はじめに
ありそうでなかった、COPY入力ファイルにかかれたJSON文書を、通常表に展開してロードする機能を考えてみた。
きっかけ
最近、AWS AuroraがS3上のXML文書をロードできるみたいな記事
https://aws.amazon.com/jp/blogs/news/amazon-aurora-update-call-lambda-functions-from-stored-procedures-load-data-from-s3/
を見て、ほぇーと思っていたけど、じゃあPostgreSQLはどうなの?と考えてみると、そういう機能ってなかったなあと。
XMLはどーでもいいんだが、キーが固定のJSON文書群を、JSON/JSONBでなく表形式に展開する機能もないんだよな。
キー固定のJSON文書群を表形式に展開する
1つのJSON文書を表形式に展開するSQL関数はないわけではない。
json_populate_record(base anyelement, from_json json)
jsonb_populate_record(base anyelement, from_json jsonb)
json_populate_recordset(base anyelement, from_json json)
jsonb_populate_recordset(base anyelement, from_json jsonb)
しかし、この関数は何気に使いにくい。
- COPYと組み合わせて使えないし。
- base anyelement として自分でレコードの形式を定義しなきゃいけないし。
そもそも「固定のキー」を持つJSONであれば、JSON文書内の情報だけで、構造も含めて抽出できるはず。
つまり、(前提条件はあるものの)固定のキーをもつJSON文書群であれば、その中の情報からCREATE TABLEでロード先のテーブルも構築できるはず!
残念ながらCOPY文一発というわけにはいかないので、以下のように一旦中間テーブルを経由して表形式に展開しなければならない。
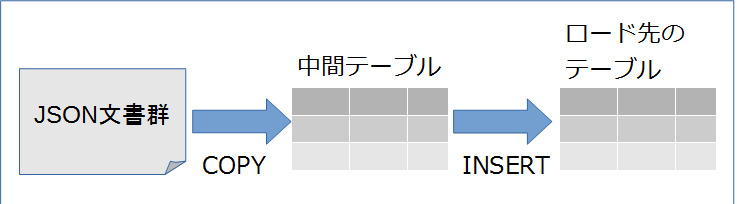
例えば以下のようなJSON文書を格納したCOPY入力形式のファイルがあるとする。
[nuko@localhost ~]$ cat /tmp/test.json
{"aid":1,"bid":1,"abalance":-10,"filler":" "}
{"aid":10001,"bid":2,"abalance":20,"filler":" "}
{"aid":20001,"bid":3,"abalance":-25,"filler":" "}
{"aid":30001,"bid":4,"abalance":100,"filler":" "}
{"aid":40001,"bid":5,"abalance":0,"filler":" "}
これを表形式に展開するなら、一旦、これをJSONB列だけを持つ中間テーブル(仮にtmpとする)にロードする必要がある。
そして、この文書群のキーはaid, bid, abalance, fillerなので、表形式に展開するなら、
CREATE TABLE foo (aid int, bid int, abalance int, filler text)
みたいなテーブルを定義して、そこに対して
INSERT INTO foo (aid, bid, abalance, filler) VALUES
SELECT data->>'aid', data->>'bid', data->>'abalance', data->>'filler' FROM tmp
みたいなINSERT ... SELECT ...文を発行することになるだろう。
もちろん手動でやってもいいのだが、なんか負けた気がする。
JSON文書にキーはあるんだし、(同一キーの型は固定であると仮定すれば)キーの型も収集して、自動でCREATE TABLEをよしなに発行して、INSERT ... SELECT ...だって自動的に発行できそうな気がする。
じゃあ、やってみよう。
load_json_file関数
ということで、load_json_file()という関数をplpgsqlで組んでみた。
関数のパラメータは3つ。
- filename text : ロードするファイル名。COPYと同じようにフルパス記述推奨。内部でCOPYに渡すのでw
- tablename text :ロード対象のテーブル名。SQL識別子引用の対応とかは特にしていない。面倒なので。
- createflag boolean :テーブル生成フラグ。trueならDROP & CREATEしてINSERT。falseならINSERTのみ。
動かしてみた
こんな感じでload_json_file関数を登録しておく。
$ psql -U postgres test -c "\d"
No relations found.
$ psql -U postgres test -f load_json.sql
CREATE FUNCTION
ロード対象のCOPY形式JSON文書群(/tmp/test.json, /tmp/append.json)は以下のような感じ。
$ cat /tmp/test.json
{"aid":1,"bid":1,"abalance":-10,"filler":" "}
{"aid":10001,"bid":2,"abalance":20,"filler":" "}
{"aid":20001,"bid":3,"abalance":-25,"filler":" "}
{"aid":30001,"bid":4,"abalance":100,"filler":" "}
{"aid":40001,"bid":5,"abalance":0,"filler":" "}
$ cat /tmp/append.json
{"aid":50001,"bid":6,"abalance":150,"filler":" "}
{"aid":60001,"bid":7,"abalance":-80,"filler":" "}
$
この状態でload_json_file関数を使って、testテーブルを生成し、データをロードする。
- 1回目はテーブルを生成してロード
- 2回めは追加ロード
$ psql -U postgres test -c "SELECT load_json_file('/tmp/test.json', 'test', true)"
NOTICE: table "test" does not exist, skipping
load_json_file
----------------
0
(1 row)
$
さて、無事にロードされたかなー。
$ psql -U postgres test -c "\d"
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | test | table | postgres
(1 row)
$ psql -U postgres test -c "\d test"
Table "public.test"
Column | Type | Modifiers
----------+---------+-----------
aid | numeric |
bid | numeric |
filler | text |
abalance | numeric |
きちんとtestテーブルが生成されている。
整数値が格納されているaid, bid, abalanceはnumeric型で、fillerはtext型で定義されている。
で、データはロードされているかというと、
$ psql -U postgres test -c "TABLE test"
aid | bid | filler | abalance
-------+-----+----------+----------
1 | 1 | | -10
10001 | 2 | | 20
20001 | 3 | | -25
30001 | 4 | | 100
40001 | 5 | | 0
(5 rows)
$
やったね♪ きちんとロードされました。
次は追加ロードを試してみる。
$ psql -U postgres test -c "SELECT load_json_file('/tmp/append.json', 'test', false)"
load_json_file
----------------
0
(1 row)
$ psql -U postgres test -c "TABLE test"
aid | bid | filler | abalance
-------+-----+----------+----------
1 | 1 | | -10
10001 | 2 | | 20
20001 | 3 | | -25
30001 | 4 | | 100
40001 | 5 | | 0
50001 | 6 | | 150
60001 | 7 | | -80
(7 rows)
$
追加ロードも無事にできました。
今回はSQL関数として実装したけど、シェル等でラッパを作るのもそんなに難しくないはず。
実装
工夫した点
そんなにないけど、一応上げておく。
- 一応、中間テーブルは
CREATE TEMP TABLEで作って、セッション終了時に自動的に消えるようにしたくらいかなー。 - JSON文書群から1文書を取り出して、キーの値とキーの型をSQL関数を使って取得して、それをもとに、
CREATE TABLE文を生成した。- JSONキーとそのキーから取得される値の型を取得するために、
jsonb_each()とjson_typeof()を使用した。 - 今回はstringとnumberのみ対応。arrayとjsonとbooleanは未対応。booleanはすぐに対応は可能だけど。
- 実際には整数値のみの値を格納する列でもnumericで定義しちゃうのがちょっとアレだけど、これは仕方がない。
- JSONキーとそのキーから取得される値の型を取得するために、
実装コード
綺麗なコードじゃないけど・・・あと長い・・・
--
-- load_json_file function.
--
-- parameter.
-- filename : json documents filename
-- tablename : load table name
-- createflag :
-- true : drop, create table, insert
-- false : insert only
--
CREATE OR REPLACE FUNCTION load_json_file(filename text, tablename text, createflag boolean) RETURNS integer AS $$
DECLARE
sql text;
create_table_sql text;
drop_table_sql text;
insert_column_sql_fragment text;
select_sql_fragment text;
insert_sql text;
select_sql text;
rec RECORD;
loop_cnt integer;
BEGIN
-- Create JSON data load temporary table
CREATE TEMP TABLE tmp_table (data jsonb);
-- Load JSONB data.
sql := 'COPY tmp_table FROM ''' || filename || '''';
-- RAISE NOTICE 'sql=%', sql;
EXECUTE sql;
loop_cnt := 0;
-- DROP TABLE statements.
drop_table_sql := 'DROP TABLE IF EXISTS ' || tablename ;
-- cREATE TANLE statements.
create_table_sql := 'CREATE TABLE ' || tablename || '(' ;
insert_column_sql_fragment := 'INSERT INTO ' || tablename || '(' ;
select_sql_fragment := 'SELECT ';
FOR rec IN SELECT key, value, jsonb_typeof(value) as type FROM jsonb_each((SELECT data FROM tmp_table LIMIT 1)) as t LOOP
IF loop_cnt <> 0 THEN
create_table_sql := create_table_sql || ', ';
insert_column_sql_fragment := insert_column_sql_fragment || ', ';
select_sql_fragment := select_sql_fragment || ', ';
END IF;
-- CREATE TABLE statements.
CASE rec.type
WHEN 'string' THEN
create_table_sql := create_table_sql || rec.key || ' text';
WHEN 'number' THEN
create_table_sql := create_table_sql || rec.key || ' numeric';
ELSE
-- nop
END CASE;
-- INSERT column statement fragment
insert_column_sql_fragment := insert_column_sql_fragment || rec.key ;
-- SELECT statement fragment
select_sql_fragment := select_sql_fragment || '(data->>''' || rec.key || ''')::';
CASE rec.type
WHEN 'string' THEN
select_sql_fragment := select_sql_fragment || ' text';
WHEN 'number' THEN
select_sql_fragment := select_sql_fragment || ' numeric';
ELSE
-- nop
END CASE;
loop_cnt := loop_cnt + 1;
END LOOP;
-- cretae statements.
create_table_sql := create_table_sql || ')';
insert_column_sql_fragment := insert_column_sql_fragment || ') ';
select_sql_fragment := select_sql_fragment || ' FROM tmp_table';
insert_sql := insert_column_sql_fragment || select_sql_fragment;
-- check createflag
IF createflag = true THEN
EXECUTE drop_table_sql;
EXECUTE create_table_sql;
END IF;
-- EXECUTE insert_sql;
-- RAISE NOTICE 'insert_sql=%', insert_sql;
EXECUTE insert_sql;
-- drop temporary json table
DROP TABLE IF EXISTS tmp_table;
RETURN 0;
END
$$
LANGUAGE plpgsql;
こうやって組んでおきながら言うのもアレだが、plpgsqlのスクリプト組むときに、PostgreSQL文書を見ながら書いている気がする。あの言語、未だにきちんと覚えきれぬ・・・