活用するほうが実用的かもしれません。
asyncioはI/O多重化によって、複数のI/O処理をシングルスレッドで効率的に処理できるため、マルチスレッドによって得られる恩恵と近いものがあります。
マルチスレッドに比べてメモリの節約のほか、複数スレッドのロック獲得/開放を考慮する必要がなく、async/awaitによるネイティブコルーチンが直感的に書けることも相まってプログラマの思考負担も減るでしょう。
なおPythonのコルーチンについては、いずれ別途記事で詳しく紹介する予定です。
最後に
後半に話が広がってしまいましたが、本記事ではGILにまつわるトピックを包括的に記述してきました。
アプリケーションレベルのコードを書いていて日々意識するポイントではないかもしれませんが、並列処理を行う場合にどのような制約があるかを知っておくことで言語選定に役立てるかと思い記事を書いてみました。