NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 の nttd-nagano です。
12月13日の記事 で、Informatica社 のオールインワンのクラウドデータマネージメントプラットフォーム「Intelligent Data Management Cloud」(※1)をご紹介しましたが、今回はこの IDMCのデータ統合サービス「Cloud Data Integration」(※2)の機能「インテリジェント構造検出」(Intelligent Structure Discovery)にて、 Kaggle で入手したネストされたJSONファイルを解析してみました ので、ご報告します。
※1. Intelligent Data Management Cloud
略称はIDMC。旧称はIICS。クラウドデータマネジメントプラットフォーム。以下IDMCと記載。※2. Cloud Data Integration
略称はCDI。データ統合サービス。ETL処理(※3)やELT処理(※4)を担う。以下CDIと記載。※3. ETL処理
データベースなどに蓄積されたデータから必要なものを抽出(Extract)し、目的に応じて変換(Transform)し、データを必要とするシステムに格納(Load)すること。※4. ELT処理
ETL処理(※3)と対比して使われることが多い言葉。データ統合処理の順序を従来型のE→T→Lの順ではなく、E→L→Tの順でおこなう。近年ではDBMSの性能が爆発的に向上したことから、その性能を有効活用するために使われる手法。近年、検索のしやすさから構造化ログ(Structured Logging)が注目されており、AWS CloudWatch Logs Insightなども構造化ログに対する検索に対応しています。構造化ログの中でも多いのがJSON形式です。
このように、JSONファイルはさまざまな所で使われています。
さて、社内で活用できるデータはないかと探し回って見つけたデータがJSONファイルで、なおかつそれがネストされたJSONファイルであった場合、 JSONスキーマなどの事前情報がすぐには分からない状況だと、階層構造を人力で解析していく必要があって、結構面倒ですよね。 そんなときに使えるのが、IDMCの 「インテリジェント構造検出」(Intelligent Structure Discovery)機能 です。
「データ連携」という文脈では、事前情報なしにJSONファイルを扱うということはないかと思いますが、このように データ分析者がセルフサービスでデータを見つけてきて、前処理としてその形を整えつつ分析環境に持ってきたいときなどは、役に立つ機能かと思います。
この機能は、JSONファイルの他に下記をサポートしています。
- テキストファイル(CSVファイルなどの区切りファイルや階層を含む複雑なファイルを含む)
- 機械生成されたファイル(Webログやクリックストリームなど)
- JSONファイル
- XMLファイル
- ORCファイル
- Avroファイル
- Parquetファイル
- Microsoft Excelファイル
- PDFフォームフィールド内のデータ
- Microsoft Wordテーブル内のデータ
- XSDファイル
- COBOLコピーブック
今回は、複雑にネストされたJSONファイルのサンプルとして、 Kaggle の「NY Philharmonic Performance History」を使います。
"NY Philharmonic Performance History" and its original "New York Philharmonic Performance History Metadata" by New York Philharmonic are licensed under CC0: Public Domain.
はじめに以降の手順の全体感をお伝えしておくと、
まず、「インテリジェント構造モデル」(Intelligent Structure Model)を作り、次に、そのモデルをマッピングの「構造パーサートランスフォーメーション」にて使う、という流れになります。
所要時間は、1時間ほどでした。今回はスクリーンショットを撮りつつでしたので1時間かかりましたが、実際はもっと手早く実施できるかと思います。
インテリジェント構造モデルを作る
まず、インテリジェント構造モデルを作っていきます。
IDMCにログインしたら、アプリケーションピッカーで「データ統合」をクリックします。
次に、左ペインにて「新規」をクリックします。
「新しいアセット」ダイアログで、「コンポーネント」>「インテリジェント構造モデル」をクリックし、「作成」ボタンをクリックします。

名前を入力し、「Choose File」の右側のファイルアイコンをクリックします。

ダイアログにて raw_nyc_phil.json を選択し、「開く」ボタンをクリックします。

「構造の検出」ボタンをクリックします。

検出処理が開始されます。
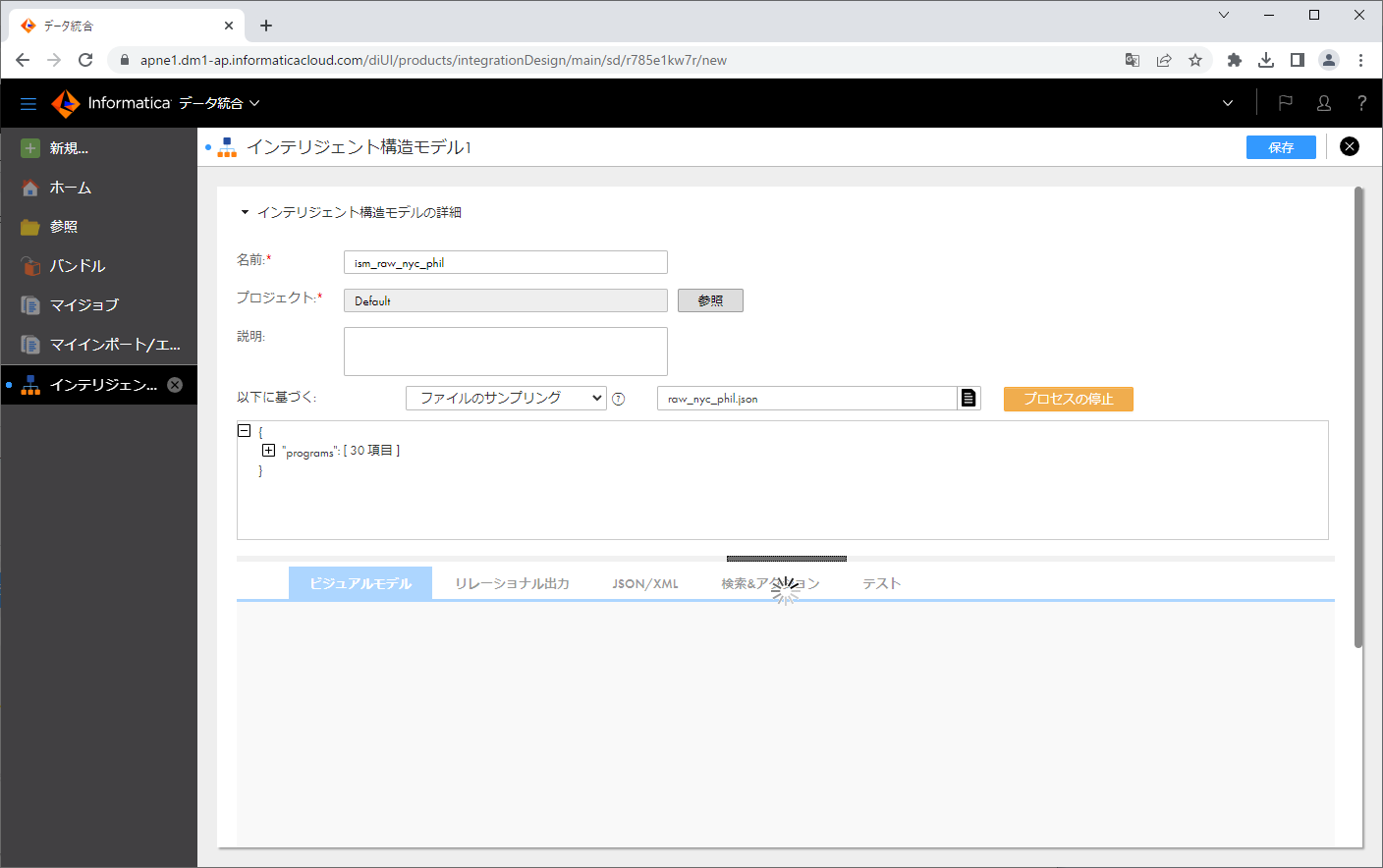
検出処理が終了すると、「ビジュアルモデル」タブに、結果が表示されます。
結果のツリーを見ると、今回のJSONファイルには、id2 ごとに複数の concerts と works がぶら下がっているような構造であることが分かりました。(id2 は本来JSONファイルの中では id ですが、ツリーの他の要素と名称が衝突していたため、CDIが自動的に連番を付与したようです)
以降では、この2つをそれぞれフラットファイルとして出力するようなマッピングを作成してみましょう。

「保存」ボタンをクリックします。

ちなみに、「リレーショナル出力」タブをクリックすると、モデルデータの表示方法を選択したり、モデルのデータ正規化モードを選択したり、モデル内の出力グループに対してアクションを実行したりすることができます。

Data Integration ServerのDTMのJavaヒープサイズを拡張する
さて、マッピングを作る前に、Secure AgentのData Integration ServerのDTMのJavaヒープサイズを拡張しておきましょう。
というのも、これから作るマッピングをデフォルトの状態で実行したところ、セッションログに下記のようなエラーが出力されたためです。
WRITER_1_*_1> WRT_8167 [2023-02-17 05:47:38.770] Start loading table [output_raw_nyc_phil_work_csv] at: Fri Feb 17 05:47:38 2023
WRITER_1_*_1> WRT_8167 [2023-02-17 05:47:38.870] Start loading table [output_raw_nyc_phil_concert_csv] at: Fri Feb 17 05:47:38 2023
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:47:43.258] Timestamp Event: [Fri Feb 17 05:47:43 2023]
TRANSF_1_1_1> STRUCTURE_PARSER_5 [2023-02-17 05:47:43.258] [ERROR] A Structure Parser runtime exception occurred : [Unknown error encountered in parsing]
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:47:43.260] Timestamp Event: [Fri Feb 17 05:47:43 2023]
TRANSF_1_1_1> STRUCTURE_PARSER_3 [2023-02-17 05:47:43.260] [ERROR] An error occurred while performing data conversion : [com.informatica.atlantic.api.AtlanticRuntimeException: Unknown error encountered in parsing
at com.informatica.atlantic.api.runtime.impl.AtlanticDefaultExecutor.internalParse(AtlanticDefaultExecutor.java:288)
【略】
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:47:43.260] Timestamp Event: [Fri Feb 17 05:47:43 2023]
TRANSF_1_1_1> TM_6085 [2023-02-17 05:47:43.260] A fatal error occurred at transformation [src_raw_nyc_phil], and the session is terminating.
前述のDTMとは、Data Transformation Managerの略で、これはETL/ELTの実際の処理(データを抽出し、変換し、ロードする)をおこなうデータ統合サービスのコンポーネントです。このDTMのJavaヒープサイズの最大値が、デフォルトの値では小さすぎて処理しきれないため、拡張しておきます。
拡張の方法は、「 FAQ:Informatica Intelligent Cloud Secure AgentのJavaヒープサイズと他のメモリ属性を増やすためのガイドラインとベストプラクティスについて 」に従って、操作していけば問題ありません。
まず、IDMCにログイン後、アプリケーションピッカーにて「管理者」をクリックします。
次に、左ペインにて「ランタイム環境」をクリックします。
Secure Agentをクリックします。

「編集」ボタンをクリックします。
「システム構成の詳細」パートを開き、「サービス」で「Data Integration Server」をクリックします。
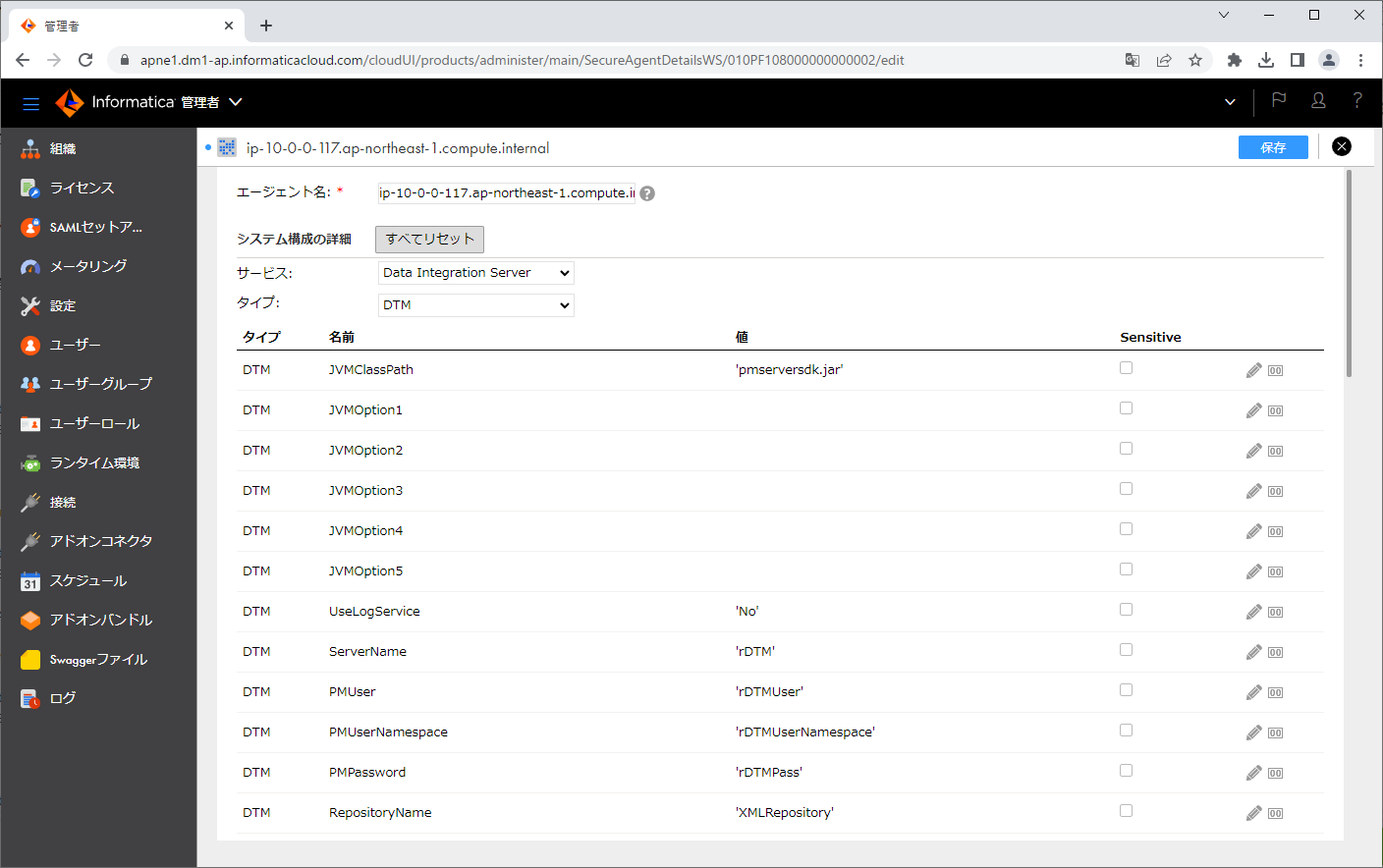
タイプが「DTM」である「JVMOption3」の値として、 -Xms1024m を指定します。
また、タイプが「DTM」である「JVMOption4」の値として、 -Xmx4096m を指定します。

「保存」ボタンをクリックします。

Secure Agentを再起動します。
フラットファイル接続を作る
フラットファイル接続を作っていきます。
まず、IDMCにログイン後、アプリケーションピッカーにて「管理者」をクリックします。
次に、左ペインにて「接続」をクリックします。
「新しい接続」ボタンをクリックします。

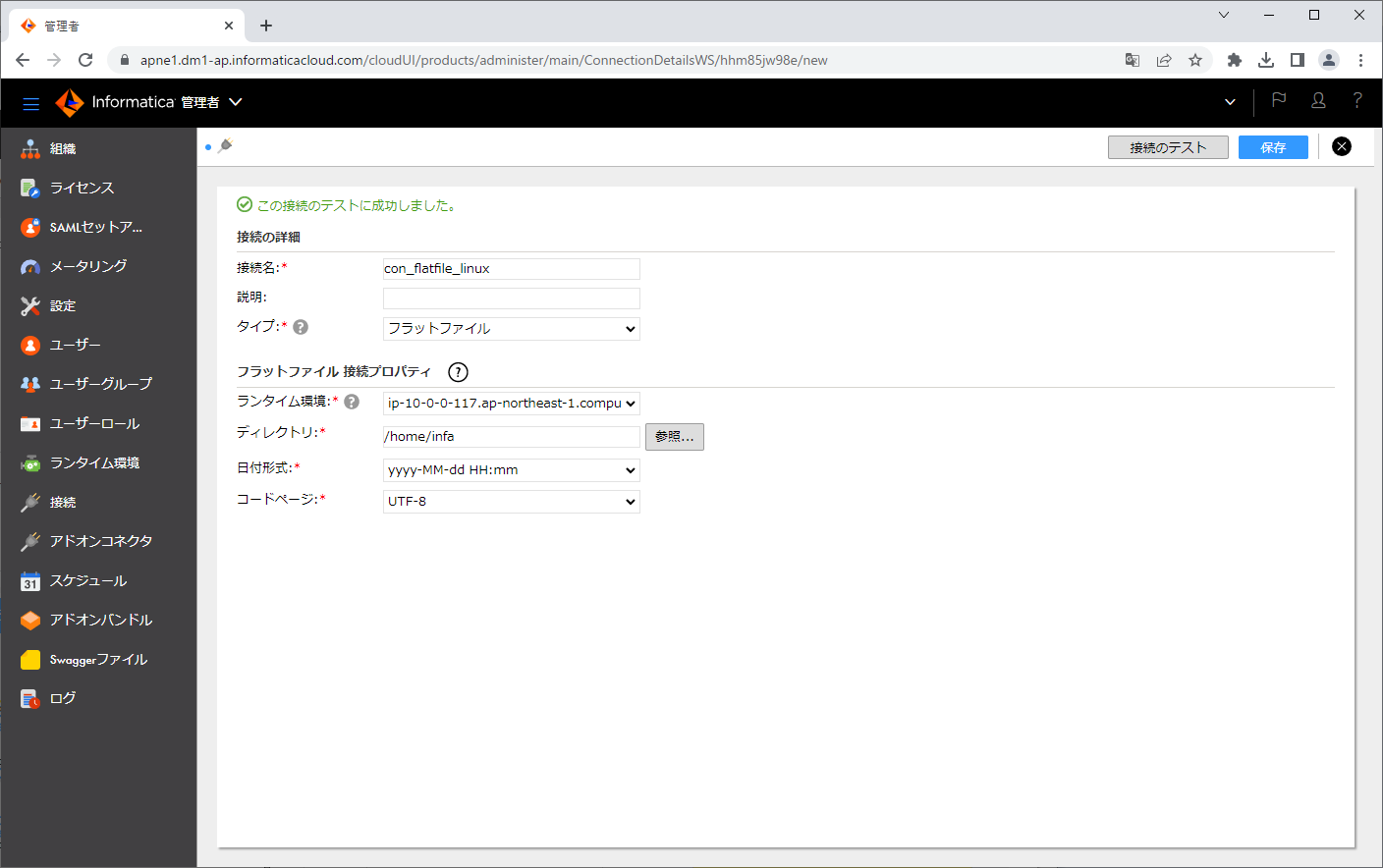
「接続名」「タイプ」「ディレクトリ」「日付形式」を入力し、「接続のテスト」ボタンをクリックします。
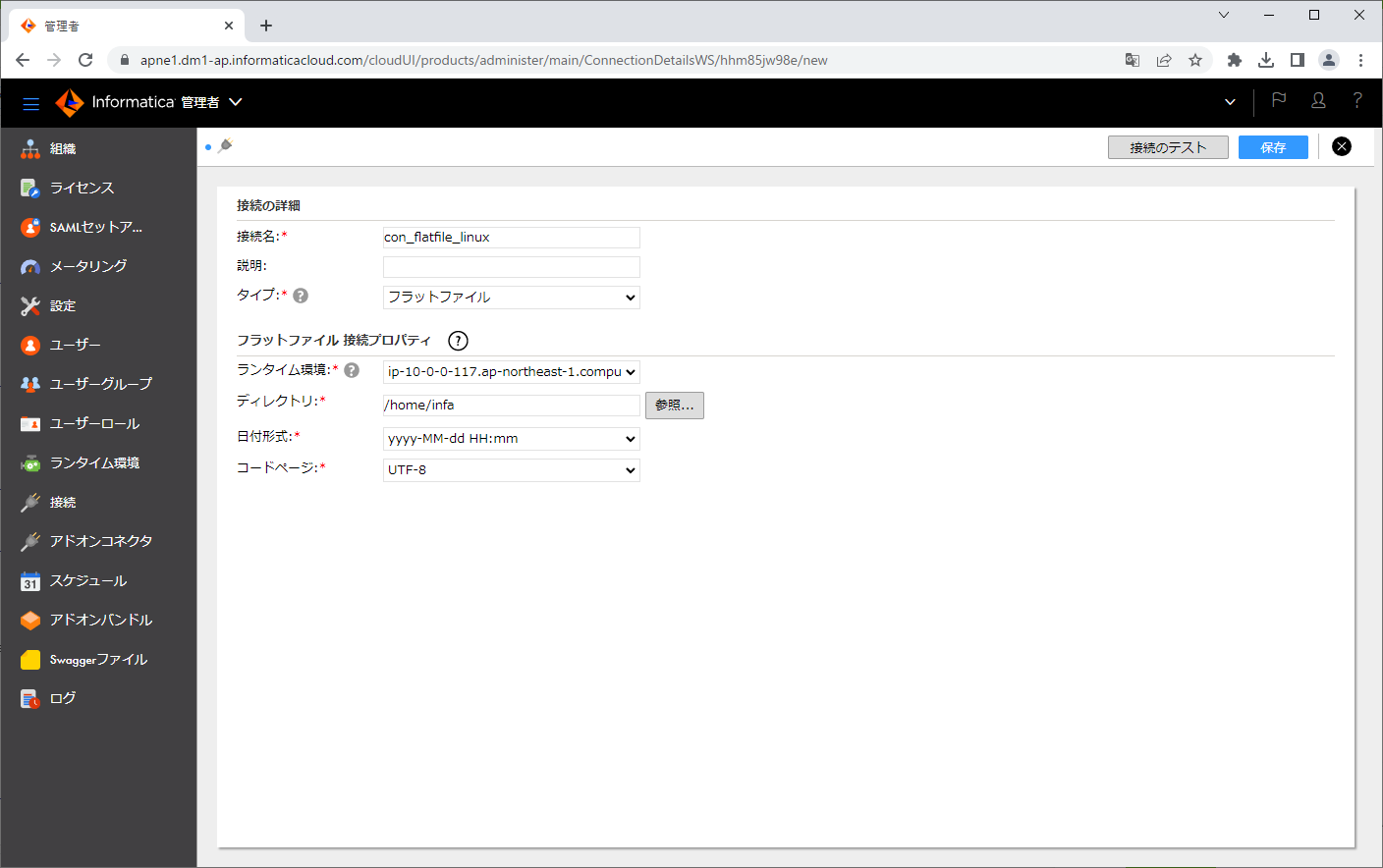
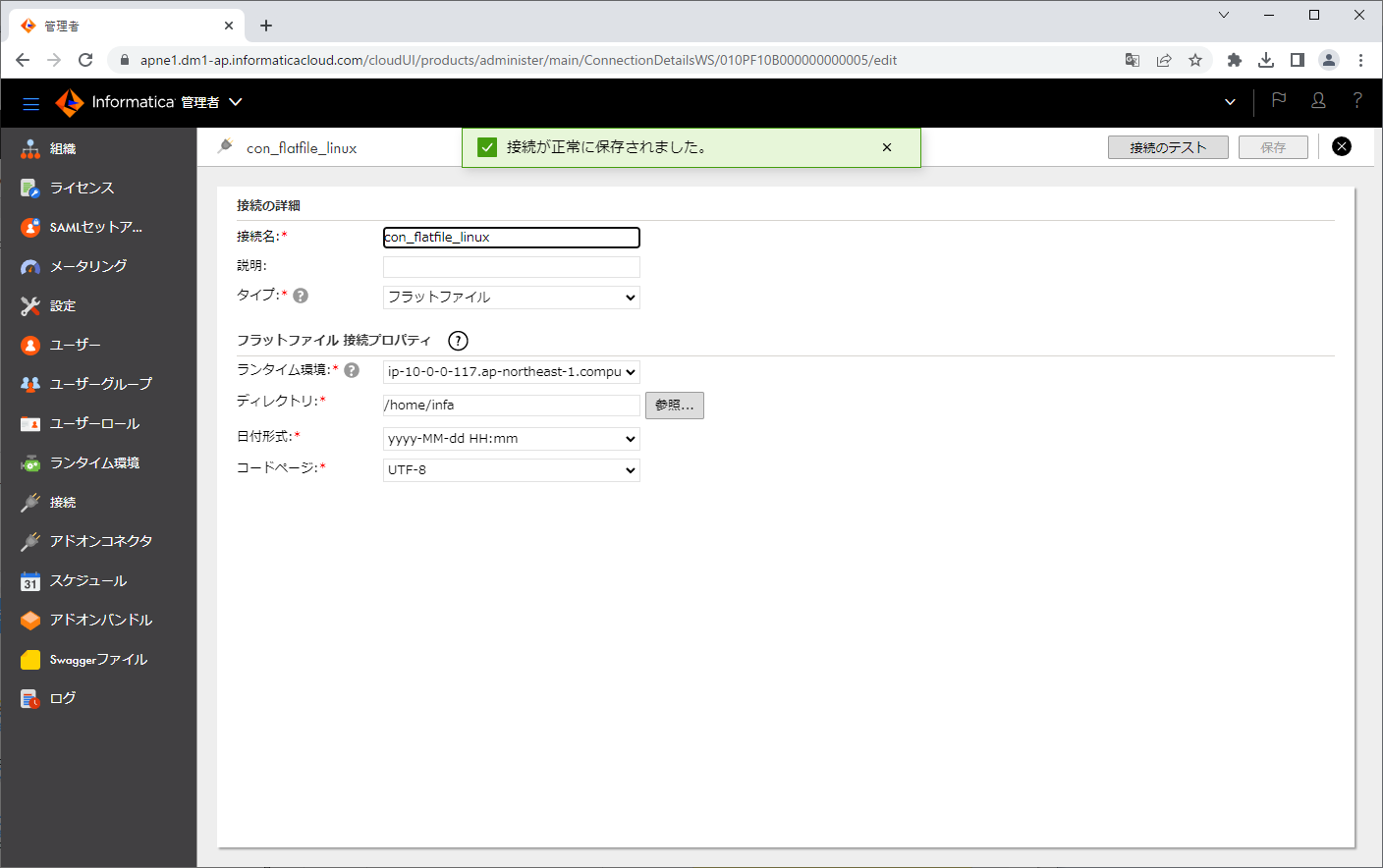
「保存」ボタンをクリックします。
入力ファイルを配置する
接続で設定したディレクトリに raw_nyc_phil.json を配置します。
このファイルは、マッピングの途中の「構造パーサートランスフォーメーション」で読むことになります。
一方、マッピングの先頭の「ソーストランスフォーメーション」では、このファイルのファイルパスを記載したファイルを読むことになります。そのため、下記のスクリーンショットのようにして、そのファイルを作ります。

マッピングを作る
マッピングを作っていきます。
まず、IDMCにログイン後、アプリケーションピッカーにて「データ統合」をクリックします。
次に、左ペインにて「新規」をクリックします。
「新しいアセット」ダイアログで、「マッピング」>「マッピング」をクリックし、「作成」ボタンをクリックします。
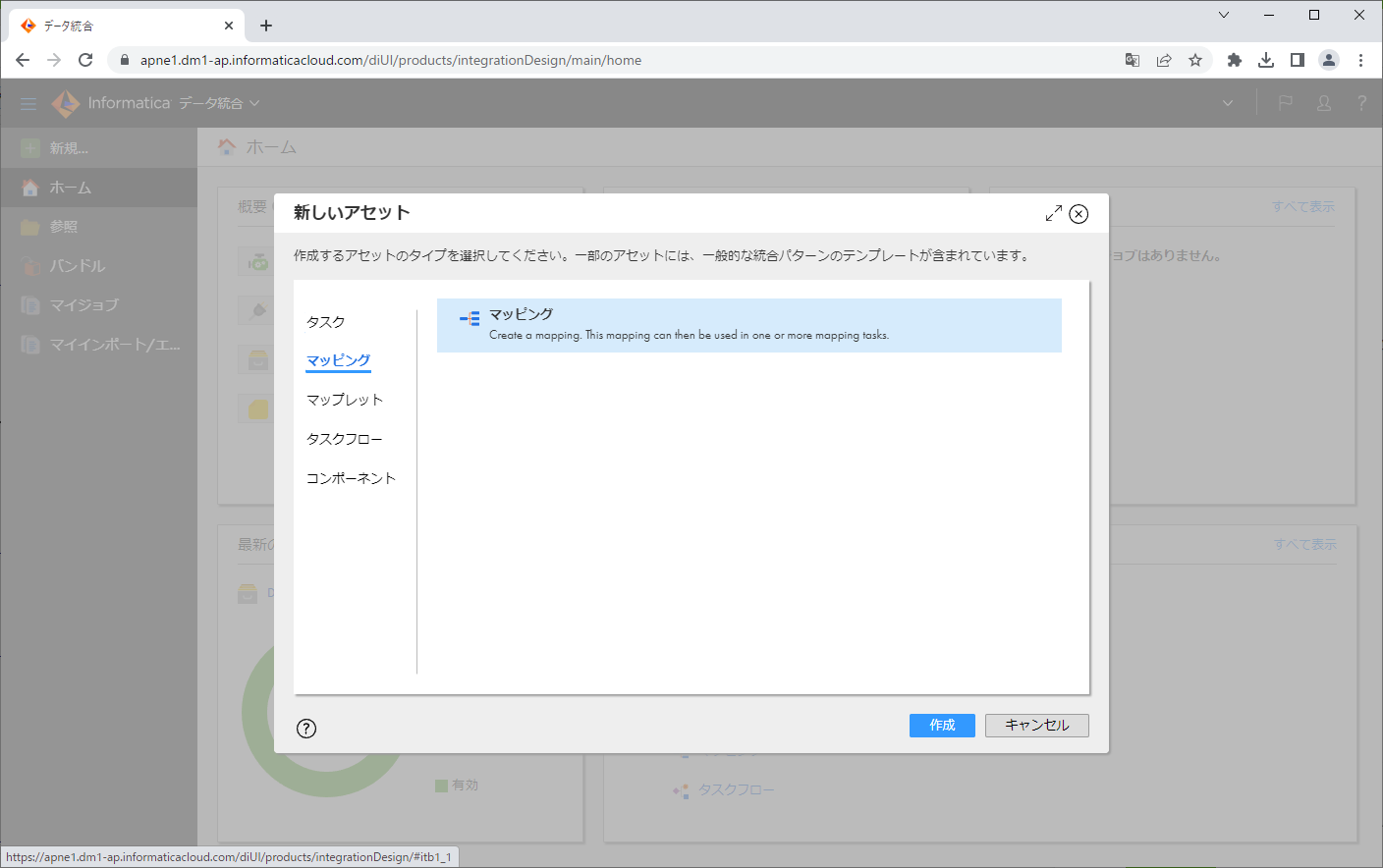
マッピングの「名前」を変更します。

ソーストランスフォーメーションを設定する
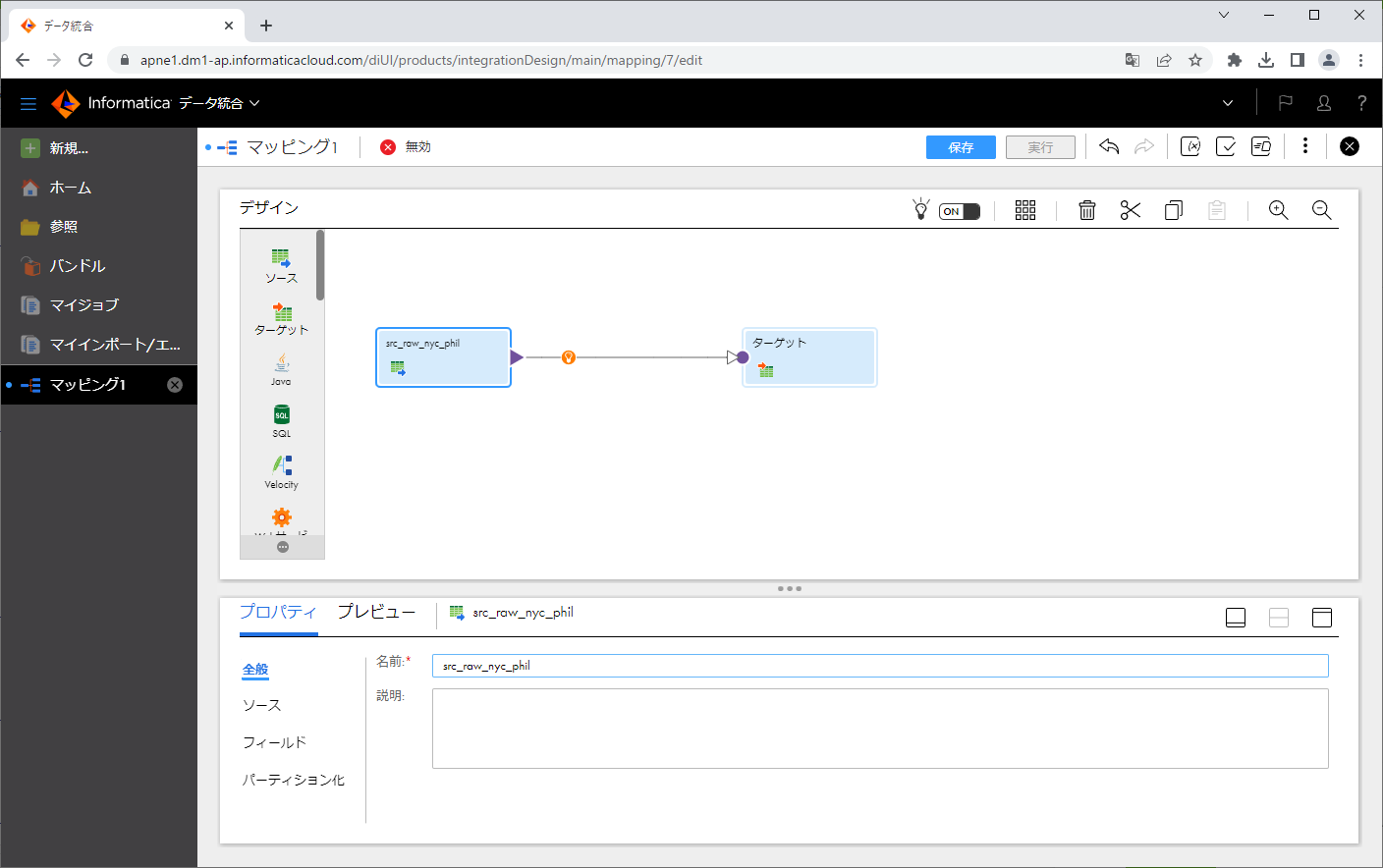
ソーストランスフォーメーションをクリックします。
ソーストランスフォーメーションの「名前」を変更します。
「ソース」タブをクリックします。
「接続」にて先ほど作ったフラットファイル接続を指定します。
「選択」ボタンをクリックします。
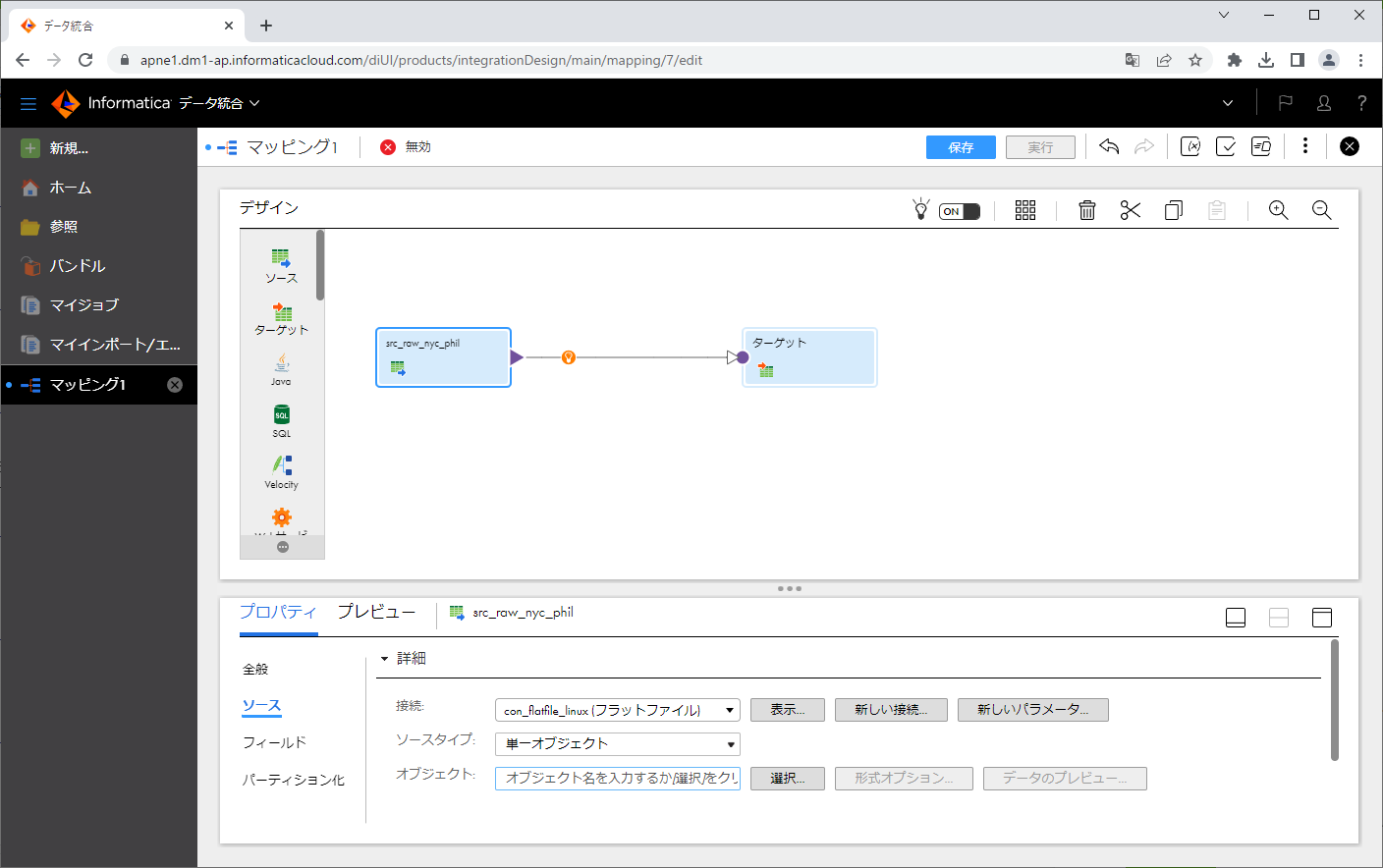
ダイアログにて、先ほど作ったファイルパスを記載したファイルを指定し、「OK」ボタンをクリックします。

指定したファイルが「オブジェクト」に表示されました。

構造パーサートランスフォーメーションを設定する
矢印部の「i」アイコンをクリックし、「構造パーサー」をクリックします。

構造パーサーの「名前」を変更します。
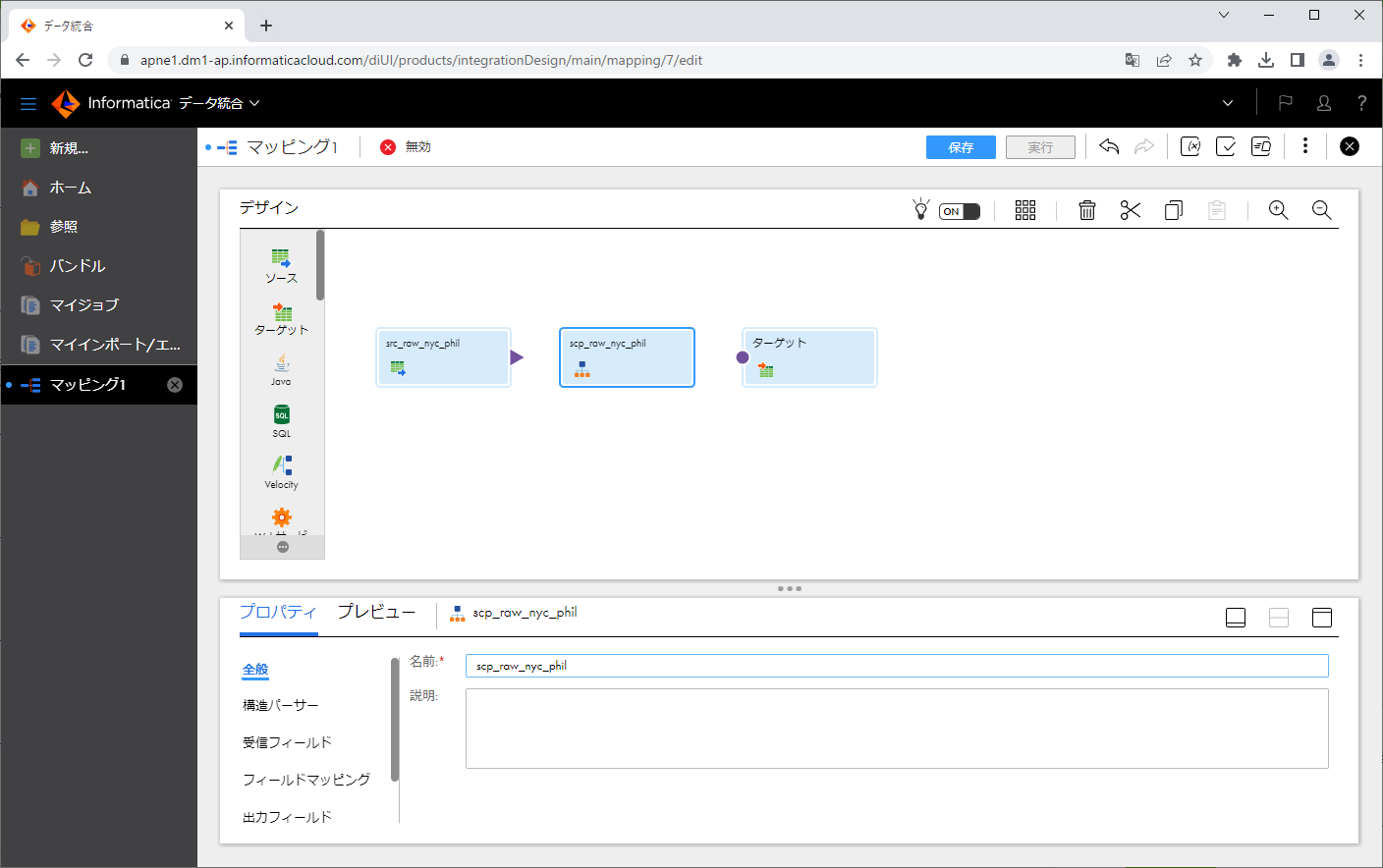
「構造パーサー」タブをクリックし、「インテリジェント構造モデル」の右の「選択」ボタンをクリックします。

先ほど作ったインテリジェント構造モデルを指定し、「選択」ボタンをクリックします。

指定したモデルが「インテリジェント構造モデル」に表示されました。
ソーストランスフォーメーションの出力側から構造パーサーの入力側に対して、ドラッグアンドドロップし、矢印を繋ぎます。

構造パーサーをクリックします。
「フィールドマッピング」タブをクリックし、「フィールドマップオプション」にて「自動」を選択します。
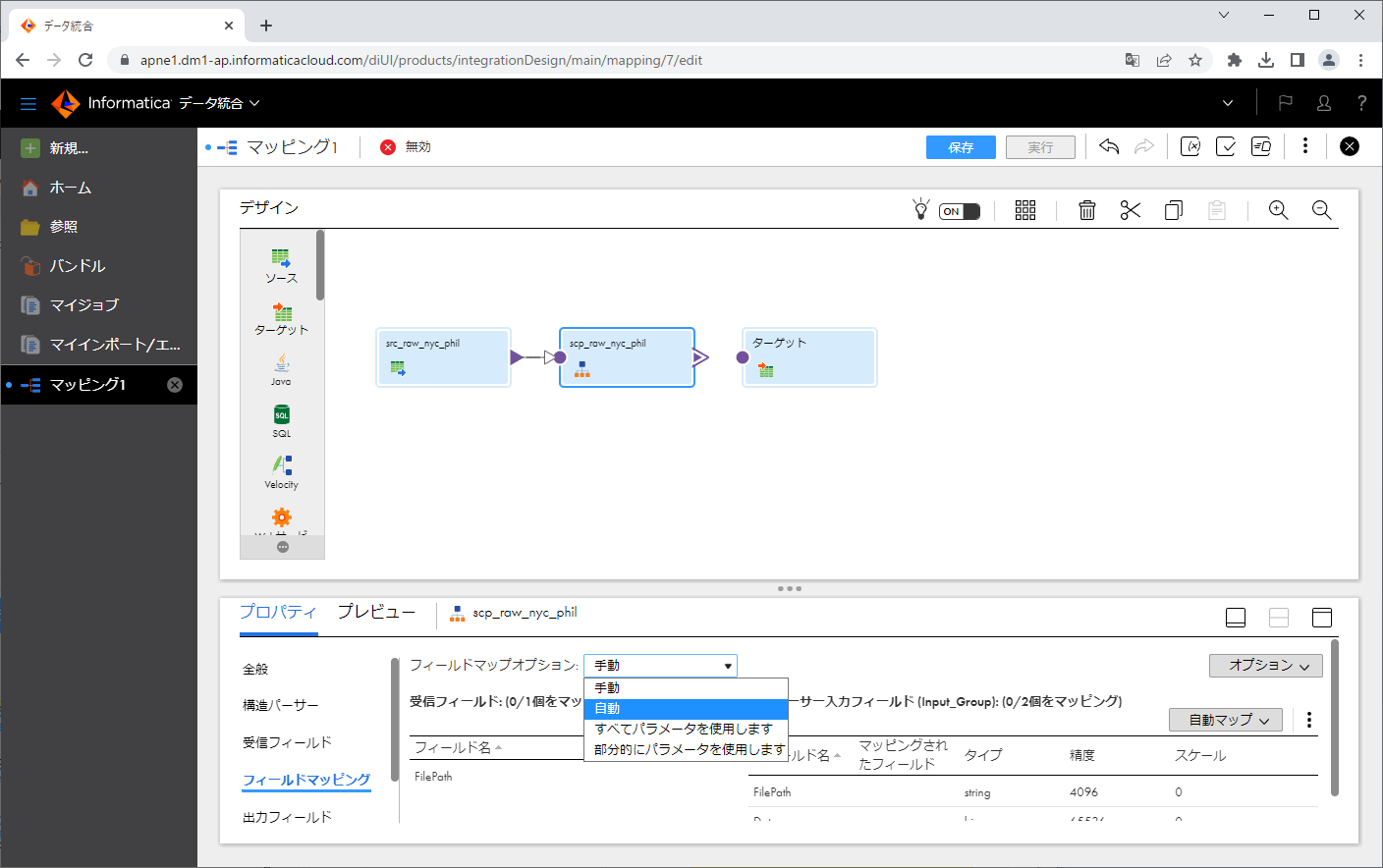
「受信フィールド」側の「フィールド名」が、「構造パーサー入力フィールド」の「マッピングされたフィールド」に転記されていることを確認します。

「出力フィールド」タブをクリックします。この中のconcertの配下とworkの配下に「id_FK2」というフィールド」があるのですが、現在この精度(桁数)が36になっているかと思います。これを拡張しておきましょう。
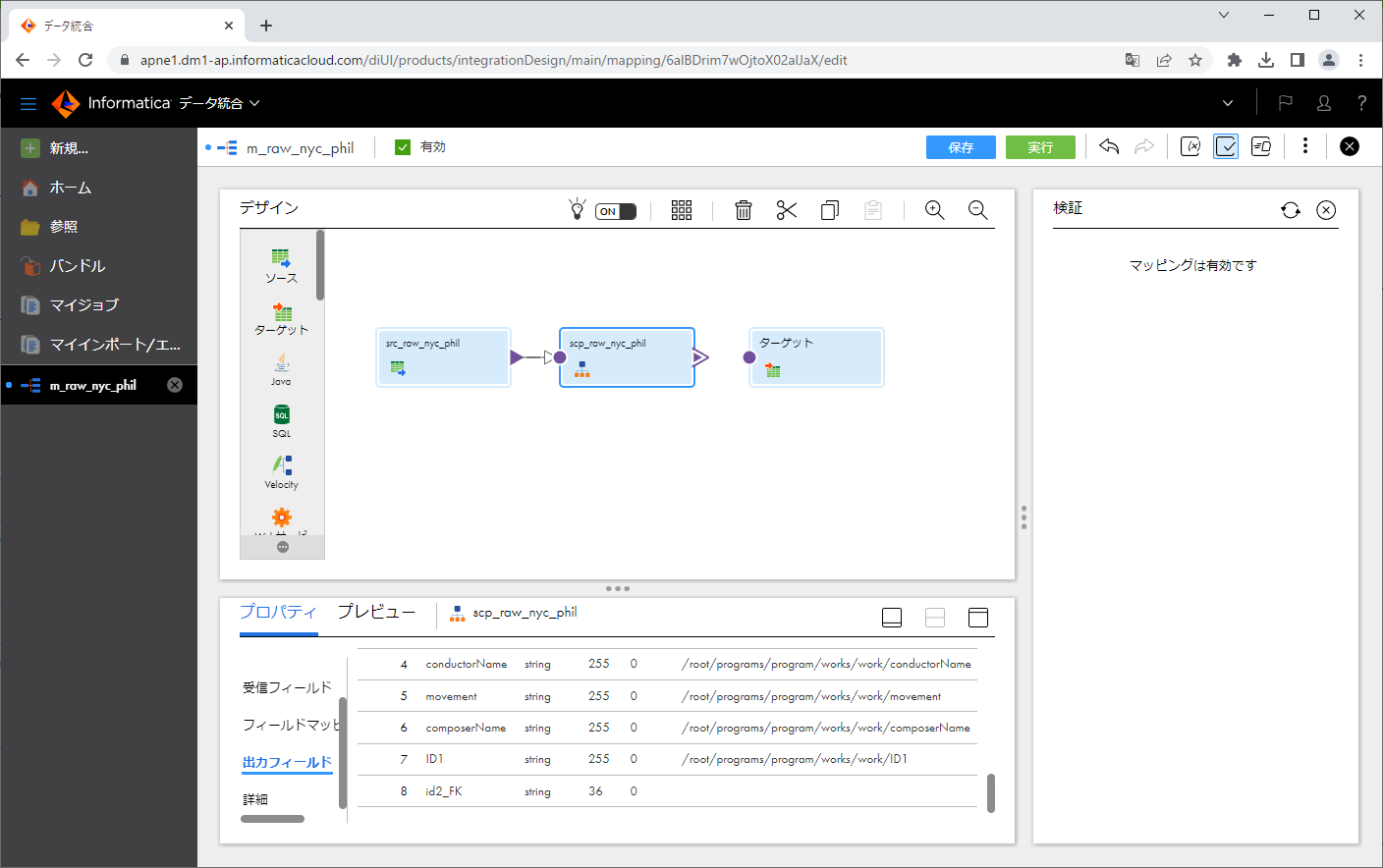
というのも、「精度」が36の状態で実行したところ、セッションログに下記のようなエラーが出力されたためです。
*****START LOAD SESSION*****
【略】
WRITER_1_*_1> WRT_8167 [2023-02-17 05:26:09.566] Start loading table [output_raw_nyc_phil_work_csv] at: Fri Feb 17 05:26:08 2023
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:26:09.578] Timestamp Event: [Fri Feb 17 05:26:09 2023]
TRANSF_1_1_1> STRUCTURE_PARSER_7 [2023-02-17 05:26:09.578] [ERROR] The output port data is truncated. To avoid truncation, in the Structure Parser transformation Output Fields tab increase the output port precision, then run the mapping.
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:26:09.578] Timestamp Event: [Fri Feb 17 05:26:09 2023]
TRANSF_1_1_1> JAVA PLUGIN_1762 [2023-02-17 05:26:09.578] [ERROR] com.informatica.powercenter.sdk.SDKException: com.informatica.powercenter.sdk.SDKException: com.informatica.cloud.api.adapter.runtime.exception.DataConversionException: failure on [id2_FK]:
Data Truncation occured
at com.informatica.isd.plugin.utils.SDOutputBuffer.setData(SDOutputBuffer.java:110)
【略】
TRANSF_1_1_1> CMN_1761 [2023-02-17 05:26:09.579] Timestamp Event: [Fri Feb 17 05:26:09 2023]
TRANSF_1_1_1> TM_6085 [2023-02-17 05:26:09.579] A fatal error occurred at transformation [src_raw_nyc_phil], and the session is terminating.
Informaticaソリューションでは一般的に文字列項目に対して「精度」という単語を使った場合は、「桁数」を意味します。
ここでは、「精度」を100に拡張しました。

ターゲットトランスフォーメーションを設定する (1/2)
ターゲットトランスフォーメーションをクリックします。
ターゲットランスフォーメーションの「名前」を変更します。
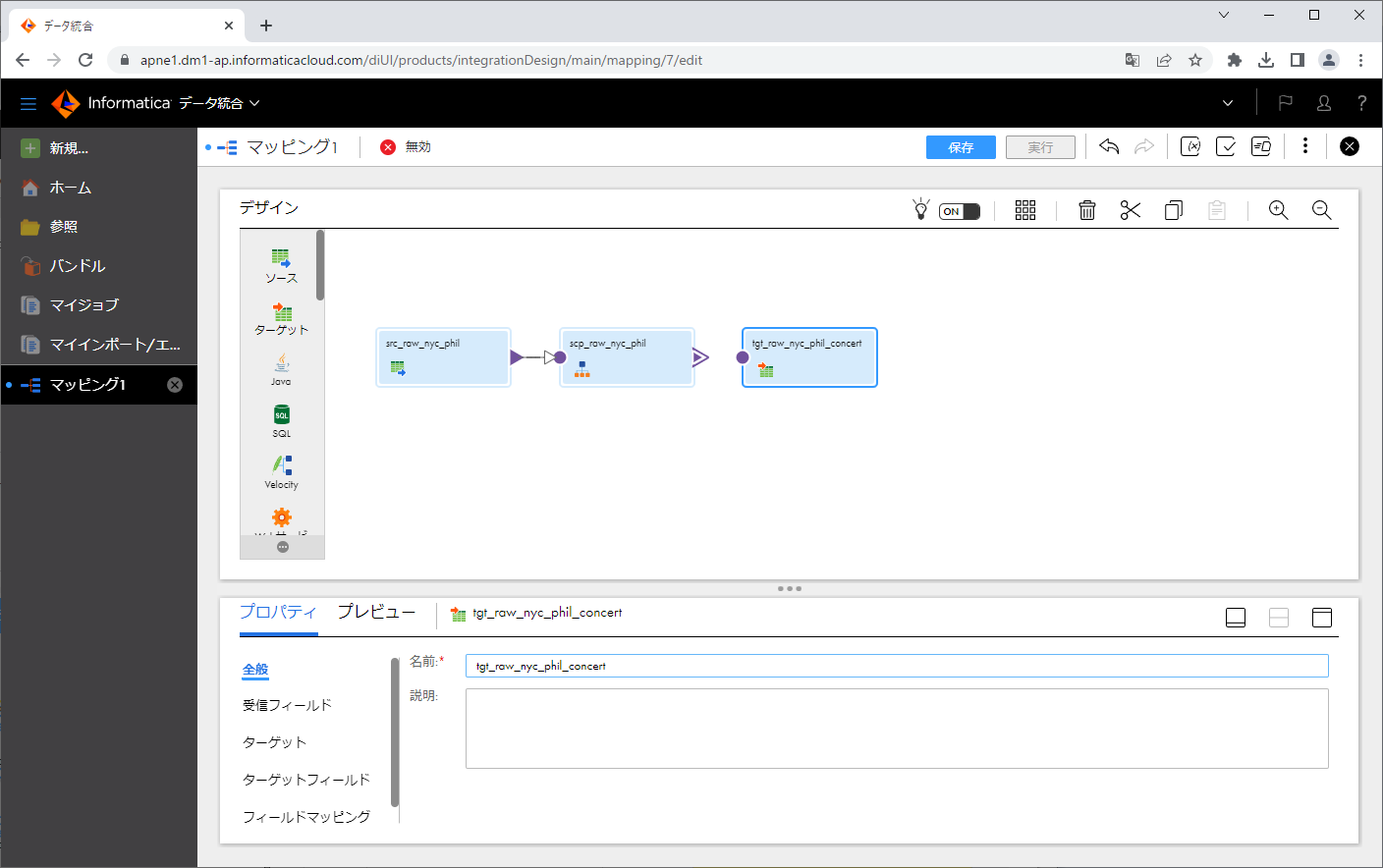
「ターゲット」タブをクリックします。
「接続」にて先ほど作ったフラットファイル接続を指定します。
「選択」ボタンをクリックします。

ダイアログの「ターゲットオブジェクト」にて、「実行時に新規作成」をクリックし、「静的ファイル名」に output_raw_nyc_phil_work.csv と入力し、「OK」ボタンをクリックします。

指定したファイルが「オブジェクト」に表示されました。
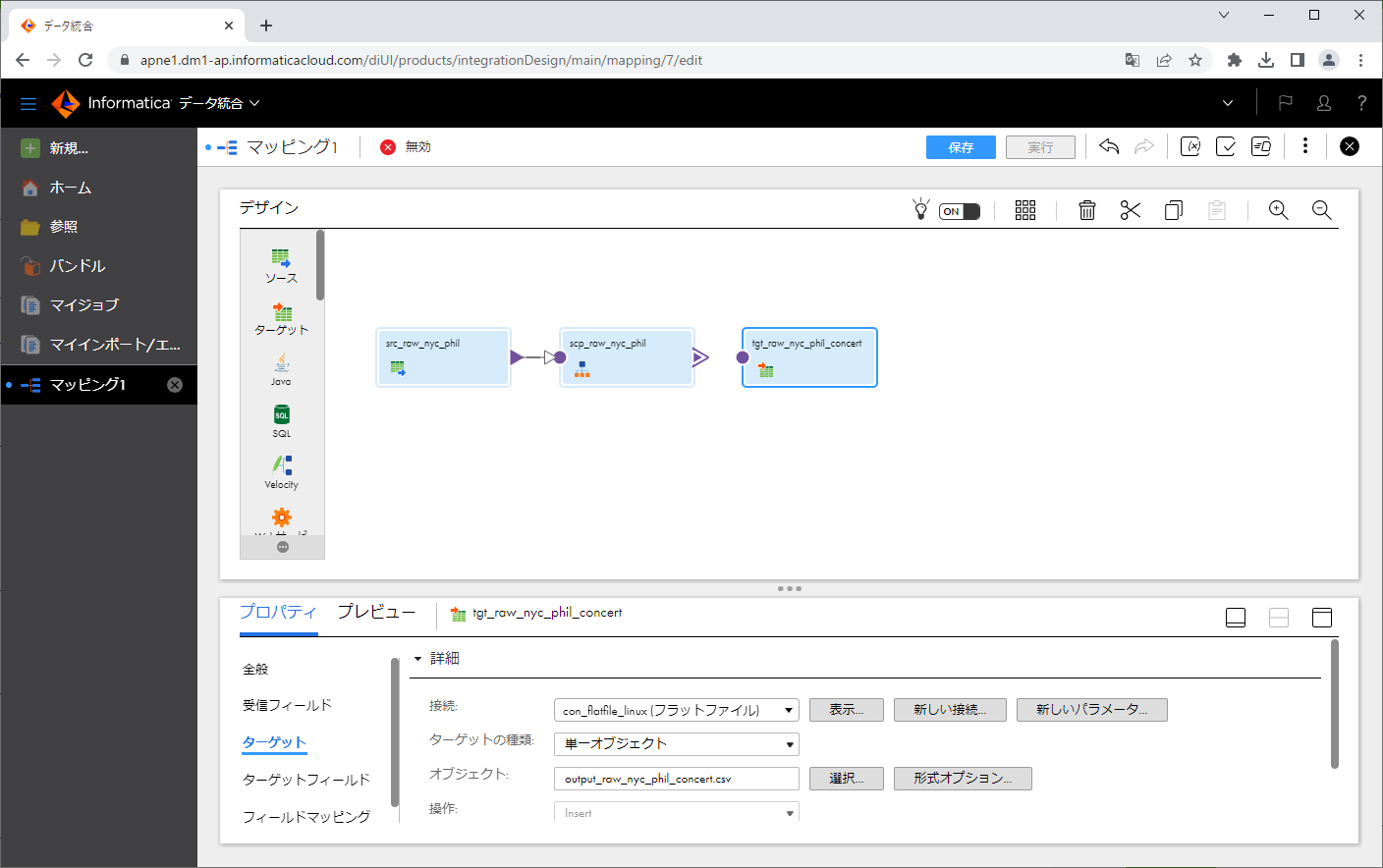
構造パーサーの出力側からターゲットトランスフォーメーションの入力側に対して、ドラッグアンドドロップし、矢印を繋ぎます。
ダイアログにて、 concert を選択し、「OK」ボタンをクリックします。

矢印が繋がりました。

ターゲットトランスフォーメーションを設定する (2/2)
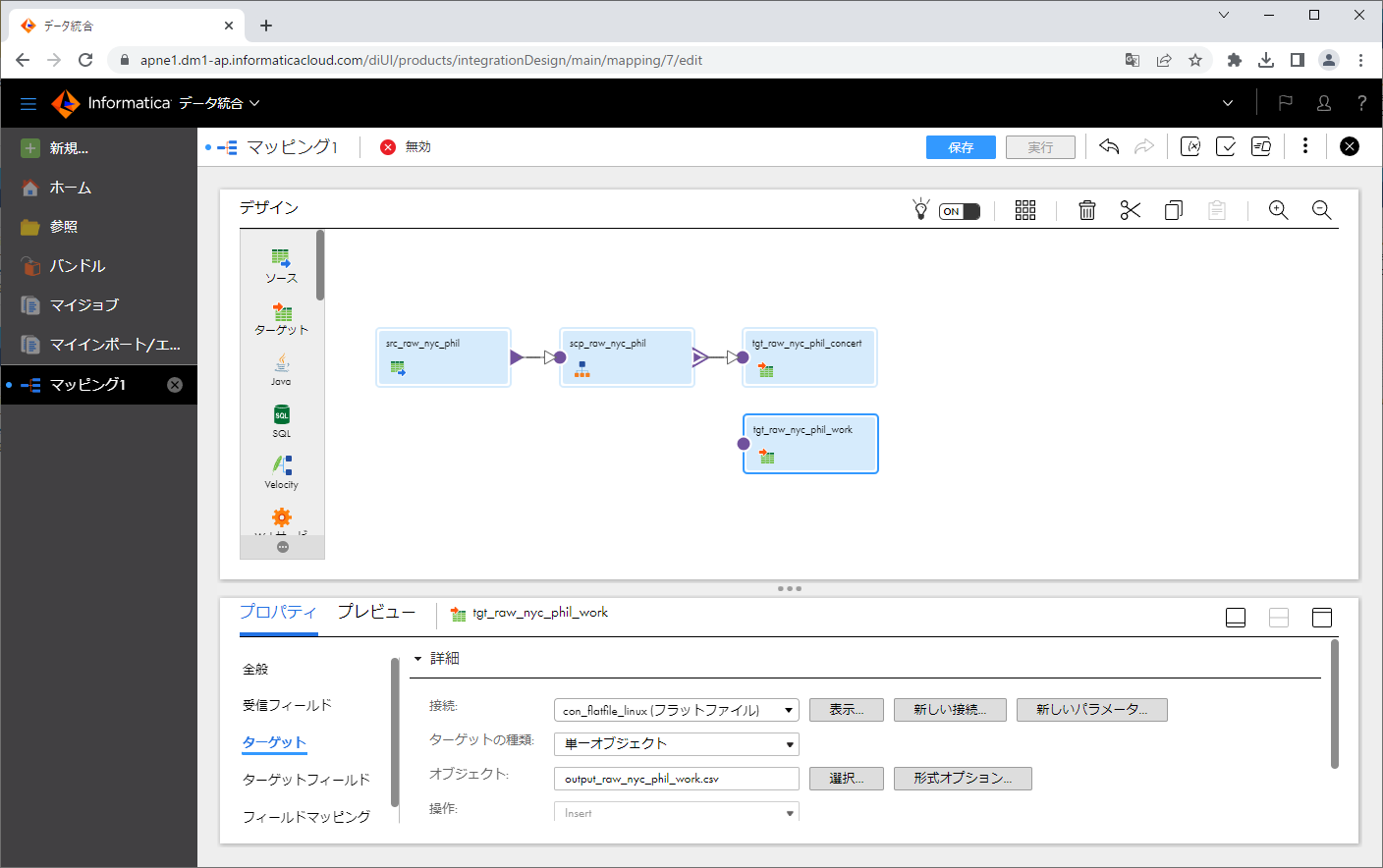
ターゲットトランスフォーメーションを新たに配置し、ターゲットトランスフォーメーションをクリックします。
ターゲットランスフォーメーションの「名前」を変更します。

「ターゲット」タブをクリックします。
「接続」にて先ほど作ったフラットファイル接続を指定します。
「選択」ボタンをクリックします。

ダイアログの「ターゲットオブジェクト」にて、「実行時に新規作成」をクリックし、「静的ファイル名」に output_raw_nyc_phil_work.csv と入力し、「OK」ボタンをクリックします。

指定したファイルが「オブジェクト」に表示されました。
構造パーサーの出力側からターゲットトランスフォーメーションの入力側に対して、ドラッグアンドドロップし、矢印を繋ぎます。
ダイアログにて、 work を選択し、「OK」ボタンをクリックします。
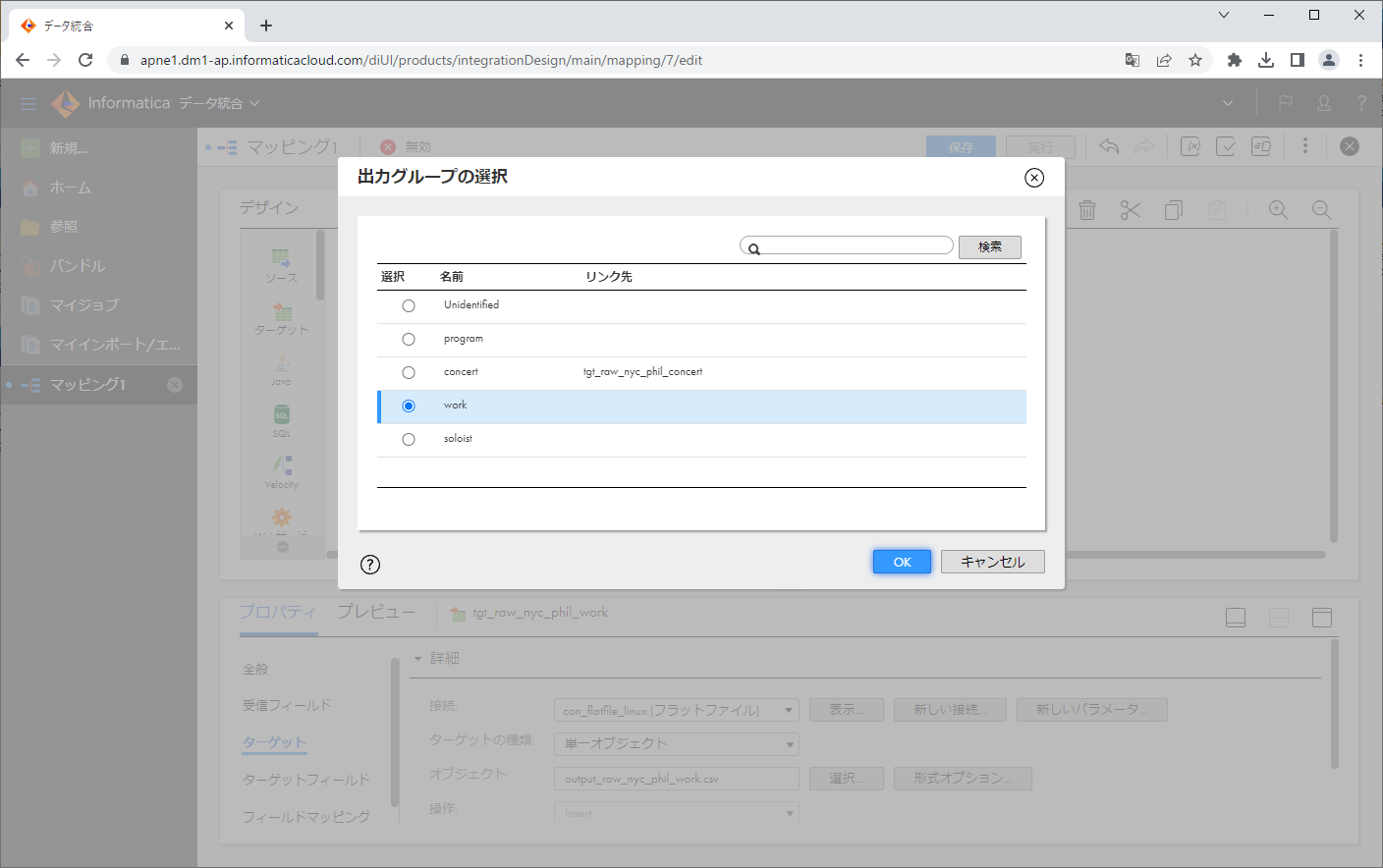
矢印が繋がりました。

検証して保存する
「検証」アイコンをクリックします。
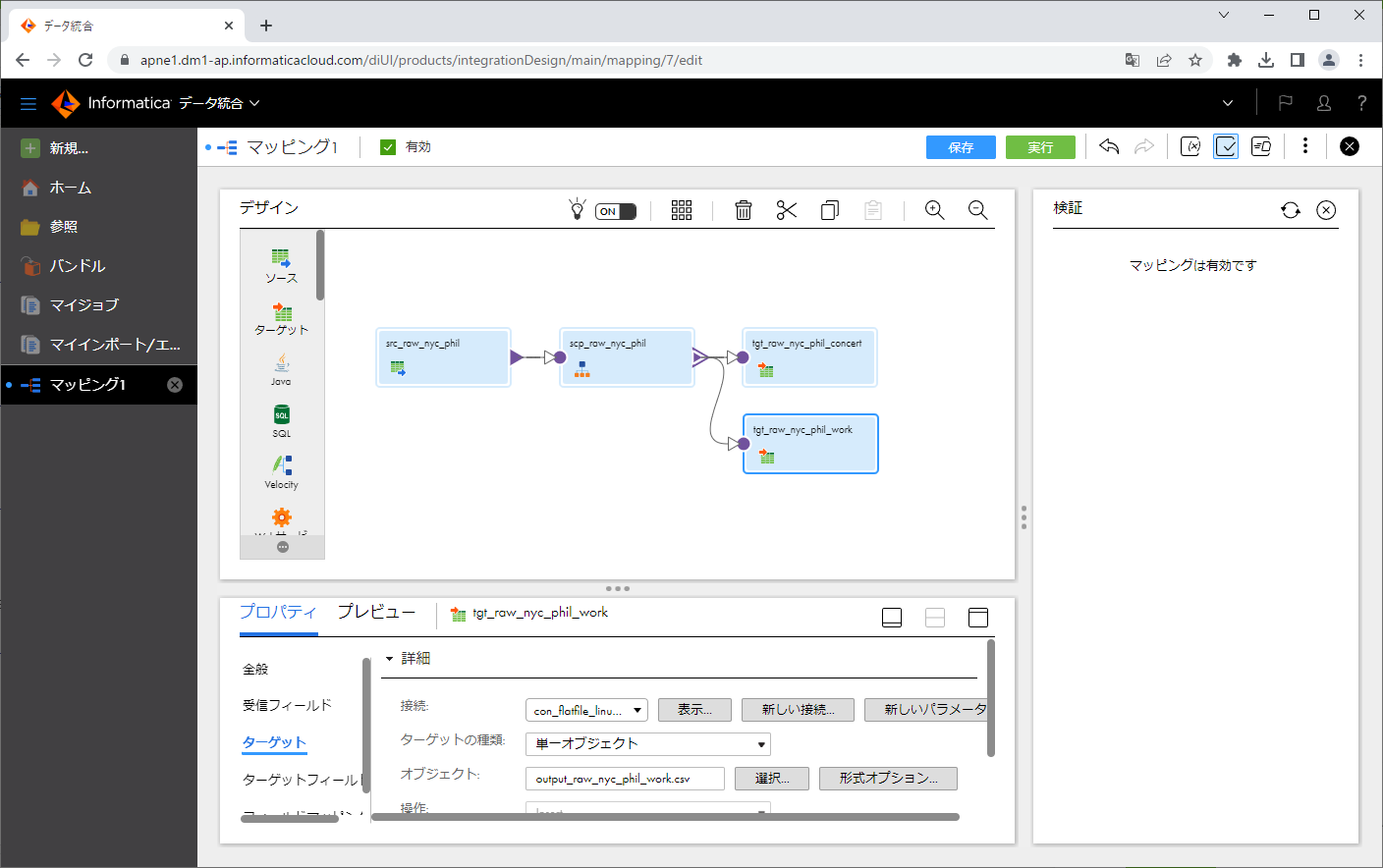
「保存」ボタンをクリックします。
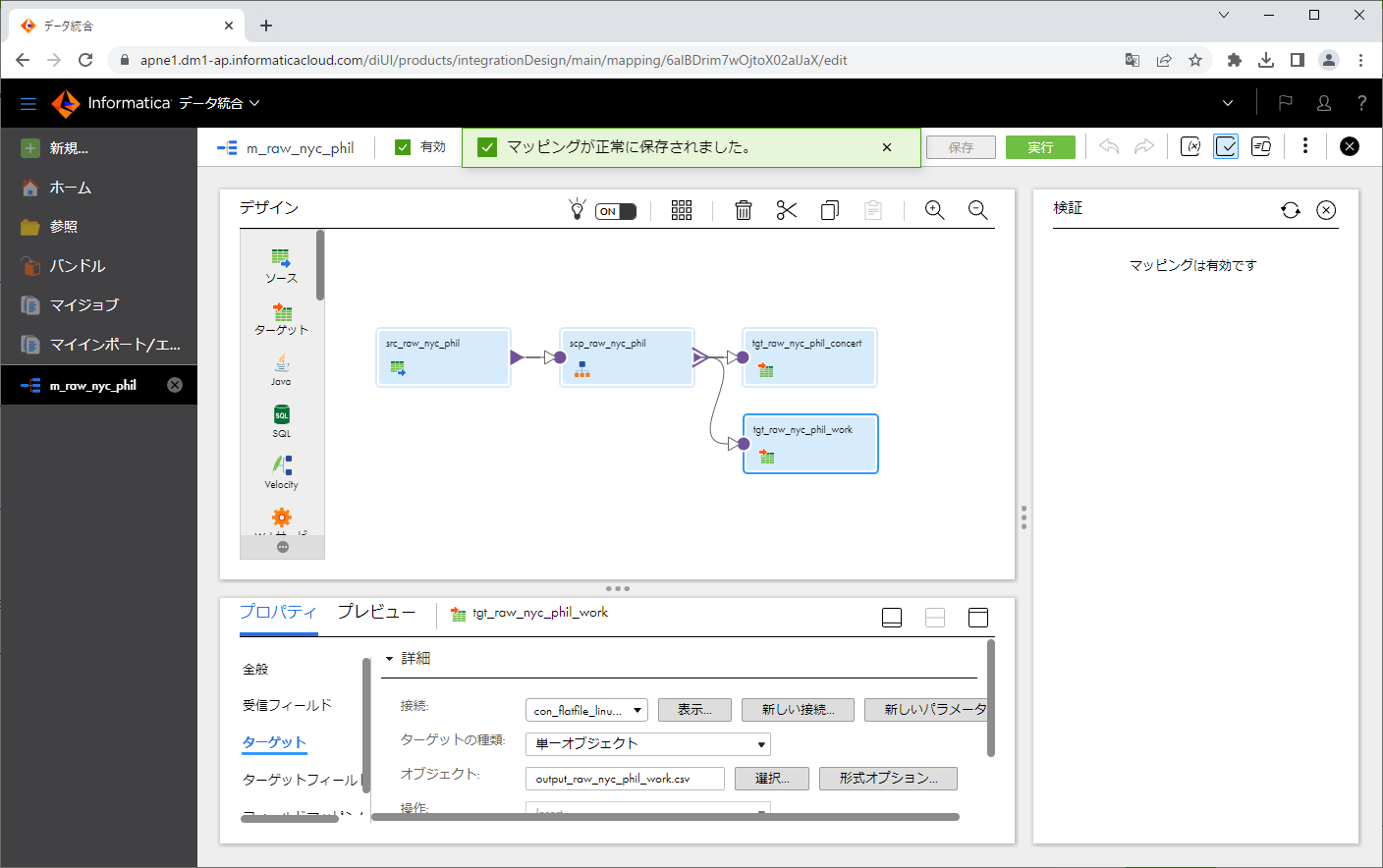
マッピングを実行する
「実行」ボタンをクリックします。

「実行」ボタンをクリックします。

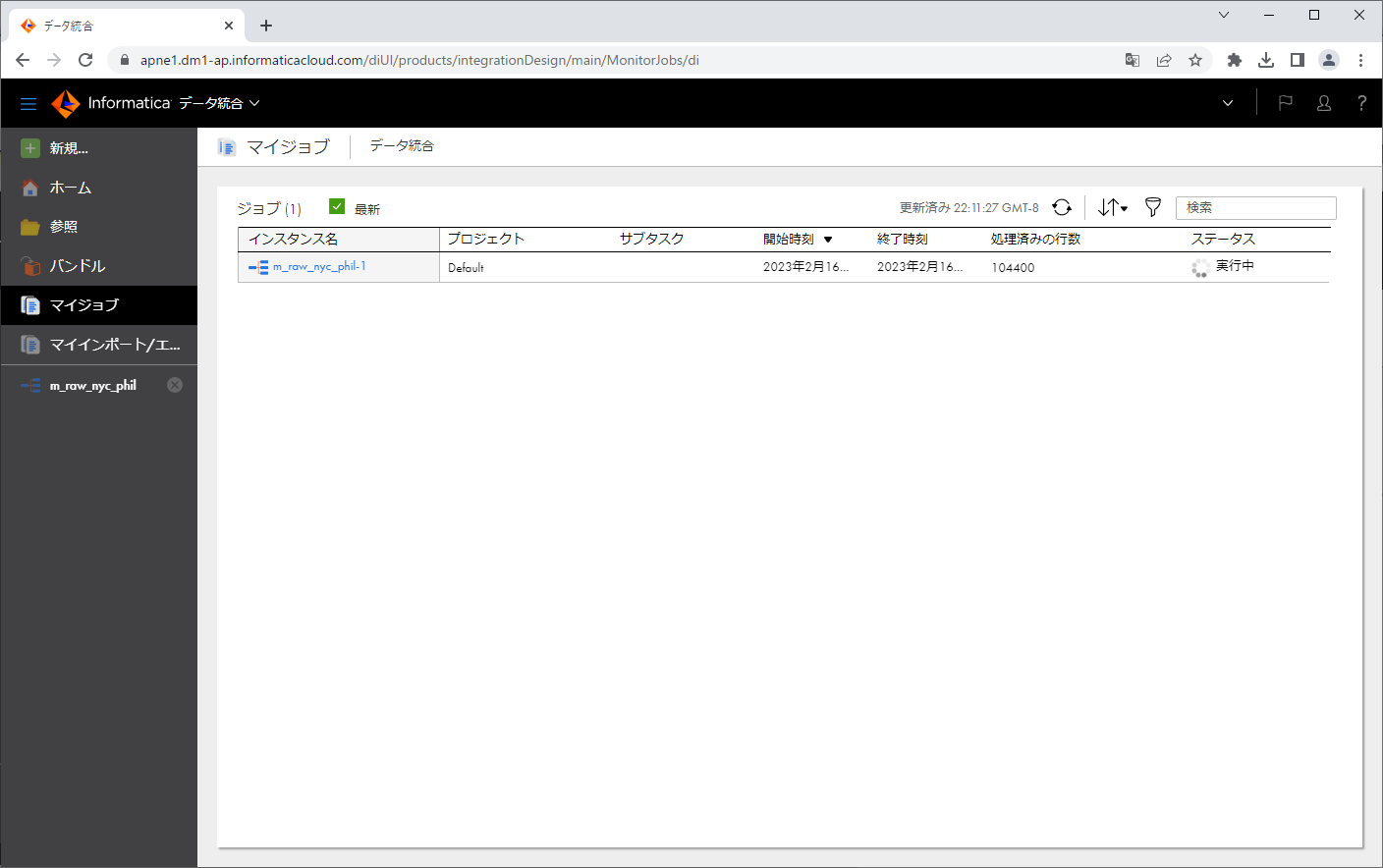
左ペインにて「マイジョブ」をクリックします。
「ステータス」が「実行中」になっています。
「ステータス」が「成功」になりました。
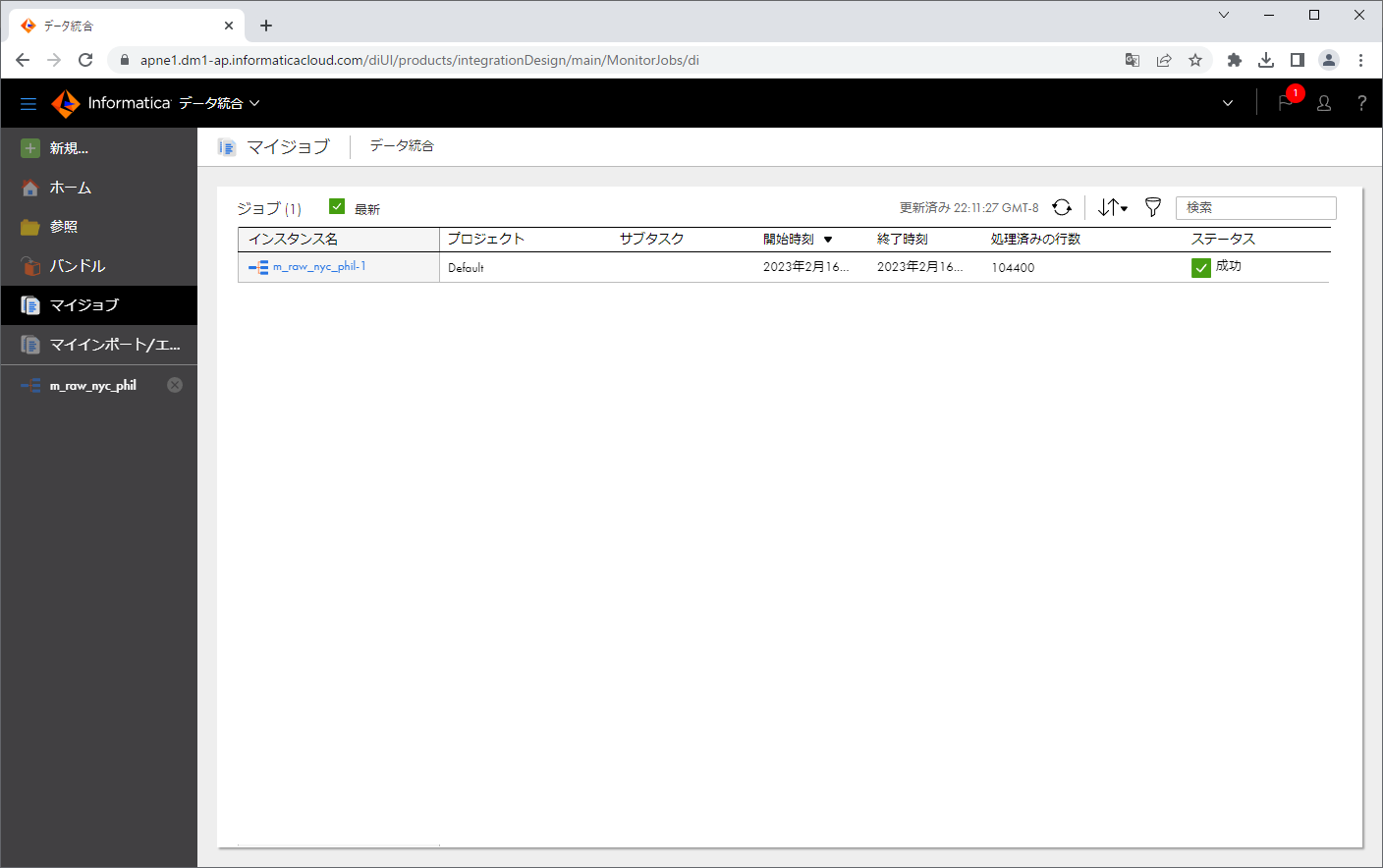
インスタンス名をクリックし、ジョブの詳細を見てみます。

「個々のソース/ターゲットの結果」パートを見ると、concert は21607個、work は82793個あったようですね。
続いて、出力ファイルができているかを確認してみます。
できていました。

output_raw_nyc_phil_concert.csv の内容を確認してみましょう。
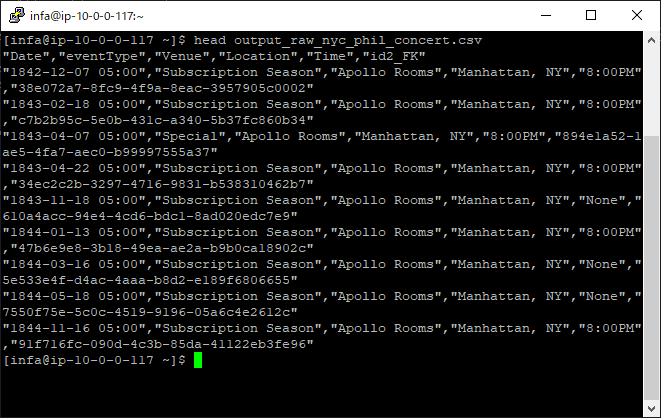
output_raw_nyc_phil_work.csv の内容も確認してみましょう。

問題なさそうです。
おわりに
以上、「Informatica IDMC(旧称IICS)のCloud Data IntegrationでKaggleのネストされたJSONファイルを解析してみた」でした。
ネストされたJSONファイルを処理したくなった場合に、 JSONスキーマなどの事前情報がない状況でも、IDMCの「インテリジェント構造検出」(Intelligent Structure Discovery)機能を使うと、スムーズに変換処理を実現することができることを分かっていただけたかと思います。
CDIは30日間の無料体験ができる ので、この機会に試してみてはいかがでしょうか。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata-career.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。https://nttdata-career.jposting.net/u/job.phtml?job_code=898
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://www.nttdata.com/jp/ja/lineup/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://www.nttdata.com/jp/ja/lineup/tdf_am/
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://www.nttdata.com/jp/ja/lineup/informatica/
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://www.nttdata.com/jp/ja/lineup/tableau/
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとDatabricksについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Databricksは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。