本記事は、連載記事 TensorFlow内部構造解析 の1つで、GraphOptimizationPassによるTensorFlowの計算グラフ最適化処理について説明した記事になります。
- TensorFlow v1.13.0-rc0
- コミットID: a8e5c41c5bbe684a88b9285e07bd9838c089e83b
TensorFlowにおける計算グラフの最適化
TensorFlowでは、以下の3つの最適化機能の仕組みを使って、ユーザが定義した計算グラフを最適化した後に実行します。
- GraphOptimizationPass ★本記事で説明
- Grappler
- GraphOptimizer
本記事では、これら3つの最適化の仕組みの中でGraphOptimizationPassによる計算グラフ最適化処理について説明します。
GraphOptimizationPassによる最適化項目
GraphOptimizationPassは、計算グラフの構造が大きく変更される前後に追加することのできる最適化処理です。
ライブラリ使用の有無などをビルドオプションで指定することによって、GraphOptimizationPassに登録されている最適化処理の有効/無効が自動的に決まります。
またGraphOptimizationPassには、TensorFlowの内部実装の制約から作られたと思われる計算グラフ変形処理も多く含まれているようです。
GraphOptimizationPassとして最適化処理を追加できるフェーズは、以下に示すように4つあります。
| フェーズ | |
|---|---|
| PRE_PLACEMENT | 計算グラフの各ノードにデバイスを割り当てる前 |
| POST_PLACEMENT | 計算グラフの各ノードにデバイスを割り当てた後、かつGrapplerによって計算グラフが最適化される前 |
| POST_REWRITE_FOR_EXEC | Grapplerによって計算グラフが最適化された後、かつ計算グラフをデバイスごとに分割する前 |
| POST_PARTITIONING | 計算グラフをデバイスごとに分割した後(GraphOptimizerによって計算グラフが最適化される前) |
GraphOptimizationPassに登録されている最適化処理を、フェーズごとに示します。
PRE_PLACEMENT
| No | Optimizer名 |
|---|---|
| 1 | FunctionalizeControlFlowPass |
| 2 | EncapsulateXlaComputationsPass |
| 3 | LowerIfWhilePass |
| 4 | ParallelConcatRemovePass |
| 5 | AccumulateNV2RemovePass |
1. FunctionalizeControlFlowPass
ソースコード:tensorflow/compiler/tf2xla/functionalize_control_flow.cc
(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
TensorFlowでは、条件分岐 tf.cond やループ処理 tf.while_loop を、複数のOperationを組み合わせることにより実現しています。
しかしこれはTensorFlowの内部実装からの制約によるもので、XLAのように最適化処理で計算グラフの変形を行うことが中心となるグラフコンパイラの場合、非常に扱いにくいものになっています。
このため本最適化処理では、tf.cond や tf.while_loop によって生成されたノードを、XLAで最適化しやすい If ノードや While ノードに変形します。
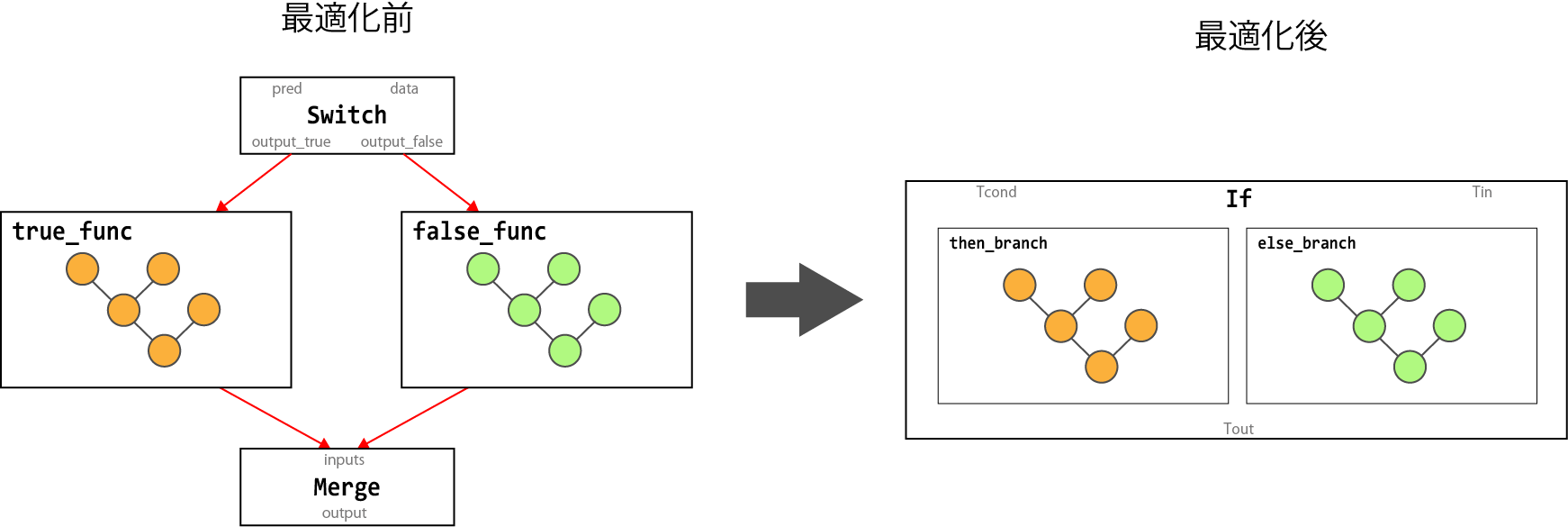
| 変換前 | 変換後 |
|---|---|
| Switch, Merge | If |
| Switch, Merge, Enter, Exit, NextIteration, LoopCond | While |
以下の図は、Switch ノードと Merge ノードから If ノードへ変換するグラフ変形処理を示しています。
2. EncapsulateXlaComputationsPass
ソースコード:tensorflow/compiler/jit/encapsulate_xla_computations_pass.cc
TensorFlowの計算グラフを、XLAで扱う計算グラフに変換します。
XLAを使って演算することが指示されている計算グラフを、XlaLaunch ノードに置き換えます。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。
3. LowerIfWhilePass
ソースコード:tensorflow/core/common_runtime/lower_if_while.cc
(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
FunctionalizeControlFlowPass でも説明した通り、TensorFlowは条件分岐 tf.cond やループ処理 tf.while_loop を、複数の演算を組み合わせることにより実現しています。
しかしTensorFlow内部では If ノード や While ノードをそのまま扱うことができないため、TensorFlowの内部実装の制約に合うように、これらのノードを複数のノードに分解します。
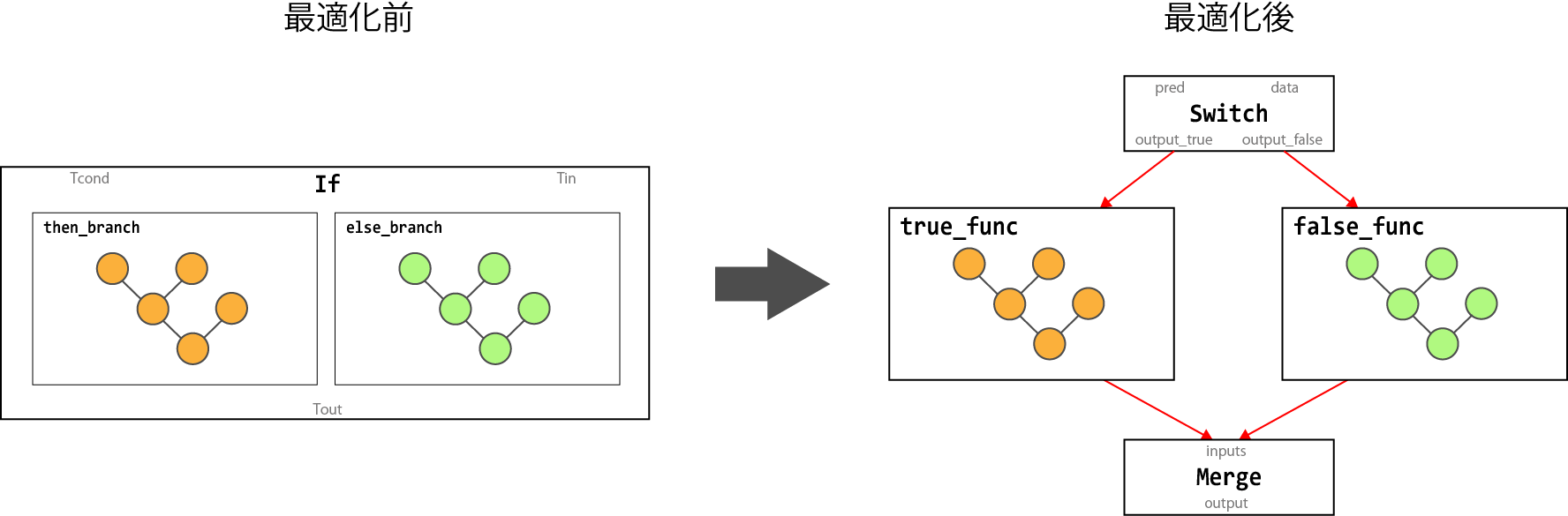
| 変換前 | 変換後 |
|---|---|
| If | Switch, Merge |
| While | Switch, Merge, Enter, Exit, NextIteration, LoopCond |
以下の図は、If ノードを Switch ノード と Merge ノードに変換するグラフ変形処理を示しています。
4. ParallelConcatRemovePass
ソースコード:tensorflow/core/common_runtime/parallel_concat_optimizer.cc
(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
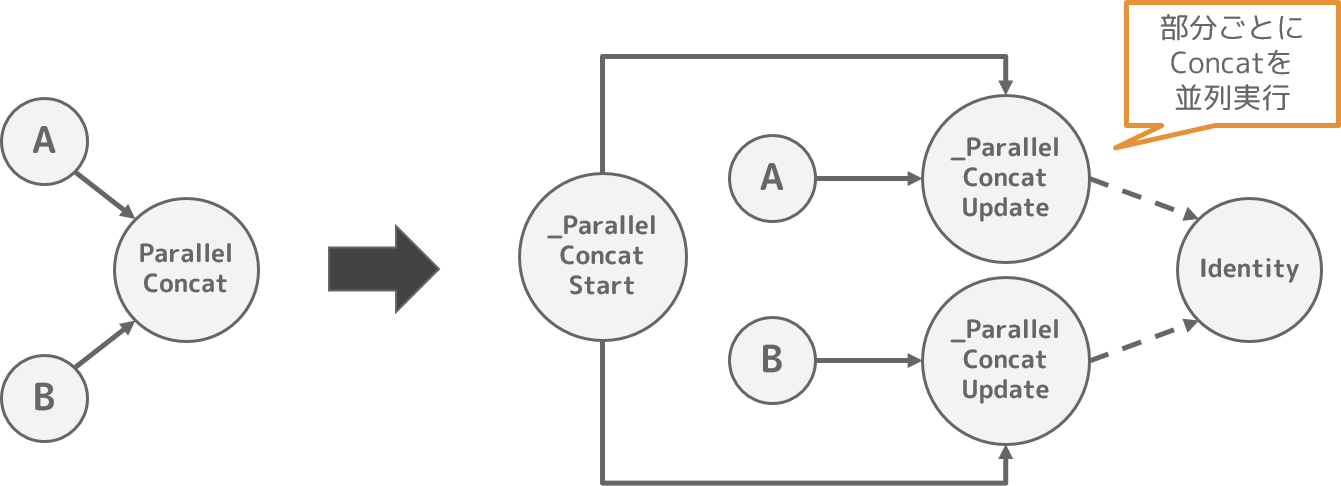
TensorFlowには、並列でConcat処理を実現するための ParallelConcat と呼ばれるOperation1があります。
並列Concat処理の計算グラフの構築をPython側で実装すると煩雑化するために、本最適化処理が存在していると推測しています。
Pythonによる計算グラフ構築時には ParallelConcat という一時的なノードを使い、本最適化処理で並列Concat処理を実現する計算グラフに変形することで、Pythonで計算グラフを構築するよりも容易に並列Concatを実装できるのかもしれません。
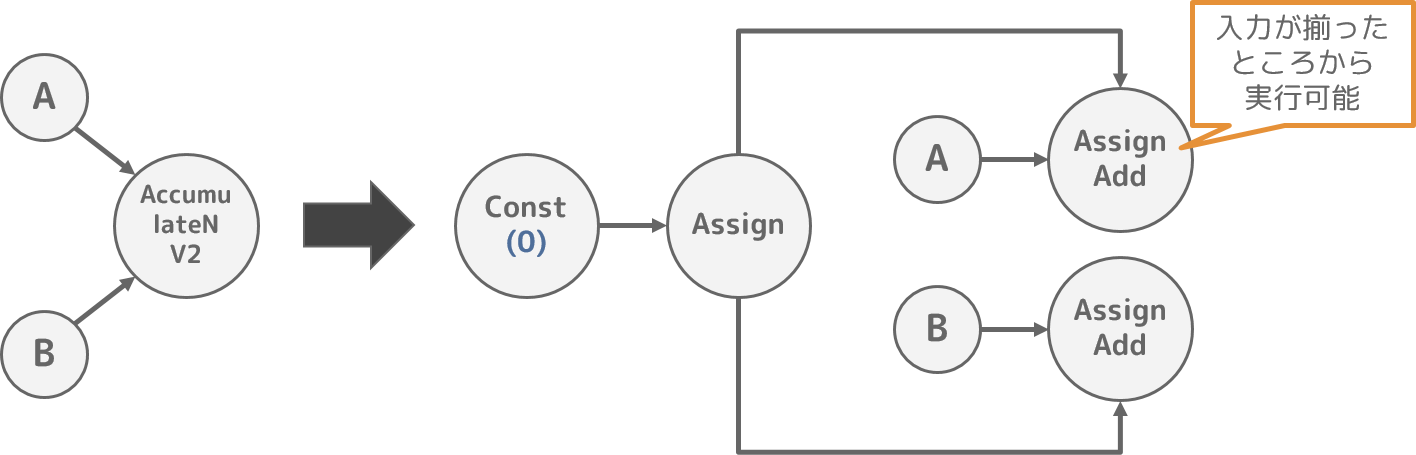
5. AccumulateNV2RemovePass
ソースコード:tensorflow/core/common_runtime/accumulate_n_optimizer.cc
(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
TensorFlowの AddN Operationは入力テンソルが全て揃ってから実行するため、AddN の入力数が多くなるとピークメモリ使用量が大きくなる問題があります。
このためTensorFlowでは、準備できた入力テンソルから足し算を行っていく AccumulateNV2 Operation2を提供しています。
なお、AccumulateNV2 をPython側で実装すると煩雑化するために、本最適化処理が存在していると推測しています。
Pythonによる計算グラフ構築時には AccumulateNV2 という一時的なノードを使い、本最適化処理で計算グラフを変形することで、AccumulateNV2 のOperationを実現しています。
POST_PLACEMENT
| No | Optimizer名 |
|---|---|
| 1 | NcclReplacePass |
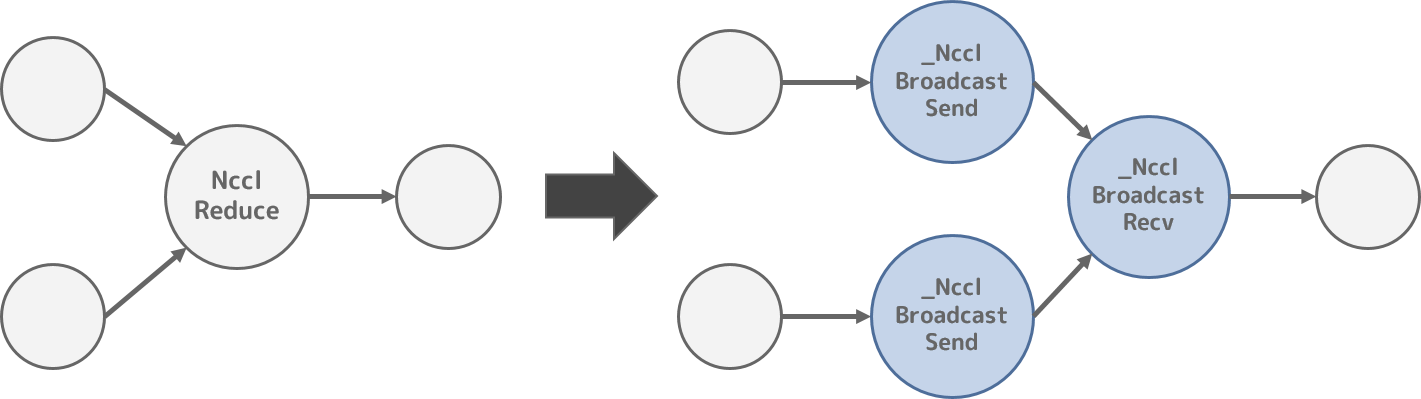
1. NcclReplacePass
ソースコード:tensorflow/core/nccl/nccl_rewrite.cc
(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
NVIDIAは、ncclというマルチGPU間で集合通信するためのライブラリを提供しています。
TensorFlowには、ncclを使ってGPU間で集合通信するためのAPIとして、tf.contrib.nccl.all_sum などの Python API を提供しており、これらのAPIを利用することによりマルチGPU間で集合通信することができます。
このようなncclを使ったマルチGPU間の集合通信を行うPython APIを実現するために、NcclAllReduce や NcclReduce 、NcclBroadcast Operationを使ってTensorFlowの計算グラフを構築します。
しかしこれらのOperationは、TensorFlow内部では _Send や _Recv のように、データの送信と受信で異なるノードとして実現した方が都合がよいと考えられ(推測です)、_NcclReduceSend などのノードに置き換えられます。
POST_REWRITE_FOR_EXEC
| No | Optimizer名 |
|---|---|
| 1 | MarkForCompilationPass |
| 2 | IncreaseDynamismForAutoJitPass |
| 3 | PartiallyDeclusterPass |
| 4 | EncapsulateSubgraphsPass |
| 5 | BuildXlaOpsPass |
1. MarkForCompilationPass
ソースコード:tensorflow/compiler/jit/mark_for_compilation_pass.cc
TensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って演算することが可能な計算グラフのノードに、XLAで実行することを示すフラグを設定します。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。
2. IncreaseDynamismForAutoJitPass
ソースコード:tensorflow/compiler/jit/increase_dynamism_for_auto_jit_pass.cc
TensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
テンソルのサイズが変化するなどでSlice等に指定するサイズが変更された場合、XLAから見ると計算グラフが変化したように見えてしまうため、XLAは再コンパイルしてしまいます。
再コンパイルによる性能悪化の影響は大きいため、XLAからみるとあたかも計算グラフが変更されていないような計算グラフに変形し、XLAが再コンパイルしないようにします。
具体的な計算グラフの変形処理としては、以下のようなケースが考えられます。
Slice(x, begin, size) \quad \Longrightarrow \quad Slice(x, begin, Size(x, begin))
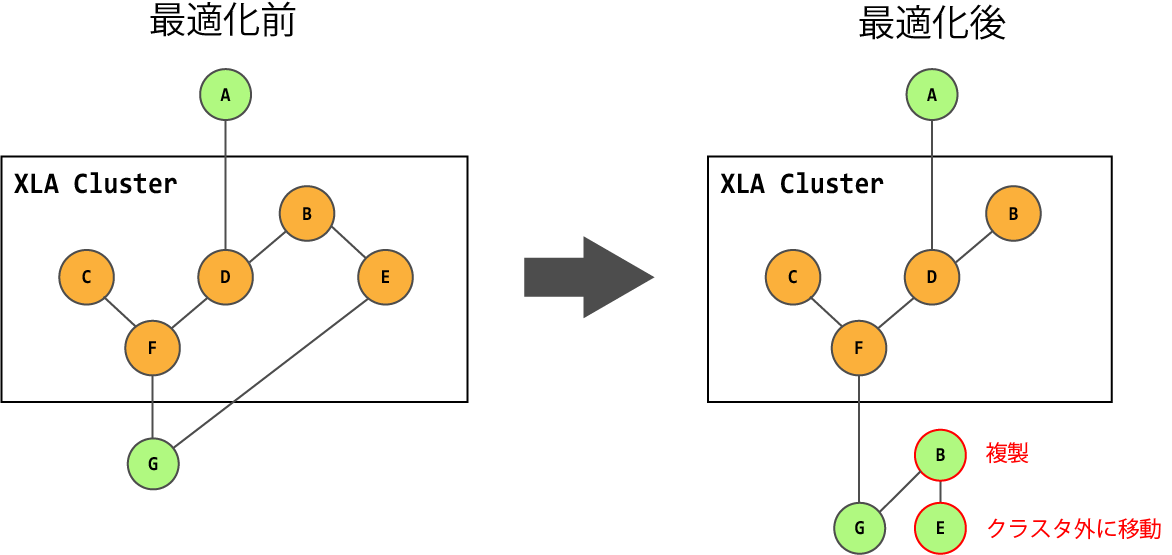
3. PartiallyDeclusterPass
ソースコード:tensorflow/compiler/jit/partially_decluster_pass.cc
TensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って実行する計算グラフのノードのクラスタに含まれるノードの中で、XLAで実行しない方が性能面でよいと判断された場合は、当該ノードをクラスタから外すか、クラスタ外に当該ノードをコピーします。
クラスタから外す判断材料としては、以下が考えられています。
- ホスト-デバイス間のメモリコピー処理を削減可能か
- XLAの再コンパイル回数を削減可能か
4. EncapsulateSubgraphsPass
ソースコード:tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc
TensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って実行する計算グラフのノードのクラスタをサブグラフ化(Function化)して、後続のBuildXlaOpsBassに渡します。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。
5. BuildXlaOpsPass
ソースコード:tensorflow/compiler/jit/build_xla_ops_pass.cc
TensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
EncapsulateSubgraphsPassによってFunction化した計算グラフのノードのクラスタを、_XlaCompile ノードと _XlaRun ノードに置き換えます。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。
POST_PARTITIONING
| No | Optimizer名 |
|---|---|
| 1 | MklToTfConversionPass |
| 2 | MklLayoutRewritePass |
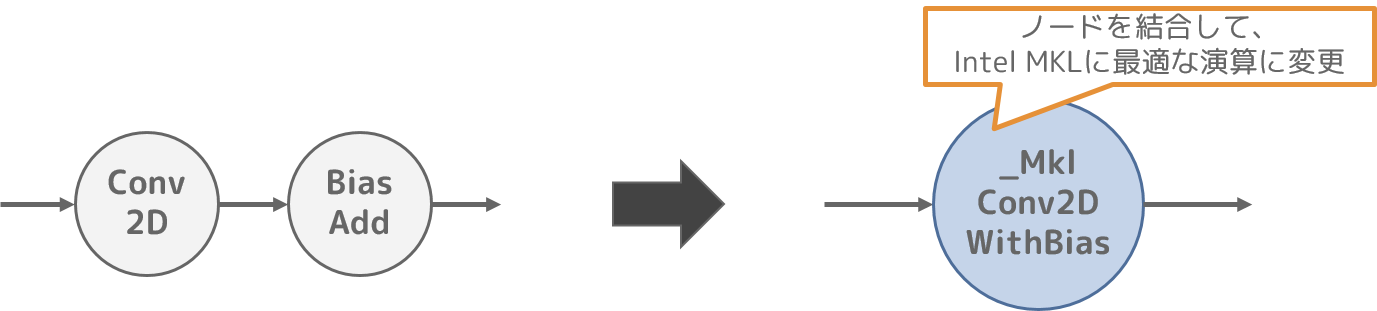
1. MklLayoutRewritePass
ソースコード:tensorflow/core/graph/mkl_layout_pass.cc
Intel MKL3を有効化してTensorFlowを利用する場合、Intel MKLにとって最適に演算できる計算グラフとなるように計算グラフを変形します。
本最適化では、複数ノードの結合や演算途中で出力される中間データの再利用により、Intel MKLで最適に演算可能な処理を増やします。
ここでは Conv2D ノードと BiasAdd ノードを、_MklConv2DWithBias ノードに結合する例を示します。
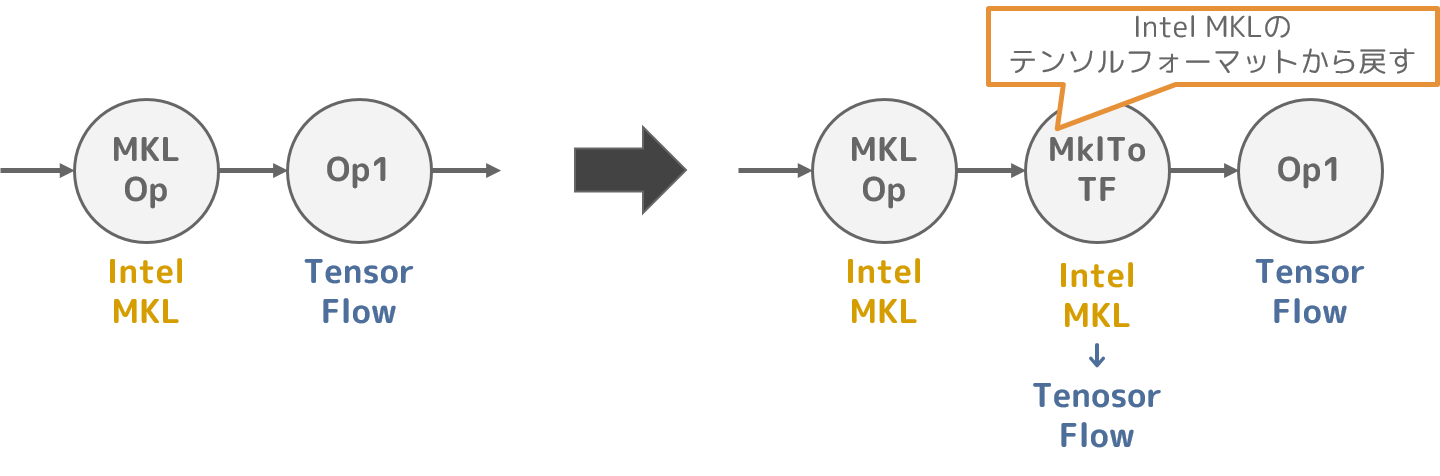
2. MklToTfConversionPass
ソースコード:tensorflow/core/graph/mkl_tfconversion_pass.cc
Intel MKLには最適なテンソルフォーマットがあり、Intel MKLを使って演算する場合はこのテンソルフォーマットを利用することで、性能の向上が見込めます。
ただし、Intel MKLに適したテンソルフォーマットは、TensorFlowのテンソルフォーマットとは異なります。
このため、本最適化処理ではIntel MKLに適したテンソルフォーマットと、TensorFlowのテンソルフォーマットの間の差異による矛盾が発生しないように、テンソルフォーマットを変換するノードを追加します。