ステレオカメラZED2i とGrounedSAMとを連動させる。
実空間の物体の理解には、3D計測、セグメンテーションだけではなく、それが何であるのかの理解が必要だ。
セグメンテーションとそれが何であるのかという理解についてはGroundedSAMがある。
そこで、ぬけているのは3D計測である。
ZED2iカメラとZED-SDKとを結びつけるサンプル実装を作ったので紹介する。
Grounded-SAM とは
以下のGithubを見てくれ

入力画像
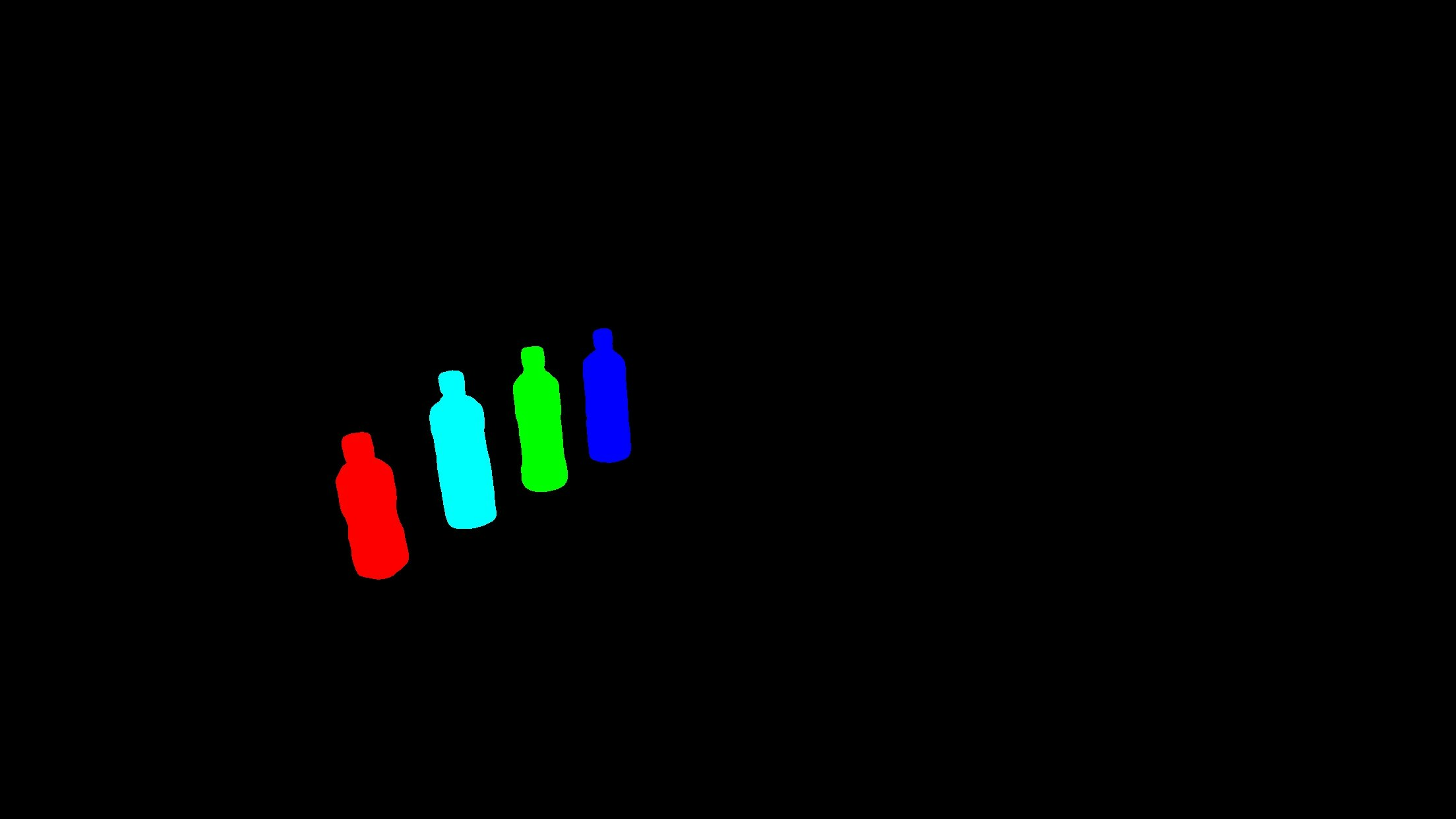
インスタンスセグメンテーション後のマスク画像

検出結果のラベルとスコアとboxとインスタンスセグメンテーション
ここまでは、2次元の画像の話だ。
自作したもの
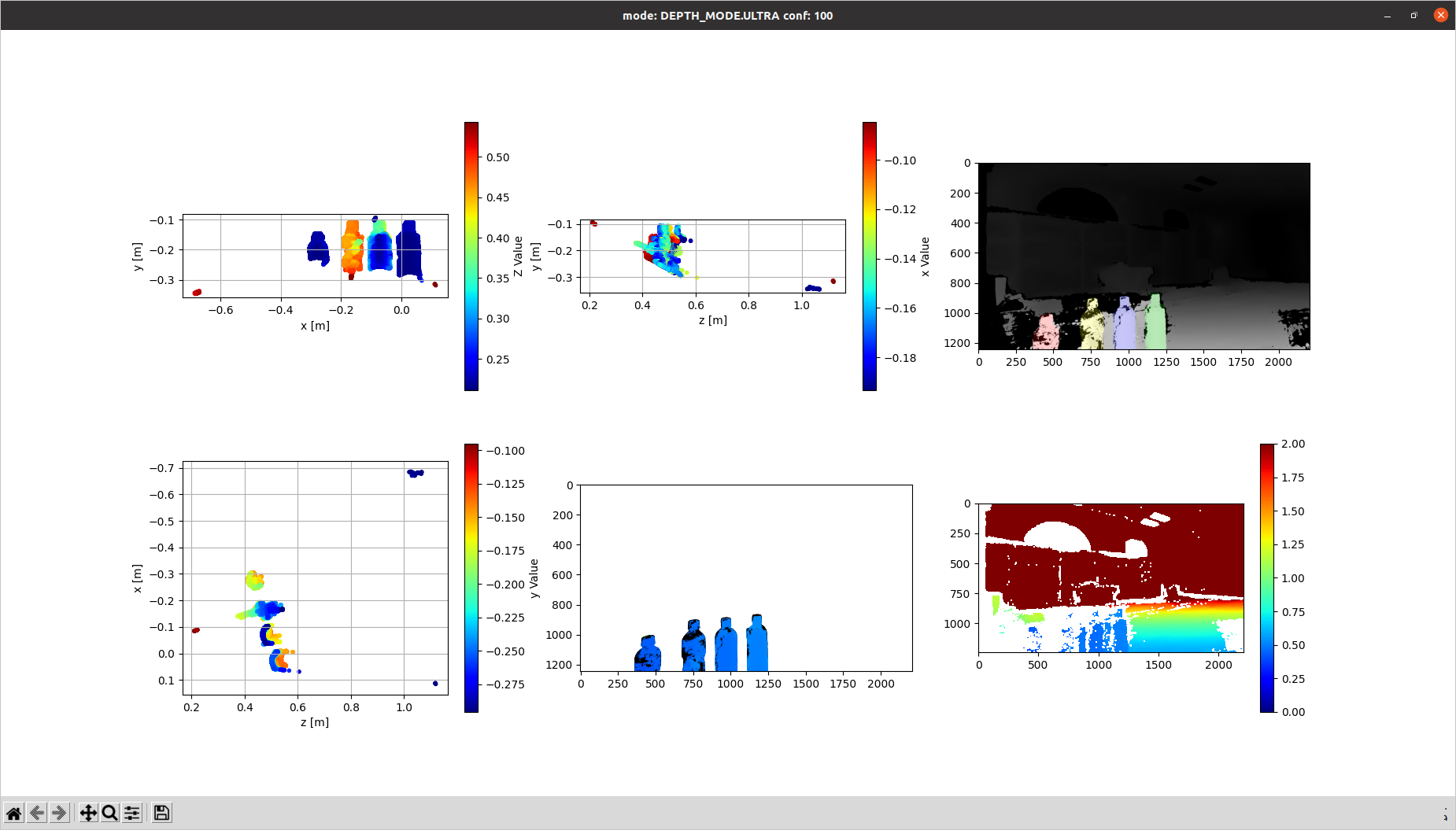
これをZED-SDKでの深度画像、点群と紐付けて可視化したのが、上の一連の図だ。
ライセンスはGrounded-Segment-Anything のライセンスと同じにした。
TODO
- まだ全然作り込まれていない。
- モジュールとして使い回せる状況にもなっていない。
- このしかばねを踏み越えて、先に進んでくれ。
まだ、これでは不足していると考えること
-
どこをどうつかむのかが計画できない。
どこを、どのようにつかむのかを、提示できなきゃならない。
紙コップと持ち手のあるコーヒーカップでは、持ち方が違ってくる。
ハサミを持つ場合も、もって移動する場合の持ち方と、ハサミを使用するための持ち方は違う。
アフォーダンスを調査中
-
外界の障害物を考慮して、手の動きを生成する行動計画には、情報が不足している。
-
テキストプロンプトの入力よりは、説明文の自動生成の方がうれしい。
- gsam の場合には、事前に複数のwordを"bottle.cup.book" などのように"."の区切り記号で複数指定している。
- そのため、指定のない物体がそこにあっても、検出・セグメンテーションをしてくれない。