オートエンコーダで異常検知を行う際に、loss・val_lossが発散してしまいます
解決したいこと
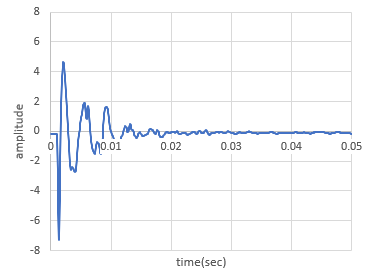
図1のような波形データを対象に、オートエンコーダによる教師なし学習で異常検知したいと思っています。
具体的には、
1.時刻歴波形のcsv(500次元のデータセット(0~0.05secの時刻歴データを0.0001secおきにプロットしたもの))を学習データとして読み取る。
2.1で読み取った学習データをオートエンコーダを用いて75次元まで圧縮する。
3.テストデータを1と同様の手順で読み取る。
4.3.で読み取った学習データを2.で生成したモデルを介して、75次元まで圧縮する。
5.4.をさらに逆変換し、元のデータと同次元のデータに復元する。
6.復元前後の残差平方和から異常の有無を判定する
という流れになります。
図1
発生している問題・エラー
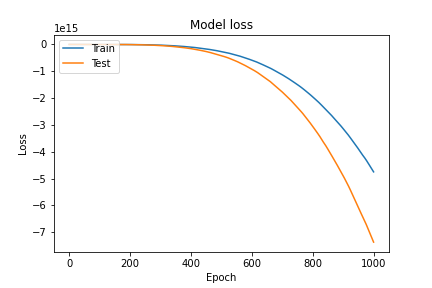
loss, val_lossともに図2のように発散してしまいます。収束させるにはどうすれば良いか教えてください。
図2
該当するソースコード
from tensorflow.keras.layers import Input,Dense
from tensorflow.keras.models import Model
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import StandardScaler
# AutoEncoder
input_layer=Input(shape=(500,))
encoded=Dense(250,activation="relu")(input_layer)
encoded=Dense(125,activation="relu")(encoded)
encoded=Dense(60,activation="relu")(encoded)
decoded=Dense(125,activation="relu")(encoded)
decoded=Dense(250,activation="relu")(encoded)
output_layer=Dense(500,activation="sigmoid")(decoded)
model=Model(inputs=input_layer,outputs=output_layer)
model.compile(loss='binary_crossentropy',optimizer="adam")
#model.compile(loss='mse',optimizer="adam")
dftrain=pd.read_csv('train.csv') #学習データ:計30
print("dftrain", dftrain.shape)
dataset_xtr=dftrain.drop(["Case","Class"],axis=1)
#dataset_xtr=np.abs(dataset_xtr)
#sc = StandardScaler()
#dataset_xtr=sc.fit_transform(dataset_xtr)
print("dataset_xtr", dataset_xtr.shape)
dataset_ytr=dftrain["Class"]
x_train,x_val,y_train,y_val=train_test_split(dataset_xtr,dataset_ytr,test_size=0.5,random_state=0)
dftest=pd.read_csv('test.csv') #テストデータ:計150
x_test=dftest.drop(["Case","Class"],axis=1)
#x_test=np.abs(x_test)
#x_test=sc.fit_transform(x_test)
y_test=dftest["Class"]
history = model.fit(x_train,x_train,epochs=1000, batch_size=4, validation_split=0.2)
nnn=1.96
x_val_inv=model.predict(x_val)
diff_tr=np.sum((np.array(x_val)-np.array(x_val_inv))**2,axis=1)
thresholder=(diff_tr.mean()+nnn*(diff_tr.std()))
preds=[]
#異常の有無を判定
x_test_inv=model.predict(x_test)
diff_test=np.sum((np.array(x_test)-np.array(x_test_inv))**2,axis=1)
for j in range(len(diff_test)):
if diff_test[j]>thresholder:
preds.append(1) #1:異常 0:正常
elif diff_test[j]<=thresholder:
preds.append(0)
print(classification_report(y_test,preds))
print(confusion_matrix(y_test,preds))
np.savetxt("out.txt",preds)
#ROC curve
cnt=0
point=[0,0]
roc=[]
roc.append([0,0])
rank=list(reversed(np.argsort(diff_test)))
error=np.sum((y_test.astype("int")==1))
for ridx in rank:
if y_test[ridx]==1:
point[1]=point[1]+1
cnt=cnt+1
else:
point[0]=point[0]+1
roc.append([point[0],point[1]])
if cnt==error:
roc.append([y_test.shape[0],point[1]])
break
roc=np.array(roc)
np.savetxt("roc.txt",roc)
plt.plot(roc[:,0]/y_test.shape,roc[:,1]/error)
plt.plot([0,1],color='black',linestyle='dashed')
plt.savefig("ROC_curve.png")
plt.show()
#loss and val_loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.savefig("loss-epoch.png")
plt.show()
自分で試したこと
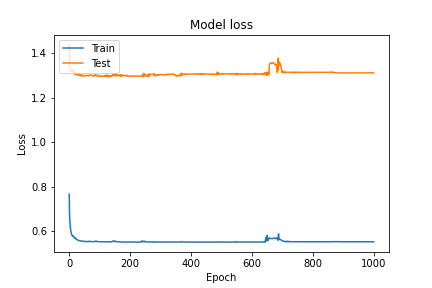
活性化関数をreluからsigmoidに変える、lossの評価関数をbinary_crossentropyからmseに変えましたが解決に至っておりません。なお、評価関数をmseに変えた際は、一応収束しました(図3参照。ただし、train/testで乖離がみられること、epoch=700付近で一時的にlossが増大するといった事象が確認されました。)
また、元データについても、絶対値をとって負値をなくす・標準化を行うなどしましたが、効果がみられませんでした。ちなみに、波形をcsvではなく画像として認識した場合には、loss, val_lossともにほぼ同値で収束しました。
図3
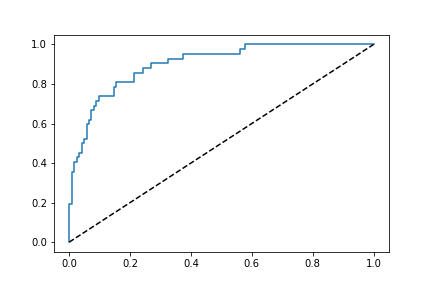
ROC曲線自体は、図4のようになっており、異常検知自体は概ね正しく行われていると思われます。
図4
0 likes


















