本記事は、連載記事 TensorFlow内部構造解析 の1つで、GrapplerによるTensorFlowの計算グラフ最適化処理について説明した記事になります。
- TensorFlow v1.13.0-rc0
- コミットID: a8e5c41c5bbe684a88b9285e07bd9838c089e83b
TensorFlowにおける計算グラフの最適化
TensorFlowでは、以下の3つの最適化機能の仕組みを使って、ユーザが定義した計算グラフを最適化した後に実行します。
- GraphOptimizationPass
- Grappler ★本記事で説明
- GraphOptimizer
本記事では、これら3つの最適化の仕組みの中で最も強力な最適化を行う、Grapplerによる計算グラフ最適化処理について説明します。
Grapplerによる最適化項目
Grapplerは、TensorFlowの計算グラフ最適化の仕組みの中で最も強力な最適化機能を持ちます。
Grapplerのソースコードは以下から参照することができ、実際に最適化を行っている処理は optimizers ディレクトリに配置されたソースコードを参照することで、具体的な計算グラフの変形処理を確認することができます。
Grapplerは、以下に示す14種類の最適化をサポートします。
これらの最適化はデフォルトで有効化されているものもあれば、無効化されているものもあります。
| No | Optimizer名 | デフォルト |
|---|---|---|
| 1 | Layout Optimizer | ON |
| 2 | Model Pruner | ON |
| 3 | Constant Folding | ON |
| 4 | Memory Optimizer | (一部のみ)ON |
| 5 | Auto Parallel | OFF |
| 6 | Arithmetic Optimizer | ON |
| 7 | Dependency Optimizer | ON |
| 8 | Loop Optimizer | ON |
| 9 | Function Optimizer | ON |
| 10 | Debug Stripper | OFF |
| 11 | Shape Optimizer | ON |
| 12 | Remapper | ON |
| 13 | Scoped Allocator Optimizer | OFF |
| 14 | Pin to Host Optimizer | ON |
1. Layout Optimizer
ソースコード:tensorflow/core/grappler/optimizers/layout_optimizer.cc
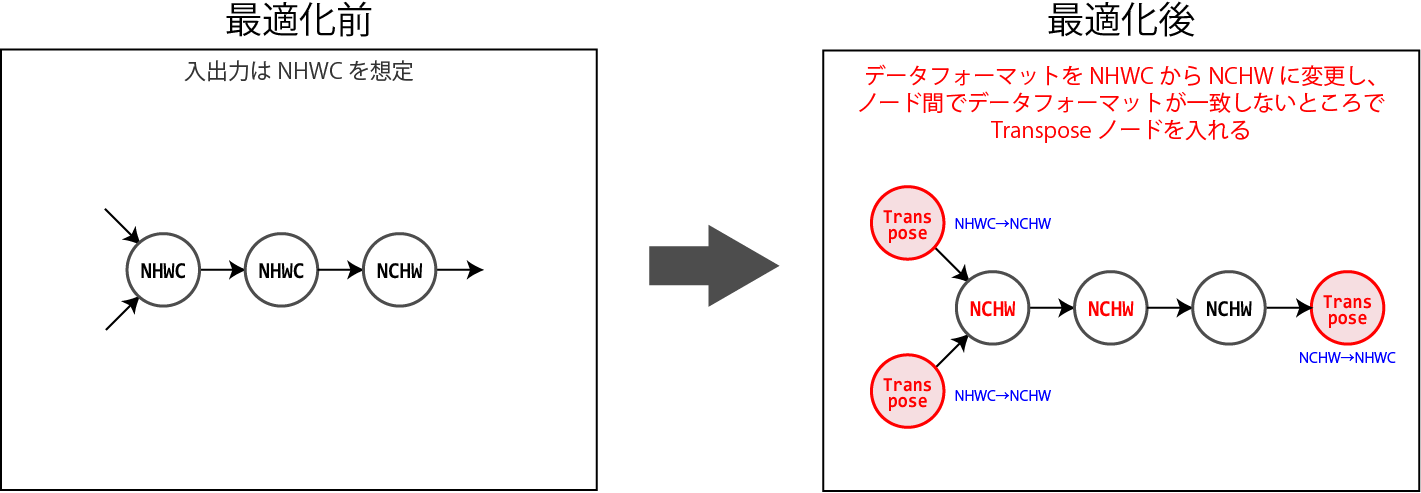
TensorFlowがデフォルトで採用するデータフォーマットはNHWC形式ですが、GPUに最適なデータフォーマットはNCHW形式です。
このため、GPUで実行するノードについてはNCHW形式のデータフォーマットで実行するように計算グラフを変形することで、GPUで最適な演算が行えるようにします。
なお、計算グラフを変形するときに、必要に応じてNCHW→NHWCまたはNHWC→NCHWのデータフォーマット変換を行うためのTransposeノードを挿入し、計算グラフ内でデータフォーマットの一貫性が取れていることを保証します。
2. Model Pruner
ソースコード:tensorflow/core/grappler/optimizers/model_pruner.cc
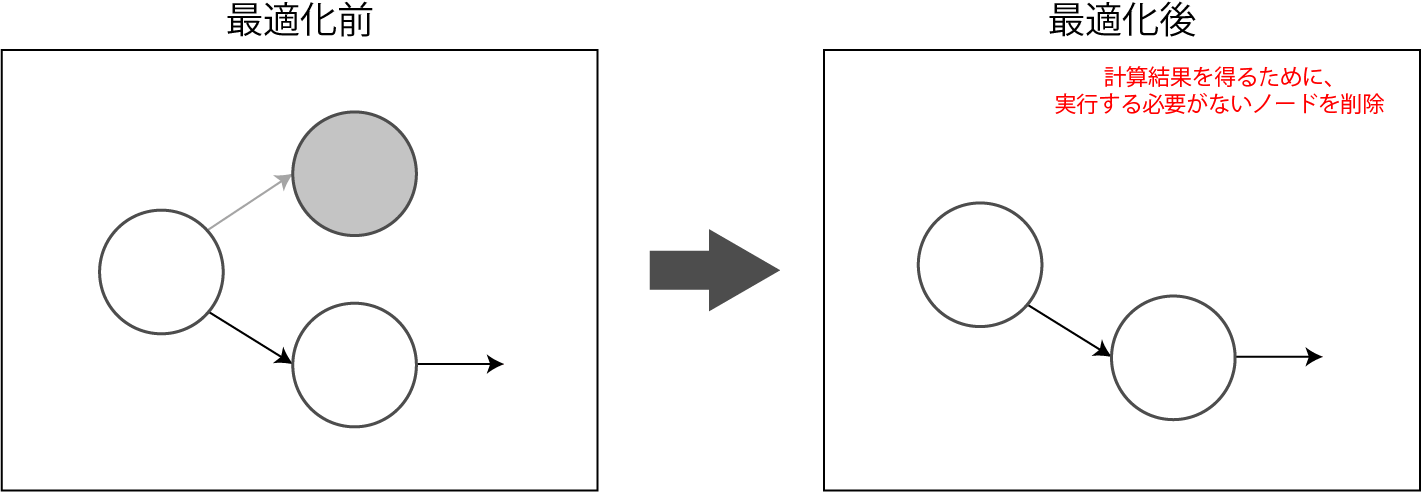
計算グラフの計算結果を得るために、実行する必要がないノードを削除します。
Dead Node Elmination(デッドノードの削除)とも呼ばれます。
ただし、計算結果を取得しない場合には、計算グラフ中の全てのノードが実行されます。
3. Constant Folding
ソースコード:tensorflow/core/grappler/optimizers/constant_folding.cc
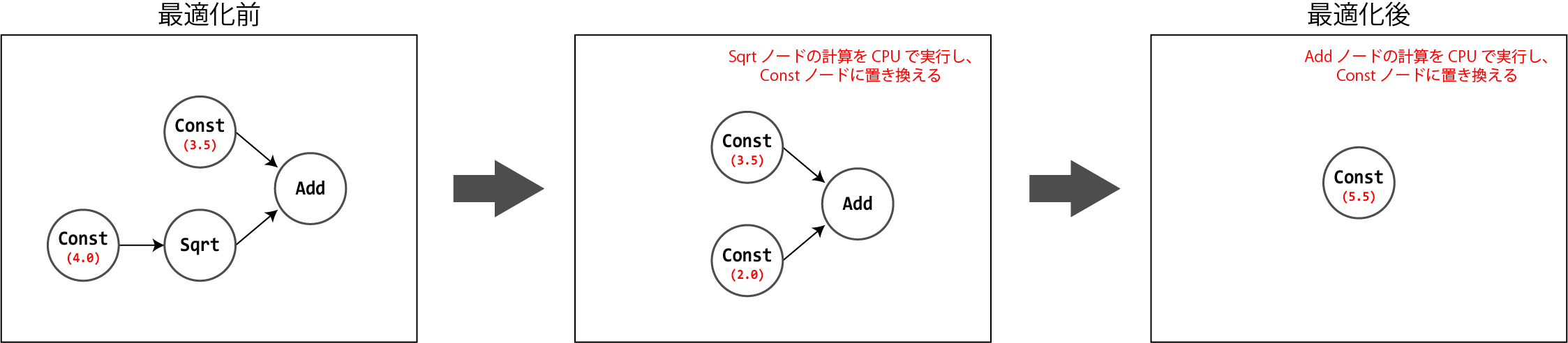
ノードの入力が全て定数値で構成されるテンソルである場合、変換対象とするノードの演算をCPUで実行し、Constノードで置き換えます。
4. Memory Optimizer
ソースコード:tensorflow/core/grappler/optimizers/memory_optimizer.cc
計算グラフ実行中のピークGPUメモリ量を減らすため、tensorflow/core/protobuf/rewriter_config.proto の MemOptType に記載された、以下の施策に基づいて計算グラフを変形します。
- SWAPPING_HEURISTICS
- RECOMPUTATION_HEURISTICS
- SCHEDULING_HEURISTICS
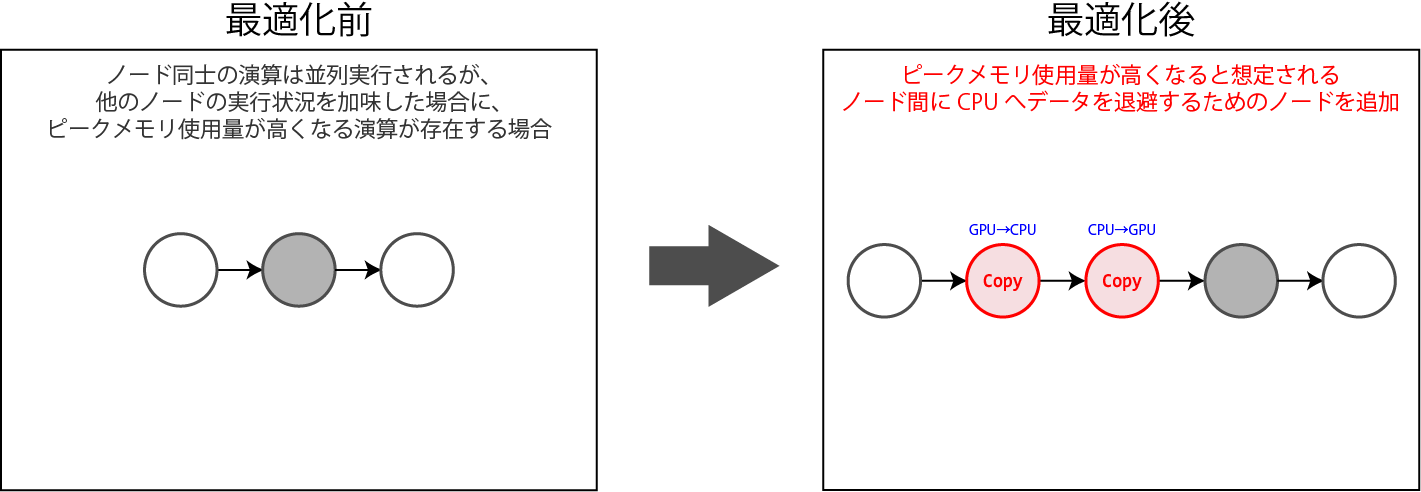
SWAPPING_HEURISTICS
GPU上に確保したメモリをCPUのメモリに退避することで、GPUのメモリ使用量を減らします。
RECOMPUTATION_HEURISTICS
勾配計算で必要なデータをメモリに保持せず、必要になった時に再計算することで、GPUのメモリ使用量を減らします。
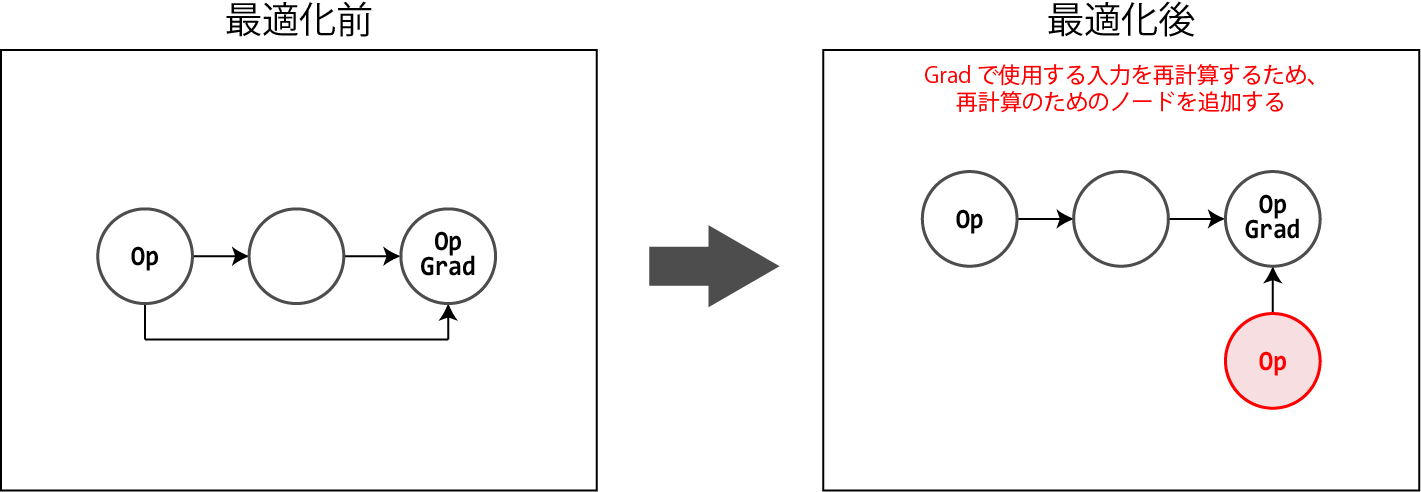
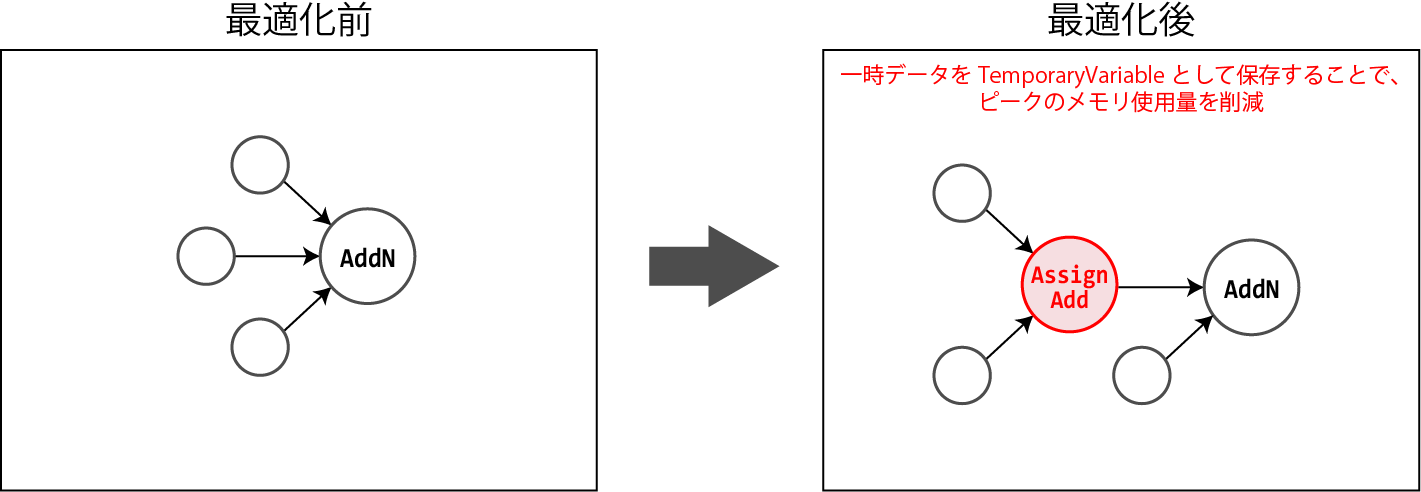
SCHEDULING_HEURISTICS
メモリを多く利用する演算をスケジューリングし、必要に応じて計算の中間結果を保持することで、GPUのメモリ使用量を減らします。
本処理は、AddNノードとAccumulateNV2ノードに対してのみ適用されます。
5. Auto Parallel
ソースコード:tensorflow/core/grappler/optimizers/auto_parallel.cc
計算グラフを複製し、複製した計算グラフを各GPUに割り当てて演算します。
複製した計算グラフの演算結果を計算グラフ数で除算し、tf.Variable を更新します。
FIFO関連の入力ノードは複製されないため、FIFOを利用することでGPU間で異なる訓練データを用いた演算が実行されるため、結果的に学習時間の短縮が見込めます。
6. Arithmetic Optimizer
ソースコード:tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc
算術演算を簡易化します。
算術演算の最適化処理は、以下に示す複数の最適化項目から構成されています。
- AddOpsRewriteStage
- HoistCommonFactorOutOfAggregation
- MinimizeBroadcasts
- RemoveIdentityTranspose
- RemoveInvolution
- RemoveRedundantBitcastStage
- RemoveRedundantCastStage
- RemoveNegationStage
- RemoveLogicalNotStage
- HoistCWiseUnaryChainsStage
- RemoveIdempotentStage
- SqrtDivToRsqrtMulStage
- RemoveRedundantReshape
- ReorderCastAndTranspose
AddOpsRewriteStage
複数のAddノードを、入力を複数受け取って足し算可能なAddNノード1つに置き換えます。
Add(Add(x, y), Add(v, w)) \quad \Longrightarrow \quad AddN(x, y, v, w)
HoistCommonFactorOutOfAggregation
結合の法則により、MulノードやDivノードを削減します。
AddN(Mul(x, y1), Mul(x, y2), Mul(y3, x)) \quad \Longrightarrow \quad Mul(x, AddN(y1, y2, y3))\\
AddN(Div(y1, x), Div(y2, x), Mul(y3, x)) \quad \Longrightarrow \quad Div(AddN(y1, y2, y3), x)
MinimizeBroadcasts
テンソルのBroadcastの回数が最小になるように、グラフを変形します。
Add(Broadcast(a, b), Broadcast(c, d)) \quad \Longrightarrow \quad Broadcast(Add(a, c), Add(b, d))
RemoveIdentityTranspose
何もしない転置や、互いに打ち消しあう転置のペアを削除します。
$ a $ がIdentity Permutationの時、
Transpose(x, a) \quad \Longrightarrow \quad x
$ b $ が $ a $ のInverse Permutationの時、
Transpose(Transpose(x, a), b) \quad \Longrightarrow \quad x
RemoveInvolution
対合(involution)となるノード群を削除します。
$ Op3(Op2(Op1(x))) = x $ の時、
Op3(Op2(Op1(x))) \quad \Longrightarrow \quad x
RemoveRedundantBitcastStage
冗長なBitcastノードを削除します。
$ type(x) = type1 $ の時、
Bitcast(x, type1) \quad \Longrightarrow \quad x
Bitcastノードが連続する時、
Bitcast(Bitcast(x, type1), type2) \quad \Longrightarrow \quad Bitcast(x, type2)
RemoveRedundantCastStage
Castノードの変換元と変換後の型が同じ場合に、Castノードを削除します。
$ type1 = type2 $ の時、
Cast(x, type1, type2) \quad \Longrightarrow \quad x
RemoveNegationStage
削除可能なNegノードを削除します。
Add(Neg(a), b) \quad \Longrightarrow \quad Sub(b, a) \\
Add(a, Neg(b)) \quad \Longrightarrow \quad Sub(a, b) \\
Sub(a, Neg(b)) \quad \Longrightarrow \quad Add(a, b)
RemoveLogicalNotStage
削除可能な論理否定(LogicalNotノード)を削除します。
LogicalNot(Equal(a, b)) \quad \Longrightarrow \quad NotEqual(a, b) \\
LogicalNot(NotEqual(a, b)) \quad \Longrightarrow \quad Equal(a, b) \\
LogicalNot(Less(a, b)) \quad \Longrightarrow \quad GreaterEqual(a, b) \\
LogicalNot(LessEqual(a, b)) \quad \Longrightarrow \quad Greater(a, b) \\
LogicalNot(Greater(a, b)) \quad \Longrightarrow \quad LessEqual(a, b) \\
LogicalNot(GreaterEqual(a, b)) \quad \Longrightarrow \quad Less(a, b)
HoistCWiseUnaryChainsStage
Element-wiseな演算を行うノードに対して、結合の法則を適用します。
Concat(Exp(Sin(x)), Exp(Sin(y)), Exp(Sin(z))) \quad \Longrightarrow \quad Exp(Sin(Concat(x, y, z)))
RemoveIdempotentStage
冪等性のあるノード群を1つのノードに置き換えます。
Op(Op(x, y, z), y, z) \quad \Longrightarrow \quad Op(x, y, z)
SqrtDivToRsqrtMulStage
平方根の計算の後に割り算を行うノードのペアを、平方根の逆数の計算の後に掛け算を行うノードのペアに置き換えます。
Div(x, Sqrt(y)) \quad \Longrightarrow \quad Mul(x, Rsqrt(y))
RemoveRedundantReshape
冗長なReshapeノードを削除します。
Reshape(Reshape(x)) \quad \Longrightarrow \quad Reshape(x)
ReorderCastAndTranspose
転置処理で扱うデータ量を減らすため、Transposeノードの後にCastノードが実行されるように計算グラフを変形します。
sizeof(type1) < sizeof(type2)の時、
Transpose(Cast(x, type1, type2), perm) \quad \Longrightarrow \quad Cast(Transpose(x, perm), type1, type2)
7. Dependency Optimizer
ソースコード:tensorflow/core/grappler/optimizers/dependency_optimizer.cc
計算グラフの実行順序を制御するために、NoOpノードやIdentityノードなどに接続されてているControl Edge 1 を付け替えて、可能な限りノード間の依存性を減らします。
これにより、依存関係が存在することで最適化できなかったノードが、最適化可能になる可能性があります。
なお、NoOpノードは入出力にテンソルデータを伴わない場合で、かつ計算グラフの実行順序を制御するときに作られ、Identityノードは入出力にテンソルデータを伴う場合で、かつ計算グラフの実行順序を制御するときに作られます。
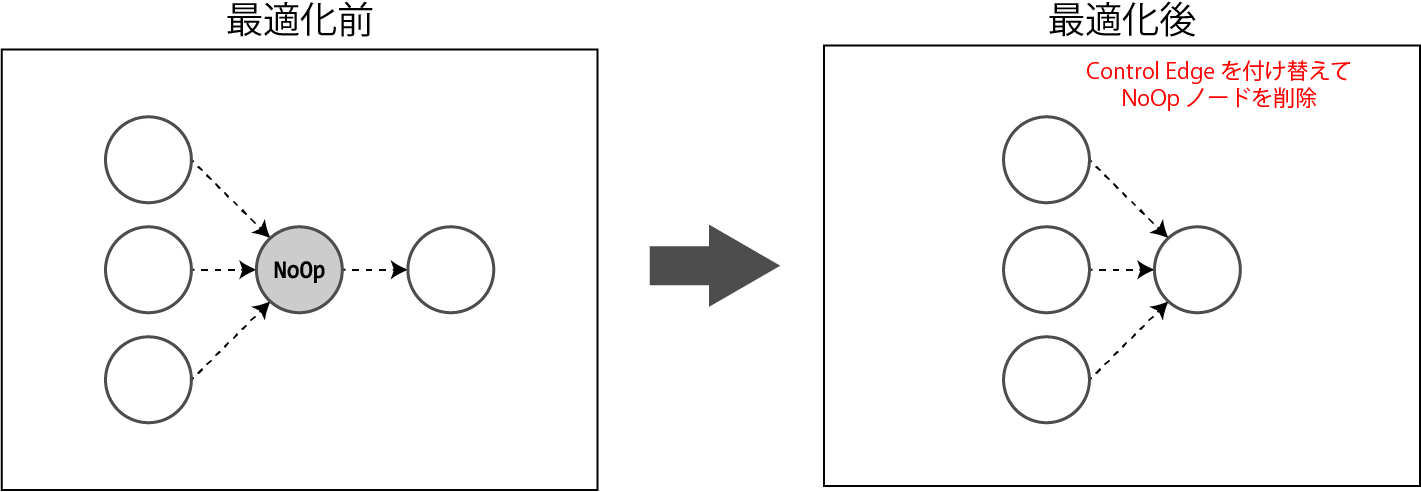
NoOpノードの最適化
NoOpノードに接続されているControl Edgeの入出力数について、「入力数×出力数 <= 入力数+出力数」が成り立つとき、Control Edgeを付け替えることによって、NoOpノードを削除します。
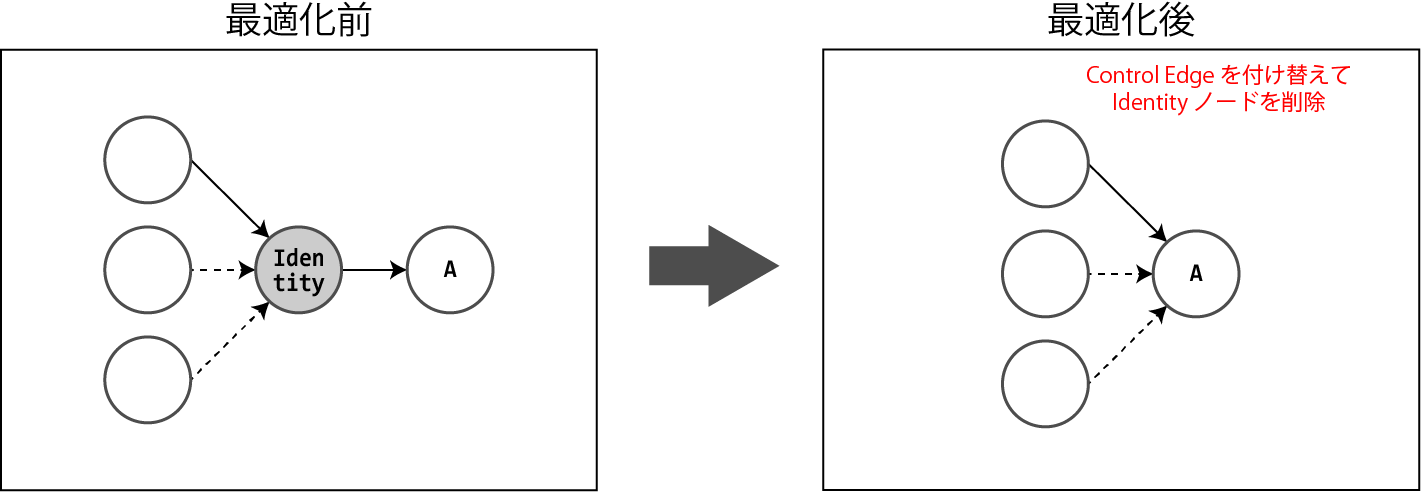
Identityノードの最適化
Control Edgeを付け替えることによってIdentityノードを削除します。
ただし、デバイス間でのデータ転送は重い処理であるため、Control Edgeの付け替えによってデバイスを跨ぐControl Edgeが増えてしまう場合は、本最適化は行われません。
8. Loop Optimizer
ソースコード:tensorflow/core/grappler/optimizers/loop_optimizer.cc
Loop Optimizerは以下の最適化を行うことにより、ループ構造を持つ計算グラフを最適化します。
- DeadBranchRemoval
- StackPushRemoval
- LoopInvariantNodeMotion
DeadBranchRemoval
分岐(Switchノード)が含まれる計算グラフにおいて、分岐先が確定している場合は、Switchノードを削除して確定している分岐先のノード群を残すように、計算グラフを変形します。
CondOpの結果がTrueであることが確定しているとき、
switch(CondOp(), TrueOp(), FalseOp()) \quad \Longrightarrow \quad TrueOp()
LoopInvariantNodeMotion
ループ処理内で値が変わらないノードを、ループ外に移動させます。
以下は最適化前のノード構成です。
while_loop {
InvariantOp()
...
}
最適化後、値不変のノード InvariantOp はループ処理である while_loop の外に移動しています。
InvariantOp()
while_loop {
...
}
StackPushRemoval
StackPushノードに対応するStackPopノードが存在しない場合は、StackPushノードをIdentityノードに変更します。
Stack() + StackPush() \quad \Longrightarrow \quad Stack() + Identity()
9. Function Optimizer
ソースコード:tensorflow/core/grappler/optimizers/function_optimizer.cc
ユーザが定義したサブグラフ(tf.Defun を使ってユーザ定義したFunction)をインライン展開することにより、サブグラフの呼び出しコストを削減します。
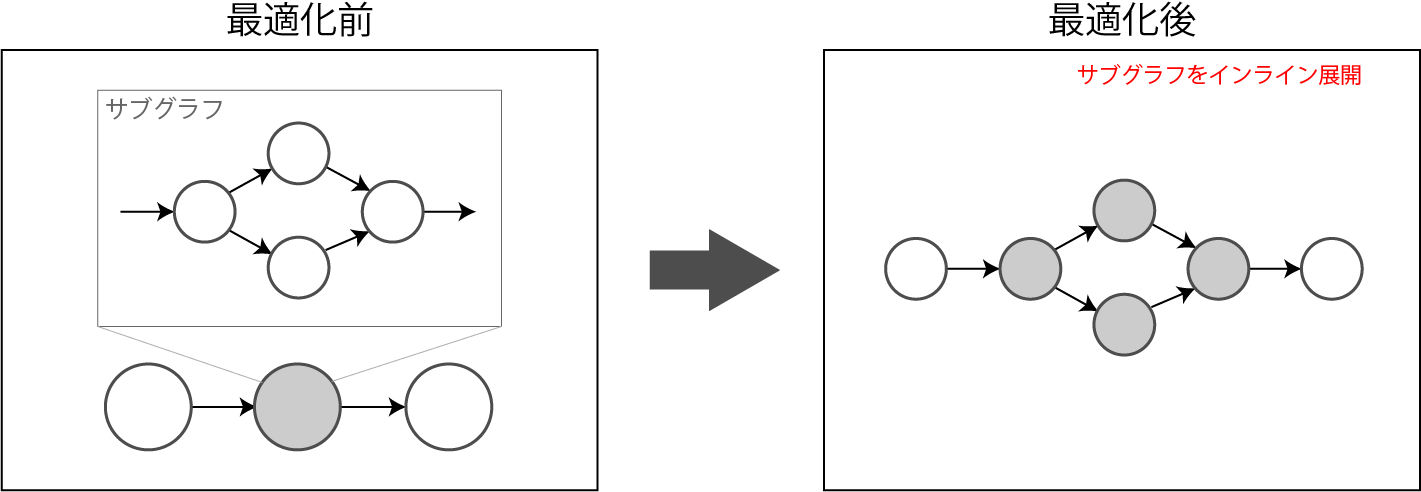
10. Debug Stripper
ソースコード:tensorflow/core/grappler/optimizers/debug_stripper.cc
演算の結果に直接関係のないノードを、NoOpノードかIdentityノードに置き換えます。
例えば、以下のような置き換えを行います。
| 置き換え前 | 置き換え後 |
|---|---|
| Assert | NoOp |
| CheckNumerics | Identity |
| Identity |
11. Shape Optimizer
ソースコード:tensorflow/core/grappler/optimizers/shape_optimizer.cc
テンソルの形状に関する演算を最適化します。
テンソル要素数の算出
テンソルの要素数を求める時に、テンソルのShapeの要素を掛け算して要素数を求める代わりに、テンソルの要素数をそのまま返します。
Prod(Shape(x)) \quad \Longrightarrow \quad Size(x)
テンソルのSize同士の割り算の定数化
テンソルのSize同士で割り算を行う場合、事前に演算して Const ノードに置き換えることで演算を省略します。
Div(Size(x), Size(y)) \quad \Longrightarrow \quad Const()
12. Remapper
ソースコード:tensorflow/core/grappler/optimizers/remapper.cc
演算を結合/分解し、演算の呼び出しコストを削減します。
サポートしている演算の結合/分解パターンを以下に示します。
| 元のOperation群 | 変換後のOperation群 |
|---|---|
| FusedBatchNorm | Add×2 + Rsqrt + Mul×3 + Sub |
| Conv2D + BiasAdd | _FusedConv2D(kBiasAdd) |
| COnv2D + BiasAdd + ReLU | _FusedConv2D(kBiasAddWithRelu) |
| Conv2D + FusedBatchNorm | _FusedConv2D(kFusedBatchNorm) |
| Conv2D + FusedBatchNorm + ReLU | _FusedConv2D(kFusedBatchNormWithRelu) |
| Conv2D + Squeeze + BiasAdd | _FusedConv2D(kBiasAdd) + Squeeze |
演算を結合することにより、演算カーネル(OpKernel)の呼び出し回数を減らすことができるため、結合前と比較して演算効率を高めることができます。
また推論時に限って言えば、FusedBatchNormの入力は定数になるため、よりPrimitiveなOperationに分解することで、Constant Foldingなどの最適化処理を適用することができるようになります。
13. Scoped Allocator Optimizer
ソースコード:tensorflow/core/grappler/optimizers/scoped_allocator_optimizer.cc
TensorFlowは、ノードを実行するたびに必要なメモリを確保し、不要になったメモリを開放するという処理を繰り返すことで、可能な限りピークメモリ量を減らすような動作をします。
しかし、メモリの確保&解放処理は重い処理です。
このため、Scoped Allocator Optimizerでは、最初に1つの巨大なテンソルを作ってメモリを割り当てておき、ノードごとに必要なメモリ領域を切り出して利用することで、ノード間でのメモリ確保&解放処理の時間を削減します。
14. Pin to Host Optimizer
ソースコード:tensorflow/core/grappler/optimizers/pin_to_host_optimizer.cc
以下の条件に当てはまる場合に、演算をホスト側(CPU側)で実行するようにします。
- TPU向けのOperationが含まれていない
- Collective Ops(
CollectiveReduce,CollectiveBcastSend,CollectiveBcastRecvのいずれか)、Control Flow Ops、NoOpではない - ホスト側で実行可能である(ホスト側のOpKernelが存在する)
- 入出力のテンソルサイズが小さく、データ型がint32かint64で、かつホストメモリ上に存在する

Grapplerによる最適化の有効・無効化
Grapplerによる計算グラフの最適化は、tensorflow/core/protobuf/rewriter_config.proto でProtocol Buffers形式により定義された RewriterConfig を使って、ユーザが明示的に有効・無効を指定することができます。
例えば以下は、デフォルトで有効化されているConstant Foldingの最適化を、Pythonプログラムから無効化するためのソースコードです。
import tensorflow as tf
from tensorflow.core.protobuf import config_pb2
from tensorflow.core.protobuf import rewriter_config_pb2
# Constant Foldingを無効化
cfg = config_pb2.ConfigProto()
cfg.graph_options.rewrite_options.constant_folding = rewriter_config_pb2.RewriterConfig.OFF
# 計算グラフ構築
# ...
# 計算グラフ実行
with tf.Session(config=cfg) as sess:
sess.run(...)
また同様に、デフォルトで無効化されているDebug Stripperを有効化したい場合は、以下のようにして有効化することができます。
import tensorflow as tf
from tensorflow.core.protobuf import config_pb2
from tensorflow.core.protobuf import rewriter_config_pb2
# Debug Stripperを有効化
cfg = config_pb2.ConfigProto()
cfg.graph_options.rewrite_options.debug_stripper = rewriter_config_pb2.RewriterConfig.ON
# 計算グラフ構築
# ...
# 計算グラフ実行
with tf.Session(config=cfg) as sess:
sess.run(...)
-
ノード間のテンソルのデータ移動を伴わないエッジです。このため、Control Edgeは実行順序を制御するために利用されます。 ↩