はじめまして! NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 の nttd-nagano です。
今回は「Informatica Data Loader for Snowflake」を使ってみましたので、本記事ではその操作方法などをご紹介します。

はじめに:NTTデータとInformaticaのパートナーシップ
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ている Informatica(インフォマティカ) 社とパートナーシップを結び、サービス強化を推進しています。

前置きが長くなりましたが…
さて皆さま、 AWS最大のカンファレンスイベント「re:Invent 2022」 は、ご覧になりましたでしょうか。

…と、先ほどまでInformaticaの話をしていたのに急にAWSの話をしはじめましたが、実はInformaticaは、re:Invent 2022にて、「Design Partner of the Year 2022」と「Analytics Partner of the Year 2022」を受賞している くらい、AWSと緊密なパートナーシップを結んでいる会社なのです。
今回、Informaticaによるブレイクアウトセッションも2つありました。
YouTubeのAWS Eventsチャネルに動画が掲載されておりますので、気になった方はご覧ください。
- Democratize data: The intersection of governance and analytics (PRT244)
- Building comprehensive cloud data management (PRT245)
さて、この動画の中で、「Informatica Data Loader for Amazon Redshift」が紹介されていました。
これは数あるInformaticaのソリューションの中のひとつに、様々なロード元(後述)からロード先(「AWS Redshift」「Azure Synapse SQL」「Google BigQuery」「Databricks Delta」「Snowflake Data Cloud」)へ大容量のデータをロードすることができる 無料のソリューション「Informatica Data Loader」 というものあり、今回 そのRedshift版がAWSマネジメントコンソールのRedshiftのUIから起動・運用できるようになった という内容でした。
※. 詳細については、AWS公式の発表をご覧ください。
さっそく使ってみよう…と思いましたが、それは他社様に先を越されてしまっておりますので、
今回は、「Informatica Data Loader for Snowflake」を使ってみようと思います。
この 「Snowflake」とは、Snowflake社が提供するクラウドベースのデータプラットフォームサービス です。
ここのところ注目を集めているサービスですので、耳にしたことがある方もいらっしゃるかと思います。
「Snowflakeとは何であり、具体的に何がすごいのか」については、弊社 村山がITmedia様に寄稿しておりますので、気になる方はご覧ください。
下準備:ロード元とロード先の準備
話が逸れてしまいました。本題に戻ります。
さて、まずは下準備です。
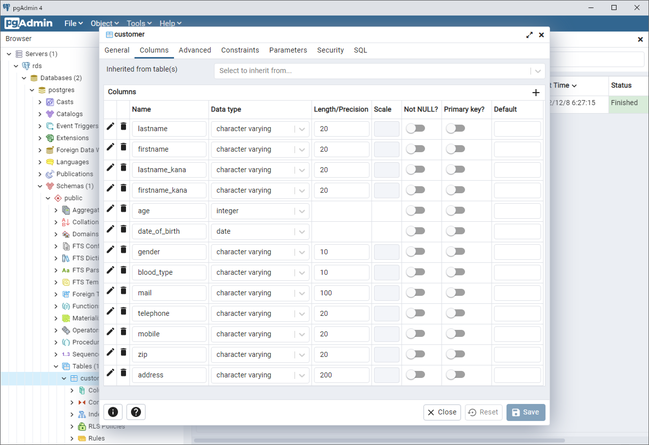
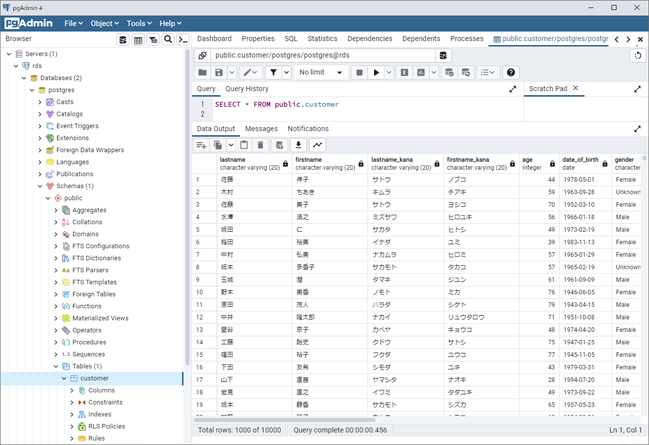
はじめに、ロード元として、AWS内にRDS for PostgreSQLを用意しました。
データベース「postgres」内のスキーマ「public」配下に、テーブル「customer」を作成して、顧客情報を模したダミーデータを入れておきました。
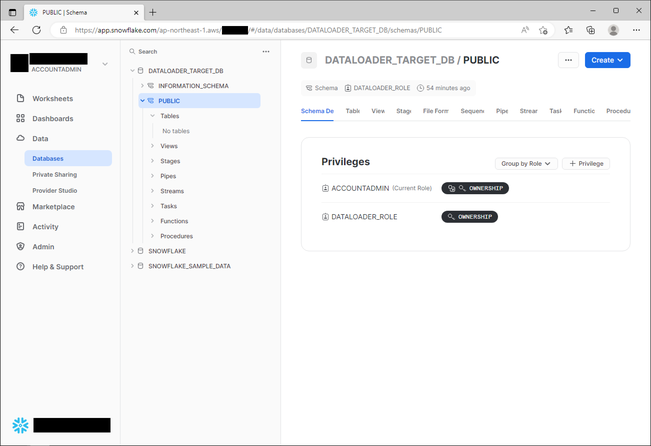
一方、ロード先となるSnowflakeには、Data Loaderが使用するロール「DATALOADER_ROLE」およびそのロールを付与したユーザー「DATALOADER_USER」を作成し、データベース「DATALODER_TARGET_DB」を作成しておきました。
「Informatica Data Loader for Snowflake」を使ってみた
さて、ようやくここからが「Informatica Data Loader for Snowflakeを使ってみた」です。
サインアップ
まず、Informatica Marketplaceの Informatica Data Loader for Snowflakeのページ にアクセスします。
次にフォームに入力していきます。
| 項目 | 説明 |
|---|---|
| Work Email | メールアドレスを入力します。ログインする際のユーザー名として使用されます。 |
| Create Password | パスワードを入力します。 |
| Select Region | Data Loaderが処理をするための「Informatica Cloud Hosted Agent」は世界の様々なリージョンでホストされています。日本の方は「Asia Pacific」を選択するのが自然かと思います。「Informatica Cloud Hosted Agent」については、後述します。 |
| Click here to receive marketing communitations ...(略) | Informatica社からマーケティング用のメールが送付されてもOKであれば、チェックを入れてください。 |
| I acknowledge that I have read and agree to the End User Terms. | エンドユーザー規約を読み、同意できる場合にチェックを入れてください。 |
「SIGN ME UP」ボタンをクリックすると、ログイン画面に遷移します。
ログイン
先ほどフォームに入力したログイン情報を入力し、「ログイン」ボタンをクリックします。
次に、「セキュリティの質問の設定」(いわゆる「秘密の質問」とその答え)を求められるので、入力します。
すると、Data Loaderのホーム画面に遷移します。
データローダータスクの作成
それでは、ここからはData Loaderのための「タスク」を定義していきます。
なお、操作に困った場合は、公式オンラインヘルプ もあわせてご覧ください。
まず、左ペインの「新規」をクリックします。
すると、「データローダータスク」の作成画面に遷移します。
ロード元への接続の作成と設定
まずは、ロード元(「ソース」)への「接続」を作成していきます。
この「接続」は、対象へ接続するための情報を管理する定義体です。
「新しい接続」ボタンをクリックします。
下図のように様々な種類の「接続」を作ることができます。
(一覧は Data Loader公式オンラインヘルプ をご覧ください)


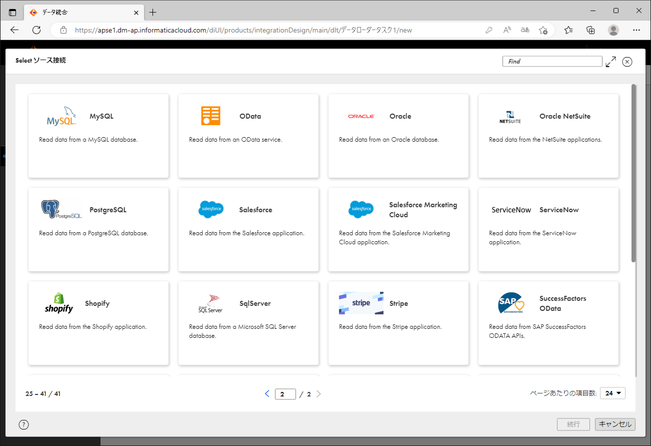
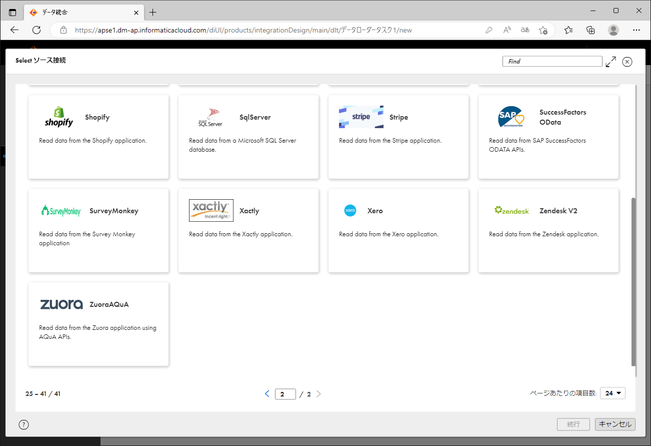
今回はロード元がRDS for PostgreSQLですので、「PostgreSQL」を選択し、「続行」ボタンをクリックします。
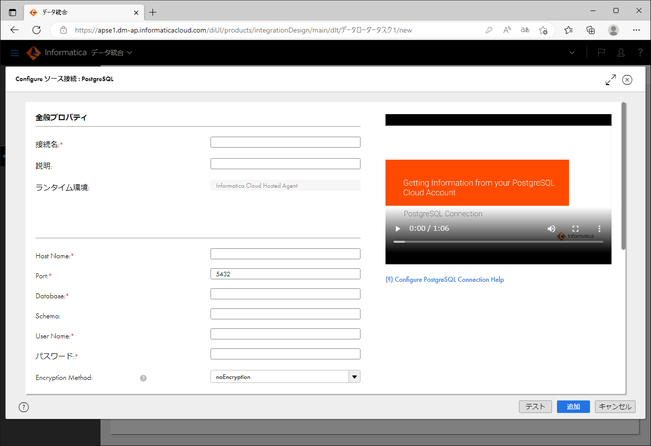
対象に接続するための情報を入力していきます。
フォーム内に赤い「*」が表示されているのが、必須項目です。
| 項目 | 説明 |
|---|---|
| 接続名 * | 任意の文字列を入力します。 |
| 説明 | 入力不要です。 |
| ランタイム環境 | Data Loaderがデータを処理する際に利用する環境(マシン上のプロセス)です。Data Loaderではあらかじめ「Informatica Cloud Hosted Agent」と固定で入力されています。これはロード元のデータをInformatica社のネットワーク内にあるマシン上のプロセスで処理することを示しています。 |
| Host Name * | 今回のようにRDSであれば、エンドポイントを入力します。 |
| Port * | あらかじめ5432と入力されています。PostgreSQLのデフォルトTCPポート番号から変更している場合は、修正します。 |
| Database * | 対象のデータベース名を入力します。今回は「postgres」と入力しました。 |
| Schema | 指定する必要がある場合に入力します。 |
| User Name * | 接続する際のユーザー名を入力します。 |
| パスワード * | ユーザー名に対応するパスワードを入力します。 |
| Encryption Method | データローダータスクには適用されません。 |
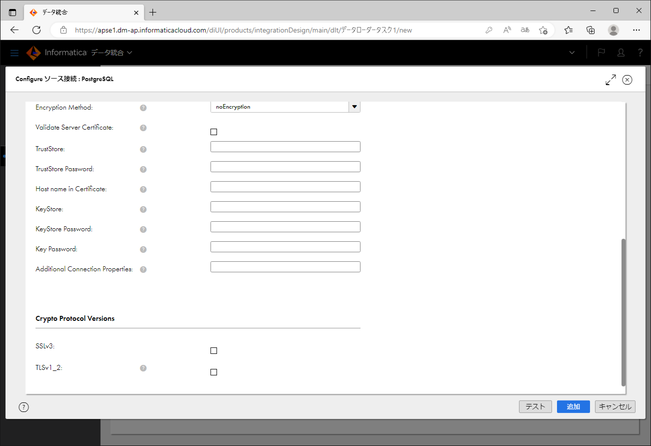
| Vaidate Server Certificate | データローダータスクには適用されません。 |
| TrustStore | データローダータスクには適用されません。 |
| TrustStore Password | データローダータスクには適用されません。 |
| Host name in Certificate | データローダータスクには適用されません。 |
| KeyStore | データローダータスクには適用されません。 |
| KeyStore Password | データローダータスクには適用されません。 |
| Key Password | データローダータスクには適用されません。 |
| Additional Connection Properties | 必要があれば入力します。 |
| SSLv3 | データローダータスクには適用されません。 |
| TLSv1_2 | データローダータスクには適用されません。 |
ロード元への接続パスと設定変更
さて、ここで、RDSの設定を変更しておきましょう。
というのも、Data Loaderでは、Informaticaのネットワーク内のマシンにてホストされている「Informatica Cloud Hosted Agent」にてデータを処理するため、対象がインターネット経由でアクセスできるようになっている必要があるためです。
RDSであれば、「パブリックアクセス可能」(パブリックアクセシビリティ:あり) に設定されている必要があります。
なお、「インターネット経由でアクセスできるようにする」というと、身構える方がいらっしゃるかもしれません。
ただし、次のリンクの通り、「Informatica Cloud Hosted Agent」のIPアドレスは公開されており、対象をインターネット全体に公開する必要はなく、これで絞ることができます。
上記ページの通り、本記事執筆時点(2022年12月)では、「Asia Pacific」リージョンの「Informatica Cloud Hosted Agent」のIPアドレスは、次のいずれかになります。
- 52.65.142.220
- 13.236.57.22
今回はロード元がRDS for PostgreSQLですので、これらのIPアドレスからTCPポート5432番への接続を許可するようなルールを、RDS用VPCセキュリティグループのインバウンドルールに追加すれば、接続元を「Informatica Cloud Hosted Agent」に限定できます。
話は戻って…
さて、「テスト」ボタンをクリックし、入力した情報が正しいかを確認します。
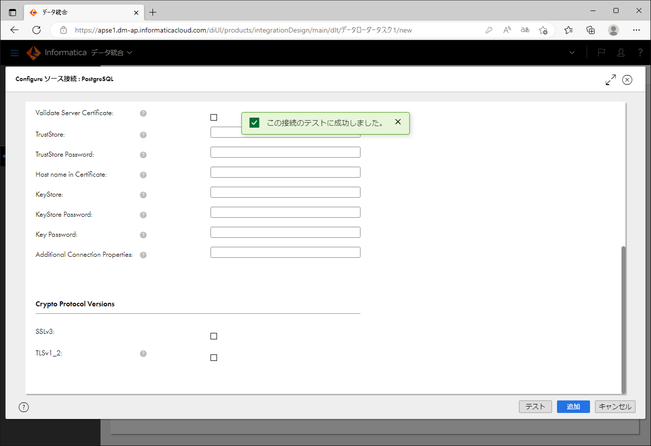
ここで、「この接続のテストに成功しました。」と表示されれば、問題ありません。
そうでない場合は、フォームへ入力した情報や、ロード元側(今回であればRDS側)の設定を確認してみてください。
「追加」ボタンをクリックします。
次に、どのテーブルを対象とするかを選びます。
「オブジェクトの定義」の「ソースオブジェクト」にて、下記のいずれかを選択します。
- すべてを読み取る
- 一部を除外
- 一部を含める
不要なテーブルはロードしないようにできるわけですね。
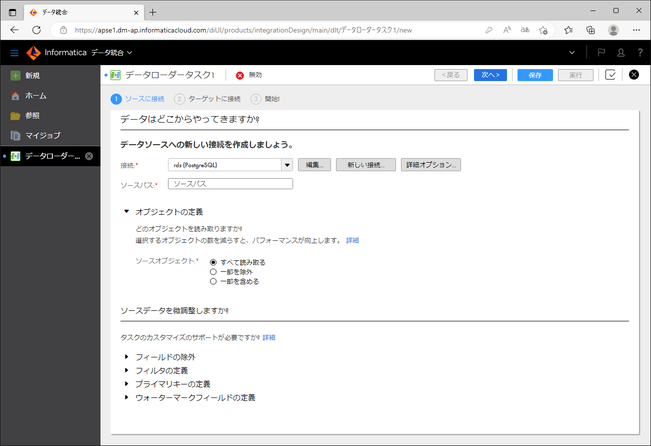
今回は「一部を含める」を選択してみました。
すると画面が一部書き換わり、「含めるソースオブジェクト」と表示されます。
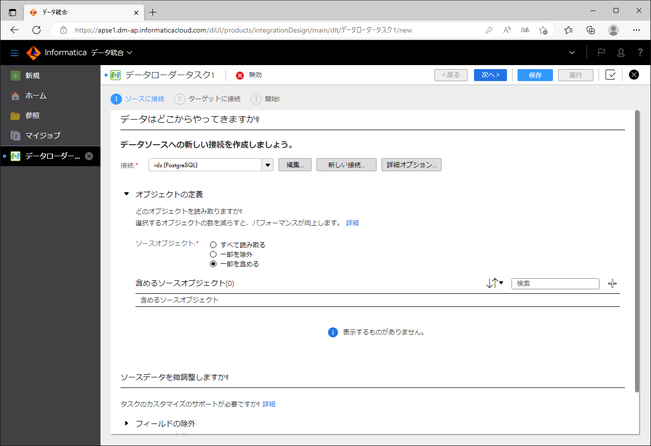
「含めるソースオブジェクト」の右端の「+」アイコンをクリックします。
自動的にロード元へ接続され、対象テーブルを選ぶダイアログが表示されます。
左ペインにてスキーマを選択し、右ペインにてオブジェクト(テーブル)を選択します。
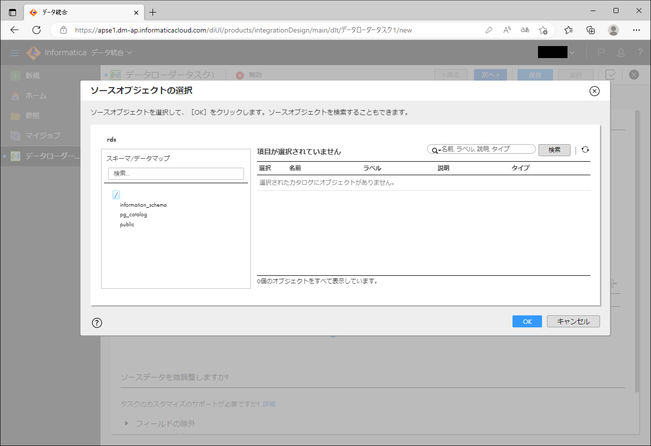
今回はテーブル「customer」のみを選択し、「OK」ボタンをクリックしました。
(もちろん、複数選択することもできます。)
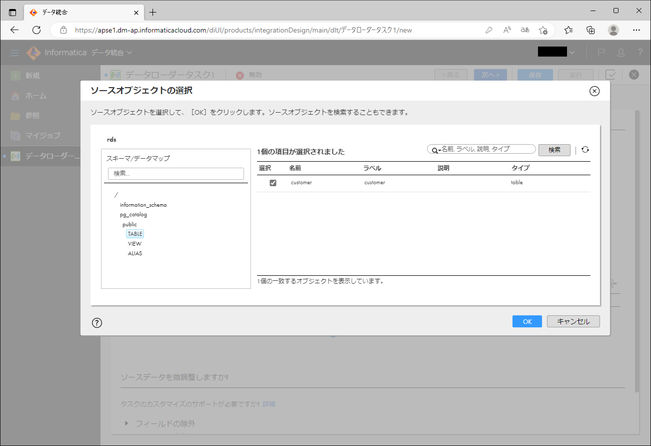
ここで、下部の「ソースデータを微調整しますか?」にて、さらに細かい設定をすることもできます。
| 項目 | 説明 |
|---|---|
| フィールドの除外 | 対象外としたいフィールド(テーブルの場合はカラム)を選択できます。 |
| フィルタの定義 | 一部のレコードのみを対象にするためのフィルタを定義できます。 |
| プライマリキーの定義 | プライマリキーフィールドを定義できます。タスクを再実行するときに行をUPDATEする場合は、プライマリキーフィールドが必要です。 |
| ウォーターマークフィールドの定義 | ウォーターマークフィールドを定義できます。ウォーターマークフィールドは、どのレコードが追加されたかあるいは変更されたかを識別する日付/時刻フィールドあるいは数値フィールドです。 ソースにウォーターマークフィールドが定義されていない場合、タスクを実行するたびにソースのすべてのレコードを処理する必要があり、タスクの処理時間が長くなります。プライマリキーの定義と合わせて定義することで、増分ロードを実行することができるようになります。 |
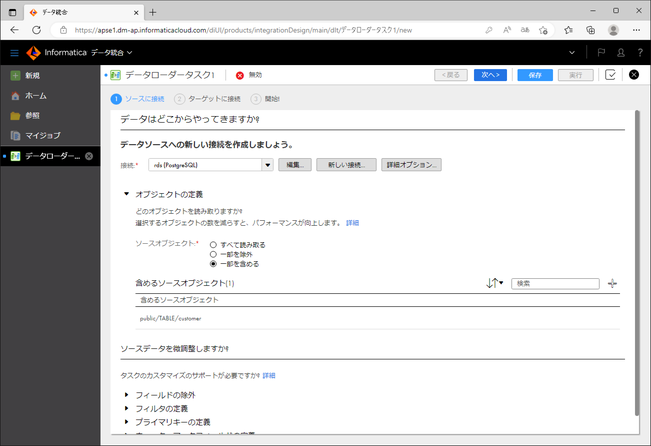
今回は簡単のため、細かい設定はせず、「次へ」ボタンをクリックします。
ロード先への接続の作成と設定
ロード先(「ターゲット」)への「接続」を作成していきます。
「新しい接続」ボタンをクリックします。
対象に接続するための情報を入力していきます。
フォーム内に赤い「*」が表示されているのが、必須項目です。
| 項目 | 説明 |
|---|---|
| 接続名 * | 任意の文字列を入力します。 |
| 説明 | 入力不要です。 |
| ランタイム環境 | Data Loaderがデータを処理する際に利用する環境(マシン上のプロセス)です。Data Loaderではあらかじめ「Informatica Cloud Hosted Agent」と固定で入力されています。ロード元のデータをInformatica社のネットワーク内にあるマシン上のプロセスで処理することを示しています。 |
| Authentication | 認証方式を指定します。詳細は Snowflakeの公式ドキュメント をご覧ください。 |
| ユーザー名 * | 接続するためのユーザー名を入力します。今回は「DATALOADER_USER」と入力しました。 |
| パスワード * | ユーザー名に対応するパスワードを入力します。 |
| Account * | Snowflakeのウェブインターフェースにログインする際に「xxxxxxxxxx.snowflakecomputing.com」のようなドメインにアクセスするかと思います。そのxxxxxxxxxの部分を入力します。詳細は Data Loaderの公式オンラインヘルプ をご覧ください。 |
| Warehouse * | ロード処理をする際に使うウェアハウスを入力します。今回は「DATALOADER_WH」と入力しました。 |
| Role | ウェアハウスを使う際のロールを入力します。必須項目となっていませんが、入力した方が誤りが少ないかと思います。 |
| Additional JDBC URL Parameters | 必要があれば入力します。 |
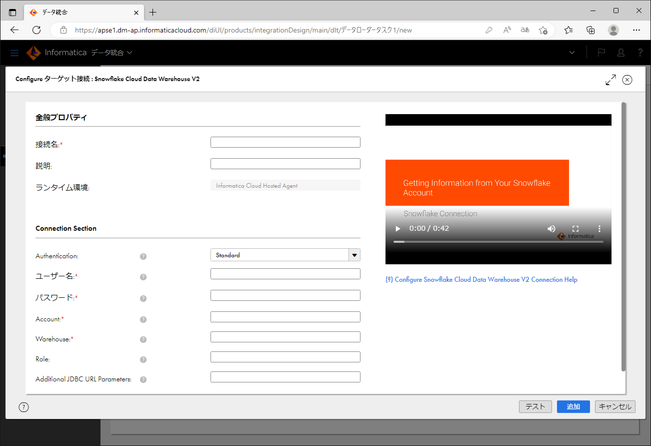
さて、「テスト」ボタンをクリックし、入力した情報が正しいかを確認します。
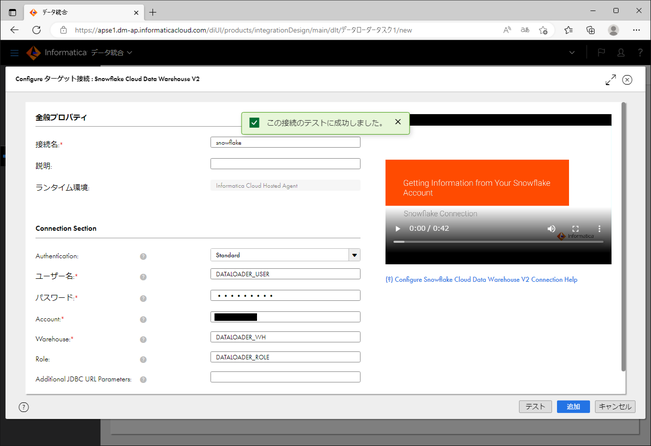
ここで、「この接続のテストに成功しました。」と表示されれば、問題ありません。
そうでない場合は、フォームへ入力した情報や、ロード先側(Snowflake側)の設定を確認してみてください。
「追加」ボタンをクリックします。
次に、どこにロードするかを入力していきます。
| 項目 | 説明 |
|---|---|
| ターゲット名のプレフィックス | ロード先のテーブル名にプレフィックスを付与することができます。必要があれば入力します。 |
| TableType | 入力不要です。 |
| Path * | 【データベース名】/【スキーマ名】の形式で入力します。今回は「DATALOADER_TARGET_DB/PUBLIC」と入力しました。 |
| 既存のテーブルにロードしますか? | 既存のテーブルに増分ロードする場合は「はい」を選びます。増分ロードでは、ロードされる行が少なくなるため、タスクのパフォーマンスが向上します。増分ロードするためにはウォーターマークフィールドが設定されている必要があります。今回は「いいえ、毎回新しいテーブルを作成する」を選択しました。 |
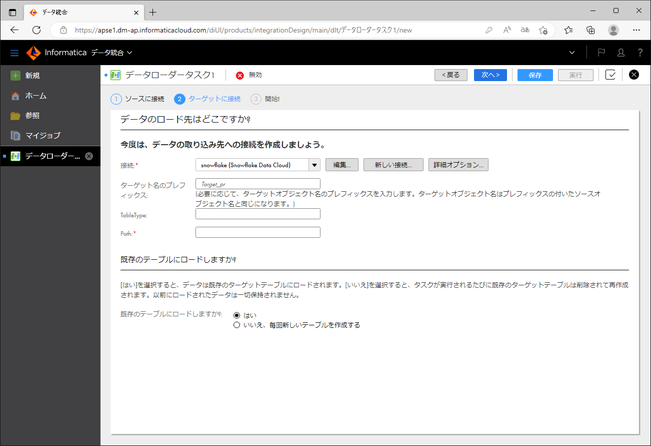
「次へ」ボタンをクリックします。
データローダータスク実行
画面上部に「開始!」と表示されているかと思います。
これでほぼ準備ができました。
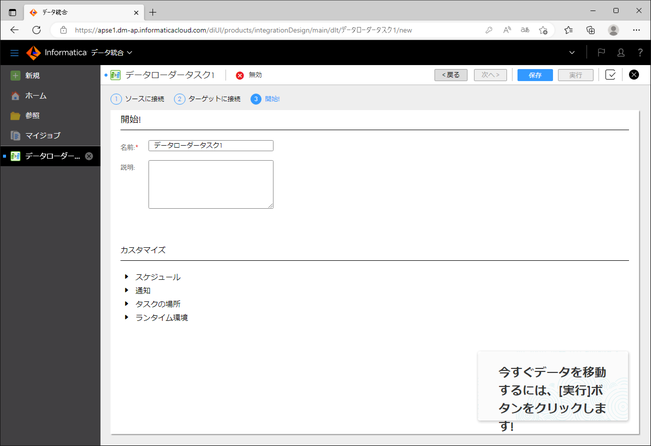
なお、下部の「カスタマイズ」にて、詳細を設定できます。
| 項目 | 説明 |
|---|---|
| スケジュール | 定期的に実行したい場合に設定します。 |
| 通知 | タスクが正常に終了したとき、警告つきで終了したとき、または失敗した際に、ユーザーに電子メールを送信してほしい場合に設定します。 |
| タスクの場所 | 現在作っているデータローダータスクの保存先プロジェクトを指定します。通常変更の必要はありません。 |
| ランタイム環境 | Data Loaderでは「Informatica Cloud Hosted Agent」固定です。 |
今回はカスタマイズ設定はせず、「保存」ボタンをクリックしました。
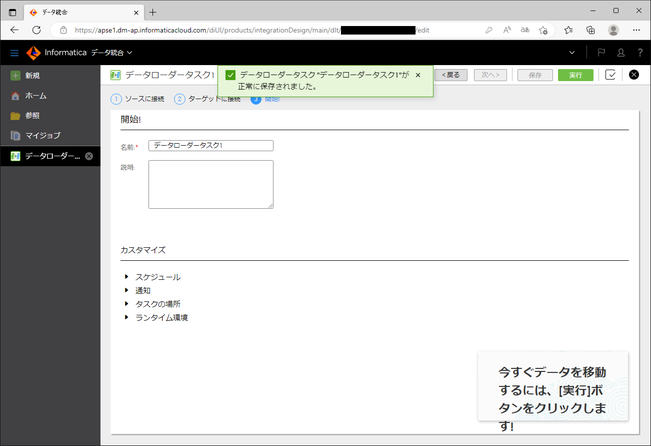
ここで、「データローダータスク"データローダータスク1"が正常に保存されました。」と表示されれば問題ありません。
それでは、「実行」ボタンをクリックし、Data Loaderを動作させてみましょう。
「実行」ボタンをクリックすると、「データローダータスク1を開始しました。マイジョブで表示してください。」と表示されます。
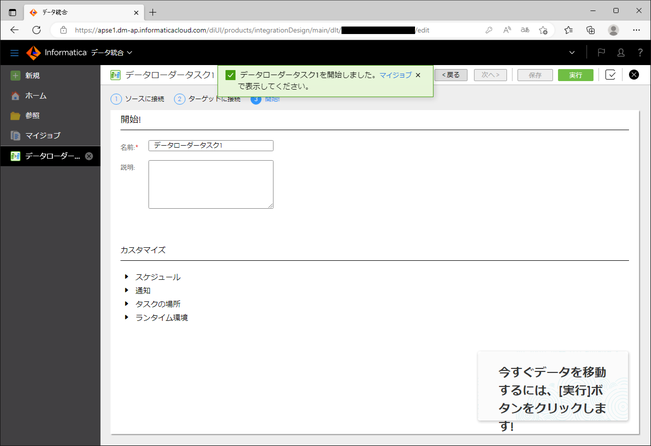
データローダータスクの実行状況を見るには、先ほどの指示通り、左ペインの「マイジョブ」をクリックします。
データローダータスクが実行中の場合は「ステータス」に「実行中」と表示されます。
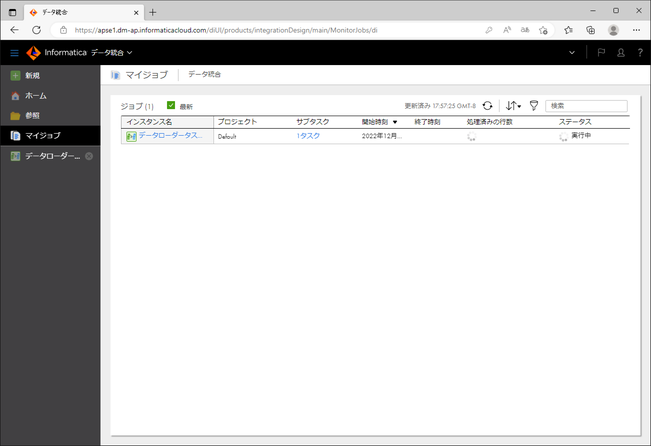
状況が変化すると、画面上部に「使用可能な更新」と表示されます。それをクリックすると、画面が更新されます。
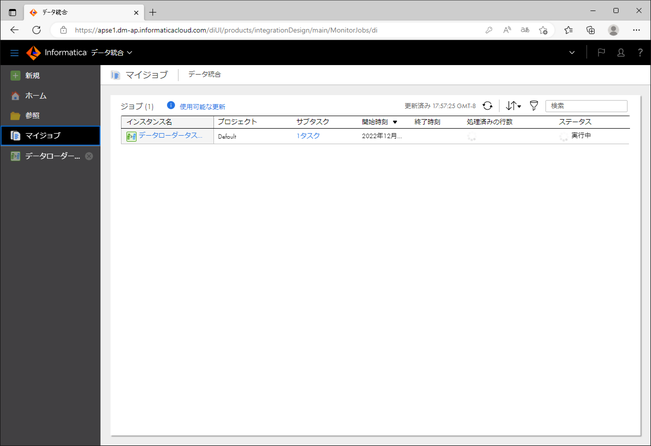
データローダータスクの実行が正常に終了した場合は、「ステータス」に「成功」と表示されます。
また、「処理済みの行数」に処理対象となったレコード数が表示されます。
一方、実行時に異常が発生した場合は、「ステータス」に「エラー」と表示されます。
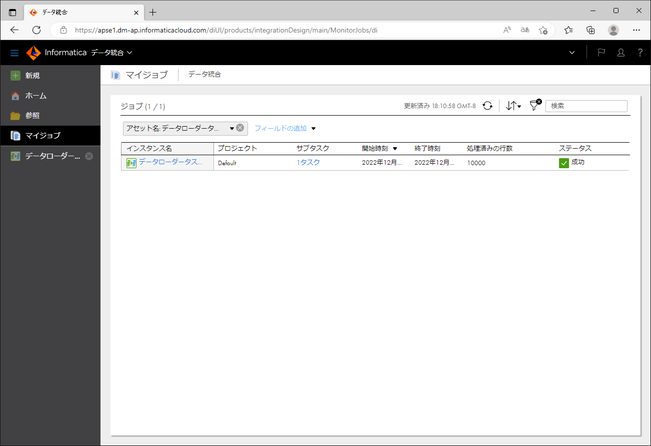
「インスタンス名」の箇所をクリックすると、実行結果の詳細が表示されます。
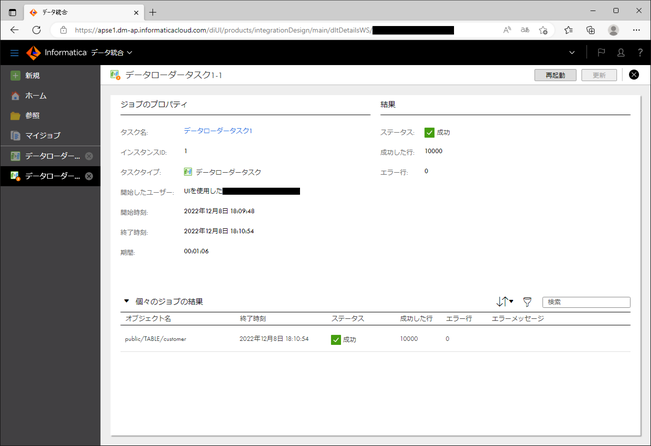
なお、「ステータス」が「エラー」の場合は、この画面から ログファイルをダウンロードできます 。
結果の確認
さあ、Snowflakeのウェブインターフェースにログインして、結果を見てみましょう。
まず、データベース「DATALOADER_TARGET_DB」のスキーマ「PUBLIC」の配下に、期待通りテーブル「customer」が作成されていることが確認できました。
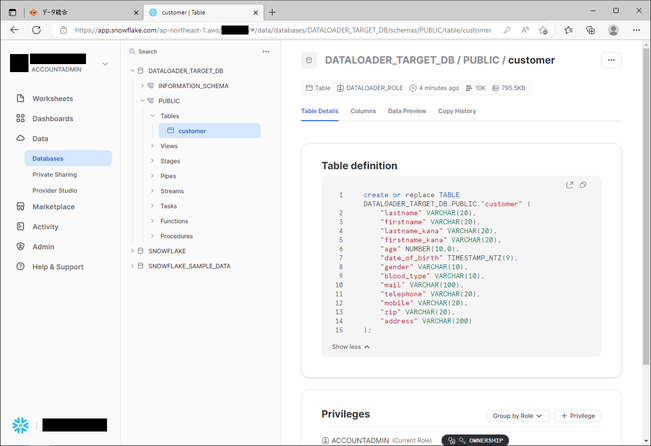
次に、「Data Preview」をクリックして、プレビューしてみると、ロード元のRDSのテーブルに入っていたデータが、ロード先のSnowflakeのテーブルに期待通り入っていることを確認できました。
レコード件数も問題ありません。
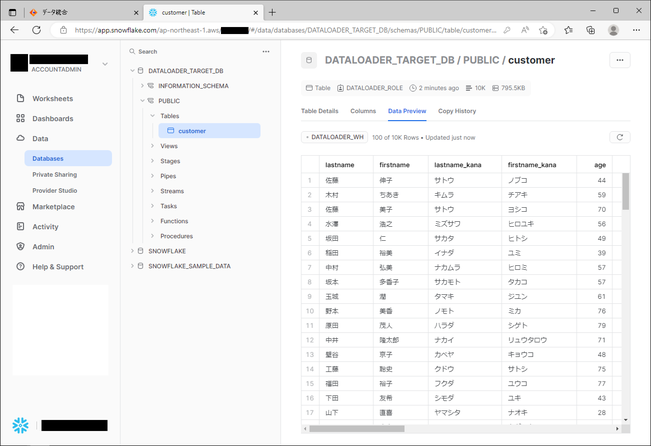
これで実際に成功していることが確認できました。
もし、エラーが発生した場合は、前述のログファイルを確認したり、Snowflakeのウェブインターフェースの「Activity」の「Query History」にて実際に発行されているクエリを確認すると良いかと思います。
おわりに
以上、「Informatica Data Loader for Snowflake」を使ってみたでした。
無料でこれが使えるというのは、なかなかすごいと思います。
なお、「Informatica Data Loader」は、Informaticaのクラウドデータマネージメントプラットフォームである「Intelligent Data Management Cloud」(略称はIDMC。旧称はIICS)をベースに動作しています。
IDMCには今回ご紹介したData Loaderの他にも、データ統合、API統合、マスターデータ管理、データガバナンス関連など様々なサービスがあります。
これらについても、今後、当Organization の記事でご紹介していく予定ですので、ご興味がございましたらご覧ください。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata-career.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。https://nttdata-career.jposting.net/u/job.phtml?job_code=898
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://www.nttdata.com/jp/ja/lineup/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://www.nttdata.com/jp/ja/lineup/tdf_am/
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://www.nttdata.com/jp/ja/lineup/informatica/
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://www.nttdata.com/jp/ja/lineup/tableau/
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとDatabricksについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Databricksは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。