3D AffordanceNet: A Benchmark for Visual Object Affordance Understanding
pdf
Shengheng Deng, Xun Xu, Chaozheng Wu, Ke Chen, Kui Jia
Abstrat の和訳
物体とのやり取り方法を視覚的手がかりから理解する能力、通称視覚的アフォーダンスは、視覚誘導ロボット研究において不可欠です。これには、視覚的アフォーダンスの分類、セグメンテーション、推論が含まれます。2Dおよび2.5D画像領域の関連する研究が以前に行われてきましたが、物体のアフォーダンスに対する真の機能的理解には、3D物理領域での学習と予測が必要です。これはまだコミュニティで不足しています。この研究では、3D AffordanceNet datasetを紹介し、23の意味的なオブジェクトカテゴリから23kの形状をベンチマークとして、18の視覚的アフォーダンスカテゴリで注釈を付けました。このデータセットに基づいて、視覚的アフォーダンス理解を評価するための3つのベンチマーキングタスクを提供します。これには、完全な形状、部分ビュー、回転不変なアフォーダンス推定が含まれます。三つの最先端の点群深層学習ネットワークがすべてのタスクで評価されます。さらに、非ラベルデータから利益を得る可能性を探るために、半教師あり学習セットアップも調査します。提供したデータセットに関する包括的な結果は、視覚的アフォーダンス理解が貴重でありながらも難しいベンチマークであることを示しています。
動作によって、着目する場所が異なる。

3D AffordanceNet
github https://github.com/Gorilla-Lab-SCUT/AffordanceNet
pip install -r requirements.txt
類似の名称だが、開発者は異なる別物らしい。
github https://github.com/nqanh/affordance-net
By Thanh-Toan Do*, Anh Nguyen*, Ian Reid (* equal contribution)

Youtube AffordanceNet: An End-To-End Deep Learning Approach for Object Affordance Detection
Youtube AffordanceNet: An End-to-End Deep Learning Approach for Object Affordance Detection
Youtube Craft Assembly Experiment
github Visual Affordance Prediction for Guiding Robot Exploration
website Visual Affordance Prediction for Guiding Robot Exploration
pdf Visual Affordance Prediction for Guiding Robot Exploration
要約— 人間が可能な相互作用の空間について直感的に理解し、この理解を以前見たことのないシーンに容易に一般化できることから着想を得て、私たちはロボットの探査を導くための視覚的な利用可能性を学習するアプローチを開発します。シーンの入力画像が与えられると、それとの相互作用によって達成可能な現実味のある将来の状態に関する分布を推論します。我々はTransformerベースのモデルを使用して、VQ-VAEの潜在的な埋め込み空間で条件付き分布を学習し、これらのモデルを大規模かつ多様なパッシブデータを用いて訓練できること、そして学習されたモデルが訓練分布を超えた多様なオブジェクトに対して組成的一般化を示すことを示します。訓練された利用可能性モデルが、ロボット操作における視覚目標条件つき方策学習中にゴールのサンプリング分布として機能する方法を示します。

Affordance Generalization Beyond Categories via Semantic
Correspondence for Robot Manipulation
pdf Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
https://tea-lab.github.io/Robo-ABC/

Affordance Transfer Learning for Human-Object Interaction Detection
pdf Affordance Transfer Learning for Human-Object Interaction Detection
https://paperswithcode.com/paper/affordance-transfer-learning-for-human-object
github https://github.com/zhihou7/HOI-CL-OneStage
人間と物体の相互作用(HOI)を推論することは、より深いシーン理解に不可欠です。一方、物体の利用可能性(または機能)は、人間が新しい物体と見たことのないHOIを発見するために重要です。この着想に触発され、私たちは新しい物体と利用可能性を認識するためのアフオーダンス転移学習アプローチを導入します。具体的には、HOIの表現は、利用可能性と物体の表現の組み合わせに分解できるため、追加の画像からの新しい物体の表現と利用可能性の表現を組み合わせることによって新しい相互作用を構成することが可能になります。つまり、利用可能性を新しい物体に転送します。提案されたアフオーダンス転移学習により、モデルは既知の利用可能性表現から新しい物体の利用可能性を推論する能力も備えています。したがって、提案された方法は、1)HOI検出のパフォーマンスを向上させる、特に未知の物体を含むHOIの場合; および2)新しい物体の利用可能性を推論するために使用できます。 HICO-DETおよびHOI-COCO(V-COCOから)の2つのデータセットでの実験結果は、HOI検出および物体の利用可能性検出の最近の最先端手法に比べて、大幅な改善を示しています。
pdf Grounding 3D Object Affordance from 2D Interactions in Images
https://yyvhang.github.io/publications/IAG/index.html
3Dオブジェクトの利用可能性の根拠付けは、3D空間内のオブジェクトの「アクション可能性」領域を特定しようとするものであり、これは具体的なエージェントの知覚と操作の間のリンクとして機能します。既存の研究は、主に視覚的な利用可能性とジオメトリ構造を結び付けることに焦点を当てており、例えば、オブジェクトのインタラクティブな関心領域を注釈付けし、その領域と利用可能性との間のマッピングを確立することに頼っています。しかし、オブジェクトの利用可能性を学ぶ本質は、それをどのように使用するかを理解することであり、相互作用を切り離す方法は一般的に一般化が制限されています。通常、人間はデモ画像や動画を通じて物理世界でオブジェクトの利用可能性を知覚する能力を持っています。これに触発され、我々は新しいタスク設定を導入します:画像中の2D相互作用から3Dオブジェクトの利用可能性を根拠付けること。これは異なるソースの相互作用を介して利用可能性を予測するという課題に直面しています。この問題に対処するために、我々はInteraction-driven 3D Affordance Grounding Network (IAG)という新しい手法を考案しました。これは、異なるソースからのオブジェクトの領域特徴を整合させ、3Dオブジェクトの利用可能性の根拠付けのための相互作用の文脈をモデル化します。さらに、提案されたタスクをサポートするためにPoint-Image Affordance Dataset (PIAD)を収集しました。PIADでの包括的な実験は、提案されたタスクの信頼性と当社の手法の優位性を実証しています。コード、モデル、およびデータはプロジェクトページで入手可能です。
HANDAL: A Dataset of Real-World Manipulable Object Categories
with Pose Annotations, Affordances, and Reconstructions
https://nvlabs.github.io/HANDAL/
機械翻訳を用いた和訳:
要約— カテゴリレベルの物体姿勢推定と利用可能性予測のためのHANDALデータセットを提案します。従来のデータセットとは異なり、私たちのデータセットは、ロボットマニピュレータによる機能的なグラスピングに適した適切なサイズと形状のロボット用操作可能なオブジェクトに焦点を当てています。例えば、プライヤーや調理器具、ドライバーなどです。私たちの注釈付けプロセスは効率化されており、市販のカメラ1台と半自動処理のみが必要で、クラウドソーシングなしで高品質な3D注釈を生成することができます。データセットは、17のカテゴリの212の実世界のオブジェクトの2.2kのビデオからの308kの注釈付き画像フレームで構成されています。私たちは、ロボットマニピュレータが単純な押すだけではなく、環境と作用する必要がある実践的なシナリオでの研究を促進するために、ハードウェアおよびキッチンツールのオブジェクトに焦点を当てています。私たちのデータセットが6DoFカテゴリレベルの姿勢+スケール推定や関連するタスクにどのように役立つかについて説明します。また、すべてのオブジェクトの3D再構築されたメッシュを提供し、このようなデータセットの収集を民主化するために対処すべきいくつかの課題を概説します。プロジェクトのウェブサイト: https://nvlabs.github.io/HANDAL/

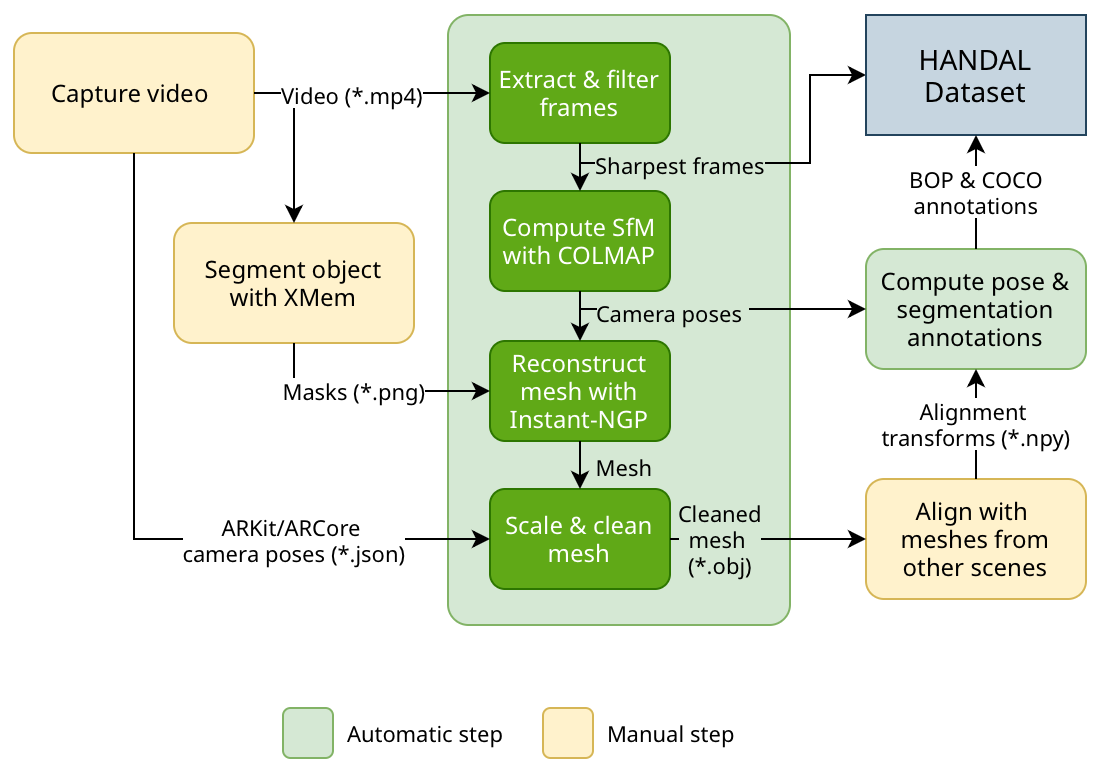
上記の図のような手順でHANDAL Datasetを構築している。
End-to-End Affordance Learning for Robotic Manipulation
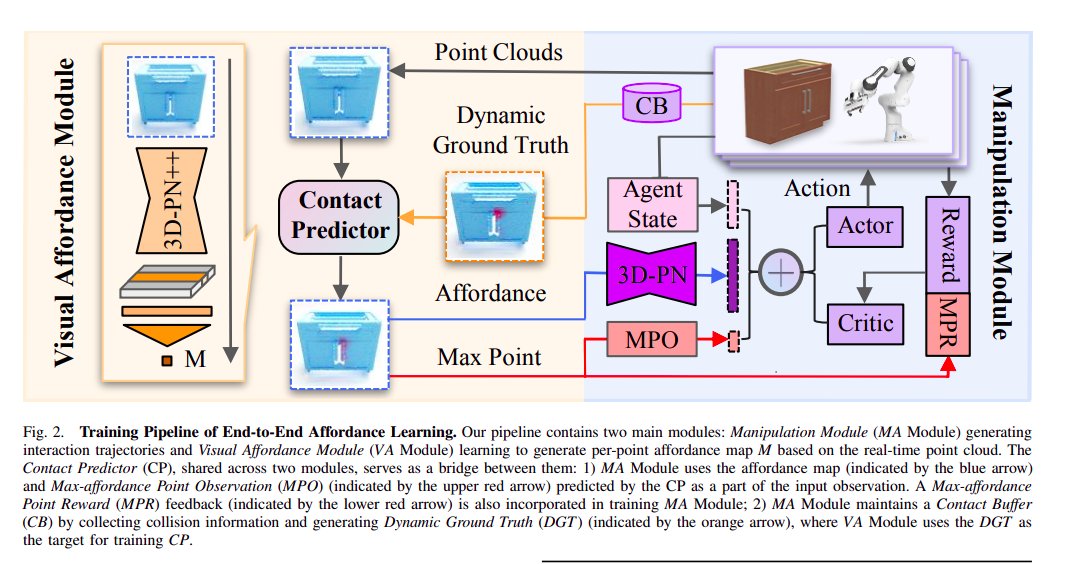
これも機械翻訳による和訳
要約— 3Dオブジェクトを対話的な環境で操作することを学習することは、強化学習(RL)における難しい課題でした。特に、異なる意味カテゴリ、多様な形状ジオメトリ、多機能性を持つオブジェクトに一般化できるポリシーを訓練することは困難でした。最近、ビジュアルアフォーダンスの技術は、効果的な実行可能なセマンティクスを持つオブジェクト中心の情報先行を提供する可能性を示しています。そのような効果的なポリシーは、ドアを開ける方法を知ることで、ドアを開けるためのハンドルに力を加えることができます。ただし、アフォーダンスを学習するには、しばしば人間が定義した動作の基本要素が必要であり、これにより適用可能なタスクの範囲が制限されます。この研究では、RLトレーニングプロセス中に生成された接触情報を利用して、人が定義した動作の基本要素を使用して興味のある接触マップを予測することにより、ビジュアルアフォーダンスの利点を活用します。このような接触予測プロセスは、異なるタイプの操作タスクに一般化できるエンドツーエンドのアフォーダンス学習フレームワークにつながります。驚くべきことに、そのようなフレームワークの効果は、マルチステージおよびマルチエージェントシナリオでも維持されます。私たちは、8種類の操作タスクで私たちの手法をテストしました。その結果、私たちの手法は、成功率でビジュアルベースのアフォーダンス手法やRL手法を含むベースラインアルゴリズムを大幅に上回ることが示されました。
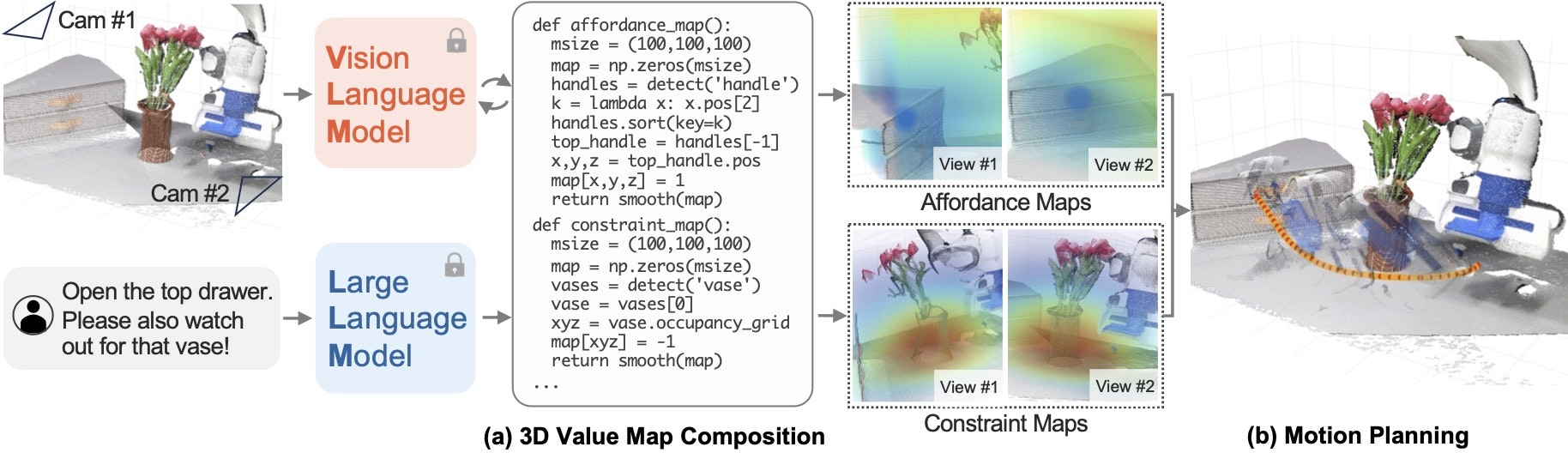
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
pdf
github
[Affordances from Human Videos as a Versatile Representation for Robotics]
https://vision-robotics-bridge.github.io/
pdf
pdf (https://policy-decomposition.github.io/Images/paper.pdf)
チェックポイント
- 手の位置とカメラの位置
- 画像データと3Dのデータ
- 学習結果で推論するのは何か
- アームの種類(単腕、双腕、双腕+移動、人型ロボット)
- VisionAndLanguageの成果を取り入れているか
- 大規模言語モデルの成果を取り入れているか
- 言語を解釈することをUIに組み込んでいるか
affordance とegocentric image とは関連があります。
物体に対して何かを操作を加えるときは、egocentric な画像を元に操作の判断をするためです。
CVPR2024 の中にも
CVPR2024 のリストの中にも、Affordanceというキーワードが5つ見つかった。
papers with code
その分野で、いまどのコードがSotA(State-of-the-Art)とされているのかを調査するには、
https://paperswithcode.com/
のサイトで、そのタスクのカテゴリを検索しよう。
用語集
HICO-DET
a dataset for detecting human-object interactions (HOI) in image