はじめに
この記事では、OpenAIGymという「強化学習のアルゴリズム開発のためのツールキット」を使って強化学習の実装をしていきます。
この記事では最初の環境構築と、簡単にゲームを実行してみます。
(要はOpenAIGymの環境構築とHelloWorld(?)記事です!)
流れとしては、
- OpenAIGymの環境構築
- 実際にいろんなゲームを実行してみよう!
ってなかんじで書いていきます!!
2021/3/3追記
今年中にはさまざまなアルゴリズムで攻略しまくった様子をqiitaにまとめる予定です
OpenAIGymとは
非営利団体であるOpenAIが提供してくれる、強化学習アルゴリズムの開発と評価のためのプラットフォームがOpenAIGymです。
OpenAIGymにはさまざまな強化学習の課題が収録されていて、テレビゲームや古典制御問題(倒立振子など)、ロボット制御などを扱えるシミュレータが用意されています。
前提環境
- Ubuntu 18.04.2 LTS
- Python3.6.7以降(3.6.7, 3.7.3, 3.8.0で動作確認済み)
1. OpenAIGymの環境構築
まずは、OpenAIGymの環境構築を行います。
以下のコマンドを実行してください。
$ sudo apt install python3-tk
$ sudo apt install python3-pip
$ sudo pip3 install --upgrade pip
$ sudo pip3 install matplotlib
少し解説すると、
$ sudo apt install python3-tk
ではtkinterというローカルのGUIアプリを構築するためのツールキットをインストールします。
OpneAIGymでは以下のようにGUIの画面を表示してゲームを実行するので、tkinterが必要になります。
※ちなみにこれは後ほど説明するCartPoleというゲームです。
次に、以下のコマンドを実行することでゲームの基本的な環境を入れることができます。
$ sudo pip3 install gym
また、いろんなゲームをプレイできるようにするには拡張機能も入れる必要があります。
ここでは、いろんなゲームを紹介したいので拡張機能も含めてインストールしていきます。
ここでは、Gym Retroと呼ばれるファミコン、ゲームボーイなどのレトロゲームをOpenAIGymに対応した環境で使えるようにするライブラリを追加します。
$ sudo apt install cmake
$ sudo apt install zlib1g-dev
$ sudo pip3 install gym[all]
$ sudo pip3 install gym-retro
最後に、マリオをgymの環境で動かすための環境構築をします。
ここでは、fceuxというlinuxでファミコン用のエミュレータをインストールし、その上でマリオを動作させます。
sudo apt-get install fceux
sudo pip3 install ppaquette_gym_super_mario
ここまでで、とりあえず環境構築は完了しているはずです!
2. 実際にいろんなゲームを実行してみよう!
まず、どんなゲームが動かせるのか確認します。
from gym import envs
envids = [print(spec.id) for spec in envs.registry.all()]
全部載せると膨大な行になってしまうので、以下に結果の一部のみ載せます。
このページにgymのすべての情報が載ってます。
また、サンプル動画のリストはこのページにも載っています・
Copy-v0
RepeatCopy-v0
ReversedAddition-v0
ReversedAddition3-v0
DuplicatedInput-v0
Reverse-v0
・
・
・
CubeCrash-v0
CubeCrashSparse-v0
CubeCrashScreenBecomesBlack-v0
MemorizeDigits-v0
では、実際にPython3で簡単なコードを書いてゲームを起動したりしてみます!
CartPole-v0
CartPoleとは、日本語で言うと倒立振子です。
倒立振子とはカートの上に回転軸を固定したポールを立て、そのポールが倒れないようにカートを右・左へと細かく動かして、制御する課題です。
このゲームの公式ページはここで、githubはここです。
以下で、パラメータについて説明していきます。
OpenAIGymはOSS(オープンソースソフトウェア)なので基本はすべて公式のgithubにかかれています。
- Actions(行動)
CartPoleでは0, 1の値で行動を決定します。
| 値(int) | 行動 |
|---|---|
| 0 | Push cart to the left(左) |
| 1 | Push cart to the right(右) |
- Observation(状態)
4つのパラメータをもとに現在の状態を取得できます。
実際に強化学習する際はこのパラメータを用いて報酬設定したりします。
| Min | Max | 内容 |
|---|---|---|
| -2.4 | 2.4 | Cart Position(カート位置) |
| -Inf | Inf | Cart Velocity(カート速度) |
| -41.8deg | 41.8deg | Pole Angle(ポール角度) |
| -Inf | Inf | Pole Velocity At Tip(ポールの先端速度) |
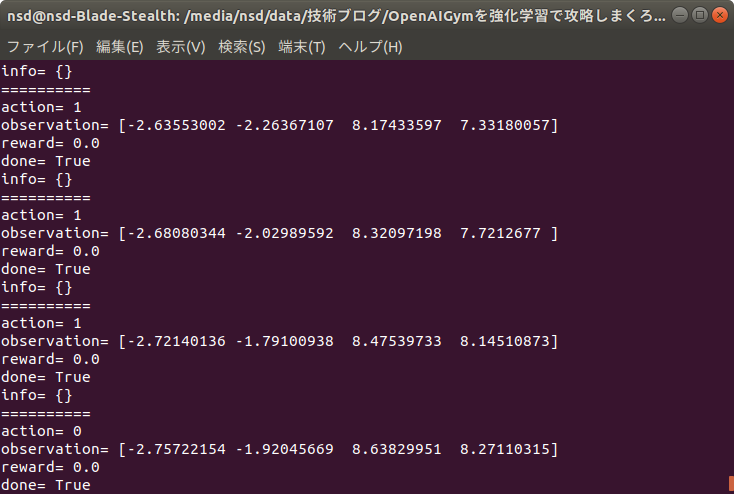
プログラムは、以下のようになります。
説明はコメント文に書いてあります。
import gym
env = gym.make("CartPole-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
MountainCar-v0

MountainCarは、右の山を登ることを目標とした課題です。
車自体の力だけではこの山を登ることはできません。
したがって、前後に揺れながら、勢いをつけてうまく山を登っていく必要があります。
このゲームの公式ページはここで、githubはここです。
以下で、パラメータについて説明していきます。
公式のgithubはこちらです。
- Actions(行動)
MountainCarでは0, 1, 2の値で行動を決定します。
| 値(int) | 行動 |
|---|---|
| 0 | push left |
| 1 | no push |
| 2 | push right |
- Observation(状態)
2つのパラメータをもとに現在の状態を取得できます。
実際に強化学習する際はこのパラメータを用いて報酬設定したりします。
| Min | Max | 内容 |
|---|---|---|
| -1.2 | 0.6 | position(位置) |
| -0.07 | 0.07 | velocity(速度) |
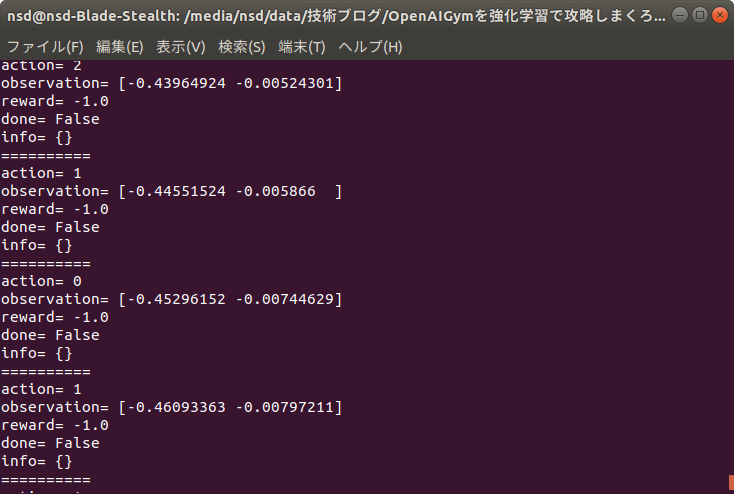
プログラムは、以下のようになります。
説明はコメント文に書いてあります。
先ほどと変わっているのは3行目の部分だけです。
import gym
env = gym.make("MountainCar-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
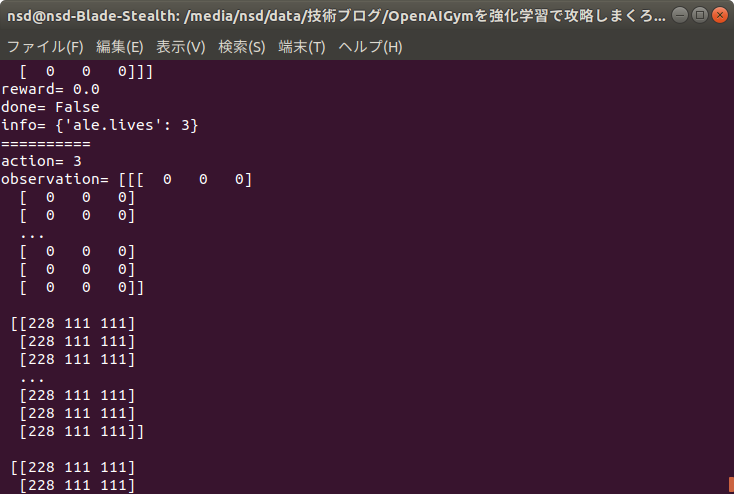
MsPacman-v0

MsPacmanは、あの有名なPacmanのゲームです。
敵にあたればゲームオーバー、餌をたくさん集めてスコアを稼いでいきます。
このゲームではより高いスコアを稼ぐことを目標としています。
このゲームの公式ページはここで、githubはここです。
以下にコードサンプルを載せます。
先ほどと変わっているのは3行目の部分だけです。
import gym
env = gym.make("MsPacman-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
Pendulum-v0

Pendulumは、適切なトルクを与えて垂直に振り上げている状態をキープするという課題です。
このゲームの公式ページはここで、githubはここです。
以下で、パラメータについて説明していきます。
公式のgithubはこちらです。
- Actions(行動)
Pendulumではトルクを任意に指定して行動を決定します。
| Min | Max | 行動 |
|---|---|---|
| -2.0 | 2.0 | トルク |
- Observation(状態)
3つのパラメータをもとに現在の状態を取得できます。
実際に強化学習する際はこのパラメータを用いて報酬設定したりします。
| Min | Max | 内容 |
|---|---|---|
| -1.0 | 1.0 | 振り子が角度θのときのcosの値 |
| -1.0 | 1.0 | 振り子が角度θのときのsinの値 |
| -8.0 | 8.0 | 振り子が角度θのときの角速度 |
- Reward(報酬)
以下の式で与えられているものがデフォルトの報酬となっています。
-(theta^2 + 0.1theta_dt^2 + 0.001action^2)
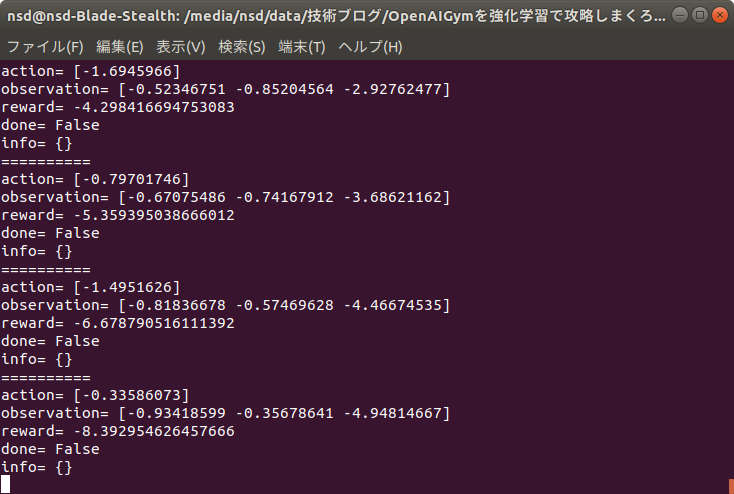
以下にコードサンプルを載せます。
import gym
env = gym.make("Pendulum-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
BipedalWalkerHardcore-v2
BipedalWalkerHardcoreは、各関節のトルク・速度を調節してうまく障害物を避けて歩けるようになる課題です。
このゲームの公式ページはここで、githubはここです。
以下にコードサンプルを載せます。
import gym
env = gym.make("BipedalWalkerHardcore-v2") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
CarRacing-v0

CarRacingは、各関節のトルク・速度を調節してうまく障害物を避けて歩けるようになる課題です。
このゲームの公式ページはここで、githubはここです。
以下にコードサンプルを載せます。
import gym
env = gym.make("CarRacing-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
Breakout-ram-v0

Breakoutとは、日本語で言うとブロック崩しです。
ボールを反射させてブロックを壊し、スコアを「稼いでいくゲームです。
このゲームの公式ページはここで、githubはここです。
以下にコードサンプルを載せます。
import gym
env = gym.make("Breakout-ram-v0") # GUI環境の開始(***)
for episode in range(20):
observation = env.reset() # 環境の初期化
for _ in range(100):
env.render() # レンダリング(画面の描画)
action = env.action_space.sample() # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
マリオ
OpenAIGyn環境に対応したマリオの環境は、2種類あります。
gym-super-mario-brosとgym-super-marioです。
これらの主な違いは、報酬体系です。
gym-super-mario-brosは報酬が「右に進んだら◯点」「左に進んだら◯点」「GameOverになったら◯点」の3種類しか選択することができません。
これに対し、gym-super-marioはより多くの選択肢があります。
したがって、この記事ではgym-super-marioを採用していきます。
環境構築については、この記事の上部で記述したとおりです。
sudo apt-get install fceux sudo pip3 install ppaquette_gym_super_mario
※マリオの環境構築については、何通りかの方法があります。
ここでは最も簡単なものを紹介しました。
環境構築の方法によって、コードが異なってくるためここで紹介した方法で環境を導入されることをおすすめします。
ネットで検索すると、gym-pullを用いてマリオを動かしているものが多く出てきますが、エラーが多発したので諦めました^^;

以下で、パラメータについて説明していきます。
公式のgithubはこちらです。
- Actions(行動)
マリオでは6つの行動を選択することができます。
以下のように長さ6のリストの各行動を選択するか(1)しないか(0)を入力します。
各行動を同時に行うことができます。
action = [0, 0, 0, 1, 1, 0] # [up, left, down, right, A, B]
- Observation(状態)
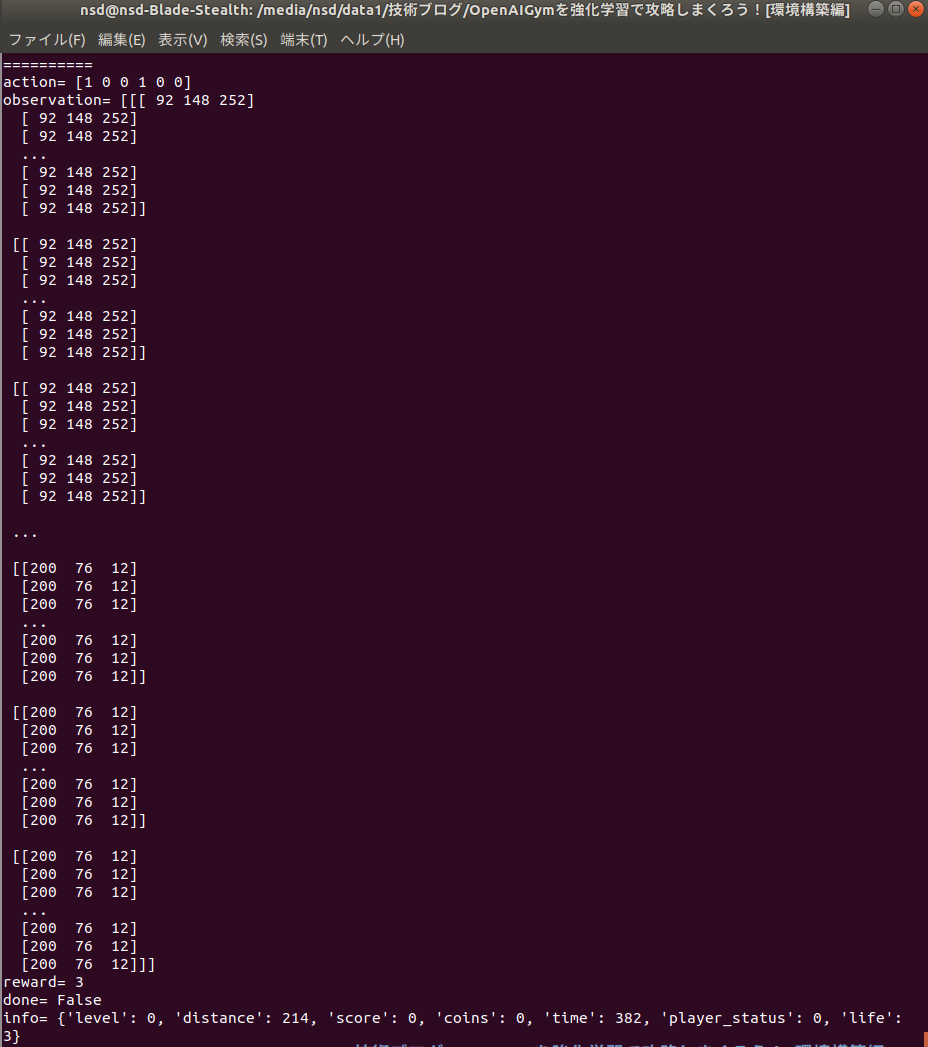
マリオでは、画像を状態として取ることができます。
- その他のパラメータ
distance: スタートからの進んだ距離(x軸)
life: ライフ。初期状態では3つあり、0になるとGameOver。
score: ゲーム内スコア。(報酬ではない)
coins: 獲得コイン数。
time: 残り時間。0になるとGameOver。
player_status: マリオの状態。smallマリオなら0、bigマリオなら1、ファイヤーボールマリオなら2。
以下にコードサンプルをのせます。
このコードのactionは、env.action_space.sample()を使用していません。
マリオでenv.action_space.sample()をすると毎回[0, 0, 0, 0, 0, 0]を返してしまうためです。
これは内部での乱数生成のコードで0.0~1.0の少数を整数型にキャスト(型変換)しているためです。
pythonのキャストは、少数を切り捨てにします。
したがって、キャスト前の少数に0.5を足すとこの問題は解決するのですが...
ソースコードの方を修正するのはめんどうなので、今回はnumpyで配列を生成しました。
import gym
import ppaquette_gym_super_mario
import numpy as np
env = gym.make('ppaquette/SuperMarioBros-1-1-v0')
for episode in range(5):
observation = env.reset() # 環境の初期化
for _ in range(100):
action = np.random.randint(0, 1+1, 6) # 行動の決定
observation, reward, done, info = env.step(action) # 行動による次の状態の決定
print("=" * 10)
print("action=",action)
print("observation=",observation)
print("reward=",reward)
print("done=",done)
print("info=",info)
env.close() # GUI環境の終了
また、マリオは1-1ステージから、8-4ステージまでのすべて(?)を選択することができます。
ステージのリストはここにのっているので、いろいろなステージを試してみてください。
まとめ
今回は、OpenAIGymを強化学習で攻略しまくるための環境構築を行いました。
試せるゲームはこの他にもたくさんあって、例えばソニックのゲームなんかも400円くらい払えばプログラムから実行できるようになり、強化学習の開発に使うことができます。
今後は、強化学習の理論(Q学習、マルコフ決定過程、DQNなど)や強化学習の実装に関する記事を書いていきますので、よろしくお願いします!!!
よければtwitterもフォローよろしくお願いします!